没错,就是那个卖外设的罗技中国。
我现在的主力鼠标,还是几年前买的 MX Master 3S。
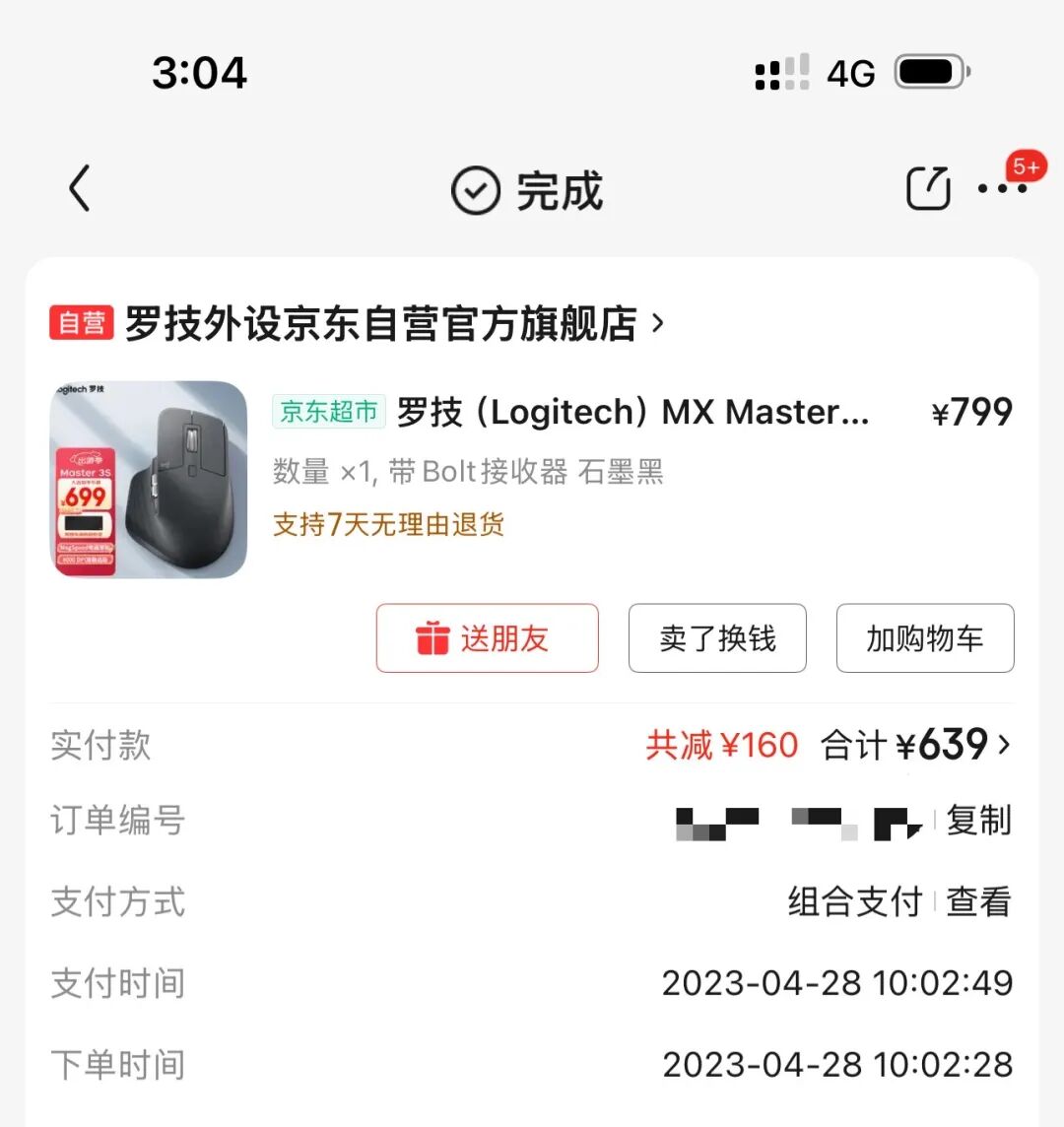
现在点进去看,好像还要 699 元。很少有电子产品能这么多年不怎么掉价的,侧面说明产品力确实还可以。
但罗技最近似乎有点别的想法,不甘于低调赚钱,自以为幽默地发布了一些让消费者感到不适的内容。
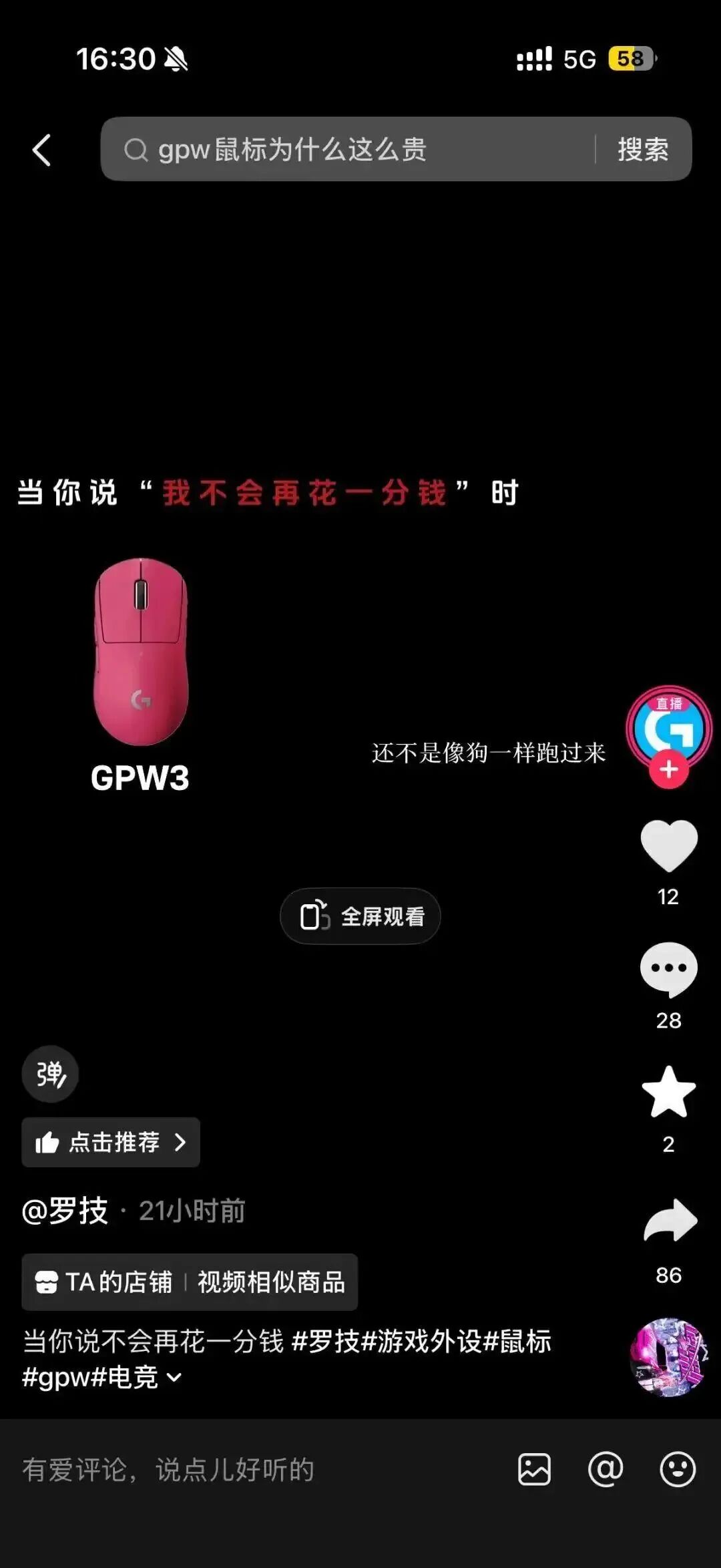
昨天,罗技官方账号发布了一则产品推广视频,里面赤裸裸地提到:“一降价你还不是像狗一样跑过来。”
说实话,我真不理解,为什么这些做 ToC 生意的企业,会觉得自己真有这么牛。最近一个敢这么“教育”消费者的企业是西贝,现在听说正准备关掉将近一半的门店。
虽然我不是小米的粉丝,但我觉得所有做 ToC 生意的企业,都应该向雷军学习,至少人家从来不会在“对消费者的态度”上翻车。
消费电子行业,尤其是外设领域,本质上是个“勤奋行业”。它不像操作系统或社交软件,能形成强大的生态锁定,用户的转移成本,往往只是一次购物车的刷新。品牌和用户的关系,绝不是主人与狗,傲慢只会逐步消耗自己的口碑。
聊完这个插曲,我们进入正题。周末了,来一道和「美团(社招)」相关的算法题。
题目描述
平台:LeetCode
题号:851
有一组 n 个人作为实验对象,从 0 到 n - 1 编号,其中每个人都有不同数目的钱,以及不同程度的安静值(quietness)。为了方便起见,我们将编号为 x 的人简称为 "person x"。
给你一个数组 richer ,其中 richer[i] = [ai, bi] 表示 person ai 比 person bi 更有钱。另给你一个整数数组 quiet ,其中 quiet[i] 是 person i 的安静值。
richer 中所给出的数据 逻辑自恰(也就是说,在 person ai 比 person bi 更有钱的同时,不会出现 person bi 比 person ai 更有钱的情况)。
现在,返回一个整数数组 answer 作为答案,其中 answer[x] = y 的前提是,在所有拥有的钱肯定不少于 person x 的人中,person y 是最安静的人(也就是安静值 quiet[y] 最小的人)。
示例 1:
输入:richer = [[1,0],[2,1],[3,1],[3,7],[4,3],[5,3],[6,3]], quiet = [3,2,5,4,6,1,7,0]
输出:[5,5,2,5,4,5,6,7]
解释:
answer[0] = 5,
person 5 比 person 3 有更多的钱,person 3 比 person 1 有更多的钱,person 1 比 person 0 有更多的钱。
唯一较为安静(有较低的安静值 quiet[x])的人是 person 7,
但是目前还不清楚他是否比 person 0 更有钱。
answer[7] = 7,
在所有拥有的钱肯定不少于 person 7 的人中(这可能包括 person 3,4,5,6 以及 7),
最安静(有较低安静值 quiet[x])的人是 person 7。
其他的答案也可以用类似的推理来解释。
示例 2:
输入:richer = [], quiet = [0]
输出:[0]
提示:
n == quiet.length1 <= n <= 5000 <= quiet[i] < nquiet 的所有值 互不相同0 <= richer.length <= n * (n - 1) / 20 <= ai, bi < nai != biricher 中的所有数对 互不相同- 对
richer 的观察在逻辑上是一致的
拓扑排序
根据题意,我们可以使用 richer 数组进行建图(邻接矩阵或邻接表)。对于每组 richer[i] = [a, b] 而言,添加一条从 a 到 b 的有向边(有钱的指向没钱的)。
题目中提到的「richer 逻辑自恰」是指在该图中不存在环,即图是一个有向无环图 (DAG)。
因此,我们可以在建图过程中,同时统计每个节点的入度数,然后在这个 DAG 中跑一遍 拓扑排序 来求得答案 answer。
对「图论 拓扑排序」不了解的同学,可以先看前置知识:拓扑排序入门,里面详细说明了拓扑排序的基本流程以及反向图做法的正确性证明。
起始时,每个 answer[i] = i(即默认自己就是最安静的人)。然后将统计入度为 0 的节点进行入队。每次节点出队时,将该节点从图中“删掉”,带来的影响是「该节点的所有邻接点的入度减一」。若某个邻接点更新入度后数值为 0,则将其加入队列。
同时,在拓扑排序的遍历过程中,我们利用节点间的指向关系进行状态更新。具体来说,当处理边 a -> b(a 比 b 有钱)时,我们检查 a 对应的最安静的人 answer[a] 是否比 b 当前记录的最安静的人 answer[b] 更安静(即 quiet[answer[a]] 更小)。如果是,则用 answer[a] 去更新 answer[b]。
本题点数为 n,边数为 richer.length。当边数接近 n*(n-1)/2 时,图非常稠密。对于稠密图,可以直接使用「邻接矩阵」进行存图,遍历邻接点时检查矩阵对应位置即可。关于如何根据图的特点选择存图方式,可以参考相关专题文章,这里不再赘述。
以下是使用邻接矩阵实现的 Java 代码:
class Solution {
public int[] loudAndRich(int[][] richer, int[] quiet) {
int n = quiet.length;
int[][] w = new int[n][n];
int[] in = new int[n];
for (int[] r : richer) {
int a = r[0], b = r[1];
w[a][b] = 1; in[b]++;
}
Deque<Integer> d = new ArrayDeque<>();
int[] ans = new int[n];
for (int i = 0; i < n; i++) {
ans[i] = i;
if (in[i] == 0) d.addLast(i);
}
while (!d.isEmpty()) {
int t = d.pollFirst();
for (int u = 0; u < n; u++) {
if (w[t][u] == 1) {
if (quiet[ans[t]] < quiet[ans[u]]) ans[u] = ans[t];
if (--in[u] == 0) d.addLast(u);
}
}
}
return ans;
}
}
也可以使用更节省空间的邻接表来实现,Java 代码如下:
class Solution {
int N = 510, M = N * N + 10;
int[] he = new int[N], e = new int[M], ne = new int[M];
int idx;
void add(int a, int b) {
e[idx] = b;
ne[idx] = he[a];
he[a] = idx;
idx++;
}
public int[] loudAndRich(int[][] richer, int[] quiet) {
int n = quiet.length;
int[] in = new int[n];
Arrays.fill(he, -1);
for (int[] r : richer) {
int a = r[0], b = r[1];
add(a, b); in[b]++;
}
Deque<Integer> d = new ArrayDeque<>();
int[] ans = new int[n];
for (int i = 0; i < n; i++) {
ans[i] = i;
if (in[i] == 0) d.addLast(i);
}
while (!d.isEmpty()) {
int t = d.pollFirst();
for (int i = he[t]; i != -1; i = ne[i]) {
int u = e[i];
if (quiet[ans[t]] < quiet[ans[u]]) ans[u] = ans[t];
if (--in[u] == 0) d.addLast(u);
}
}
return ans;
}
}
- 时间复杂度:令
n 为人数(点数),m 为 richer 数组长度(边数)。建图的复杂度为 O(m) 或 O(n^2)(取决于使用邻接表还是邻接矩阵);拓扑排序的复杂度为 O(n + m)。整体复杂度为 O(n + m)。
- 空间复杂度:
O(n + m),用于存图及存储中间状态。
从品牌营销的翻车案例,到一个经典的图论算法应用,看似不相关,实则都关乎“关系”与“顺序”的处理。品牌需要理清与用户的关系,算法需要理清节点间的依赖关系。希望本文的讨论和解析对你有所启发。如果你想就此类话题或技术问题做更深入的交流,欢迎来云栈社区一起探讨。
 发表于 2026-3-28 05:37:53
|
查看: 144|
回复: 0
发表于 2026-3-28 05:37:53
|
查看: 144|
回复: 0
