咱们做运维的,几乎天天和 Nginx 打交道,配置文件写得滚瓜烂熟。但被问到“它凭啥能扛住几万甚至几十万的并发连接”时,很多人可能只能复述“异步非阻塞,基于事件驱动”这样的标准答案。这话没错,但总觉得像隔靴搔痒。今天,咱们就撇开教科书定义,用生产实践中的大白话,把这个事儿彻底聊明白。
从“傻等”说起:传统的阻塞模式
要理解 Nginx 的强大,不妨先看看它的“前辈”是怎么做的。以经典的 Apache prefork 模型,或者最简单的 Socket 服务器为例,它们通常采用 BIO(Blocking I/O),即阻塞式 I/O。
想象一下,你是一名服务员(服务器进程)。在传统阻塞模式下,你走到1号桌准备点菜,但客人还在看菜单。这时你只能干站在那儿等,手里的小本本(进程资源)也不能给别人用。此时2号桌高喊“服务员!”,你听到了,却无法响应,因为你被1号桌“阻塞”住了。
为了解决这个问题,老板(系统)只好采用“人海战术”——来一个客人,就派一个专门的服务员。这就是“多进程/多线程”模型。Apache 的 prefork 模式正是如此:一个连接,fork 一个子进程。
这招看似解决了问题,但代价高昂。进程是资源消耗大户,每个进程都要占用独立的内存和 CPU 时间片。当并发连接数达到成千上万时,系统内就会充斥着大量进程,CPU 把大量时间浪费在进程间的上下文切换上,而非实际处理请求。这正是著名的 C10K问题的根源:用“人海战术”硬堆连接,服务器资源很快就会耗尽。
换个思路:非阻塞 I/O
既然“傻等”效率低下,那能不能“不等”呢?还是服务员的例子。这次你走到1号桌,客人没想好,你不再傻等,而是说“您先看,好了叫我”,然后立刻转身去服务2号桌。这就是 非阻塞 I/O。
在程序中,当尝试读取数据(如接收请求)时,如果没有数据可读,系统不会阻塞进程,而是立即返回一个错误(如 EAGAIN 或 EWOULDBLOCK),意思是“现在没数据,请稍后再试”。
这听起来不错,但带来了新问题:你怎么知道哪桌客人准备好了?你只能不停地轮询,一遍遍跑去每桌问“好了吗?”。如果有一万桌客人,你光是跑路就累垮了,CPU 也在进行大量无效的轮询,造成资源浪费。这就是“忙轮询”的弊端。
真正的大招:事件驱动机制
此时,如果有一个大堂经理(操作系统内核)拿着对讲机(I/O多路复用机制),问题就迎刃而解了。
你不再需要轮询。你只需原地待命。哪桌客人准备好了,经理就在对讲机里喊:“5号桌要点菜!”你闻声而去即可。这就是 事件驱动。
在 Linux 系统中,这个“大堂经理”就是 epoll;在 BSD/Mac 上是 kqueue;更早的系统则有 select 和 poll。Nginx 强大的核心,正是高效地运用了这套机制。它摒弃了人海战术,采用了“精英策略”:一个 Worker 进程,就能高效管理成千上万个连接。
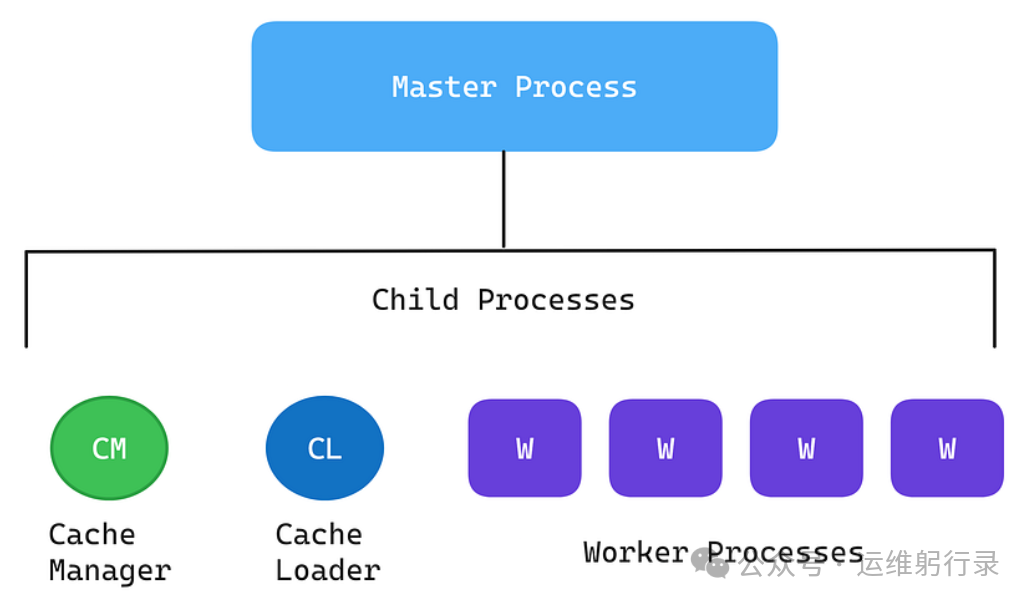
让我们拆解一下 Nginx 的工作流,看看它是如何将这几个概念融会贯通的。
1. Master 与 Worker 的分工
Nginx 启动后,会有一个 Master 进程和多个 Worker 进程。Master 进程如同饭店老板,负责管理(读取配置、绑定端口、平滑重启),不直接服务客人。真正干活的是 Worker 进程。
关键在于,Worker 进程的数量通常与 CPU 核心数保持一致。这样既能充分利用多核性能,又能避免过多的进程导致频繁的上下文切换开销。
2. 抢占式连接接受
所有 Worker 进程都监听相同的服务端口(如80或443)。当一个新的客户端连接到来时,哪个 Worker 来处理?Nginx 使用了一把“锁”(accept_mutex)。连接到达时,抢到锁的 Worker 获得该连接的处理权。一旦连接建立,该连接后续的所有读写操作都将由这个 Worker 全权负责,有效避免了“惊群效应”(所有 Worker 被唤醒但只有一个能抢到连接,造成资源浪费)。
3. 事件循环(Event Loop)
这是 Nginx 的灵魂。每个 Worker 进程内部都在运行一个高效的事件循环,其核心逻辑如下:
while (true) {
// 1. 等待事件发生
events = epoll_wait(连接池, 超时时间);
// 2. 遍历处理事件
for (event in events) {
if (event.type == '读事件') {
// 处理读数据,比如接收 HTTP 请求
handle_read(event);
} else if (event.type == '写事件') {
// 处理写数据,比如返回 HTTP 响应
handle_write(event);
}
}
}
看明白了吗?Worker 并非傻等某一个连接,而是通过调用 epoll_wait 这个系统调用,一次性询问操作系统内核:“我管理的这上万个连接里,哪些现在有动静(数据可读、可写)?”
内核负责维护所有被监视的连接(通常用红黑树存储),并将有事件发生的连接放入一个就绪列表。当网卡收到数据,内核识别出这是对应某个连接的数据,就会将该连接标记为就绪。随后,epoll_wait 返回的正是这一小批“有事儿”的连接列表。
这就像大堂经理手里有个“服务铃”列表,他只通知服务员那些按了铃的桌号。服务员无需询问每一桌,效率自然倍增。理解这种 高并发 处理模型,是后端架构设计的重要基础。
为什么这套模型能抗住高并发?
我们来算一笔经济账。假设一台8核服务器,运行8个 Nginx Worker 进程,需要处理10,000个并发连接。
- 传统多进程模型 (如 Apache prefork):可能需要数千个进程。假设每个进程占用10MB内存,总内存消耗就是几十GB。CPU 忙于在数千个进程间切换,缓存命中率极低,性能低下。
- Nginx 事件驱动模型:
- 内存占用极低:仅有8个常驻 Worker 进程。每个活跃连接只占用少量内存存储状态(如 socket 描述符、请求缓冲区)。那10,000个连接中,大部分可能处于空闲状态(如用户阅读页面),它们几乎不消耗 CPU,仅占用极少内存。
- CPU 利用率极高:Worker 进程被唤醒就是为了处理事件,处理完一个立即处理下一个,没有空转和大量无谓的上下文切换。
这就好比一个配备了对讲机的超级服务员,只响应呼叫,行动高效。这种设计使得 Nginx 能够以极少的资源代价,支撑海量并发连接。
一个关键陷阱:阻塞操作
看到这里,你可能会有疑问:“既然 Nginx 这么强,为什么有时还会出现 CPU 飙升或服务卡死?” 这就引出了事件驱动模型的天敌:阻塞调用。
Nginx 的 Worker 事件循环本质上是单线程的(尽管支持多线程,但核心事件循环是单线程)。这意味着,一旦这个线程被某个操作阻塞,那么这个 Worker 管理的所有连接都会“卡住”。
例如,在 Nginx 中执行一个复杂的 Lua 脚本进行大量计算,或者不慎调用了阻塞式的磁盘 I/O(尽管 Nginx 对文件 I/O 有异步优化,但慢速磁盘仍是潜在瓶颈)。这就好比超级服务员被5号桌客人拉着计算“圆周率后一万位”,期间其他所有需要服务的客人都只能等待。
因此,Nginx 的设计哲学要求所有操作都必须是非阻塞的。无论是 DNS 解析、磁盘访问还是与后端通信,都应采用异步方式。必须执行的阻塞操作,要么确保其速度极快,要么将其卸载到独立的线程池中去处理。这也是为什么在生产环境中,我们应避免在 Nginx 中执行复杂的同步逻辑。
Nginx 关键配置调优
理解了原理,我们来看看生产环境中几个至关重要的配置参数,调优它们能直接提升性能。
worker_processes
此参数通常设置为 auto。Nginx 会自动检测 CPU 核心数并启动对应数量的 Worker 进程,遵循“一个核心一个 Worker”的原则,最大化利用 CPU 并减少切换开销。
worker_connections
定义单个 Worker 进程能够同时处理的最大连接数。默认值1024对于现代应用来说通常太小。生产环境常设置为 65535 或更高,但这取决于系统级的文件句柄限制(ulimit -n)。
这里有个公式:理论最大并发连接数 = worker_processes * worker_connections。
请注意:如果启用了 HTTP keepalive 长连接,一个连接会占用更长时间。更重要的是,当 Nginx 作为反向代理时,一个客户端请求会同时占用一个“客户端到 Nginx”的连接和一个“Nginx 到后端服务器”的连接。因此,实际能支撑的客户端并发数会低于公式计算值,配置时需预留足够余量,避免出现 502 Bad Gateway 错误。
use epoll;
在 events { ... } 配置块中,我们常看到这行指令。在 Linux 2.6+ 内核上,Nginx 默认就会使用 epoll。显式指定它主要是为了清晰和确保使用最优的多路复用器。在 BSD 系统上,对应的指令是 use kqueue;。
accept_mutex
这就是前文提到的“锁”,默认是开启的(on)。它能有效防止“惊群效应”。在绝大多数场景下,保持开启是有益的。只有在连接建立速率极高(如每秒数万)的极端场景下,这把锁可能成为微小瓶颈,此时可以考虑关闭(off)并进行压测对比。
实践案例:一次性能瓶颈排查
曾经遇到一个案例:某系统使用32核高端服务器进行压测,但 QPS 始终卡在5000左右,CPU 使用率却只有30%。
排查发现,后端服务响应较慢,平均耗时200ms。而 Nginx 的 worker_connections 仅设置为默认的1024。我们来算一下:QPS 5000,平均响应时间200ms,根据 Little‘s Law,系统中平均处于“正在处理”状态的请求数约为 5000 * 0.2 = 1000 个。这已经接近单个 Worker 的连接数上限,导致连接槽位迅速被占满,新请求无法及时得到处理,只能在队列中堆积或超时。
解决方案很简单:首先调整系统文件句柄限制,然后将 Nginx 的 worker_connections 提升至一个合理值(例如30000)。调整后重载配置,再次压测,QPS 直接突破20000,CPU 利用率也健康地上升了。这个案例生动说明,不理解底层模型,再好的硬件也无法发挥性能。
总结
总而言之,Nginx 之所以能成为高性能 Web 服务器的标杆,关键在于它彻底颠覆了“一个进程/线程处理一个连接”的传统线性思维。它深度融合了事件驱动与非阻塞 I/O 模型。
它不再被动等待 I/O 完成,而是主动通过操作系统提供的 epoll 等 I/O 多路复用机制,像一个高效调度中心,只关注那些真正需要处理的连接事件。这种设计使其能够以极低的资源消耗,承载极高的并发连接吞吐量。
对于运维和开发者而言,深入理解这一模型绝不仅仅是为了应对面试。它为我们提供了排查性能瓶颈、进行参数调优和做出架构选型的坚实依据。下次当你面对服务器负载不高但请求却频频超时的情况时,不妨从连接数、阻塞操作、epoll 效率等角度进行思考。原理通了,许多问题便会豁然开朗。
在技术社区如云栈社区中,与同行交流这类底层原理和实战调优经验,是开发者持续成长的重要途径。
 发表于 2026-3-28 06:57:10
|
查看: 101|
回复: 0
发表于 2026-3-28 06:57:10
|
查看: 101|
回复: 0
