超节点好不好?当然好!
现在大家都知道,跟传统的8卡机相比,超节点才是真正干大事儿的。

拿来训练更大的模型,尤其扛住智能体爆发后,海量、实时、复杂的推理需求,超节点已经成为算力基础设施的基本单元。
好归好,大家又觉得跟一堆传统8卡机相比,超节点是个新事物,不太好拿捏。

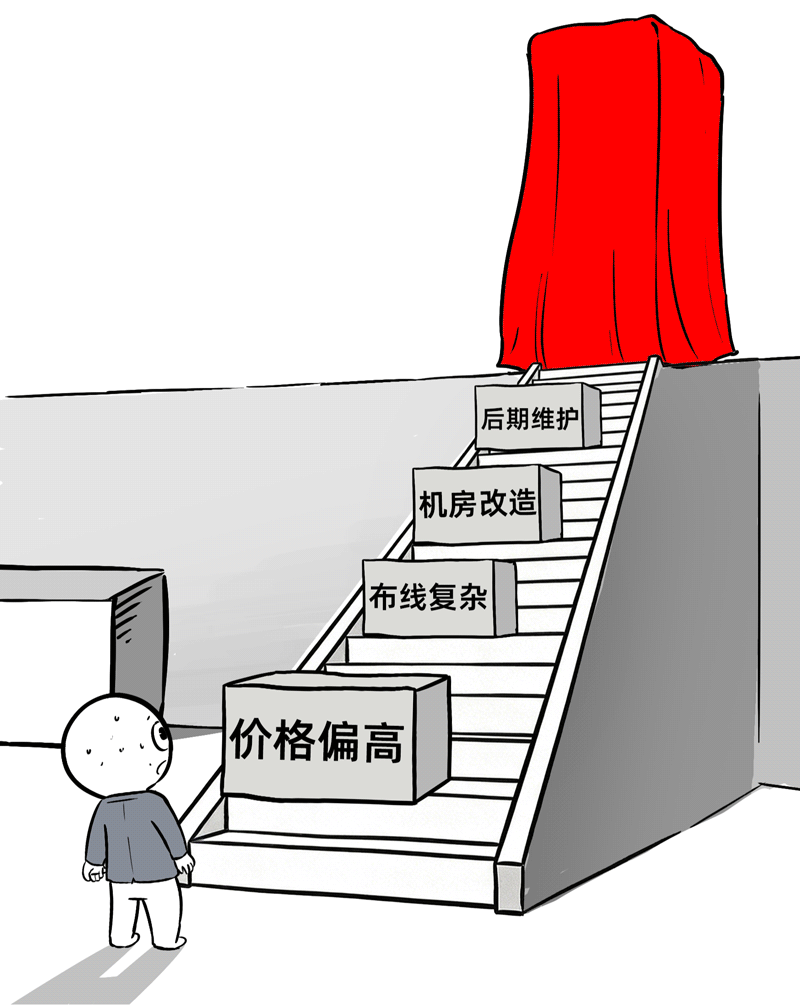
的确,从当下市面上的超节点看,入手门槛有点高。价格、布线复杂、机房改造和后期维护,每一样都是门槛。

但是,从现在起,企业级用户部署和使用超节点的门槛,被大幅降低了。
刚刚,中科曙光下了“狠手”,猛砸这些门槛。
3月26日,曙光发布业界首个箱式无线缆超节点 scaleX40。

scaleX40采用标准箱式高密集成设计,旨在打破传统超节点成本高昂、部署繁琐、运维复杂的行业痛点。
那么,这款 scaleX40 到底有哪些亮点,能担得起“降低门槛”的重任?
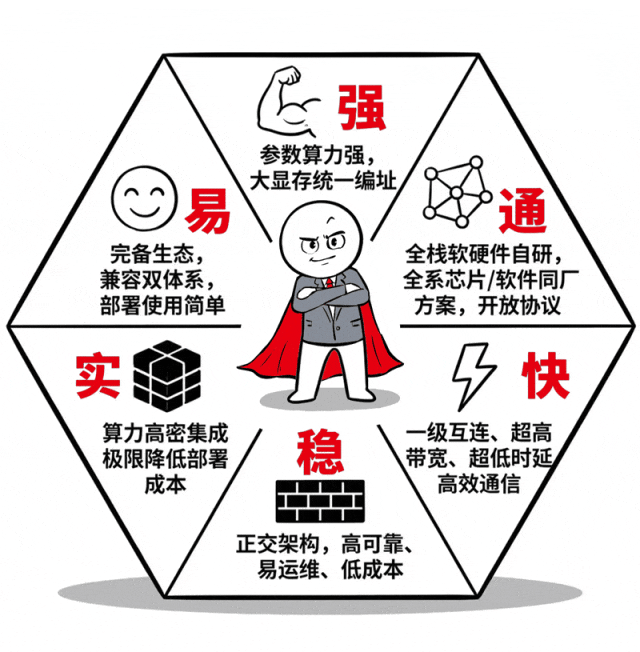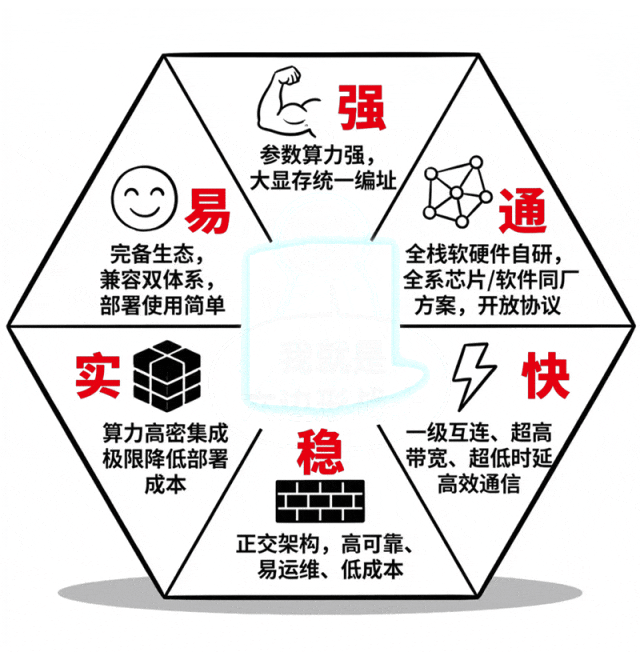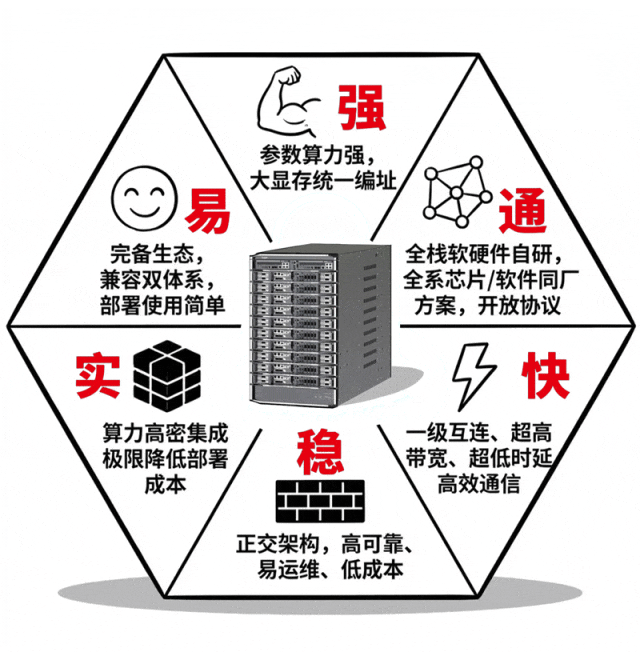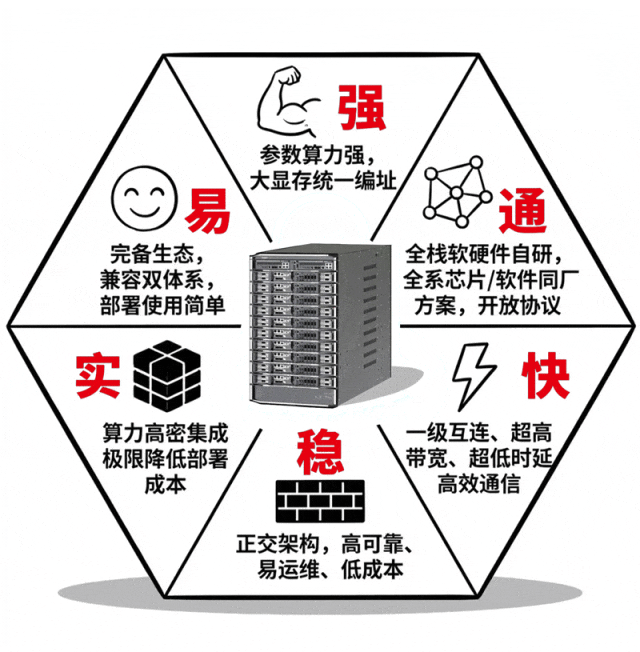
① 性能超级强悍
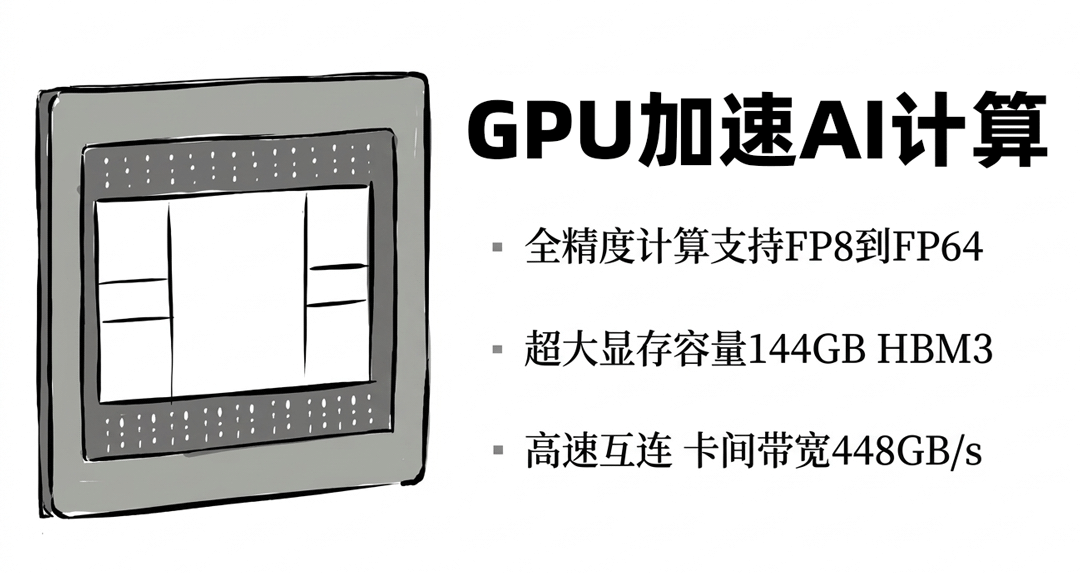
别看身材很紧凑,却能一口气塞下40张AI加速卡,整机火力全开,训练更快,推理更高效。

不光40卡组团厉害,每张卡单拎出来也超级能打,支持全精度计算,拥有超大显存和高速互连能力。
② 一级互连,真正的Scale-UP
如何让40张卡组团战力不打折?一级互连的“真 scale-up”架构是关键。
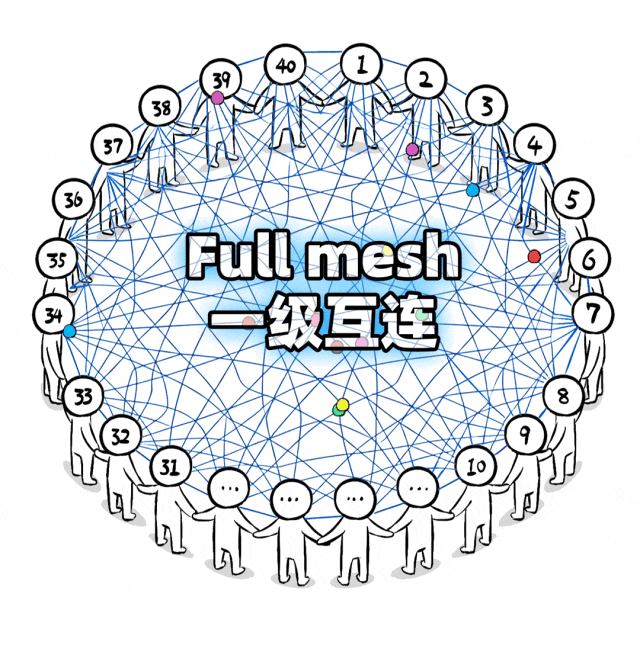
所谓一级互连,是指所有AI加速卡之间的互通都不需要多级中转。一跳直达,对等通信,实现低延迟(单向通信时延百ns级)、高带宽(聚合带宽>17TB/s)。
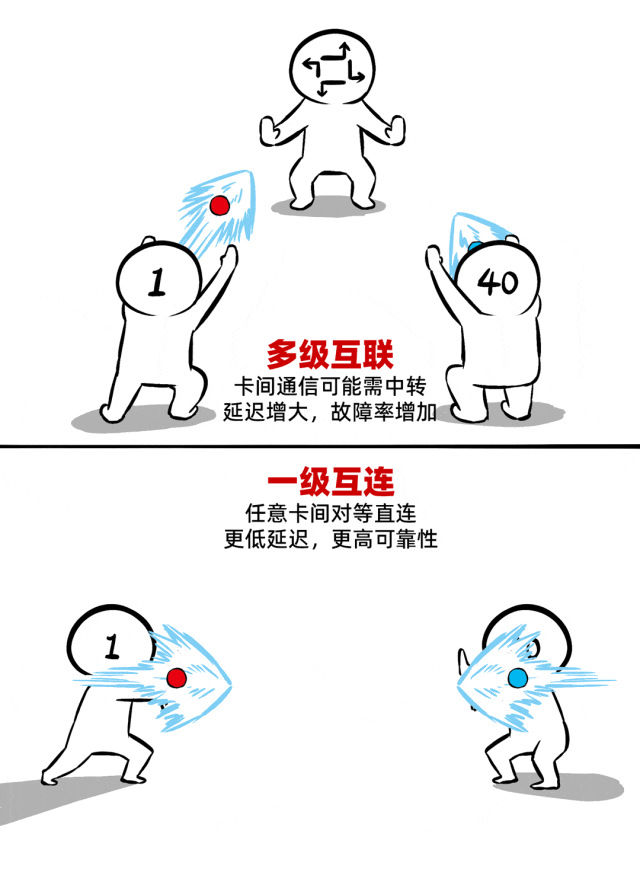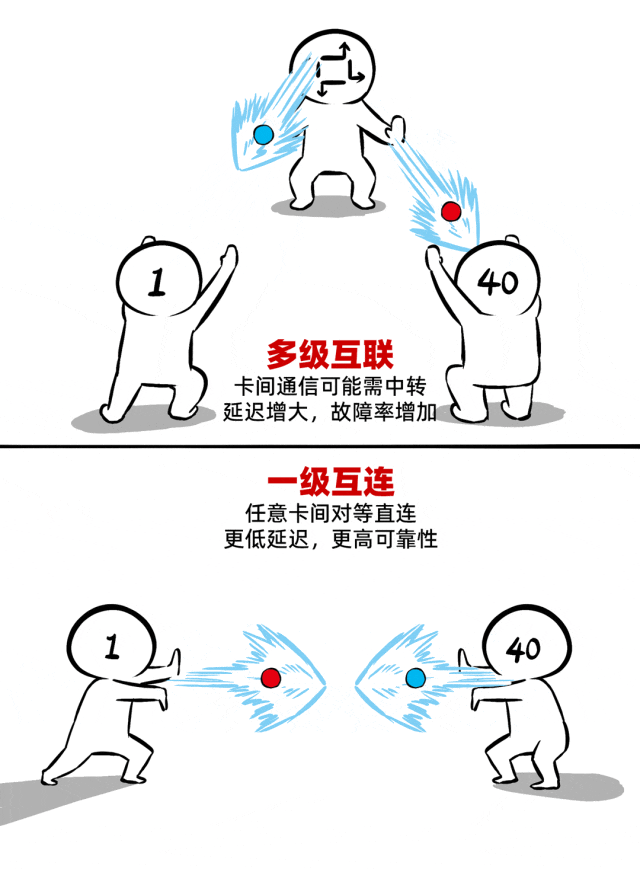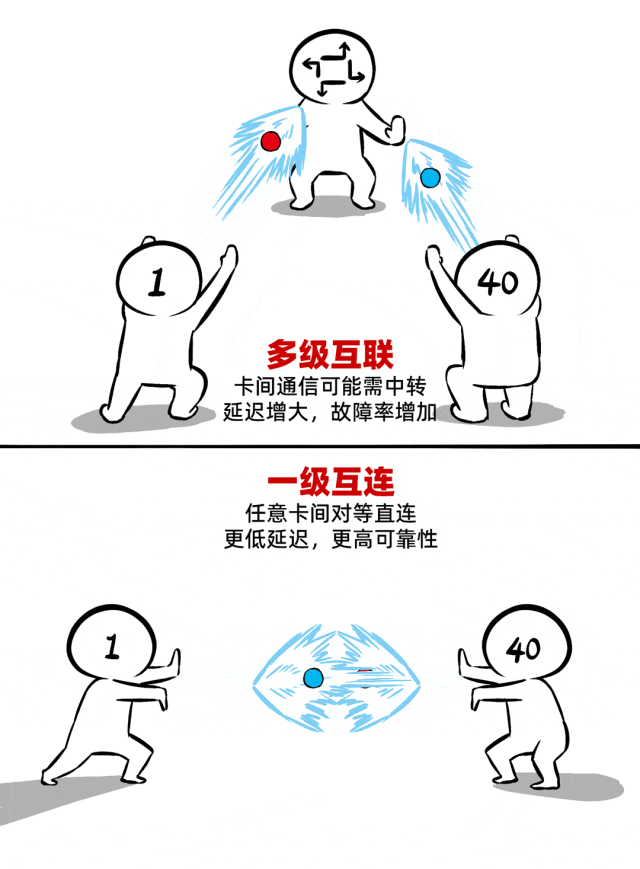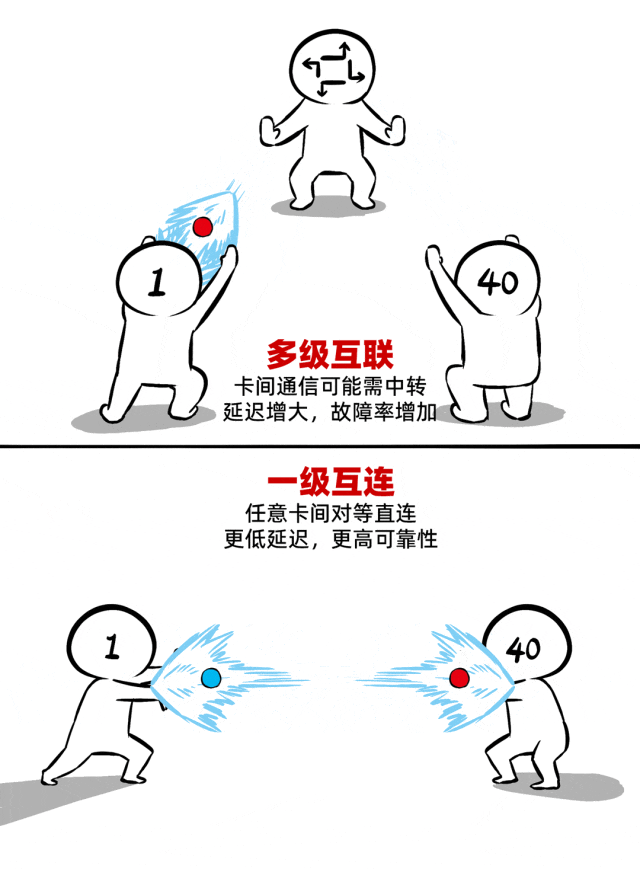
同时,还支持内存语义、统一显存编址。这就意味着40张加速卡不是一盘散沙,而是真正抱团,化身一张显存更大、算力更强的超级加速卡。

③ 无线缆正交架构
scaleX40凭啥成为世界上首个无线缆箱式超节点?又凭啥做到40卡一级互连?这个正交架构是核心。
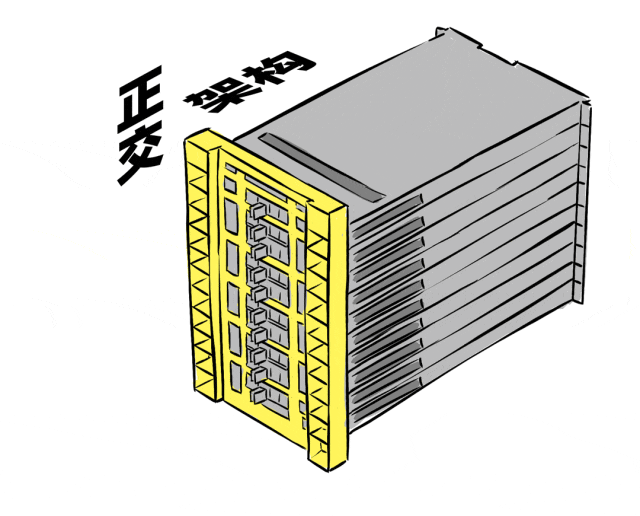
简单来说,就是计算节点和交换节点通过正交的方式直接连接,从此摆脱了线缆的束缚。这不仅省去了线缆的维护烦恼,还带来了更高的可靠性,以及更低的功耗(可用性比铜缆模式提高10倍,功耗比光纤连接降低40%-70%)。
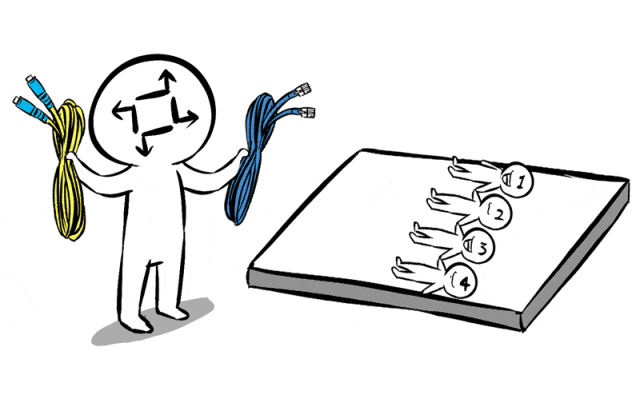
④ 标准尺寸,灵活扩展
scaleX40单机吃下40卡,但身材一点不臃肿,“腰围”是19英寸标准机架规格,普通服务器机柜就能装。而且一个单机柜还能装下双PoD,实现80张加速卡的集群密度!

⑤ 开箱即用,生态兼容性好
scaleX40虽然是新品,但用户完全不需要为上手、迁移担心。配套的开发工具、基础软件、AI大模型与应用全部就绪,开箱即用,主流大模型可以轻松迁移。

这么说吧,scaleX40就像是个超节点领域的“六边形战士”,在算力、互连、架构、部署、生态、可靠性等各项能力值上都拉满了。
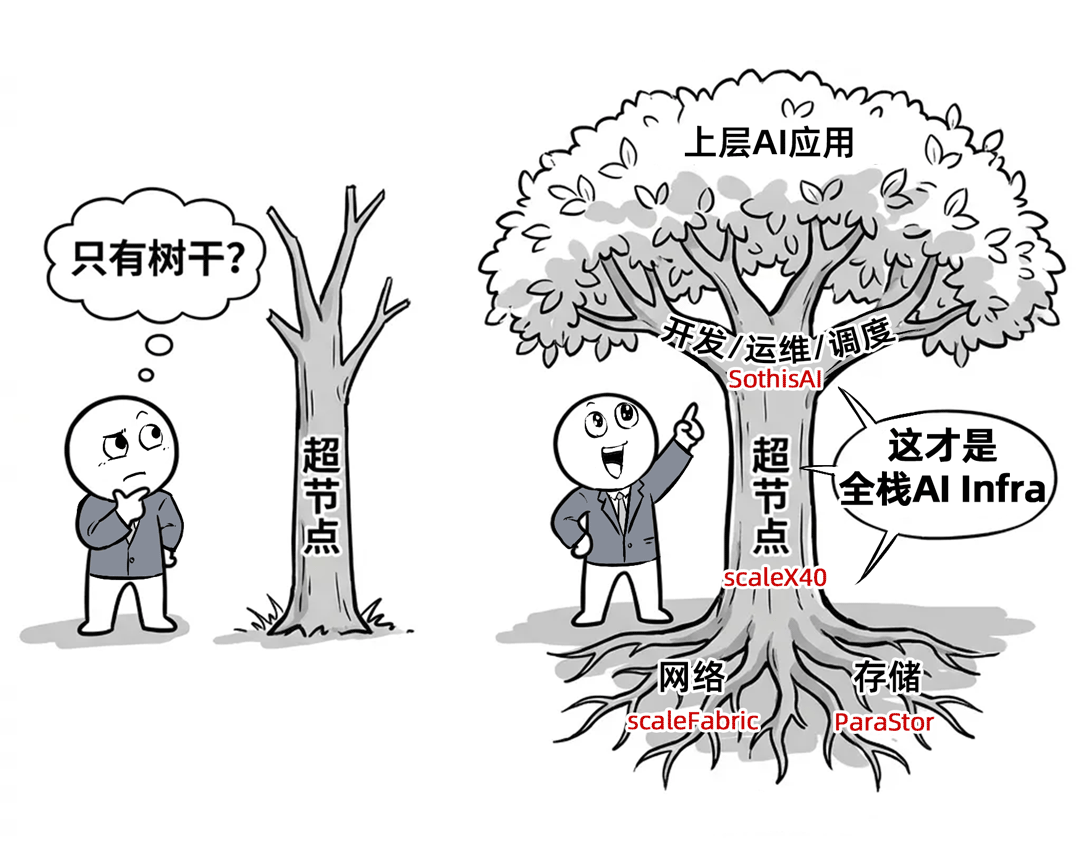
不止超节点,更有全栈配套
在企业级用户的实际应用中,不只需要超节点,AI落地更需要全栈AI基础设施(AI Infra)。
所以,除了scaleX40这个企业级AI Infra“最佳”构建单元,曙光还提供了全栈配套:
① 解决存储瓶颈,曙光提供最懂AI的存储:ParaStor。
② 让多超节点横向无损扩展,曙光提供国产IB网络:scaleFabric。

③ 搞定开发运维难题,曙光提供一站式开发、调度、运维平台:SothisAI。
算力普惠,从scaleX40开始
如今,超节点已经从互联网、大模型巨头渗透到千行百业,越来越多的企业级客户,开始考虑用超节点作为最佳算力载体。
但那些高门槛怎么破?中科曙光用 scaleX40 给出了一个答案——从成本、可落地性、可维护性以及需求适配性来看,它无疑是一个更优的选择。
金融、科教、电网、医疗、运营商……过去这些企业级客户不是不想上超节点,而是受限于性价比和部署运维复杂度。
现在情况不同了,一台真正让企业“买得起、用得上、用得好”、能支撑生产级AI业务的超节点,已经来了。
对于正在寻求构建或升级自身AI算力平台的企业技术决策者而言,关注像 scaleX40 这样能切实降低总拥有成本(TCO)和部署难度的基础设施产品,正变得愈发重要。技术的普及,往往始于门槛的降低。想了解更多前沿技术解读与深度讨论,欢迎来云栈社区交流分享。
 发表于 2026-3-29 02:20:59
|
查看: 182|
回复: 0
发表于 2026-3-29 02:20:59
|
查看: 182|
回复: 0
