OpenClaw的技能库现在大概有一万多个(内置的+官方的+社区的)。第一次看到这个数字,我直接懵了——这么多,怎么选?
这篇文章记录我当时是怎么挑的,以及最后实际在生产环境跑起来的10个技能。
一、先看懂架构,别急着装
一开始我也是看到技能就装,结果发现:
- 有些功能重复,三个技能干同一件事
- 有些装了之后互相冲突
- 有些配置复杂,装完不会用,白占资源
后来才搞明白,OpenClaw的技能分三层:
1.1 三层架构设计
OpenClaw的Skills生态采用三层架构,确保扩展性与稳定性:
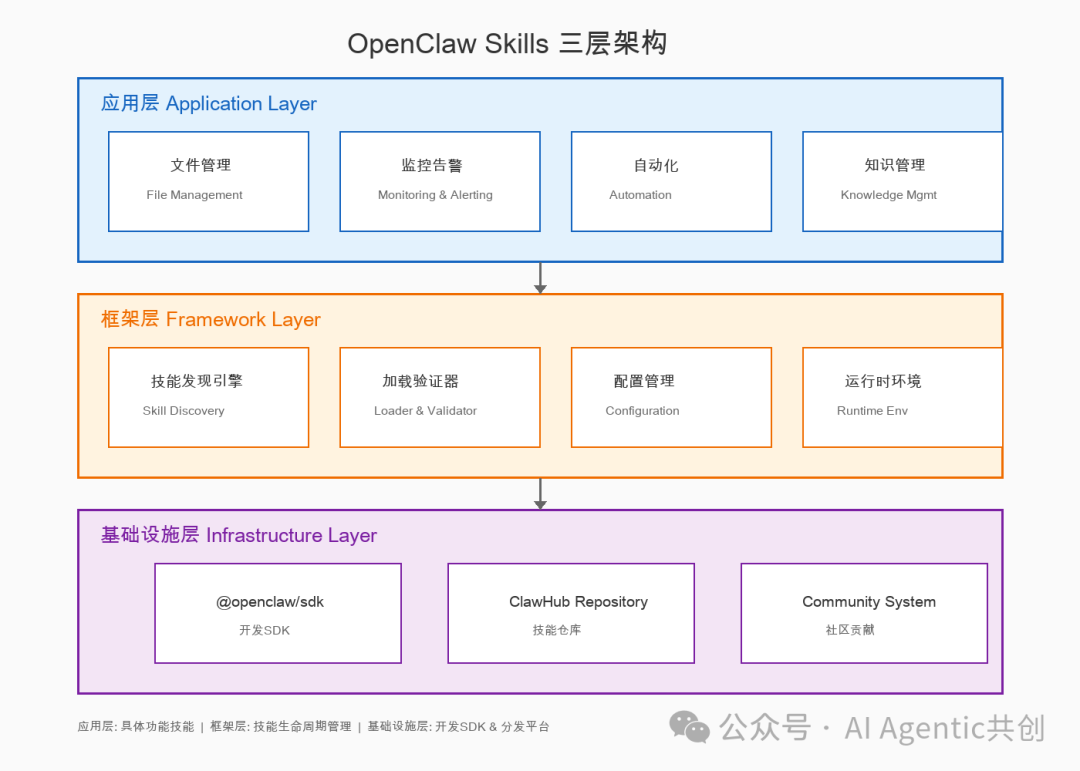
1.2 渐进式加载机制
OpenClaw采用智能加载策略,显著提升性能:
- 按需加载:仅在调用时加载对应Skill,节省80% Token消耗
- 依赖管理:自动解析和处理Skill间的依赖关系
- 缓存优化:常用Skill保持在内存中,减少重复加载开销
1.3 安全沙箱设计
所有Skills运行在独立的安全沙箱中:
- 权限分级控制(network、file:read、file:write等)
- 资源使用限制(CPU、内存、执行时间)
- 操作审计日志,确保可追溯性
理解这个之后,我会先看技能的 manifest.json,确认它的资源占用和依赖关系,再决定装不装。在实际的运维/DevOps/SRE场景中,这能避免很多潜在冲突。
一个教训:早期装了个file-search,结果发现它跟另一个文件管理技能共用同一个缓存目录,两边数据互相覆盖。排查了半天才发现是命名空间冲突。
二、我的筛选流程
面对一万多个技能,我当时是这么筛的:
第一步:关键词搜索
# 分别搜索相关关键词(不支持正则,只能单个关键词)
npx skills find monitor
npx skills find log
npx skills find backup
npx skills find automation
# 或者用 GitHub 搜索,支持排序
gh search repos "openclaw skill monitor" --sort stars --limit 10
搜出来大概几十个相关的。然后逐个看README,排除掉:
- 最近一次更新是一年前的
- Issue区一堆未解决的bug
- 依赖特别复杂,装个技能要配一堆环境
第二步:测试环境验证
剩下20个左右,我在测试环境每个跑一遍基本功能。有些看着很好,实际跑起来要么慢,要么内存泄漏,要么跟我的系统不兼容。
第三步:评估性价比
当时的标准:
- 能不能5分钟内跑通基本功能?
- 配置文件能不能一眼看懂?
- 出问题的时候,日志好不好排查?
最后筛出8个现成的+2个自己处理的,实际在生产环境用了。
运维技能评估矩阵
| 评估维度 |
权重 |
具体指标 |
评分标准 |
| 实用性 |
40% |
解决痛点能力 |
1-5分,基于实际应用场景 |
| 易用性 |
30% |
配置复杂度 |
安装步骤、依赖项数量 |
| 社区活跃度 |
20% |
更新频率、issue响应 |
近3个月更新次数 |
| 运维相关性 |
10% |
运维场景覆盖 |
监控、告警、自动化等 |
三、我实际装了的8个现成技能
1. file-manager
运维最常见的场景:日志里找错误。
以前:grep -r "ERROR" /var/log,然后等几分钟,看着满屏的输出头大。
现在用这个技能:
bash skill.sh "find ERROR in /var/log"
我的配置:
编辑 config.json:
{
"max_results": 100,
"default_paths": ["/var/log", "/opt/logs"],
"exclude_patterns": ["*.tmp", "*.cache"]
}
安装:
npx skills add bussgrowwithlucky-crypto/openclaw-skill-file-manager
2. system_resource_monitor
之前用Prometheus+Grafana,太重了。对于小团队,这个够用。
用法很简单,直接对话:
"system status"
返回结果:
- CPU Load(1, 5, 15分钟平均负载)
- 内存使用(物理内存 + Swap)
- 磁盘空间(根分区容量和百分比)
- 运行时间
安装:
npx skills add legoliath/openclaw-skill-system-monitor
3. log-analyzer
不是简单的搜索,是帮你找出日志里的规律。
用法:
bash skill.sh "analyze /var/log/nginx/access.log for 4xx and 5xx errors"
它会告诉你:过去24小时,404错误主要集中在哪里,哪个IP访问最多,哪个时间段异常。
安装:
npx skills add bussgrowwithlucky-crypto/openclaw-skill-log-analyzer
4. task-scheduler
以前用crontab,分散在各个服务器上,管理很乱。现在用这个统一管理。
用法:
bash skill.sh "schedule daily backup at 2am"
教训:一开始我把所有定时任务都迁过来了,结果OpenClaw成了单点故障。后来关键任务还是保留了crontab作为备份。
安装:
npx skills add bussgrowwithlucky-crypto/openclaw-skill-task-scheduler
5. backup-manager
配置备份策略和检查备份完整性。
这个技能是触发式的,直接说关键词:
"backup database"
"setup backup rotation"
关键点:备份完之后一定要验证。我有次备份文件损坏了,过了两周才发现,差点恢复不了。现在每次备份完自动做校验。
安装:
npx skills add smouj/backup-manager-skill
6. Workflow Weaver
比如部署流程:拉代码→编译→测试→部署→验证→通知。
以前用Jenkins,太重。小项目用这个够用了。
用法示例:
# 触发工作流
workflow trigger --repo owner/repo --event push --branch main
# 发送通知
workflow notify --slack "#alerts" --message "Build failed"
# 定时任务
workflow schedule --cron "0 2 * * *" --name daily-backup
局限:复杂场景(多环境并行、蓝绿部署)还是Jenkins更成熟。我现在是混合使用:简单流程OpenClaw,复杂流程Jenkins。
安装:
npx skills add smouj/workflow-weaver-skill
7. knowledge-management
记录故障处理过程、解决方案、SOP文档。
支持全文搜索、标签分类、版本控制。
核心命令:
km sync # 同步memory到本地知识库
km classify # 解析并分类
km summarize # 生成索引文件
实际用法:每次处理完一个故障,花5分钟写个简要记录。下次遇到类似问题,直接搜关键词。
安装:
npx skills add ClaireAICodes/openclaw-skill-knowledge-management
8. config-manager
批量部署配置文件、对比差异、支持回滚。
用法:
bash skill.sh "deploy nginx.conf to web-server-1,web-server-2,web-server-3"
回滚救过我一次:有次改Nginx配置,配错了导致服务不可用,用回滚功能秒恢复。
安装:
npx skills add bussgrowwithlucky-crypto/openclaw-skill-config-manager
四、缺失的2个技能怎么办?用 skill-creator 自己造
文章里我还提到了2个技能,但在社区里没找到现成的。我的解决方案是:用 skill-creator 自己创建。这其实是一种很好的开源实战方式,解决了自己的痛点,也锻炼了动手能力。
安装 skill-creator
# 安装 SkillHub CLI
curl -fsSL https://skillhub-1388575217.cos.ap-guangzhou.myqcloud.com/install/install.sh | bash -s -- --cli-only
# 安装 skill-creator
skillhub install skill-creator
场景1:创建 ssh-monitor 技能(远程服务器巡检)
需求:批量监控多台服务器的 CPU、内存、磁盘,不用每台都登录。
创建步骤:
# 1. 初始化技能
python3 ~/.openclaw/workspace/skills/skill-creator/scripts/init_skill.py ssh-monitor --path ~/.openclaw/workspace/skills/
# 2. 编辑脚本
# 修改 scripts/ssh_monitor.sh
cat > ~/.openclaw/workspace/skills/ssh-monitor/scripts/ssh_monitor.sh << 'EOF'
#!/bin/bash
# 读取配置文件中的服务器列表
HOSTS=$(cat config.json | jq -r '.hosts[]')
SSH_KEY=$(cat config.json | jq -r '.ssh_key')
for HOST in $HOSTS; do
echo "=== $HOST ==="
ssh -i $SSH_KEY $HOST "echo '--- CPU ---' && top -bn1 | head -3 && echo '--- Memory ---' && free -h && echo '--- Disk ---' && df -h | grep -E 'Filesystem|/dev'"
echo ""
done
EOF
chmod +x ~/.openclaw/workspace/skills/ssh-monitor/scripts/ssh_monitor.sh
# 3. 编辑配置文件
# config.json
{
"hosts": ["prod-server-1", "prod-server-2", "prod-server-3"],
"ssh_key": "~/.ssh/id_rsa",
"check_interval": "5m"
}
# 4. 编辑 SKILL.md
# 说明使用方法和触发条件
使用方式:
cd ~/.openclaw/workspace/skills/ssh-monitor
bash scripts/ssh_monitor.sh
效果:一次命令,查看所有服务器的资源状态,不用反复SSH登录。
场景2:创建 service-check 技能(服务健康检查)
需求:定时检查多个服务的健康状态,异常时告警。
创建步骤:
# 1. 初始化技能
python3 ~/.openclaw/workspace/skills/skill-creator/scripts/init_skill.py service-check --path ~/.openclaw/workspace/skills/
# 2. 编写检查脚本
cat > ~/.openclaw/workspace/skills/service-check/scripts/check_service.sh << 'EOF'
#!/bin/bash
SERVICES=$(cat config.json | jq -r '.services[]')
for SERVICE in $SERVICES; do
if ! curl -f "$SERVICE/health" > /dev/null 2>&1; then
echo "ALERT: $SERVICE is down"
# 发送告警(可以集成飞书、钉钉等)
curl -X POST "$WEBHOOK_URL" -d "{\"msg\":\"Service $SERVICE is down\"}"
else
echo "OK: $SERVICE"
fi
done
EOF
chmod +x ~/.openclaw/workspace/skills/service-check/scripts/check_service.sh
# 3. 添加到定时任务(用 task-scheduler 或 crontab)
# 每5分钟检查一次
*/5 * * * * cd ~/.openclaw/workspace/skills/service-check && bash scripts/check_service.sh
skill-creator 的核心功能
1. 技能创建流程
init_skill.py → 编辑 resources → 编辑 SKILL.md → package_skill.py
2. 渐进式披露设计
- Metadata:name + description(始终在上下文,~100字)
- SKILL.md body:技能触发时加载(<5k字)
- Bundled resources:按需加载(scripts/references/assets)
3. 技能结构
my-skill/
├── SKILL.md # 必需的,包含触发条件和用法
├── scripts/ # 可执行脚本
├── references/ # 参考文档
└── assets/ # 模板、图片等资源
4. 打包发布
python3 ~/.openclaw/workspace/skills/skill-creator/scripts/package_skill.py ~/.openclaw/workspace/skills/my-skill
# 生成 my-skill.skill 文件,可以分享给其他人使用
五、实际运行数据
用了大概3个月:
| 运维任务 |
以前 |
现在 |
| 日志搜索定位 |
15-30分钟 |
10-30秒 |
| 系统巡检 |
30-60分钟 |
5-10分钟 |
| 故障排查 |
1-4小时 |
10-30分钟 |
| 配置管理 |
30-90分钟 |
5-15分钟 |
| 多服务器巡检 |
每台登录查看,累死人 |
一键批量查看 |
但不是银弹:
- 配置花时间,前期投入不少
- 有些技能不稳定,出过几次问题
- 学习成本,团队需要适应
- 缺失的技能需要自己创建,需要写代码能力
六、我的建议
如果你也想试:
1. 从1-2个技能开始
别一上来装10个。先选最痛的一个点,比如日志搜索,用一个技能解决。跑顺了再扩展。
2. 测试环境先跑
别直接上生产。有些技能看着文档很好,实际跑起来有各种坑。
3. 缺失的技能自己造
社区没有的,用 skill-creator 自己创建。比等别人做靠谱。
4. 定期清理
装了不用的技能及时卸载。有些技能会在后台跑定时任务,占资源。
5. 参与社区
遇到问题去GitHub提issue。我解决的问题,一半是靠搜issue找到的。当然,你也可以在像云栈社区这样的技术论坛上分享你的实践,与更多人交流。
附录:技能安装速查表
本文提到的8个现成技能
| 技能名称 |
GitHub仓库 |
安装命令 |
主要用法 |
| file-manager |
bussgrowwithlucky-crypto/openclaw-skill-file-manager |
npx skills add bussgrowwithlucky-crypto/openclaw-skill-file-manager |
bash skill.sh "find ERROR in /var/log" |
| system_resource_monitor |
legoliath/openclaw-skill-system-monitor |
npx skills add legoliath/openclaw-skill-system-monitor |
对话:"system status" |
| log-analyzer |
bussgrowwithlucky-crypto/openclaw-skill-log-analyzer |
npx skills add bussgrowwithlucky-crypto/openclaw-skill-log-analyzer |
bash skill.sh "analyze /path/to/log" |
| task-scheduler |
bussgrowwithlucky-crypto/openclaw-skill-task-scheduler |
npx skills add bussgrowwithlucky-crypto/openclaw-skill-task-scheduler |
bash skill.sh "schedule xxx" |
| backup-manager |
smouj/backup-manager-skill |
npx skills add smouj/backup-manager-skill |
对话:"backup database" |
| Workflow Weaver |
smouj/workflow-weaver-skill |
npx skills add smouj/workflow-weaver-skill |
workflow trigger --repo xxx |
| knowledge-management |
ClaireAICodes/openclaw-skill-knowledge-management |
npx skills add ClaireAICodes/openclaw-skill-knowledge-management |
km sync, km classify |
| config-manager |
bussgrowwithlucky-crypto/openclaw-skill-config-manager |
npx skills add bussgrowwithlucky-crypto/openclaw-skill-config-manager |
bash skill.sh "deploy xxx" |
OpenClaw 系列文章
这是关于 OpenClaw 实践的第5篇。下一篇讲讲OpenClaw如何对接prometheus做监控与告警。
基于 OpenClaw 实践,边做边记录。
 发表于 2026-3-30 00:51:35
|
查看: 264|
回复: 0
发表于 2026-3-30 00:51:35
|
查看: 264|
回复: 0
