你有没有过这样的经历?看着报表上一切向好的数据,心里却隐隐觉得哪里不对。在一次复盘会上,面对那条显示需求完成率高达105%的上扬曲线,我却完全高兴不起来。因为就在前一天,一个刚上线的核心模块因为一个低级配置错误直接宕机了。研发总监在会上强调“指标不会骗人”,这让我突然意识到,我们对于研发过程的管理,很可能还停留在一种原始的、凭“手感”的阶段。
我们能看清服务器的负载和数据库的响应,但对于“人”与“流程”这个核心黑盒,我们却像是在迷雾中开车。所谓的效率提升,有没有可能只是因为我们统计了类似“代码行数”这种毫无意义的堆叠数据?
为什么你的“管理直觉”通常是错的?
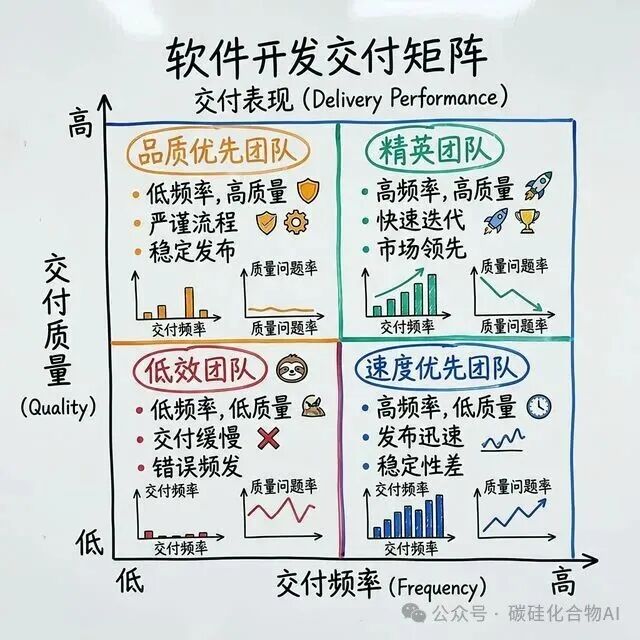
当你发现团队出包变慢时,第一反应是什么?是增加人手,还是在会议上催促进度?我曾经也掉进过同样的陷阱。我曾试图通过为每个冲刺(Sprint)设置更严格的截止日期来提速,结果呢?交付周期(Lead Time)没降下来,变更失败率(Change Failure Rate)反而直线飙升。
后来才明白,研发管理的本质不是监控个体的勤奋,而是识别整个系统的瓶颈。
这时,很多技术负责人会想到 DORA(DevOps Research and Assessment)指标。这个由 Google 主导的研发效能评估体系,确实像一盏明灯。它定义的四个核心指标——部署频率(DF)、交付周期(MLT)、变更失败率(CFR)和恢复时间(MTTR),堪称现代工程团队的“心电图”。
但问题在于实践。为了收集这些数据,你需要在 GitHub、Jira、Jenkins 等不同工具之间来回切换,导出、清洗、合并数据。等你手动把几百个 JSON 文件拼凑成一份 Excel 报表,两周时间已经过去了。这种严重滞后的“马后炮”指标,除了向上汇报,对日常的实时管理几乎毫无价值。
Apache DevLake:将数据碎片转化为标准化资产
就在我被这些碎片化数据折磨时,我遇到了 Apache DevLake。它不是一个简单的可视化看板,而是一个真正的“研发数据底座”。其核心魅力在于强大的数据“标准化”能力。
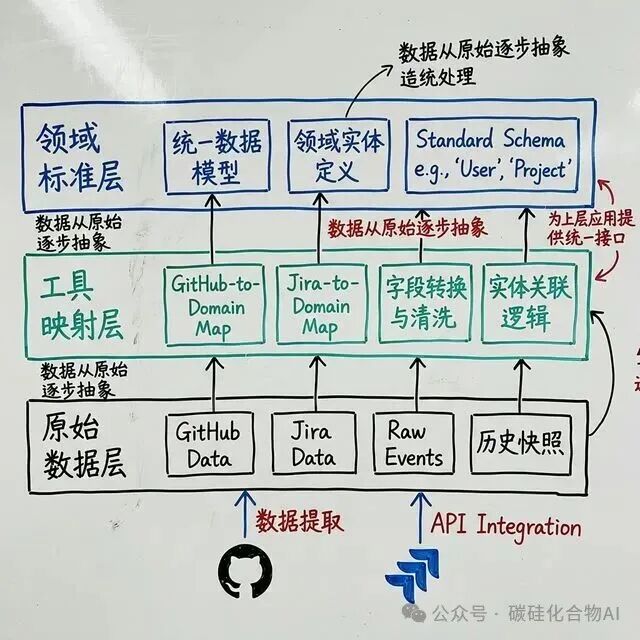
研究其架构后发现,DevLake 采用了严谨的三层数据模型,这简直是对工程管理流程的工业级拆解:
- Raw Layer(原始数据层):直接存储从各工具 API 获取的原始 JSON 数据。保留“原始现场”至关重要,即使未来度量逻辑发生变化,也无需重新拉取历史数据。
- Tool Layer(工具映射层):将原始 JSON 转换为关系型数据库表。例如,GitHub 的 PR 和 Jira 的 Story 会分别映射成不同的表。
- Domain Layer(领域标准层):这是 DevLake 的“灵魂”。它将 GitHub 的 Pull Request、GitLab 的 Merge Request 等不同工具的相似概念,统一抽象为标准实体,例如
pull_requests。
这意味着,无论你的团队混合使用了多少种工具,对于管理者而言,底层的数据逻辑和模型都是统一的。
标准化是自动化的前提,更是实现科学数据驱动的基石。
实战配置:从“盲打”到精准度量
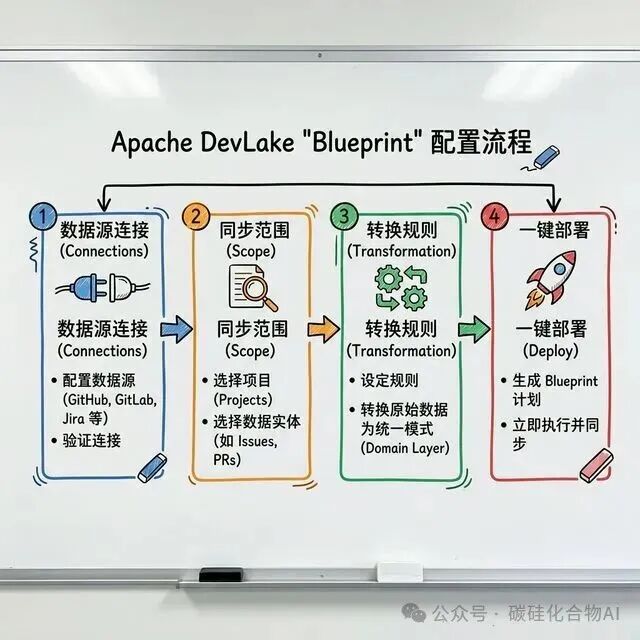
作为 Apache 基金会的顶级开源项目,DevLake 的配置对开发者相当友好。其核心配置概念是 Blueprint(蓝图)。
在配置界面中,你主要完成三件事:
- 设置 Connections:填入你的 GitHub Token、Jira API Key 等凭证。
- 定义 Scope:选择需要监控的具体代码仓库或项目看板。
- 配置 Transformation Rules:例如,将 Jira 中的“Bug”类型映射为 DevLake 领域模型中的“Incident”,这样变更失败率(CFR)指标才有了准确的统计依据。
配置完成后,由 Go 编写的高并发数据采集器(Collector)便会开始工作,能够快速处理数万条开发记录。
最令人省心的是其开箱即用的 Grafana 集成。DevLake 内置了针对 DORA 等指标的一套完整仪表盘。你无需编写任何 SQL,点击“部署”后,团队真实的效能“健康数据”便直观呈现。
研发效能不是靠“内卷”卷出来的,而是靠识别并修复系统瓶颈“修”出来的。
发现深层的系统瓶颈“报警”
接入 DevLake 大约一周后,真正的问题信号浮现了。数据显示,我们团队部署频率很高,但交付周期(Lead Time)存在严重的“长尾效应”。通过下钻分析发现,代码拉取请求(PR)从“提交”到“合并”的平均耗时竟高达48小时。
深入调查后,真相水落石出:代码评审(Code Review)的权限过于集中在少数几位核心专家手中,他们成了整个交付流水线的单一瓶颈。这根本不是“代码写得慢”的问题,而是“流程卡住了”的系统性问题。
基于这个洞察,我们没有指责任何开发者,而是通过调整评审策略和引入更强的自动化测试,成功将这一环节的平均耗时缩短到了4小时。这就是数据驱动决策的力量。
从“功能工厂”回归“价值引擎”
如果到了今天,技术管理者仍通过“是否看到大家加班”来判断团队效能,那可能真的落后于时代了。Apache DevLake 提供的不仅仅是一份报表,更是一份关于“研发正义”的契约:它让开发者免受无效度量的误伤,也让管理者告别在迷雾中的“裸奔”。
如果你也正困于研发管理的“数据盲区”,不妨尝试运行一下 Apache DevLake,生成属于你团队的第一份 DORA 效能报告。真正的改进,始于清晰的看见。那么,你的团队中,有哪些是明明存在却一直“无法量化”的系统瓶颈呢?欢迎分享你的观察。
本文涉及的技术实践与数据分析,正是高效能团队在 运维/DevOps/SRE 领域持续探索的核心。如果你对更多研发效能工具或方法论感兴趣,可以关注相关技术社区的讨论。
 发表于 2026-3-30 01:39:32
|
查看: 151|
回复: 0
发表于 2026-3-30 01:39:32
|
查看: 151|
回复: 0
