
近日,由 Mistral AI 开源的 Voxtral TTS 模型在 HuggingFace 上冲到了热门榜单前列,成为开发者社区热议的焦点。这是一个仅在40亿参数级别就实现了多语言语音生成 SOTA 性能的文本转语音模型。
它基于大规模语音数据集训练,专为全球化应用设计,支持包括英语、法语、德语、西班牙语、意大利语等在内的9种主流语言。凭借其小巧的参数量,基于 Voxtral 的语音助手能够以经济高效的方式,大规模生成自然、可靠的语音。
Voxtral TTS 的核心特点
Voxtral TTS 旨在为生产型语音代理提供企业级的文本转语音能力,具备以下突出功能:
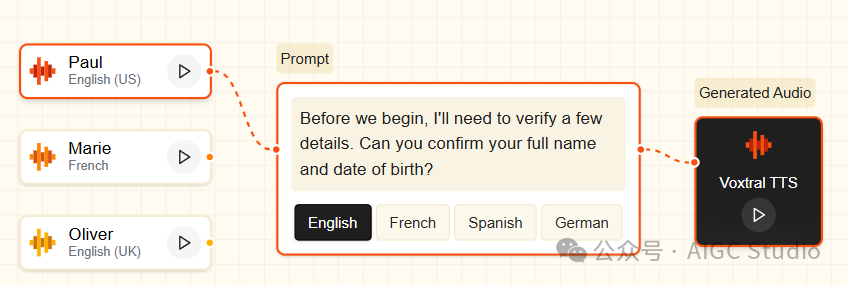
- 多语言与高表现力:支持9种语言的逼真、富有表现力的语音合成,具备自然的韵律和情感表达,并覆盖多种方言。
- 丰富的语音预设:提供20种预设语音,并且可以轻松适配新的说话人音色。
- 超低延迟与流式支持:具备极低的响应延迟,支持流式传输和批量推理,满足实时交互需求。
- 高品质音频输出:支持24 kHz采样率的音频输出,格式涵盖 WAV、PCM、FLAC、MP3、AAC 和 Opus。
- 生产就绪:专为高吞吐量、实时的语音代理工作流程优化,性能稳定可靠。
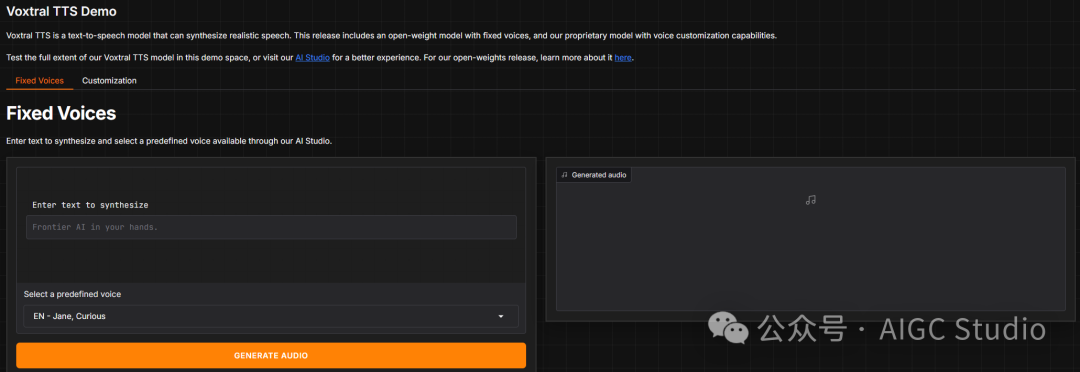
资源与链接
如果你想深入了解或立即体验,可以参考以下资源:
技术原理与方法概述

自然语音生成的关键在于模型不仅要能“读”文本,更要能“理解”文本。对话境(如中性、快乐、讽刺)的理解,直接决定了生成语音是自然准确还是机械生硬。Voxtral TTS 在语境理解和说话人建模方面表现卓越,能够捕捉特定人物自然的说话方式,包括其个性化的停顿、节奏、语调和情感。
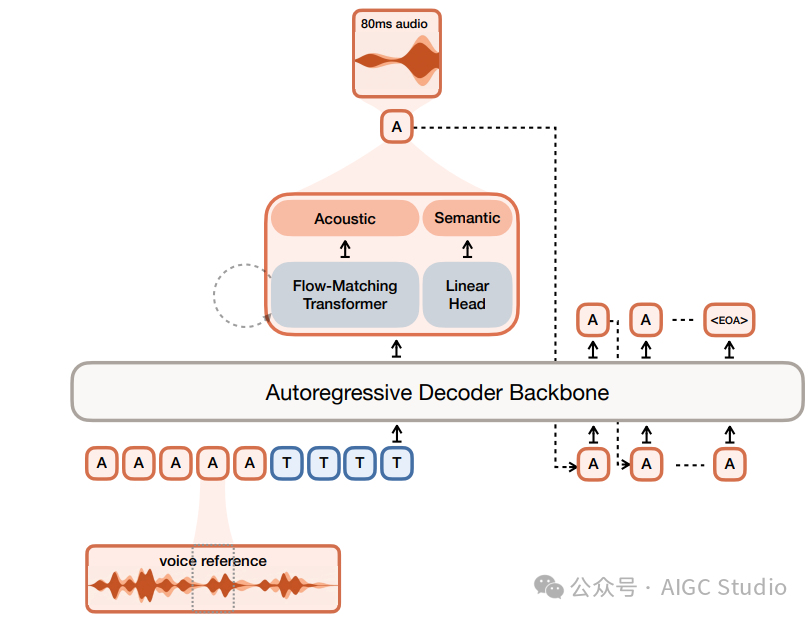
从技术架构上看,Voxtral TTS 是一个基于 Transformer 的自回归流匹配模型,其主干网络构建于 Ministral 3B 之上。整个模型由以下组件构成:
- 一个 34 亿参数的 Transformer 解码器主干网络。
- 一个 3.9 亿参数的流匹配声学 Transformer。
- 一个 3 亿参数的神经音频编解码器(对称的编码器-解码器结构)。
模型接收一段语音提示(5-25秒)和一段文本提示(支持9种语言)。对于每个音频帧,Transformer 主干网络会预测一个语义标记,随后流匹配 Transformer 会运行16次函数评估来生成声学潜在词元。
团队还专门开发了一套内部编解码器,它使用语义 VQ(8192大小的词表)和声学 FSQ(36维,21个量化级别)对音频进行因果处理,最终以 12.5 Hz 的帧速率生成高质量音频。
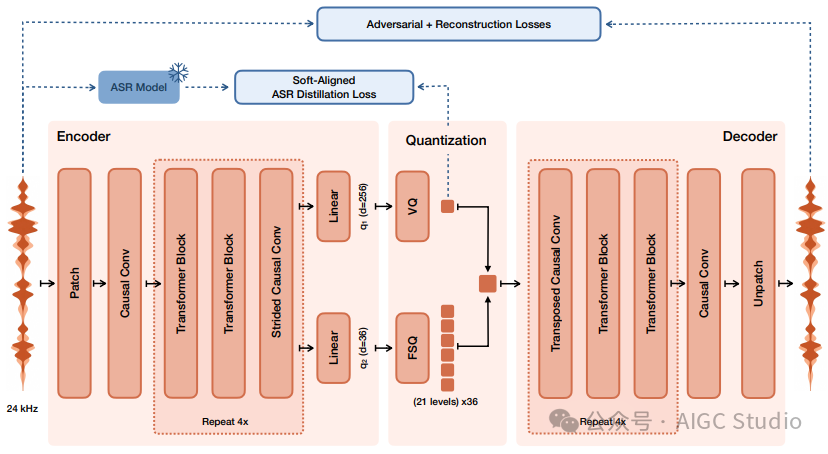
上图展示了 Voxtral 编解码器的架构和训练流程。它结合了语义 VQ 码本和声学 FSQ 码本,并将两者的标记结合起来进行音频重建。此外,语义标记的训练还引入了来自监督式自动语音识别模型的额外蒸馏损失,以提升其语义理解能力。
性能表现评估
在 人工智能 领域,尤其是多语言 TTS 系统中,像词错误率这样的自动化指标难以衡量语音最关键的属性——自然度。语音的自然感极其微妙,需要对文化差异和典型说话模式有深刻理解。因此,由母语者进行的对比评估至关重要。
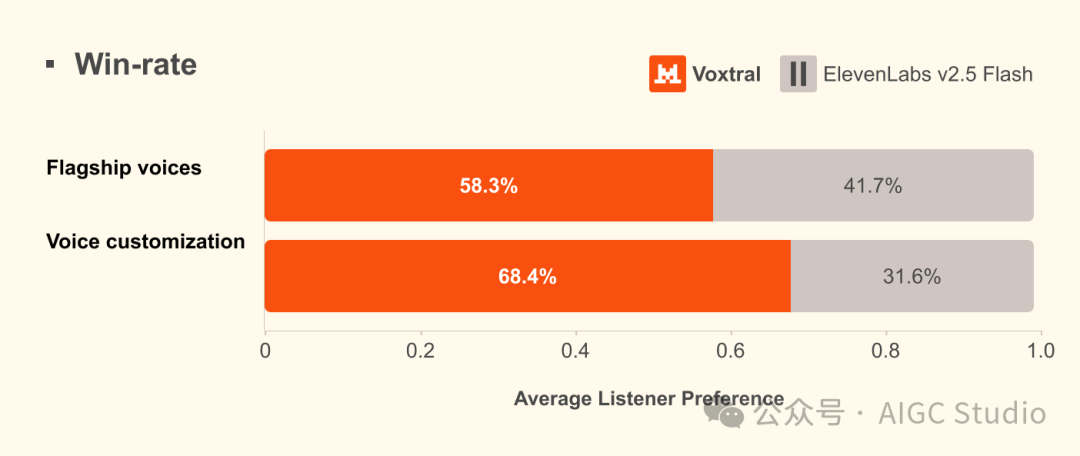
评估结果显示,Voxtral TTS 在“旗舰语音”和“语音定制”两个维度上,均显著超越了竞争对手 ElevenLabs v2.5 Flash 版本。对于语音代理而言,延迟和质量常常难以兼得。而人工评估表明,Voxtral TTS 在保持与 ElevenLabs Flash v2.5 相近的首次音频播放时间的同时,实现了更自然的语音效果。其整体性能可与 ElevenLabs v3 相媲美,并且成功支持了情感控制,为实现更逼真的人机交互体验提供了可能。
Voxtral TTS 的出现,为开发者和企业提供了一个参数小巧、性能强大、延迟低且易于定制的语音合成解决方案。无论是集成到语音助手、客服系统,还是用于内容创作,它都展现出了巨大的潜力。随着开源模型的发布,社区将能在此基础上进行更多探索和创新,推动语音交互技术向前发展。
|  发表于 2026-3-31 02:29:29
|
查看: 140|
回复: 0
发表于 2026-3-31 02:29:29
|
查看: 140|
回复: 0
