多轮检索增强生成(RAG)系统中的核心挑战之一,是如何智能地决定在推理过程中何时、以何种方式调用外部知识库。传统方法往往依赖于固定的规则或启发式策略,而 RouteRAG 则提出了一种全新的思路:将整个“推理-检索-生成”循环重新建模为一个序列决策过程,让模型自己学会一套高效的检索策略。
它摒弃了固定的手工流水线,转而训练模型在推理过程中使用特殊 Token 来动态触发检索动作。每一步,模型都可能生成一个动作 Token:继续在 ` 标签内进行内部推理、通过<search>...</search>发起一次检索,或是通过<answer>...</answer>输出最终答案。特别地,在<search>标签内部,模型需要使用[passage]、[graph]或两者组合(如[graph][passage]`)来明确指定本次检索所采用的模式。
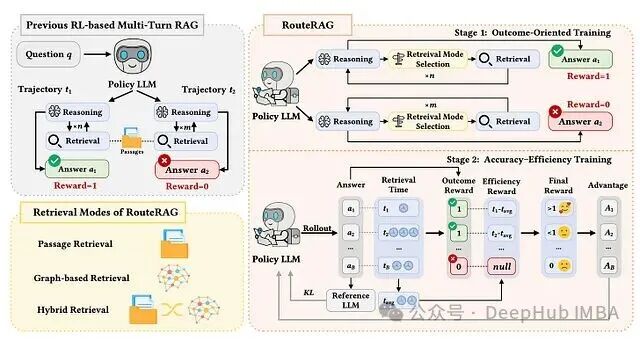
图 1:RouteRAG 模型架构与两阶段训练流程。左侧对比了传统基于强化学习的多轮 RAG 与 RouteRAG 的核心差异,右侧详细展示了其两阶段训练过程。
理解图1是把握全文的关键。早期基于强化学习的多轮 RAG 方法通常交替进行推理与段落检索,其奖励信号仅来源于最终答案的正确与否(结果奖励),并未对检索成本和效率进行显式优化。RouteRAG 则将检索模式扩展到了段落检索、图检索以及混合检索三种,并设计了一个基于 GRPO(Group Relative Policy Optimization)的两阶段训练框架:第一阶段专注于优化答案的正确性;第二阶段则引入根据总检索时间计算的效率奖励,旨在鼓励模型进行更有选择性、更高效的检索,同时不牺牲回答质量。
多轮工作流:核心是学习何时触发检索,而非编写复杂提示
策略模型 πθ 在预设的最大步数预算 B 内逐 Token 生成序列。一旦模型输出了 <search>...,系统便会从中解析出子查询 q′ 和检索模式 m ∈ {Passage, Graph, Hybrid},并将其传递给检索器 R。检索器返回的相关证据 d 会被包裹在 <information>...</information> 标签内,并回注到模型的上下文中,以供下一轮推理使用。当模型生成 <answer>...</answer> 标签后,整个问答流程便宣告终止。
在训练阶段,检索预算固定为 B=4,每次检索返回 k=3 个相关段落。这里需要注意,后文提到的 RRF 公式中的 k 是另一个平滑超参数,在符号上应加以区分。

图 2:策略模型(Policy LLM)的训练提示词模板,明确规定了检索动作的格式与三种模式的选择。
换言之,模型不再是盲目地猜测“要不要搜”和“搜什么”,而是通过学习来做出三类关键决策:何时发起检索、如何拆解和构建子查询,以及选用哪种检索模式(段落、图或混合)。这种将检索策略纳入学习范畴的方法,比静态指令更具灵活性和适应性。
三种检索模式:文本检索快,图谱检索深,混合模式取长补短
- 段落检索:采用经典的 DPR 风格稠密检索,将子查询与语料库中的所有段落编码到同一嵌入空间中,依据余弦相似度选取 top-k 最相关的段落。
- 基于图的检索:首先使用 HippoRAG 2 等方法从语料库中构建知识图谱。给定查询后,从图谱中相关的实体节点出发,执行个性化的 PageRank 算法,沿着多跳连接来搜集相关证据。这种方法在回答复杂、多跳问题时尤其有效。
- 混合检索:采用倒数排名融合(Reciprocal Rank Fusion, RRF)算法来合并上述两种检索路径的结果。其核心思想很直观:一个文档只要在任一检索模式的返回列表中排名靠前,它就会在最终的融合排名中获得加分。公式如下:
RRF(d) = ∑ over m ∈ {Passage, Graph} of [1 / (k + rank_m(d))]
通过这种机制,任一模式识别出的重要文档在融合后都不会被遗漏,实现了证据的互补。
两阶段强化学习:先学会答对,再学会答得快
RouteRAG 采用 GRPO 算法进行训练,该算法通过组内轨迹的比较来稳定学习过程,有效降低了稀疏奖励下的方差。
整个训练过程的关键在于奖励函数的设计:
-
第一阶段:面向结果的训练(Outcome-Oriented Training)
此阶段只关注答案的准确性。模型生成的答案若与标准答案完全匹配(Exact Match),则获得奖励 +1,否则为 0。目标简洁明了:让模型先学会给出正确答案。
-
第二阶段:准确率-效率训练(Accuracy-Efficiency Training)
在此阶段,只有那些答案正确的轨迹才会参与效率奖励的计算。效率奖励 R_efficiency 基于总检索时间 t 计算,公式如下:
R_efficiency = (t_avg - t) / T
其中,t_avg 是当前训练批次中所有正确轨迹的平均检索时间,T 是一个归一化常数,用于将时间差缩放到一个合适的区间。其含义非常明确:即使你答对了,但如果比同批次的其他样本慢,依然会受到惩罚(负奖励)。
最终的训练目标结合了裁剪后的策略比率和 KL 散度惩罚,并利用 GRPO 计算出的组相对优势 Aᵢ 来稳定梯度更新。在这种两阶段奖励的共同驱动下,策略模型倾向于选择那些既正确、检索次数又更少的轨迹,而不是依赖偶然发现的低效策略。
性能评估与主要发现
实验在五个经典的问答数据集上进行评估:PopQA、Natural Questions (NQ)、HotpotQA、2WikiMultihopQA (2Wiki) 和 MuSiQue。评估指标采用精确匹配(EM)和 F1 分数,结果按简单问答(PopQA, NQ)和多跳问答(HotpotQA, 2Wiki, MuSiQue)进行分组报告。
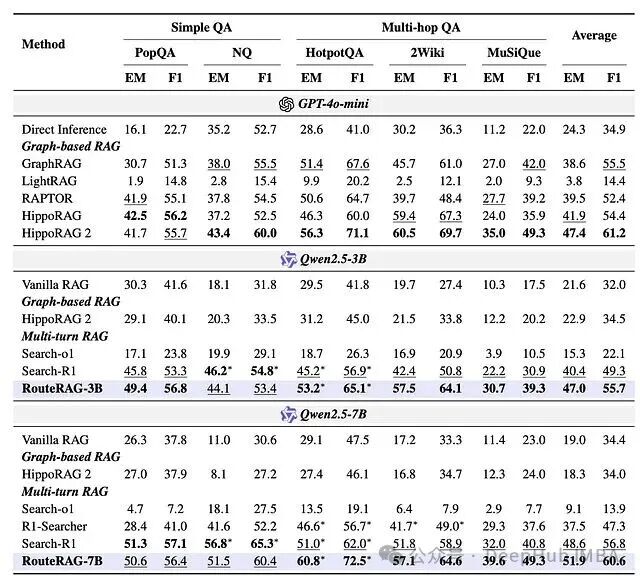
图 3:RouteRAG-3B/7B 与多种基线方法在五个数据集上的性能对比(EM/F1)。
主要发现如下:即使骨干模型仅为参数量较小的 Qwen2.5–3B-Instruct 和 Qwen2.5–7B-Instruct,RouteRAG 在多跳问答任务上依然带来了显著的性能提升,并拉高了整体平均分数。其多跳问答成绩接近甚至在某些指标上超过了基于强大模型 GPT-4o-mini 的图 RAG 基线系统。不过,在相对简单的问答任务上,为了追求更高的效率和复杂的策略学习,模型在准确率上做出了一定的让步。
案例研究:策略学习如何修正错误

图 4:训练前后模型对同一问题的回答逻辑对比。训练前模型依赖内部知识产生幻觉,训练后则能通过有策略的检索一步步找到正确答案。
图 4 清晰地展示了训练前后模型的决策变化。在训练前,模型完全依赖其内部知识产生了“幻觉”:错误地认为演员 Johnny Pemberton 是在电视剧 That ‘70s Show 中扮演 Bo Thompson,并错误地将该剧的创作者归于 Steven Molaro。经过训练后,RouteRAG 模型不再犯此类错误。它学会将复杂问题“谁创作了 Johnny Pemberton 扮演 Bo Thompson 的那部 NBC 情景喜剧?”拆解为多个子步骤:首先检索确定剧集名称(Superstore),然后检索该剧的创作者。通过这种有策略、分步的检索,模型最终正确识别出 Justin Spitzer 才是真正的答案。
总结与思考
RouteRAG 的核心贡献在于,它将“推理—检索—生成”这一复杂循环统一为一个单一、可学习的策略。模型能够自主决定:检索什么内容(段落、图还是混合)、在什么时刻输出最终答案(受最大步数预算 B 约束)。通过基于 GRPO 的两阶段强化学习框架,该策略在答案准确性和检索效率之间取得了良好平衡。
最值得关注的或许不是它又为 RAG 增添了一个新模块,而是它成功地将“何时检索信息”和“何时给出最终答案”这些关键决策纳入了模型的学习范畴,而不是写死在僵化的规则里。一个直观的数据支持是:对比不使用效率奖励的变体,加入效率奖励后的 RouteRAG-7B 将平均检索轮次从 2.70 显著降低到了 2.25,而整体 F1 分数并未下降。

图 5:RouteRAG-3B/7B 在有/无效率奖励条件下的平均检索轮次(Avg. Turns)与平均 F1 分数(Avg. F1)对比。
当然,任何新方法在迈向实际部署时都可能面临挑战。RouteRAG 主要有两个潜在的隐忧:
- 泛化能力:当前实验仅基于 3B 和 7B 参数量级的模型,且图检索部分统一使用了 HippoRAG 2 构建知识图谱。这套学习到的路由策略如果迁移到更大的模型或完全不同的图谱构建流水线上,其表现如何尚无数据支撑。在生产环境中,知识图谱的质量和覆盖范围可能动态变化,这可能导致检索规划器的行为发生不可预测的漂移。
- 奖励设计的潜在偏差:RouteRAG 以批次平均检索时间为基准来鼓励效率,论文认为这有助于降低噪声、稳定训练。然而,这是否会系统性地“歧视”那些耗时更长但有时必不可少的图检索路径?论文并未直接验证这一风险。对于某些复杂的长尾多跳问题,深入的图推理往往是不可或缺的。尽管 RouteRAG 的设计机制(仅对正确轨迹施加效率奖励 + GRPO 的组内相对比较)在理论上鼓励的是“选择性”检索而非单纯求快,但它无法绝对保证那些“慢而必要”的图检索路径总能被优先选中。
总体而言,RouteRAG 为构建更智能、更高效的检索策略提供了一条富有前景的研究路径。它将强化学习与 RAG 深度融合,让模型不仅是知识的利用者,更是检索过程的规划者。对这类技术细节的深入探讨,正是 云栈社区 所鼓励和关注的。
论文链接:https://arxiv.org/pdf/2512.09487v1
 发表于 2026-3-31 03:50:31
|
查看: 142|
回复: 0
发表于 2026-3-31 03:50:31
|
查看: 142|
回复: 0
