从 Hacker News 的热帖到 arXiv 的前沿论文,从专利数据到最新的技术书籍——你是否也在信息洪流中感到焦虑?这正是我决定动手构建 tect-brain 的初衷:一个本地优先、AI 驱动的技术情报雷达系统。它能自动聚合多源信息,构建知识库,并通过 RAG 对话和量化分析帮你洞察技术趋势。
系统设计的核心,源于一个朴素的观察:技术人的信息焦虑,本质上是缺乏一个系统化的情报处理管道。 tect-brain 就是为了填补这个空白,它跑在你的本地机器上,自动抓取、分析并预测,让碎片化的信息变得可追踪、可分析。
让我们先通过几个实际场景,看看它能做什么。
核心能力与应用场景
除了基础的 CLI,我还为 tect-brain 开发了一个 Tauri 桌面客户端,它提供了数据总览、多源同步控制、话题监控、对话界面和 Markdown 报告导出等完整功能。
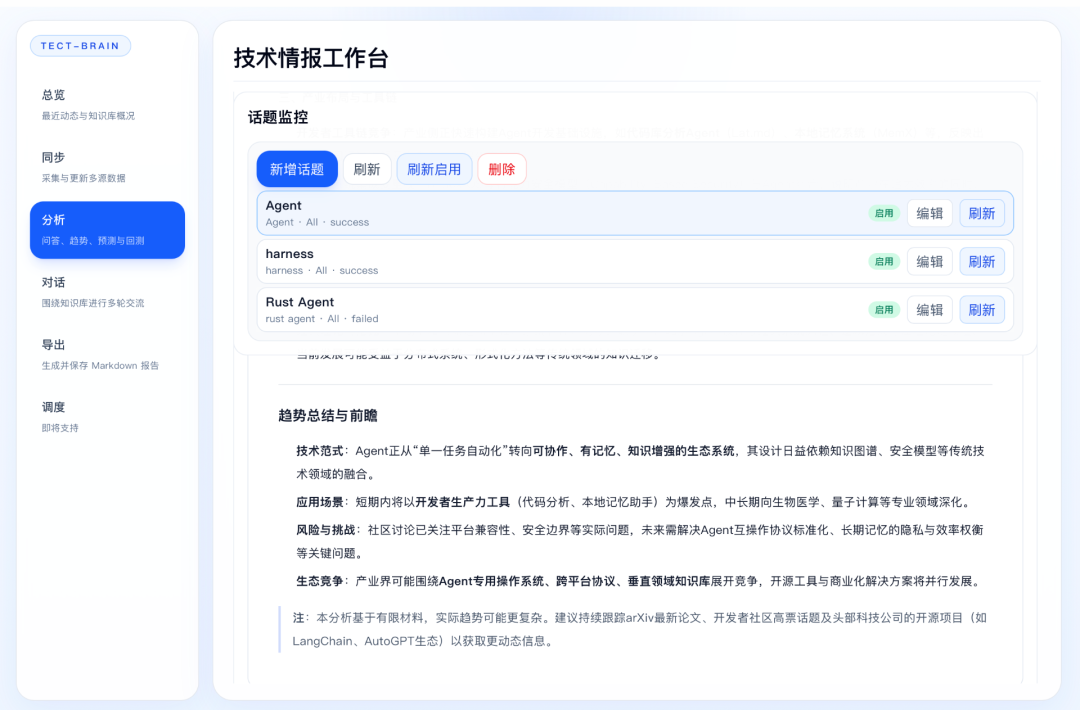
场景 1:早间技术简报
每天开工前,一句命令就能获取结构化的技术动态摘要。
cargo run -- digest
系统会从本地知识库中提取近期内容,按主题分类,输出一份带摘要、分来源(社区讨论 / 论文 / 专利 / 图书)的整理报告,而不是简单的链接罗列。
场景 2:趋势预测与回测
当你好奇“Rust 在 AI 基础设施领域的热度趋势如何?”时,可以直接进行预测。
cargo run -- forecast “rust ai infrastructure”
系统会跨越 HN、arXiv、专利、技术书籍四个维度,统计关键词在不同时间窗口的出现频率变化,给出置信度分级(Low / Medium / High)的预测,并判断其处于 emerging、accelerating、plateauing 还是 declining 阶段。
更严谨的是,所有预测都可以进行回测验证。
cargo run -- backtest “rust ai infrastructure”
通过对比“当前窗口”和“前一个同等长度窗口”的数据变化,计算出实际变化量,验证预测模型的准确性,并分析哪个数据源最先发出信号。
场景 3:与知识库对话
进入多轮对话模式,你的每个问题都会基于本地知识库生成回答。
cargo run -- chat
提问会先经过向量检索找到最相关的本地文章,再送入 LLM 生成回答。所有回答都有据可查,最大程度减少“幻觉”。
数据管道:捕获技术生命周期的不同信号
一条技术信息从产生到被广泛认知,会经历很长的传播链。tect-brain 的策略是在链条的不同关键位置设置“探针”,我目前选择了四个代表性的数据来源:
┌─────────────────────────────────────────────────────────┐
│ 技术信号来源 │
├──────────┬──────────┬──────────┬────────────────────────┤
│ HN 热帖 │ arXiv │ 专利数据 │ 技术书籍 │
│ (社区讨论) │ (学术前沿) │ (产业落地) │ (知识沉淀) │
└────┬─────┴────┬─────┴────┬─────┴───────────┬────────────┘
│ │ │ │
▼ ▼ ▼ ▼
┌─────────────────────────────────────────────────────────┐
│ 统一 stories 表 (SQLite) │
│ source | title | url | score | published_ts | ... │
└────────────────────────┬────────────────────────────────┘
│
embed + index
│
▼
┌─────────────────────────────────────────────────────────┐
│ Qdrant 向量集合 │
│ payload: { source, title, url, hn_score } │
└─────────────────────────────────────────────────────────┘
这四个来源并非随意选择,它们分别代表了技术生命周期的不同阶段:
- Hacker News:代表社区讨论,是最早的“弱信号”。一个技术开始被频繁提及,往往意味着开发者群体的关注度在上升。
- arXiv 论文:代表学术前沿。当一个方向的论文密度显著增加,说明研究资源正在向其倾斜。
- 专利数据:代表产业落地。公司为一个技术方向申请专利,是真金白银的投入信号,意味着正从概念走向实践。
- 技术书籍:代表知识沉淀。当出版社开始为一个主题体系化出书,说明该技术已发展到相对成熟的阶段。
这四个信号叠加,能够描绘出一条技术从 “emerging” 到 “maturing” 的完整轨迹。所有数据都被规范化到同一张 stories 表中,通过 source 字段区分,并使用统一的 published_ts 时间戳,这是进行跨源时间分析和趋势预测的基础。
爬虫层设计:各司其职的数据抓取器
为了从上述四个来源高效获取数据,我设计了四个独立的爬虫模块。
HN Crawler:并发与增量同步
调用 HN 的 Firebase API 获取 topstories 列表,然后使用 Tokio 信号量控制并发,抓取每条 story 的详情。评论采用可控深度的 BFS 展开。
关键设计是增量同步:已存在的文章不会重复写入或计为“新增”。这对后续的趋势统计至关重要,避免了因重复计数导致的趋势失真。
arXiv Crawler:轻量级 XML 解析
arXiv 的导出 API 返回 Atom/XML 格式。为了减少依赖和保持轻量,我选择手写一个轻量级解析器。虽然对 XML 格式变更更敏感,但 arXiv 的 API 格式已稳定多年,这个权衡是可接受的。
Patent Crawler:对接官方 API
直接对接美国专利局的 PatentsView 搜索 API,通过 POST 请求查询并解析结构化的专利元数据,数据权威且格式规范。
Book Crawler:适配器模式的应用
书籍爬虫采用了经典的适配器模式,支持两种抓取策略,是设计上最有意思的部分:
BookClient::search_publisher(publisher)
│
▼
publisher_adapter(key)
│
┌────┴────────────────┐
▼ ▼
ManningDirect GoogleBooksFallback
(专用适配器) (通用回退)
│ │
▼ ▼
抓取 Manning 页面 Google Books API
解析 JSON-LD + publisher: 过滤
对于 Manning 这类特定出版社,有专用适配器直接抓取其网站并解析 schema.org 的 JSON-LD 数据。对于其他出版社(如 O‘Reilly、Packt),则暂时回退到 Google Books API 并按出版商字段过滤。这种设计使得新增出版社适配器只需修改路由逻辑,不影响整体架构。
向量化与检索:本地优先的 RAG 管道
出于成本与隐私考虑,tect-brain 的 RAG 管道严格遵循本地优先原则:
用户提问
│
▼
Ollama embed (nomic-embed-text) ← 本地运行,零成本
│
▼
Qdrant 相似度检索 (top_k=5)
│
▼
格式化上下文:
- [hn] Building a Rust Compiler (https://...) [relevance: 0.87]
- [arxiv] Efficient LLM Inference with... (https://...) [relevance: 0.82]
│
▼
注入 LLM system prompt + 用户问题
│
▼
DeepSeek / OpenAI 兼容 API 生成回答
这里有几个关键的设计决策:
- Embedding 与 LLM 解耦:Embedding 使用 Ollama 在本地运行
nomic-embed-text 模型,零成本、零延迟且完全隐私。而 LLM 推理则可以根据需求灵活选用 DeepSeek 或其他任何 OpenAI 兼容的 API,兼顾了效率与灵活性。
- SQLite 为真相源:SQLite 数据库是唯一的真相源,Qdrant 向量库只是一个派生的索引。如果向量数据丢失或需要更换 Embedding 模型,都可以从 SQLite 完整重建。这个原则保证了系统的健壮性和可维护性。
- 巧妙的 ID 管理:为了避免 Hacker News 的 story 和 comment 在共用向量集合时发生 ID 冲突,comment 的向量 ID 被设置为
comment.id + 10_000_000_000。对于 arXiv、专利等来源的字符串 ID,则通过 FNV-1a 哈希算法将其映射为 i64 整数。
趋势预测:基于统计,而非玄学
系统的趋势预测功能不是让 LLM 凭空猜想,而是建立在量化统计的基础上,再用 LLM 生成叙述性解读。
forecast “rust”
│
▼
SQLite 关键词搜索 → 匹配记录
│
▼
按 source 分组统计:
- HN: 42 条 (近期 28, 较早 14)
- arXiv: 15 条 (近期 11, 较早 4)
- patent: 3 条 (近期 2, 较早 1)
- book: 8 条 (近期 6, 较早 2)
│
├─→ compute_stage() → “accelerating”
├─→ compute_confidence() → “High”
│
▼
Agent::forecast(统计数据 + 样本列表)
│
▼
LLM 输出:一句话结论 + 阶段判断 + 6-12月预测 + 不确定性
- 置信度计算:
compute_confidence 是一个纯规则函数,综合考虑匹配总数、多源覆盖度以及近期与远期数据的变化幅度。
- 阶段判断:
compute_stage 使用启发式规则,例如,仅有社区讨论可能处于 emerging 阶段;论文和专利开始出现可能意味着 accelerating;而书籍大量出版则可能标志进入 maturing 期。
预测必须可证伪,因此 backtest 功能至关重要。它能告诉你之前的预测是否准确,以及哪个数据源是领先指标(source_leading_signal)。例如,如果 arXiv 论文密度在 90 天前就开始上升,而 HN 讨论最近才跟上,这可能意味着学术探索正在向工程实践扩散。
话题管道:自动化的持续监控分析
除了单次查询,你还可以创建“话题”进行持续监控。系统会自动运行完整的分析流水线:
run_topic_pipeline(“Rust Agent”)
│
├─→ trend_topic() → 趋势分析报告
├─→ digest_topic() → 相关内容摘要
├─→ forecast_topic() → 预测报告
└─→ backtest_topic() → 回测报告
│
▼
所有报告写入 topic_reports 表
可在桌面端查看历史快照
每次数据同步后,可以自动触发所有已启用话题的更新。这意味着你早上打开电脑,前一夜的新数据已经被消化,每个关注话题的最新报告已然就绪。
从 CLI 到 GUI:共享核心库的桌面端
CLI 是高级用户的利器,但日常使用需要一个更友好的界面。我使用 Tauri 构建了桌面客户端,前端采用 React + TailwindCSS。
在架构上,桌面端与 CLI 共享同一个 Rust lib 库。Tauri 的 command 直接调用 services::* 模块中的函数,实现了业务逻辑的零重复:
┌──────────────┐ ┌──────────────┐
│ CLI (main) │ │ Tauri (lib) │
└──────┬───────┘ └──────┬───────┘
│ │
└───────┬───────────┘
│
┌──────▼──────┐
│ services │ ← 统一的业务编排层
├─────────────┤
│ storage │ ← SQLite + Qdrant
├─────────────┤
│ crawler │ ← 多源爬虫
├─────────────┤
│ ai │ ← Embedding + RAG + LLM
└─────────────┘
桌面端提供了总览、同步、分析、对话、导出等核心视图,所有功能都通过 Rust 后端驱动,确保了跨平台的一致性和高性能。
技术选型背后的思考
每一个技术选择都经过了仔细权衡:
| 选择 |
理由 |
| Rust |
卓越的性能、优秀的依赖管理(Cargo)、可编译为单二进制文件。CLI 与 lib 库的代码复用天然契合。 |
| SQLite |
本地优先理念的绝配,零运维、嵌入式,rusqlite 的 bundled feature 使得部署无需外部依赖。 |
| Qdrant |
成熟的向量数据库,Docker 一键启动,gRPC 客户端性能出色,社区活跃。 |
| Ollama |
本地运行 LLM/Embedding 推理,完美契合个人知识库场景对隐私和安全的需求。 |
| Tauri |
相比 Electron,应用体积小得多,且后端天然复用 Rust 代码,资源占用低。 |
| clap |
Rust 生态中最成熟、体验最好的 CLI 框架,derive 宏让定义命令变得简单直观。 |
| DeepSeek 兼容 API |
性价比高,中文理解能力强,采用通用的 OpenAI 兼容格式,易于切换和集成。 |
项目结构与设计感悟
核心的 Rust 代码大约 3500 行,结构清晰:
src/
├── main.rs # CLI 入口:命令分发、调度循环、REPL
├── lib.rs # 库入口:供 Tauri 引用
├── cli.rs # 命令定义 (clap derive)
├── config.rs # 配置加载 (config.toml + .env)
├── services.rs # 业务编排:sync、forecast、backtest、topic pipeline
├── ai/ # AI 相关模块
├── crawler/ # 爬虫模块
└── storage/ # 存储模块 (SQLite + Qdrant)
在开发过程中,我获得了几点重要的设计感悟:
- “预测”必须可回测:预测系统最忌“事后诸葛亮”。内置的
backtest 机制让每一次预测都能被未来数据验证,形成反馈闭环,驱动模型持续优化。
- 关键词统计与语义检索各司其职:一个反直觉但关键的设计是,趋势预测 (
forecast/backtest) 不使用向量检索,而是直接使用 SQLite 进行关键词匹配。因为趋势关心的是“出现频率”,SELECT COUNT(*) WHERE title LIKE ‘%rust%’ 在此场景下比向量检索更直接、更可解释。语义理解的任务则留给 RAG 问答模块。
- “本地优先”是优势而非妥协:对于个人技术情报系统,本地优先是最合理的选择。它确保了隐私(你的技术关注点本身就是敏感信息)、成本可控(本地Embedding,按需调用LLM API)、完全可控(SQLite文件可备份、迁移、版本管理)以及离线可用(核心分析功能无需联网)。
后续演进方向
tect-brain 仍在积极迭代中,未来的计划包括:
- 接入 GitHub Trending 数据,补全开源项目维度的信号。
- 开发更多出版社(如 O’Reilly、Packt)的专用爬虫适配器。
- 建立预测校准机制,利用历史回测数据自动调整置信度模型。
- 开发基于
ratatui 的终端仪表盘,满足终端爱好者的需求。
- 实现 MCP Server,让 tect-brain 的能力可以直接被各类 AI Agent 调用。
结语
归根结底,tect-brain 的目标不是取代你的技术判断力,而是充当你的技术情报参谋。它帮助你将噪音转化为信号,将碎片信息组织为可分析的数据,将主观的“感觉”转化为可量化、可验证的趋势洞察。
在这个信息过载的时代,构建一套属于自己的信息处理系统,或许是一种有效的应对之道。正如在 云栈社区 的交流中常提到的,主动管理信息流,而非被其淹没,是保持技术敏锐度的关键。如果你也对如何利用 Rust 构建高效工具感兴趣,或者想了解更多的 开源实战 经验,不妨深入探索一下。
项目已开源,你可以在这里找到它:https://github.com/coder-brzhang/tect-brain
最后,不妨用 tect-brain 试着回答一下这个问题:“你最近关注的那个技术方向,它现在究竟处于什么阶段?”
 发表于 2026-3-31 04:29:24
|
查看: 130|
回复: 0
发表于 2026-3-31 04:29:24
|
查看: 130|
回复: 0
