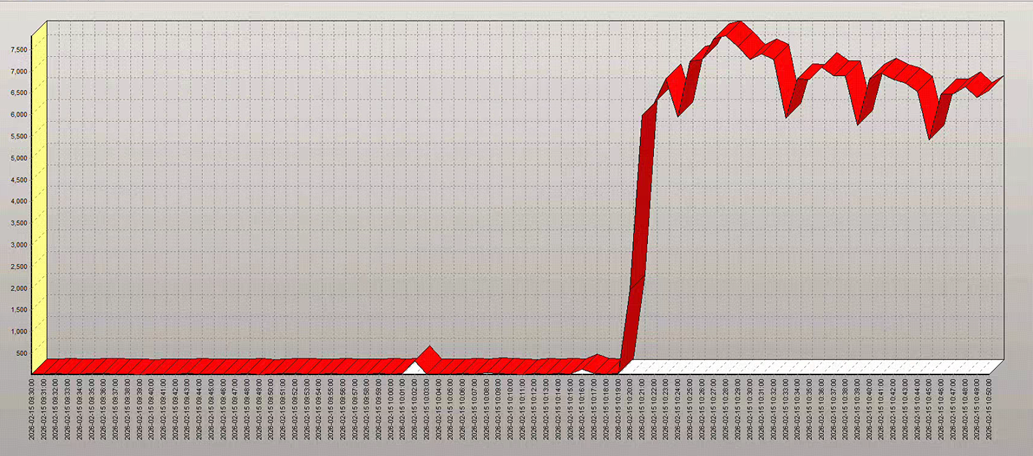
客户反馈数据库性能出现异常。根据ASH(Active Session History)数据显示,从2026-02-15 10:20开始,系统出现大量异常等待,导致INSERT操作无法正常执行,需要紧急分析并处理。
问题分析
首先,我们从数据库的ASH监控数据入手。数据显示,自10:20起,等待事件数量激增,其中最为突出的几个等待事件为:
enq: TX - row lock contentionenq: TX - index contentionlatch: ges resource hash list
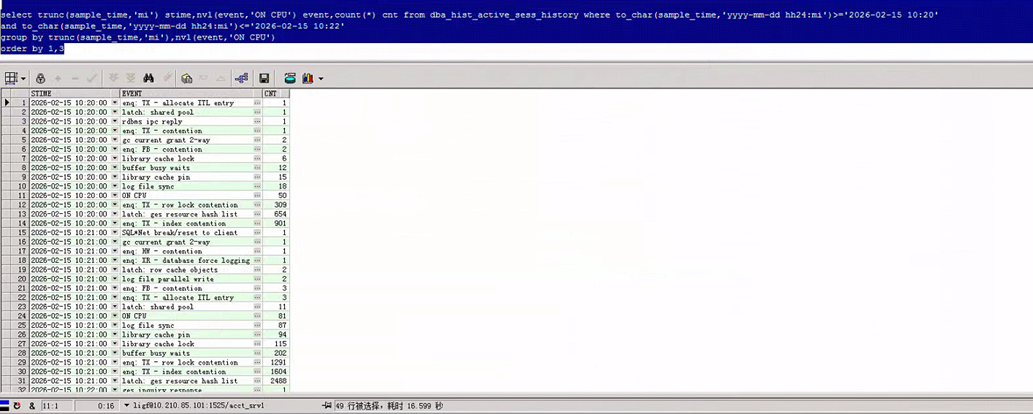
以下是具体时段的ASH数据抽样:
select trunc(sample_time,'mi') stime,nvl(event,'ON CPU') event,count(*) cnt
from dba_hist_active_sess_history
where to_char(sample_time,'yyyy-mm-dd hh24:mi')>='2026-02-15 10:20'
and to_char(sample_time,'yyyy-mm-dd hh24:mi')<='2026-02-15 10:22'
group by trunc(sample_time,'mi'),nvl(event,'ON CPU')
order by 1,2
这些等待事件分别指向了不同层面的问题:
enq: TX - row lock contention:大量事务在等待行锁。这通常由热点数据更新、批量操作、大事务未提交或唯一索引冲突引发。enq: TX - index contention:这通常意味着热点索引块冲突,尤其是在使用单调递增键值(如序列SEQ.NEXTVAL)作为索引键时,所有插入都集中在索引结构的“最右”位置。latch: ges resource hash list:这是Oracle RAC环境下特有的latch等待,表明GES(全局锁服务)的资源哈希桶发生了严重冲突。简单来说,当TX队列(事务锁)风暴爆发时,全局锁管理系统被“打爆”了。
综合来看,这很可能是由高并发引起的连锁问题。为了进一步定位,我们需要分析具体的阻塞关系。
阻塞链分析
查询阻塞链,我们发现:
- 被阻塞方:执行形如
SELECT ... FROM ACCOUNT FOR UPDATE的会话,它们正在等待enq: TX - row lock contention事件。
select sql_opname,sql_id,current_obj#,sql_plan_operation,event,blocking_session,blocking_session_serial#,blocking_inst_id
from dba_hist_active_sess_history
where event in('enq: TX - index contention','enq: TX - row lock contention')
and to_char(sample_time,'yyyy-mm-dd hh24:mi:s')='2026-02-15 10:27'
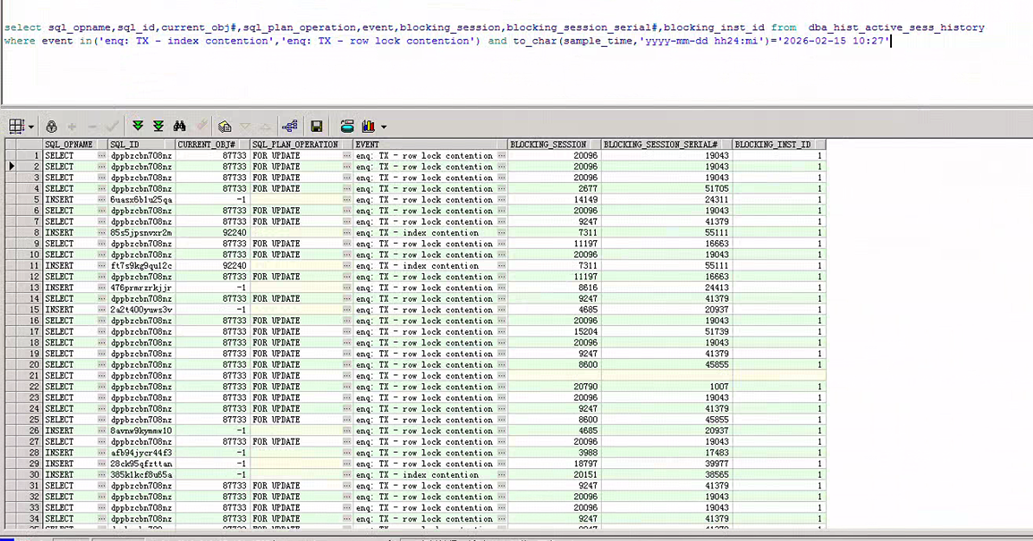
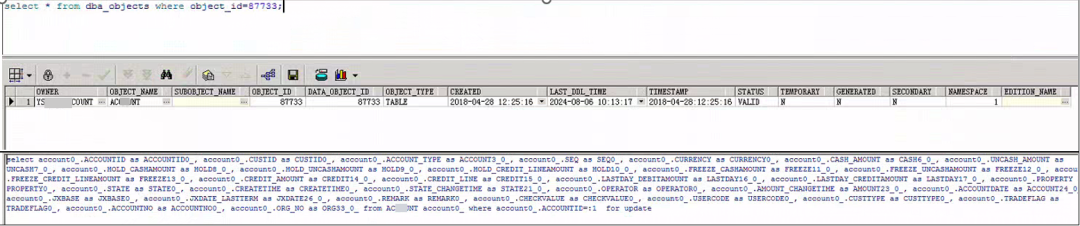
被阻塞会话等待的对象ID为87733,经查询是ACCOUNT表。
select * from dba_objects where object_id=87733;
- 阻塞方:当前正在执行
INSERT INTO SUBXXX_LOG0215的会话。通过ASH历史进一步查询阻塞会话的活动,发现其当前对象指向PK_SUBXXX_LOG0215。
select sample_time,sql_id,sql_opname,sql_exec_start,event,current_obj#,blocking_session,blocking_session_serial#
from dba_hist_active_sess_history
where to_char(sample_time,'yyyy-mm-dd hh24:mi')='2026-02-15 10:27'
and session_id=20096;

查询PK_SUBXXX_LOG0215的详细信息,确认其为SUBXXX_LOG0215表上的主键索引。
select * from dba_objects where object_id=92240;
-- 以及获取索引DDL
select dbms_metadata.get_ddl('INDEX', 'PK_SUBXXX_LOG0215') from dual;
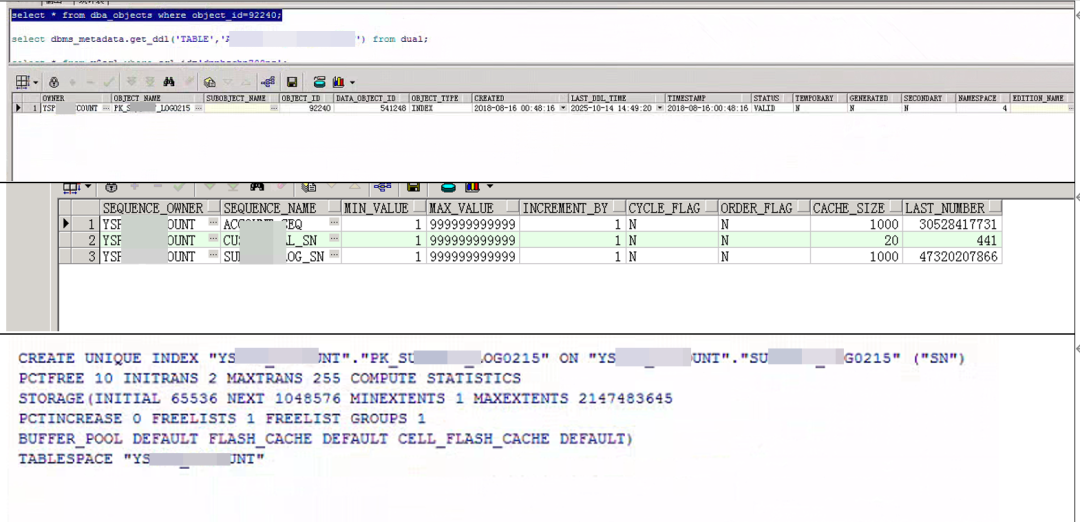
热点对象确认
检查数据库中的热点块,发现在问题时段,对象ID 92240(即PK_SUBXXX_LOG0215)是主要的buffer busy waits等待对象。
select trunc(sample_time,'mi') time, nvl(event,'ON CPU') event,current_obj#
from dba_hist_active_sess_history
where to_char(sample_time,'yyyy-mm-dd hh24:mi')>='2026-02-15 10:00'
and to_char(sample_time,'yyyy-mm-dd hh24:mi')<='2026-02-15 10:50'
and event like '%buffer busy%'
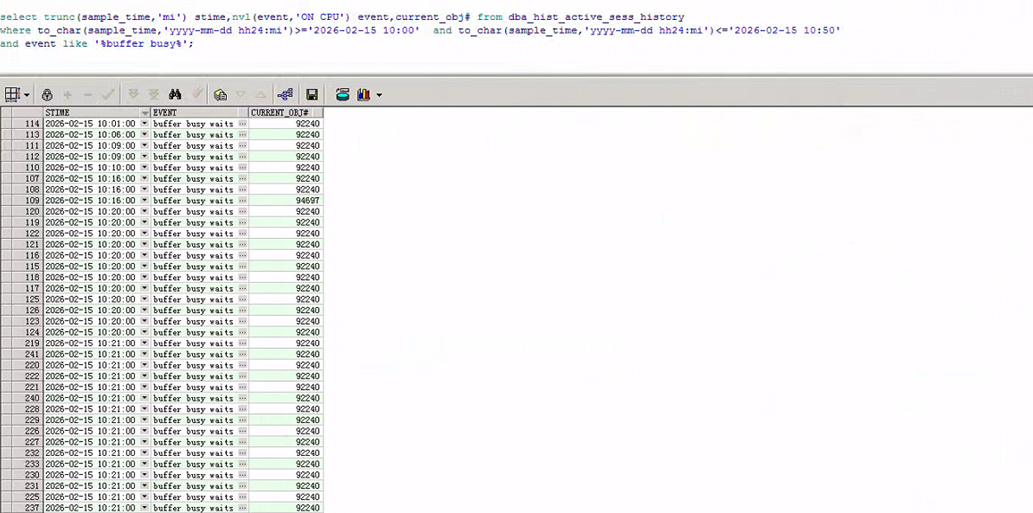
至此,问题根源已经清晰。阻塞链的源头是PK_SUBXXX_LOG0215索引。这是一个典型的因索引结构引发的高并发右边界热点问题。
问题机理总结:
SUBXXX_LOG0215表的主键索引PK_SUBXXX_LOG0215使用了单调递增的序列值(如SN列)。- 在高并发
INSERT场景下,所有新数据都试图插入到B-Tree索引“最右边”的叶子块中。
- 这导致所有并发事务都在竞争同一个或少数几个索引块,引发
enq: TX - index contention(索引块争用)。
- 索引块争用导致
INSERT事务执行时间变长,使其持有的行锁(对ACCOUNT表的更新?)长时间不释放。
- 进而引发了大量的
enq: TX - row lock contention(行锁争用)。
- 在RAC环境中,大量
TX队列的传播和协调最终导致了latch: ges resource hash list的全局锁服务过载。
解决方案
针对这类因单调递增索引导致的右边界热点问题,一个有效的解决方案是将主键索引修改为反向索引。
前提条件:业务查询中,如果几乎没有使用SN列进行范围查询(如BETWEEN, >, <),或者即使使用反向索引后范围查询的性能仍可接受。
实施步骤:
- 评估业务SQL,确认修改索引类型不会对现有查询产生重大性能影响。
- 在业务低峰期,使用
ONLINE选项重建索引为反向索引。
ALTER INDEX PK_SUBXXX_LOG0215 REBUILD REVERSE ONLINE;
原理:反向索引会颠倒索引键值的字节顺序。这样,即使主键值是顺序增长的,其在反向索引中的存储位置也会被“打散”,分布到不同的索引块中,从而避免所有插入集中竞争同一个右边界块,从根本上缓解热点问题。
这个案例展示了在Oracle,尤其是RAC架构下,一个设计不当的索引如何在高压力下引发从索引争用、行锁堵塞到全局锁服务风暴的连锁反应。深入的诊断和针对性的优化是保障数据库稳定性的关键。更多关于高并发场景下的数据库调优案例,欢迎在云栈社区交流探讨。
 发表于 2026-3-31 05:20:55
|
查看: 109|
回复: 0
发表于 2026-3-31 05:20:55
|
查看: 109|
回复: 0
