实测下来,最直观的感受就是:它终于能像一个真正的同事一样,跟我开着视频会议讨论正事了。
无论是根据视频画面生成代码,还是解读复杂的学术论文,亦或是拆解电影预告片,它都能轻松应对。这简直就是一个现成的生产力利器。

根据官方介绍,Qwen3.5-Omni实现了真正的“全模态”原生能力。它能无缝理解文本、图像、音频及音视频输入,并生成带精确时间戳的音视频脚本。模型提供了 Plus、Flash、Light 三种尺寸,支持256K上下文与113种语言识别,单次可处理长达10小时的音频或1小时的视频内容。
在性能基准测试上,Qwen3.5-Omni的表现也相当抢眼,一举拿下了 215项SOTA(State-of-the-Art),整体成绩与谷歌的Gemini 3.1 Pro不相上下。
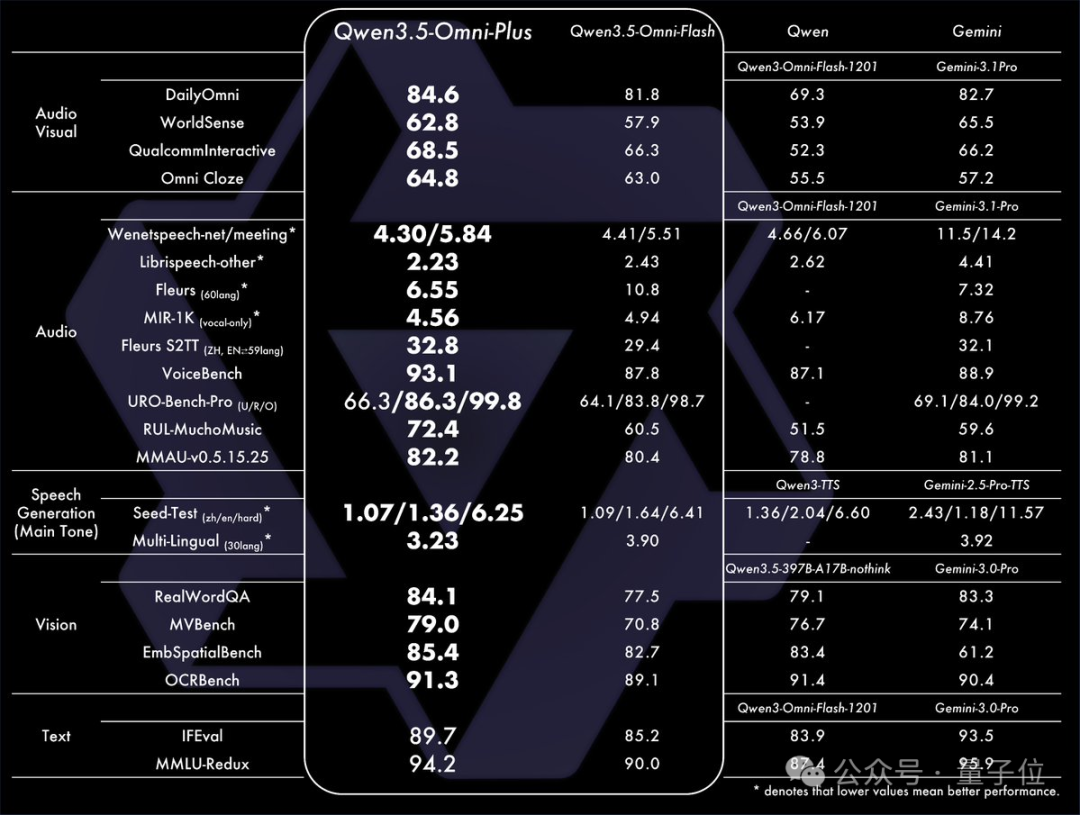
具体来看,在通用音频理解、推理、识别、翻译、对话等多个维度上,它已经全面超越了Gemini-3.1 Pro,音视频理解能力总体上达到了同级水平。而在视觉和文本能力上,则与同尺寸的Qwen3.5模型保持了一致。
更让人兴奋的是,Qwen3.5-Omni展现出了 自然涌现的“视听氛围编码”(Vibe Coding)能力。这意味着在实时视频通话中,它可以直接根据摄像头捕捉到的画面逻辑,动态生成Python代码或前端网页原型。
消息一出,社交媒体上反响热烈。有开发者评价道:这完全改变了非开发者与人工智能交互的范式。
话不多说,直接进入实测环节。
音视频拆解与分析:拉片小能手
首先考验一下它宣称的强大视频理解能力。我上传了一段无字幕的《疯狂动物城2》预告片,要求它分析内容并生成详细的视频脚本。
要知道,预告片的视频理解难度很高。节奏快、镜头密集、画面逻辑跳跃,出场人物繁多。但这对Qwen3.5-Omni来说似乎不是问题,短短几秒钟,它就生成了一个带有精确时间戳的详尽脚本。
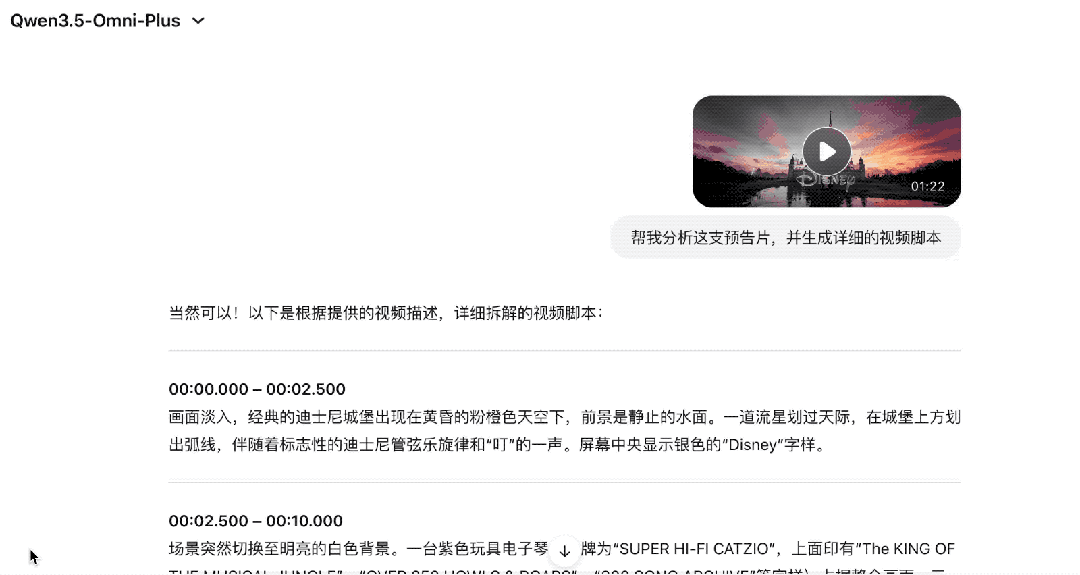
从结果看,它不仅准确地拆解了每一个分镜画面,还详细描述了字幕、特效、音乐乃至蒙太奇手法,所有出场角色一个都没漏掉。
接着提高难度,进行追问:“37秒左右出场的人物是谁?他们在干什么?”

它同样迅速给出了正确答案:尼克、朱迪和新角色蓝蛇盖瑞,并且附带分析了该片段的音效与氛围设计。
我还想让它更进一步,从专业角度评价这支预告片的节奏、手法以及思想内涵。

它的回答再次让人印象深刻。不仅精准概括了“快—慢—爆—收”的波浪式叙事结构,更在没有任何对白和字幕辅助的情况下,解读出了影片关于“差异即力量”、“秩序与自由”等多重深刻隐喻。
这完全就是一个专业的“拉片”助手。
看视频做网页:实时Vibe Coding
接下来,体验一下Qwen3.5-Omni最引人注目的功能——边视频通话边进行Vibe Coding。
在Qwen Chat中打开视频通话功能,AI就能实时看到摄像头画面并和你对话,体验如同真人视频会议。我向它展示了一张手绘的前端界面草图,要求它创建一个关于Geoffrey Hinton的简介网页。
沟通过程中,AI“小姐姐”的语音非常有感情,语气、停顿甚至轻笑都模仿得惟妙惟肖。领取任务后,它仅用十多秒就生成了一套完整的HTML+CSS代码,并给出了网页预览。
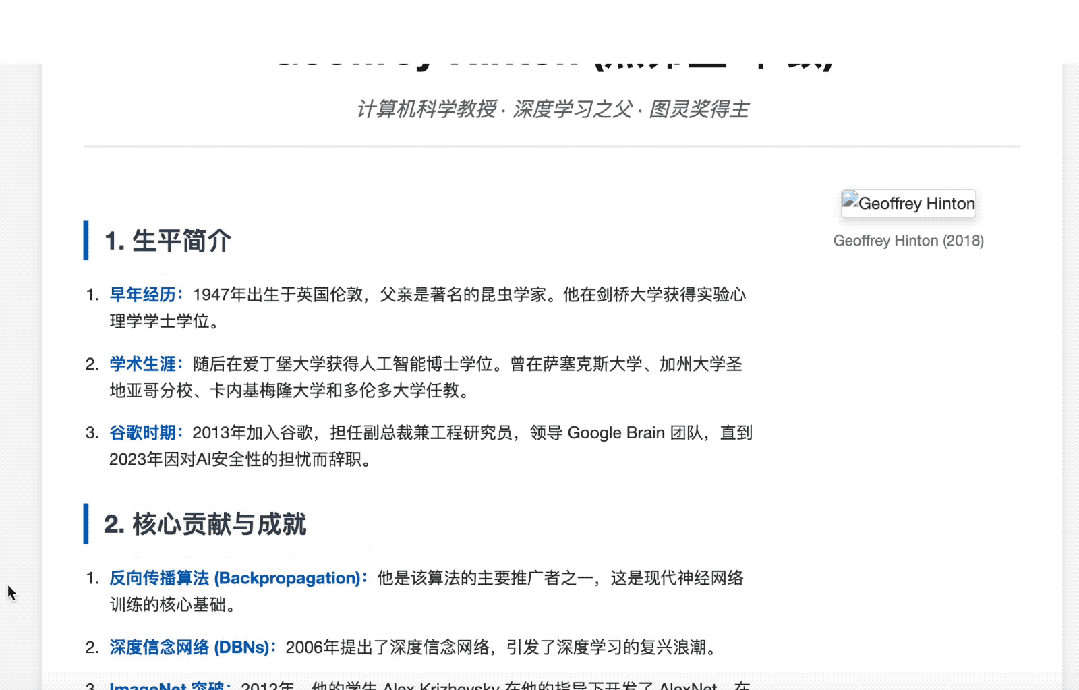
最终效果基本还原了手绘草图的布局。由于模型原生支持网页搜索(WebSearch)和复杂函数调用(Function Call),它自动调用了搜索功能来填充Hinton的生平资料。美中不足的是没有自动匹配图片,且内容相对简略。但结合视频通话和实时代码生成这一整套流程,体验已经足够惊艳。
实时对话解读论文:你的私人学术助手
不止于此,Qwen3.5-Omni还能在视频通话中帮你“读”论文。
对于很多开发者来说,阅读充满复杂图表、公式和术语的AI领域论文是一项挑战。现在,你不需要复制粘贴文本,只需打开摄像头让AI“看”论文页面,它就能用大白话给你讲明白。
我们测试了Yann LeCun团队关于世界模型的新论文“LeWorldModel”。Qwen3.5-Omni根据实时看到的论文页面,清晰地解释了该模型是什么、与以往方法有何不同、创新点在哪里。
过程中,我直接打断它的讲述,询问其中一张图表的意义,它能立刻切换话题进行解答。这得益于本次新增的语义打断功能。更智能的是,它不会被无意义的附和或背景杂音(如开关门声)干扰,保证了对话的连贯性。
这意味着,未来的学术阅读将变得更加友好。你可以随时与AI讨论重点,获得即时的解释,甚至还能得到一些“情绪价值”。
215项SOTA,与Gemini 3.1-Pro旗鼓相当
我们来详细看看Qwen3.5-Omni在各项基准测试中的表现。Qwen3.5-Omni-Plus版本总计获得了215项SOTA,与Gemini 3.1-Pro形成了强有力的竞争。
在音视频理解方面,其整体能力已达到Gemini 3.1-Pro的水平。
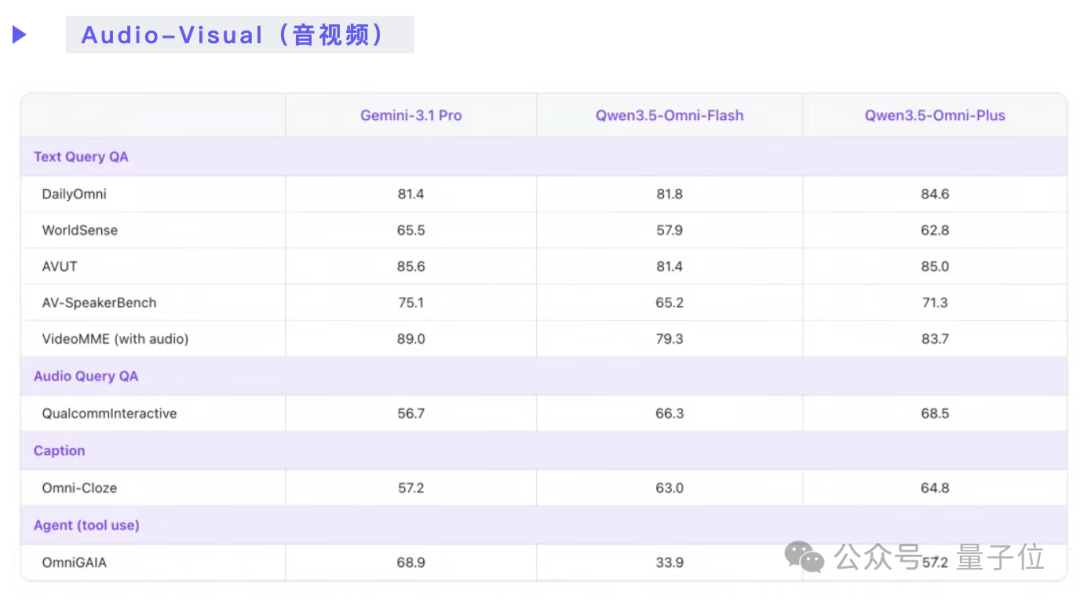
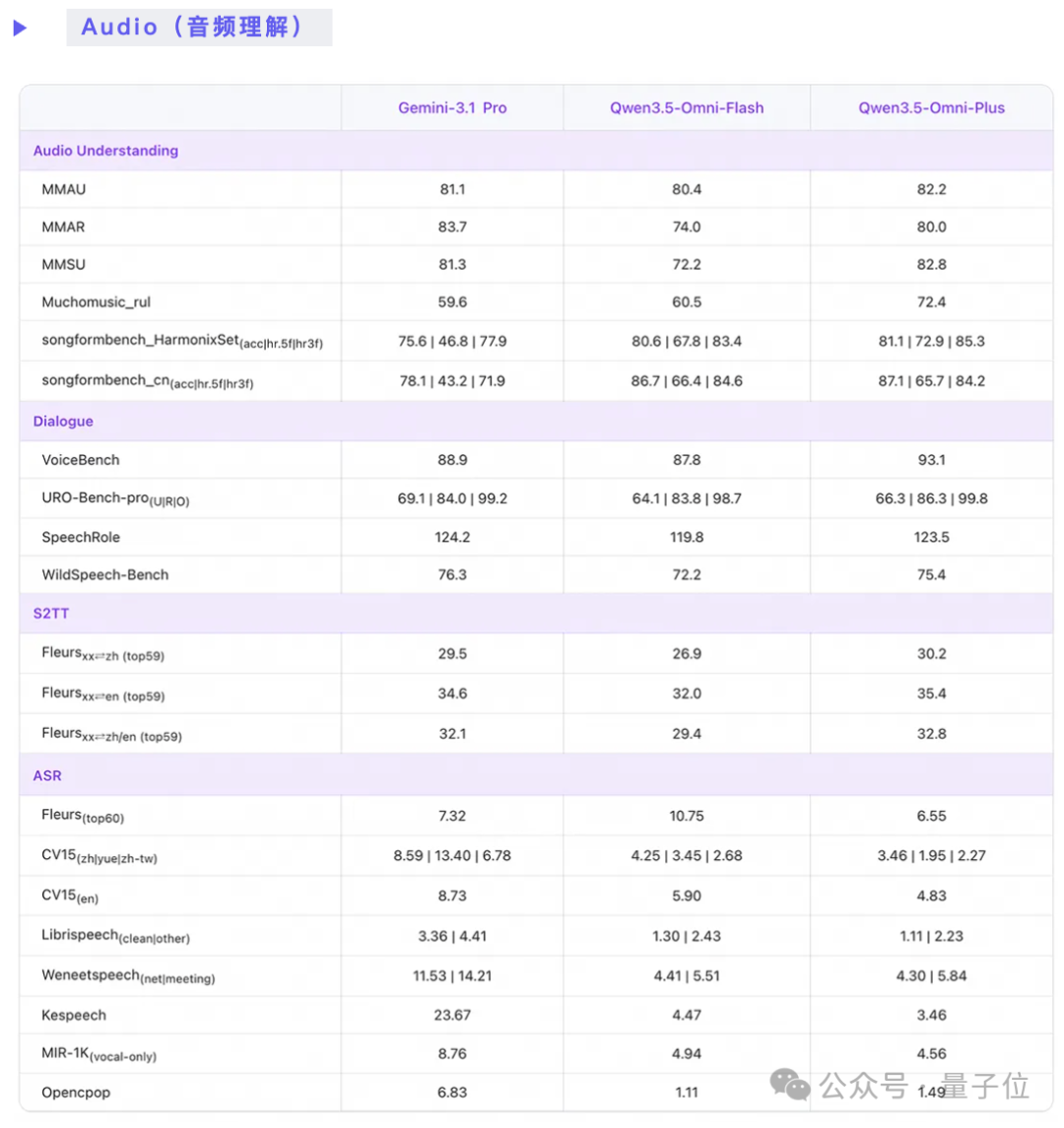
在文本和语音生成能力上,则与同系列模型保持同步,并在部分细分项目上领先。
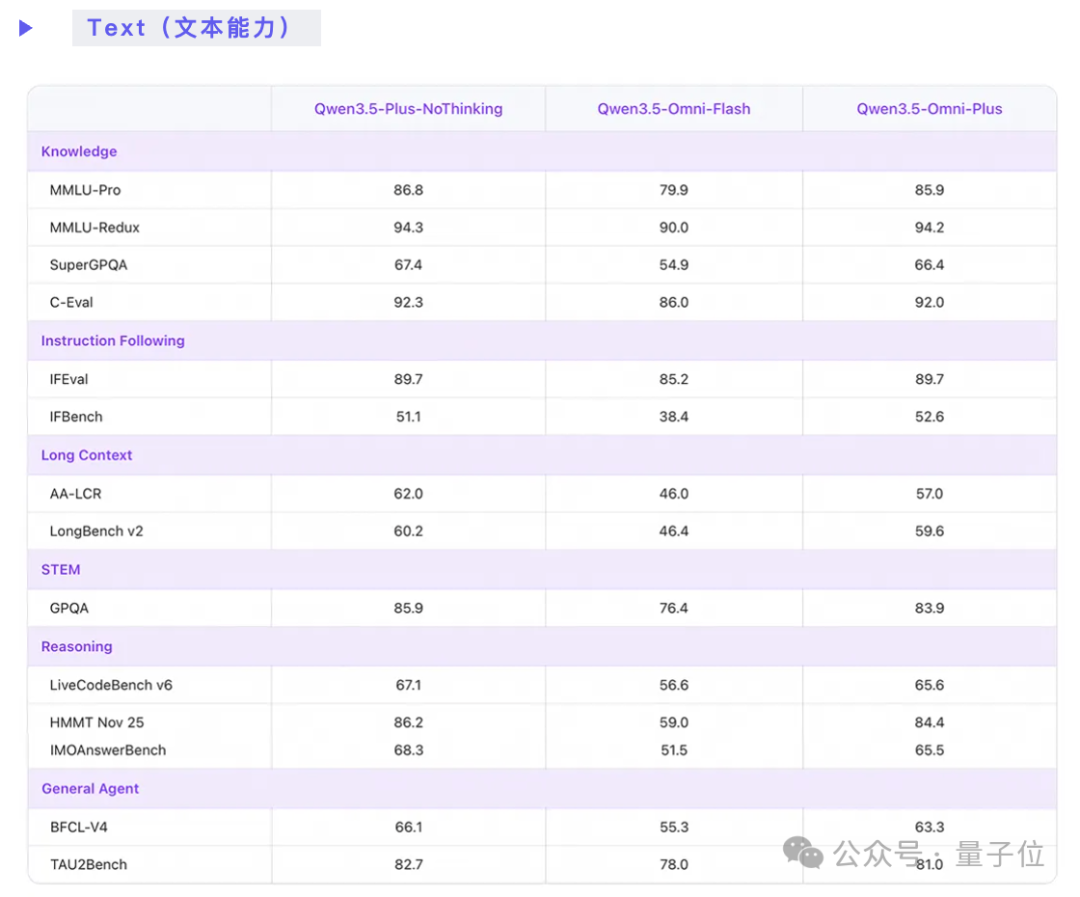
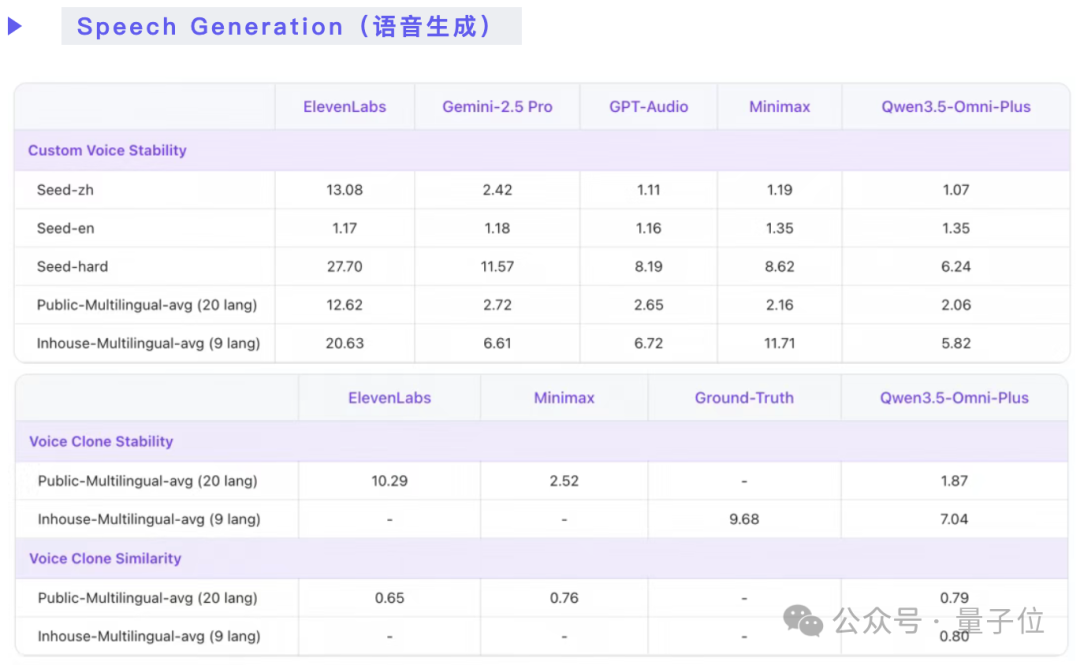
与上一代Qwen3-Omni相比,Qwen3.5-Omni在长上下文、多语言支持、音视频深度理解上均有显著提升。同时新增了语义打断、音色克隆、语音控制等实时交互能力,让对话体验更贴近真人。配合 ARIA(自适应速率交错对齐) 技术,语音输出的稳定性和自然度也进一步改善。
模型架构揭秘:“会思考”与“会说话”的协作
那么,Qwen3.5-Omni是如何实现“边看、边想、边输出”的呢?答案藏在它的模型架构里。
它延续了经典的“思考者-讲述者”(Thinker-Talker)双系统架构:
- Thinker(思考者):负责理解所有输入(文本、图像、音频、视频)。
- Talker(讲述者):负责将思考结果转化为语音输出。
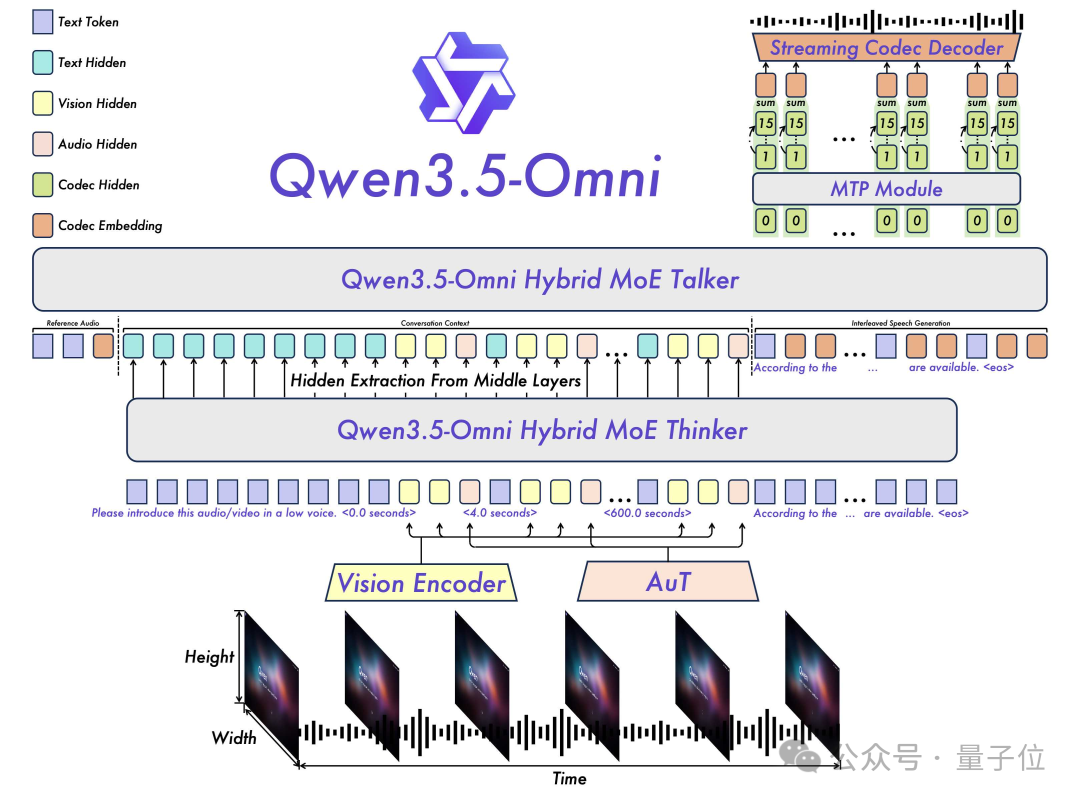
这一次,两者均升级为混合注意力专家混合模型(Hybrid-Attention MoE),在效率和性能上都有显著提升。
Thinker能同时处理多模态信息。模型将音频和视频流“混合”输入,并采用特殊的时序位置编码来理解它们之间的时间关系。最终,Thinker将所有信息整合理解,输出成文本。
Talker则像一个“AI配音演员”。它的关键升级在于:
- 更轻量的语音生成:采用类似“语音压缩编码”(RVQ)的方法,用“拼装声音单元”替代复杂的逐帧生成,更快更省算力。
- 解决“嘴瓢”问题:引入ARIA技术,动态对齐文本与语音的生成节奏,使得输出更稳定、清晰,基本杜绝漏读、错读。
- 真正的实时对话:通过流式设计,实现“边输入、边处理、边生成”。你话未说完,它已在理解;它未想完,就已开始回答,体验如同真人交谈,毫无延迟感。这也解释了为什么有时会觉得它在“抢话”。

目前,新模型可以在 Qwen Chat 上直接体验。若想尝试视频通话功能,需在手机网页端使用。API可通过阿里云百炼平台调用。
体验地址:
从实测来看,Qwen3.5-Omni在多模态理解、实时交互和创造性任务上的表现,确实为AI融入日常工作流打开了新的想象空间。无论是技术爱好者还是寻求效率工具的专业人士,都值得亲自上手一试。
 发表于 2026-3-31 22:29:21
|
查看: 163|
回复: 0
发表于 2026-3-31 22:29:21
|
查看: 163|
回复: 0
