第一次用 AI 写代码的那个下午,我几乎以为自己要失业了。
需求丢进去,代码刷刷刷出来,逻辑清晰,注释完整,测试也有。我当时心里只有一个念头:这玩意儿太厉害了。
然后是两周后。
同一个项目,我开了新的对话窗口,把需求稍微扩展了一下,AI 又刷刷刷给了我代码。风格变了。命名习惯变了。错误处理的方式变了。两段代码像是两个完全不认识的人分别写的,但它们要跑在同一个项目里。
再然后是一个月后。
我已经记不清哪个版本是“对的”了。每次改动都像在拆炸弹,改了这里,不知道哪里会炸。AI 每次都很热情地给我新代码,但它根本不知道、也不在乎这个项目之前发生过什么。
这不是 AI 的问题。这是我的问题——我从来没有给这个“合作者”一个可以遵守的框架。
我相信这个经历不只是我一个人的。现在用 AI 编程的开发者,大概分成两类:一类在用 AI 写工程,另一类在用 AI 写脚本。脚本可以随意,工程不行。工程需要规范、纪律和协同。而这三件事,恰好对应了今天想聊的东西——OpenCode 铁三角。

一、先把问题说清楚,再谈解法
在聊铁三角之前,我想先把“随意编码”的本质说透,因为很多人其实没意识到自己在随意编码。
第一个误区:把 AI 当写代码工具,而不是协作者。
写代码工具是你给需求它给输出,交易完成,关系结束。协作者不一样,协作者需要上下文,需要知道“我们之前说好的是什么”,需要在同一套规则下工作。你用对话框跟 AI 交互,每次新开窗口它就失忆,本质原因是你没有给它一个“持久化的规则层”。
第二个误区:用 Prompt 替代工程规范。
Prompt 是临时性的。你今天写的 Prompt,明天换个说法就是另一个结果。工程规范是稳定的,它规定了这个项目里命名怎么来、接口怎么定义、错误怎么处理,不管谁来问,答案是一样的。用 Prompt 管项目,等于用便利贴管图纸。
第三个误区:每次从零开始的无状态开发。
项目是有历史的。上周做了什么决策,为什么这样设计,踩过什么坑——这些信息如果没有沉淀下来,每次开发都是在重新发明轮子。AI 没有记忆,但你可以给它一个可以读取的“记忆库”。
这三个问题,对应了三个解法:OpenSpec 解决规范问题,Superpowers 解决纪律问题,OMO 解决协同与状态管理问题。这就是铁三角的由来。
二、第一角 OpenSpec:让 AI 从“盲写”变成“按图施工”
我有一个做建筑设计的朋友,有次跟我聊起他们行业的规矩。他说,建筑师不管多有才华,上来就得先出施工蓝图——尺寸、材料、结构、承重,全部白纸黑字。工人不会按建筑师的“感觉”施工,只会按图纸。
我听完沉默了一会儿,然后想到自己每次给 AI 的 Prompt:“帮我写一个用户登录功能,用 JWT,安全一点。”
这哪是施工蓝图,这是在工地门口跟工人说“你看着盖吧,弄好看点”。
OpenSpec 要解决的就是这个问题——把模糊的意图变成显式的约束。
一份合格的 OpenSpec 大概包含这几层:
- 目标层(Goal):这个模块要解决什么问题,成功的标准是什么,边界在哪里。
- 模块层(Modules):功能拆分到哪个粒度,模块之间的依赖关系是什么。
- 接口层(I/O):输入什么、输出什么、数据格式是什么、异常怎么返回。
- 约束层(Constraints):性能要求、安全要求、不能做什么。
- 风格层(Style Guide):命名规范、注释风格、文件结构。
还是那个登录功能,换成 OpenSpec 的写法,大概是这样:
Goal:
实现基于 JWT 的用户登录认证
成功标准:登录成功返回 token,失败返回标准错误码
不在范围内:注册、找回密码、第三方登录
I/O:
Input: { username: string, password: string }
Output(success): { token: string, expires_in: number, user_id: string }
Output(error): { code: number, message: string }
错误码定义:1001=用户不存在,1002=密码错误,1003=账号锁定
Constraints:
- password 传输前必须在客户端加密
- 连续失败 5 次触发账号锁定,锁定时长 30 分钟
- token 有效期 24 小时,支持续期
- 接口响应时间 < 200ms
Style Guide:
- 函数命名:动词+名词,如 validateUser, generateToken
- 错误处理:统一使用 AppError 类,不直接 throw 原生 Error
你把这个丢给 AI,和丢一句“帮我写登录功能”给 AI,出来的代码是两个世界的东西。
OpenSpec 还有一个容易被忽视的价值:变更治理。
项目在演进,需求在变。没有 OpenSpec 的项目,每次变更都是凭感觉改,改完谁也说不清为什么这么改,下次遇到类似问题还得重新想。
OpenCode 里有两个操作专门处理这件事:/opsx:propose 用来生成变更提案,里面包括变更意图、影响范围、设计方案;/opsx:archive 用来把通过的变更合并进主规范。这样做的结果是,你的 OpenSpec 会持续进化,而且每一步进化都有迹可查。
三、第二角 Superpowers:让 AI 像资深工程师一样严谨
说完规范,聊聊纪律。
你有没有发现一个现象:你让 AI 写代码,它能写;你让它写测试,它能写;但如果你不主动要求,它大概率不会主动给你写测试。更不会主动去想“这个函数的边界情况有没有覆盖到”、“这个错误有没有可能在生产环境出现”。
AI 很擅长“完成你说的”,但不擅长“做你没说的但应该做的”。
一个资深工程师不一样。资深工程师有内化的纪律——写完代码自己先 review 一遍,边界情况主动考虑,测试不是可选项而是默认动作。这种纪律不用别人提醒,它是工作方式的一部分。
Superpowers 要做的,就是给 AI 装上这套“内化纪律”。
核心机制一:强制 TDD。
TDD 的逻辑很简单:先写测试,再写实现。测试写不出来,说明你对这个功能的理解还不清楚,这时候去写实现只会越写越乱。
Superpowers 里对此的处理相当直接——不写测试就删代码。听起来暴力,但这个机制真的有用。它不是在惩罚你,它是在强制你把功能想清楚再动手。
核心机制二:标准化工作流。
一个完整的功能开发,应该经过这几个阶段:头脑风暴(把所有可能的情况都列出来)→ 计划(确定实现路径)→ 执行(按计划写代码)→ 审查(自我 review,找问题)→ 收尾(整理、归档、更新文档)。
这个流程大多数人都知道,但在 AI 编程里很少有人会显式地走这几个步骤。结果就是跳过头脑风暴直接执行,然后执行到一半发现漏了东西,推翻重来。
Superpowers 把这个流程内置化了,每次开始新任务都会先走头脑风暴,把边界情况和潜在问题逼出来,再开始写代码。
核心机制三:可复用能力模块。
这一点我觉得是最容易被低估的。
一个项目里,有很多东西是反复用的:统一的 API 请求封装、标准的日志格式、错误处理的方式、分页的逻辑……这些东西第一次写完之后,就应该沉淀成可复用的模块,后续直接调用,而不是每次让 AI 重新生成一遍(每次生成都可能略有不同,这是代码风格割裂的根源之一)。
Superpowers 的能力模块体系,就是在做这件事:把稳定、可信的实现固定下来,给 AI 用,而不是每次靠 Prompt 碰运气。
四、第三角 OMO:把“对话”变成真正的“工程”
前两角解决了“做什么”和“怎么做”,第三角要解决的是“如何持续做”。
OMO 是 Online-Merge-Offline 的缩写。听起来有点绕,但核心思想其实很直白:AI 在线生成是起点,不是终点;代码要经过整合和沉淀,才算真正完成。
很多人用 AI 编程的方式是这样的:需求来了,跟 AI 聊,代码出来了,复制粘贴,提交。这个流程最大的问题是没有“整合”这一步——新代码和旧代码有没有冲突?和 OpenSpec 的定义有没有偏差?这次生成的模式有没有可以沉淀成 Superpowers 的东西?这些问题全部被跳过了。
OMO 的三个环节,就是把这些问题显式化:
- Online(在线生成):AI 理解 OpenSpec,生成代码草稿。这一步追求的不是完美,是方向正确。
- Merge(结构整合):把生成的代码和已有代码库对齐,校验是否符合 OpenSpec 的约束,跑测试,检查边界。这一步是质量门禁。
- Offline(资产沉淀):本地精化,安全审查,把这次开发中抽象出来的好模式更新进 Superpowers,把发现的新约束补充进 OpenSpec。这一步是让整个体系越来越好用的关键。
流程图大概是这样:
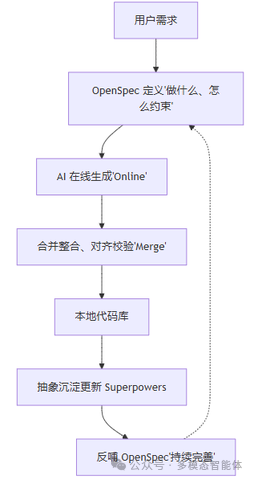
这个循环一旦跑起来,是有复利效应的:OpenSpec 越来越完整,AI 生成的代码质量越来越高;Superpowers 越来越丰富,AI 能直接调用的稳定模块越来越多;整个项目的可维护性会随时间提升,而不是随时间腐烂。
OMO 还有一个进阶玩法:多智能体协作。可以同时跑模拟架构师、前端、后端的多个 AI 角色并行工作,彼此之间通过 OpenSpec 定义的接口协作,互不干扰。复杂任务的开发时间会大幅缩短。
五、三角协同的实战演示
说了这么多概念,来一个具体的场景走一遍。
需求:给一个已有项目加一个“用户登录模块”。
第一阶段——规范先行
不要先写代码。先打开 OpenSpec,用 /opsx:propose 生成变更提案。提案里包括:这个模块的目标是什么,接口格式怎么定,安全约束是什么,和现有代码的依赖关系是什么。
这一步做完,生成一个 proposal.md,把所有人(如果有团队的话)拉到同一个认知平面上,确认没有遗漏,再进入下一步。
第二阶段——纪律落地
加载 Superpowers,开始执行。AI 先走头脑风暴,把所有需要考虑的边界情况列出来:密码加密方式、Token 续期策略、并发登录处理、异常情况的错误码。
确认没有遗漏之后,先写测试用例——正常登录、密码错误、账号锁定、Token 过期,每种场景一个测试。
测试写完,再写实现。实现完成后,AI 自己做一遍 code review,检查是否有安全漏洞、是否符合 OpenSpec 的约束、是否有未处理的异常。
第三阶段——协同收尾
跑 OMO 的 Merge 流程:把新代码和已有代码合并,跑全量测试,校验接口格式是否和 OpenSpec 完全一致。
没有问题之后,/opsx:archive 把这次变更归档进主规范。如果这次开发里有可复用的模式(比如统一的 Token 处理逻辑),更新进 Superpowers。
整个过程走下来,比“直接跟 AI 说帮我写登录功能”慢了不少,但你得到的不只是代码——你得到了一个可以继续在上面演进的、有据可查的、质量可信的工程模块。
六、落地建议:不要一上来就全上
看到这里,可能有人想着把三个东西一次全部引入。建议别这么做。
工具引入的阻力,很多时候不是工具本身的问题,是变化太多一次消化不了。
推荐的顺序是:
第一步:先上 Superpowers。 它改变的是 AI 的工作方式,对你现有的习惯冲击最小,但带来的质量提升最明显。强制 TDD、标准化工作流,这两件事单独拿出来就已经值了。
第二步:再建 OpenSpec。 有了 Superpowers 之后,你会越来越清楚地感觉到“AI 需要更清晰的约束”——这时候自然会想去写 OpenSpec。动机到位了,写出来的 OpenSpec 才是真的有用的,而不是为了写而写。
第三步:最后搭 OMO。 OMO 是整套体系的粘合剂和加速器,它的价值建立在前两者都跑起来之后。单独上 OMO 意义不大。
另外有几个坑,亲测会踩:
一是 OpenSpec 写太细。什么都规定死了,AI 反而施展不开,你自己也累。OpenSpec 的颗粒度应该是“约束边界”,不是“逐行指令”。
二是忽视 TDD 的“先写测试”这一步。很多人觉得先写测试慢,跳过去直接写实现,然后补测试。补出来的测试大概率是在配合实现,而不是在验证功能。先写测试的核心价值不是测试本身,是逼你在动手之前把功能想清楚。
三是 OMO 的 Offline 阶段敷衍了事。代码跑通了就合并,不更新 Superpowers,不回补 OpenSpec,这样整个体系就变成了单向的,没有复利,慢慢就废了。
七、最后说一件事
现在有很多人在谈“AI 会不会取代程序员”,我觉得这个问题本身就问错了。
真正的问题是:AI 会取代哪种程序员?
我的判断是:会被取代的,是那些把自己定位成“写代码的人”的程序员——给需求,出代码,交差。这件事 AI 已经做得够好了。
不会被取代的,是那些把自己定位成“设计系统的人”的程序员——他们知道用什么框架来管约束、用什么机制来保证质量、用什么流程来让协作不崩盘。
OpenCode 铁三角,本质上是在帮你完成这个转变:从“写代码的人”变成“让 AI 稳定写出好代码的人”。
这不是退而求其次,这是往上走了一层。
如果你现在在用 AI 编程,但总感觉越用越乱、越用越累,可以从今天开始做一件具体的事:为你手头的下一个需求,写一份 OpenSpec。哪怕很粗糙,哪怕只有两三行约束,先写出来。你会发现,光是这一步,就已经让 AI 的输出质量有了明显的变化。
剩下的,慢慢来。
你现在的 AI 编码体系,走到哪个阶段了?欢迎在 云栈社区 聊聊,或者分享你踩过的坑。
 发表于 2026-5-3 19:50:58
|
查看: 147|
回复: 0
发表于 2026-5-3 19:50:58
|
查看: 147|
回复: 0
