混合专家架构在扩展大型语言模型容量方面功不可没,但在将其应用于视觉生成的核心架构——扩散 Transformer时,却发现效果提升有限。为何同样成功的架构跨界到视觉领域就“水土不服”?
最近,来自复旦大学、阿里通义万相Wan Team、浙江大学和香港大学的研究团队给出了他们的答案:视觉Token的独特属性阻碍了视觉MoE中专家的有效“专业化”。他们提出了一种名为ProMoE的全新MoE框架,通过显式路由引导来解决这一问题,相关论文已被ICLR 2026接收。这项研究为我们理解如何在人工智能视觉模型中高效应用MoE架构提供了新思路。
论文标题:Routing Matters in MoE: Scaling Diffusion Transformers with Explicit Routing Guidance
论文地址:https://arxiv.org/abs/2510.24711
代码仓库:https://github.com/ali-vilab/ProMoE
视觉Token为何是MoE的“绊脚石”?
研究团队指出,视觉Token具有两个不同于语言Token的显著特性,使得传统的隐式路由策略难以奏效:
- 高度空间冗余性:文本Token语义凝练、差异显著,而图像Patch(视觉Token)在空间上高度相关,包含大量冗余信息。这导致MoE中的专家倾向于学习同质化的特征,无法形成有效的专业分工。
- 功能异质性:在扩散模型中广泛使用的无分类器引导技术,天然地将输入Token分为两类:条件Token和无条件Token。标准的MoE范式对它们不加区分地进行路由,忽略了它们承担的不同功能角色。
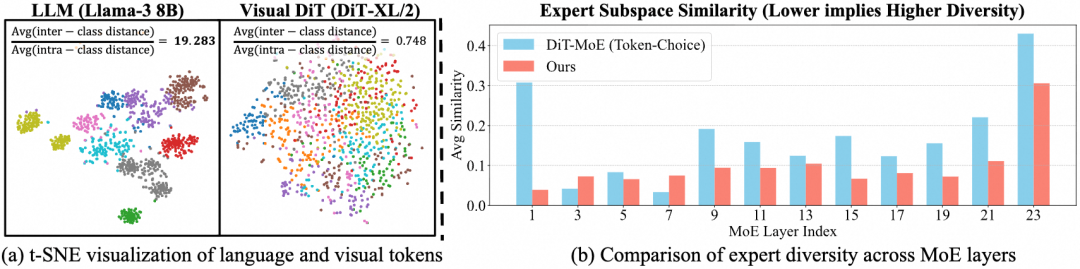
图1:(a) 随机选取的1k个中间层Token的t-SNE可视化。语言Token(来自LLM)形成了紧凑且分离良好的语义簇,而视觉Token(来自DiT)则分布更为分散和冗余。(b) 专家子空间相似度对比。引入路由引导的ProMoE(Ours)比传统DiT-MoE在多数层上表现出更低的相似度,意味着更高的专家多样性。
为了在视觉Token的“混沌”中建立秩序,实现真正的“专家内一致、专家间多样”,ProMoE设计了精巧的两步路由机制,并引入了显式的语义路由引导。
第一步:条件路由
首先,路由器根据Token的功能角色进行“硬”分配。无条件图像Token被直接路由给专门的无条件专家处理。条件图像Token则进入下一步,交由标准的路由专家处理。这一步实现了专家在功能层面的隔离,让不同类型的专家专注处理不同角色的Token。
第二步:原型路由
对于条件图像Token,ProMoE引入了一组可学习的“原型”,每个原型对应一个特定的路由专家。路由器计算每个Token与所有原型在隐空间中的余弦相似度,选择分数最高的原型(及其对应的专家)来“认领”该Token。这种方式为路由赋予了更明确的语义指引。
显式语义路由引导:路由对比学习
为了进一步增强路由的语义清晰度,ProMoE提出了一种路由对比损失。该损失无需人工标注,在训练中会动态产生两种效果:
- 拉近:将每个原型拉向分配给它的所有Token的质心,确保同一专家处理的Token在语义上相近。
- 推开:将每个原型推离其他专家处理的Token的质心,鼓励不同专家学习差异化的知识,促进专业化。
有趣的是,实验发现RCL中的“推开”操作在语义层面天然起到了负载均衡的效果,比传统设计的负载均衡损失更灵活有效。
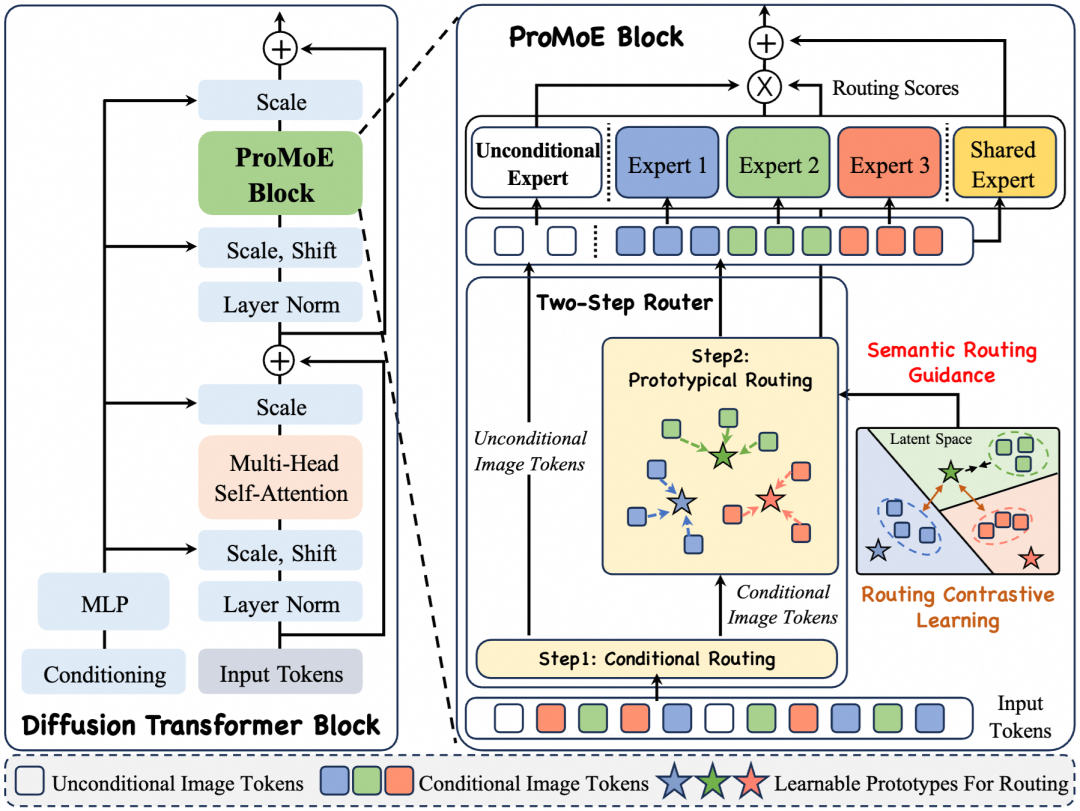
图2:ProMoE架构概览。输入Token首先通过条件路由进行分流。条件Token经由基于可学习原型的原型路由分配给对应专家,并辅以路由对比学习进行语义引导。
其训练过程的核心算法伪代码如下:
Algorithm 1 ProMoE Layer (Training)
Input: X ∈ R^B×L×D (input sequence), c ∈ Z^B (batch labels)
Variables: N_E (number of routed experts), K (number of activated routed experts), P ∈ R^{N_E×D} (Learnable prototypes for routing), E (List of routed expert FFNs), E^U (Unconditional expert FFN), E^S (Shared expert FFN), λ_RCL (coef of Routing contrastive loss), τ (temperature)
1: Initialize: O ← zeros_like(X) ▷ Initialize final output
2: /*** Step 1. Functional Routing ***/
3: M_u ← (c == 0) ▷ Get mask of unconditional image tokens
4: M_c ← ¬M_u ▷ Get mask of conditional image tokens
5: X_u ← X[expand(M_u)] ▷ Get unconditional image tokens
6: X_c ← X[expand(M_c)] ▷ Get conditional image tokens
7: /*** Step 2. Unconditional Image Tokens Processing ***/
8: O_U ← E^U(X_u)
9: O[M_u] ← O_U
10: if any(M_c) then
11: /*** Step 3. Prototypical Routing ***/
12: X'_c ← reshape(X_c, (-1, D)) ▷ Flatten conditional image tokens
13: n_c ← X'_c.shape[0] ▷ Get number of conditional image tokens
14: Z ∈ R^{n_c×N_E} ← L2_Normalize(X'_c) × L2_Normalize(P)^T ▷ Get pre-activation scores
15: S ← Identity(Z) ▷ Get token-expert affinity scores
16: G ∈ R^{n_c×K}, indices ∈ Z^{n_c×K} ← TopK(S, K) ▷ Get gating tensor and indices
17: /*** Step 4. Conditional Image Tokens Processing ***/
18: O'_c ← zeros_like(X'_c)
19: for i ← 0 to N_E - 1 do
20: m_i ← (indices == i).any(dim = 1) ▷ Mask of tokens routed to expert i
21: if any(m_i) then
22: G_i ← sum(G[m_i] × (indices[m_i] == i), dim = 1) ▷ Final gating scores
23: O'_c[m_i] ← O'_c[m_i] + G_i.unsqueeze(1) × E_i(X'_c[m_i]) ▷ Update final output
24: end if
25: end for
26: O' ← reshape(O', X_c.shape)
27: O[M_c] ← O[M_c] + O'
28: /*** Step 5. Routing Contrastive Learning ***/
29: aux_loss ← λ_RCL × L_RCL(X_c, indices, P, τ)
30: end if
31: /*** Step 6. Shared Expert Processing ***/
32: O ← O + E^S(X)
33: Return: O, aux_loss
实验结果
模型配置
研究团队构建了与标准DiT系列对齐的ProMoE模型(S, B, L, XL),其具体配置如下表所示。“E14A1S1U1”表示共使用14个专家,每个Token激活1个专家,1个共享专家,以及1个处理无条件Token的专家。
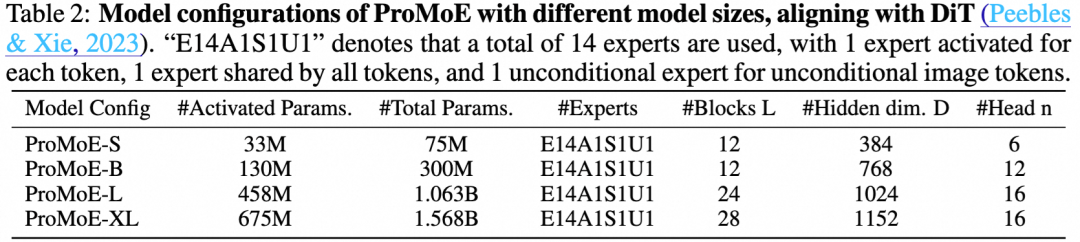
表2:ProMoE不同尺寸模型的配置参数。
与稠密模型的对比
ProMoE在各种规模下均稳定超越了对应的稠密DiT模型。一个亮眼的结果是,激活参数量为458M的ProMoE-L-Flow,其性能超越了激活参数量为675M的Dense-DiT-XL-Flow,实现了“以少胜多”。
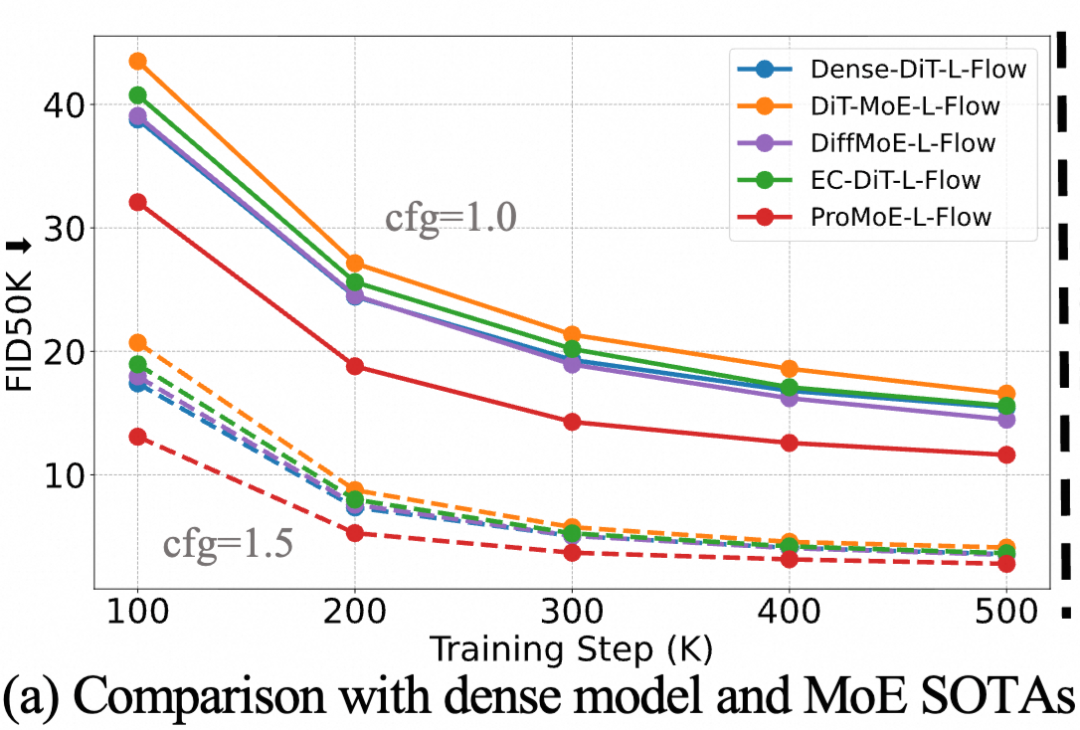
图 (a):ProMoE-L-Flow在训练过程中的FID下降趋势优于其他MoE基线及稠密模型。
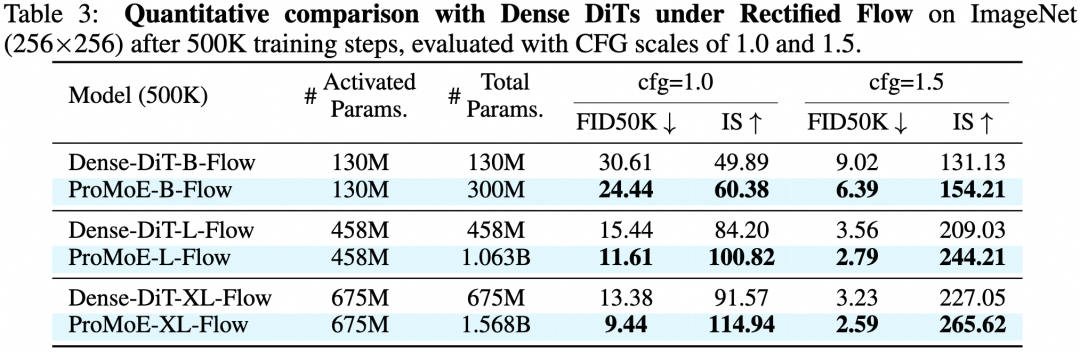
表3:在ImageNet 256×256上训练500K步后,ProMoE与稠密DiT的定量比较(使用Rectified Flow)。
与现有视觉MoE方法的对比
ProMoE同样超越了现有的视觉MoE方案。在相同激活参数量(458M)下,总参数量为1.063B的ProMoE-L-Flow,其性能甚至超越了总参数量达1.846B(16个专家)的DiffMoE模型。
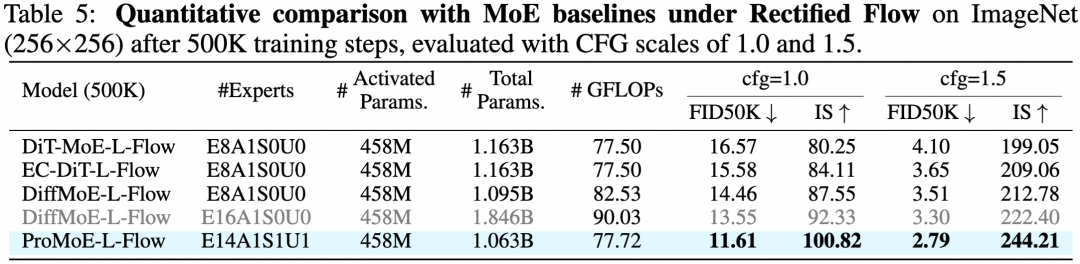
表5:与MoE基线在ImageNet 256×256上的定量比较。
文本到图像生成验证
在评估组合泛化能力的GenEval基准测试中,ProMoE在“计数”、“颜色”、“位置”等多个子任务上全面超越了标准的Token-Choice MoE模型,展现出更强的泛化能力。

表6:在GenEval基准上的比较结果。
生成效果可视化
模型能够生成高质量、多样化的图像。

图4:ProMoE-XL-Flow训练2M步后生成的类别条件图像样本(cfg=4.0)。

图14:ProMoE在文本到图像任务上生成的样本。
收敛性与可扩展性分析
训练损失曲线显示,ProMoE的收敛速度显著快于稠密模型和其他MoE方法。此外,无论是扩大模型整体尺寸还是增加专家数量,ProMoE都表现出了良好的扩展性,性能随着规模增长而稳步提升。
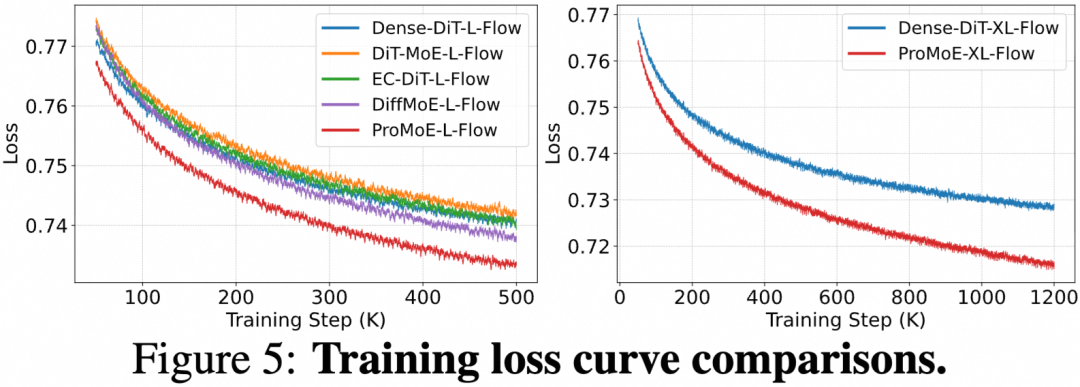
图5:训练损失曲线对比。(左) L规模模型,(右) XL规模模型。
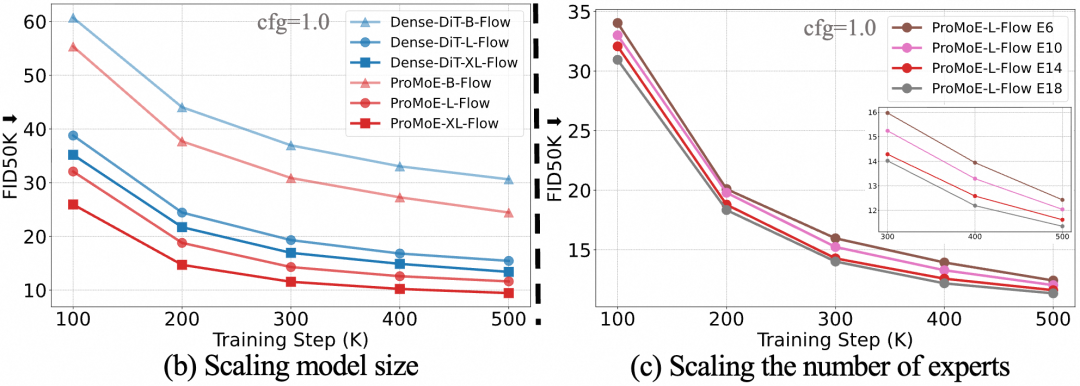
图 (b)(c):ProMoE在扩展模型尺寸和专家数量时的性能变化。
消融实验
消融研究验证了ProMoE各个组件的有效性。依次引入原型路由、路由对比学习和条件路由,均带来了显著的性能提升。
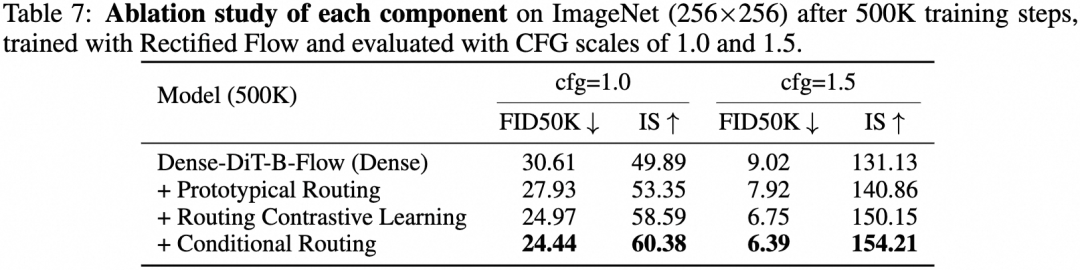
表7:ProMoE各核心组件的消融研究结果。
总结
ProMoE通过深入分析语言与视觉Token的根本差异,提出了一个针对视觉生成模型优化的MoE框架。其核心的两步路由机制与显式语义路由引导,有效解决了视觉Token冗余和功能异质性带来的挑战,从而在更少的激活参数量下,实现了超越稠密模型和现有MoE方法的性能。这项研究不仅为开源实战社区贡献了创新的模型架构,也为未来大规模视觉生成模型的高效扩展提供了一条清晰的路径。更多技术细节和实验结果,可查阅原论文及开源代码。
 发表于 2026-3-31 23:13:31
|
查看: 155|
回复: 0
发表于 2026-3-31 23:13:31
|
查看: 155|
回复: 0
