2026年3月30日,微软为其Microsoft 365 Copilot的“研究助理”(Researcher)功能引入了两项关键的多模型协作新机制——Critique(批判) 与 Council(理事会)。
这标志着GPT与Claude两大顶级大语言模型首次在商业化产品中实现深度协同与双向互审。此举直指当前人工智能应用的核心痛点——“幻觉”问题,旨在为企业级的深度研究工作重构一种全新的AI协作范式。
一、Critique:一写一审,构建 AI 内容 “双保险”
Critique是本次功能更新的核心。它采用“生成-审核”的接力式协同架构,旨在精准结合GPT与Claude各自的能力长板,形成一个“初稿撰写 + 交叉评审”的闭环质检流程。
- GPT 主生成:发挥GPT在文本创作、结构化输出和快速信息整合方面的优势,负责执行初步的研究梳理、搭建报告逻辑框架、完成内容铺陈并进行初步的数据引用。
- Claude 严审核:利用Claude在长上下文理解、事实核查、逻辑严谨性以及合规性校验上的强项,对GPT生成的初稿进行全维度评审。这包括核验数据来源的真实性、引用的完整性、结论的一致性,并确保事实陈述无冲突,最终输出结构化的纠错与优化建议。
- 双向互审演进:目前Critique采用的是“GPT生成,Claude审核”的单向模式。微软已明确表示,未来将开放双向模式,即支持“Claude生成,GPT审核”,实现对称协作,以覆盖更多样化的写作与校验场景。
二、Council:多模型并行,打造 “AI 辩论场”
与Critique形成互补的是Council(理事会)机制。它采用并行对比架构,让多个模型独立工作、交叉验证,从而拓宽研究的视角。
- GPT与Claude会针对用户提出的同一研究课题,独立展开调研并各自生成一份报告。
- 随后,一个独立的“裁判模型”会对这两份产出进行评估,提炼出共识点与分歧点,并总结每个模型带来的独特见解。
- 这种模式能有效帮助用户捕捉单一模型可能遗漏的信息,从而提升研究的深度与决策的全面性。
三、核心价值:从根源抑制 AI 幻觉,提升研究质量
这套多模型协作系统为根治AI“一本正经胡说八道”的幻觉问题提供了一个结构化的解决方案。
- 数据验证:在DRACO(深度研究准确性、完整性与客观性)基准测试中,采用Critique机制的双模型协作效果显著超越了任何单一模型的表现。
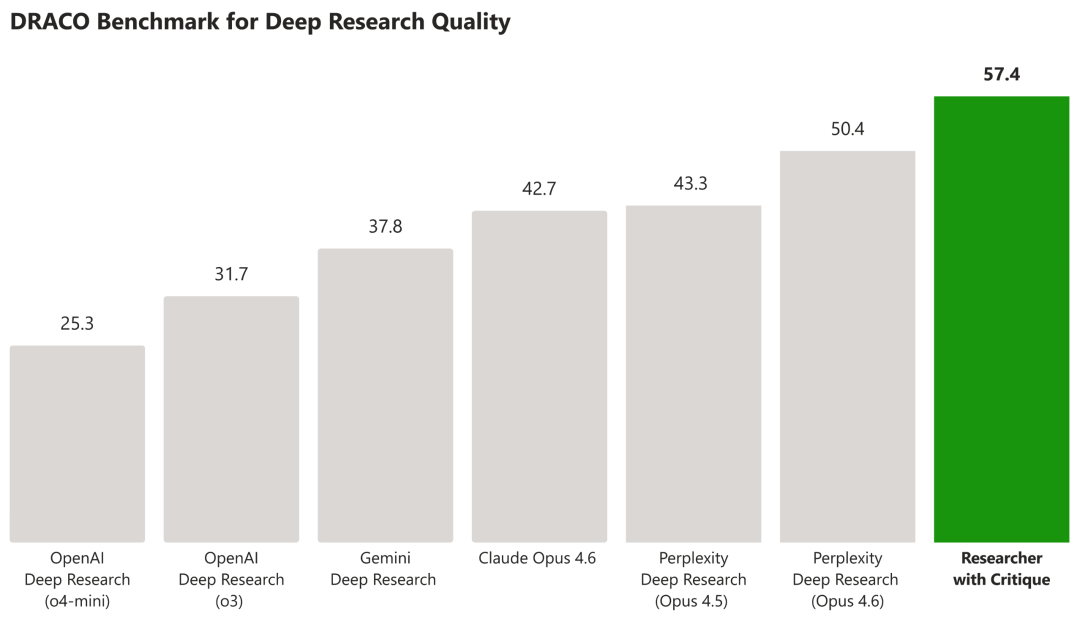
- 效率与质量双升:微软365 Copilot的企业副总裁Nicole Herskowitz指出,这种协作模式不仅能有效限制AI幻觉,还能大幅提升企业在研究分析与内容生产方面的生产力。
- 开放生态:此次更新是微软与Anthropic深化合作的重要一步。此前,Claude模型已入驻Azure云平台。现在,365 Copilot用户可以直接在两大模型之间进行切换或组合使用,以适应不同任务的需求,这体现了智能与数据云生态的开放与融合趋势。
四、应用场景与开放范围
目前,Critique与Council功能已被集成到Microsoft 365 Copilot的Researcher智能代理中,并面向微软Frontier企业计划用户开放。其主要服务场景包括企业级的深度市场调研、综合报告撰写、竞争分析以及技术文档审核等,旨在为专业人士提供一个更可靠、更严谨的AI辅助工具。
参考来源:https://techcommunity.microsoft.com/blog/microsoft365copilotblog/introducing-multi-model-intelligence-in-researcher/4506011
对于这类前沿的AI协作模式和技术实践,云栈社区将持续关注,为开发者提供更多深度分析和交流空间。 |  发表于 2026-4-1 02:56:28
|
查看: 193|
回复: 0
发表于 2026-4-1 02:56:28
|
查看: 193|
回复: 0
