在过去,AI更多地被视为一个高效的工具。但如今,它的定位似乎在发生微妙的变化。一种新的可能性正在浮现:AI或许正在尝试占据一些更具主导性的“位置”。
一个许多用过AI编程工具的人都深有体会的感受是:无论使用哪个模型,体验常常像是在带领一位实习生。你需要将任务分解成一步步的指令,它执行一步,你检查一步。一旦任务复杂度稍高,它就可能忘记之前的要求,或者在修改代码时引入新的错误。整个过程需要你全程监控,不时地介入修正,有时甚至会发现,自己动手完成反而比指导AI修改更快捷。
因此,“AI将取代程序员”的口号喊了多年,但真正深度使用过的人心里都明白:距离真正的“取代”,路还很长。
直到上周,智谱悄无声息地上线了其新一代模型——智谱GLM-5.1。作为国内领先的大模型公司,智谱的GLM系列一直在编程(Coding)方向上持续发力。GLM-5.1的目标非常明确:攻克那些此前模型未能妥善解决的核心难题。发布当天,GLM Coding Plan订阅服务直接售罄,补货页面也排起了长队。
我的第一反应是:哦,又是一篇发布稿罢了。于是,我决定将一个完整的项目需求直接扔给它,进行一次实测。
从零搭建一个完整项目
我的需求很简单,但完整:
从零搭建一个内部运营工具,需要包含用户权限系统、数据看板、导出功能,后端使用 FastAPI,前端使用 React。
按照以往的经验,我会将这个需求拆解成七八个子任务,逐个喂给模型。
但这次使用智谱GLM-5.1,我直接将完整的、未经任何拆解的需求文档抛了进去。它没有立刻开始编写代码,而是花了大约两分钟,输出了一份详细的技术方案。
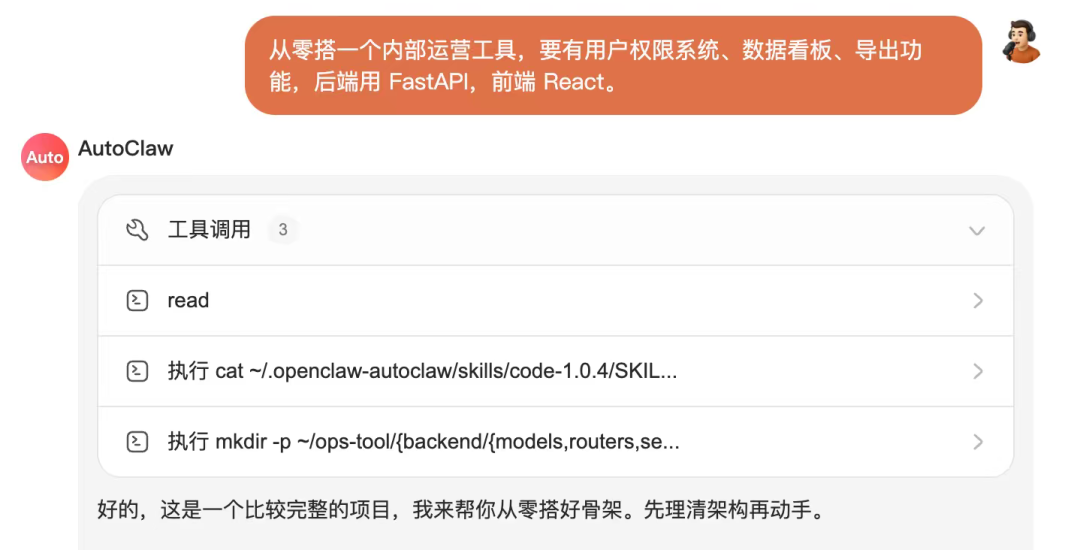
它首先规划了整个项目的结构、模块间的依赖关系以及开发的先后顺序,并询问我是否有修改意见。
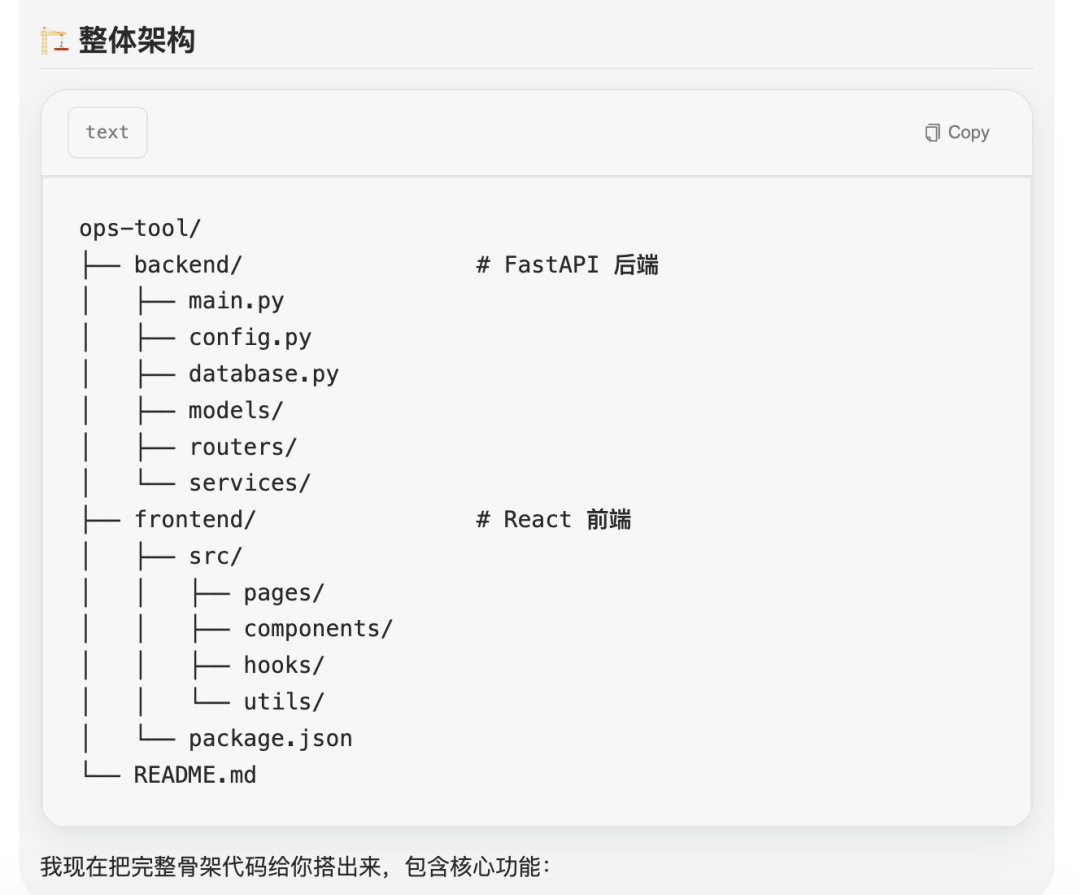
在我确认没有意见后,它便自主开始推进项目。整个过程中,模型会在内部记录当前进度,并据此执行下一步操作。在进行到第四步时,它自行发现了JWT鉴权模块与异步任务调度模块在接口设计上存在一处潜在冲突,并主动进行了修正,整个过程没有向我发出任何提示或请求。
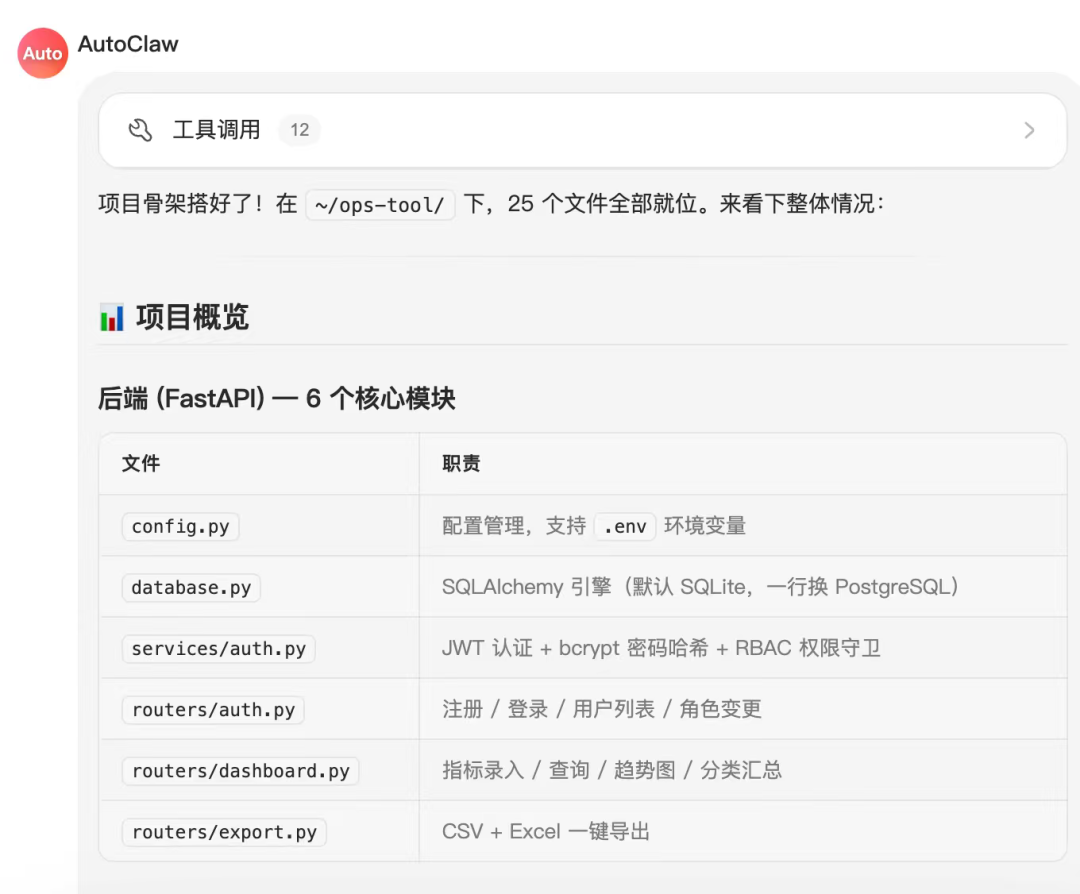

全程我没有进行任何干预,一个可运行的项目便搭建完成了。

这种体验,与以往使用任何模型的感觉都截然不同,属于完全不同的量级。
社区实测:从游戏到行业报告
这并非个例。智谱GLM-5.1发布后,技术社区掀起了一波实测热潮。
一位游戏开发者利用GLM-5.1,在一夜之间构建了一个可交互的网页版《我的世界》,镜头移动流畅,未探索区域还能实时生成地形。这类任务以往可能需要一个小型团队协作完成。
另一位用户将自己积累的所有关于“灵巧手”(Dexterous Hands)的研究资料输入给GLM-5.1,要求其生成一本有助于理解该行业的书籍。结果他得到了一份结构完整、章节逻辑清晰的行业分析手册,其质量让他直呼“远超预期”。

这些案例的共同点在于:AI交付的不再是简单的问答或孤立的片段,而是一个完整的、可交付的成果。
核心突破:Long Horizon 能力
深入了解后,我发现这背后的关键在于一个名为 “Long Horizon”(长视野) 的能力。
简单来说,这项能力衡量的是:AI能否在一个持续数小时、跨越十几个步骤、中间可能出现意外的完整项目中,始终保持目标一致、自主推进、并在出错时自行修复。此前的模型大多难以胜任此类任务,上下文一长就容易偏离方向,需求稍有变动就会迷失。
智谱GLM-5.1是国产大模型中首批在此能力上重点发力并取得显著进展的。
数据上有直观体现:在基于 Claude Code 框架的 Coding Agent 评测中,智谱GLM-5.1 获得了 45.3 分,相比上一代 GLM-5(35.4分)提升了近10分,与目前全球顶尖的编程模型 Claude Opus 4.6(47.9分)仅相差2.6分。
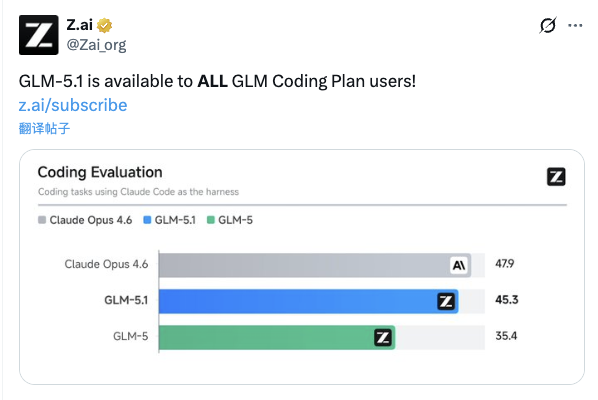
这个分数的意义远超排名本身。从GLM-5到GLM-5.1,智谱仅用了一个多月时间。这样的迭代速度表明:这并非一次偶然的技术跳跃,而是一个明确且正在加速的发展方向。
此外,在 BrowseComp(多步网页操作记忆)测试中,GLM-5.1 取得了75.9分,超越了GPT-4o等主流模型。
这些测试的共同核心在于:它们考核的并非单一问题的解答能力,而是在连续、复杂的行动序列中保持状态稳定、不偏离轨道的能力——这正是 Long Horizon 能力的精髓。
重新思考:我们的“护城河”在哪里?
我曾经深信,无论AI变得多强大,作为那个负责拆解任务、确定方向、做出关键判断的人,我的角色是稳固的。毕竟,以前的AI只能产出“碎片”,而我们是那个将碎片拼合成完整图景的“整合者”与“决策者”。
但在使用GLM-5.1完整地交付了那个运营工具项目后,我猛然意识到:它现在已经开始自己拆解任务、自己规划方向、自己做出技术决策了。
如果说以前的AI替代的是我们“执行”的手,那么现在,它正开始尝试替代我们“规划”与“协调”的脑。这对于传统的项目管理思维模式构成了直接的挑战。
这绝非意味着程序员或项目管理者即将失业。但它清晰地标志着,一条曾经被认为坚固的防线已经被悄然突破。
我们当前的“护城河”究竟是什么?
- 是编写代码的能力?这条线正在被快速追平。
- 是管理项目、协调进度的能力?这条线刚刚被证明是可以突破的。
- 是定义问题、进行价值判断和战略决策的能力?这或许是更深的护城河,但绝非永不可破。
我没有确切的答案,但我认为,每一个身处技术行业的人,现在都值得开始认真思考这个问题。技术变革的窗口期,可能比我们想象的更为短暂。如果你对 AI编程 的演进有更多想法或实践经验,欢迎到 云栈社区 与更多开发者交流探讨。
 发表于 2026-4-1 03:40:55
|
查看: 178|
回复: 0
发表于 2026-4-1 03:40:55
|
查看: 178|
回复: 0
