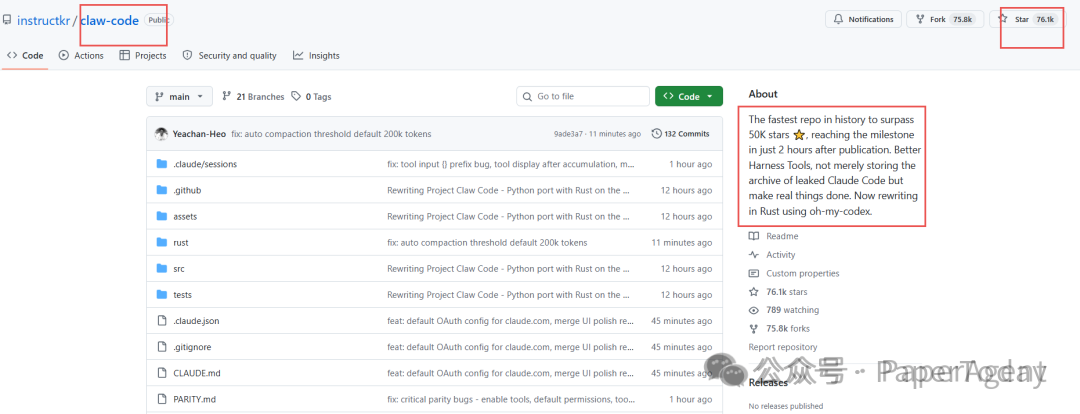
昨天,Claude Code 意外泄露的新闻刷屏了技术圈。这个“被动开源”的项目在 GitHub 上迅速冲到了 76k 星,可以说是史上蹿红最快的仓库之一。
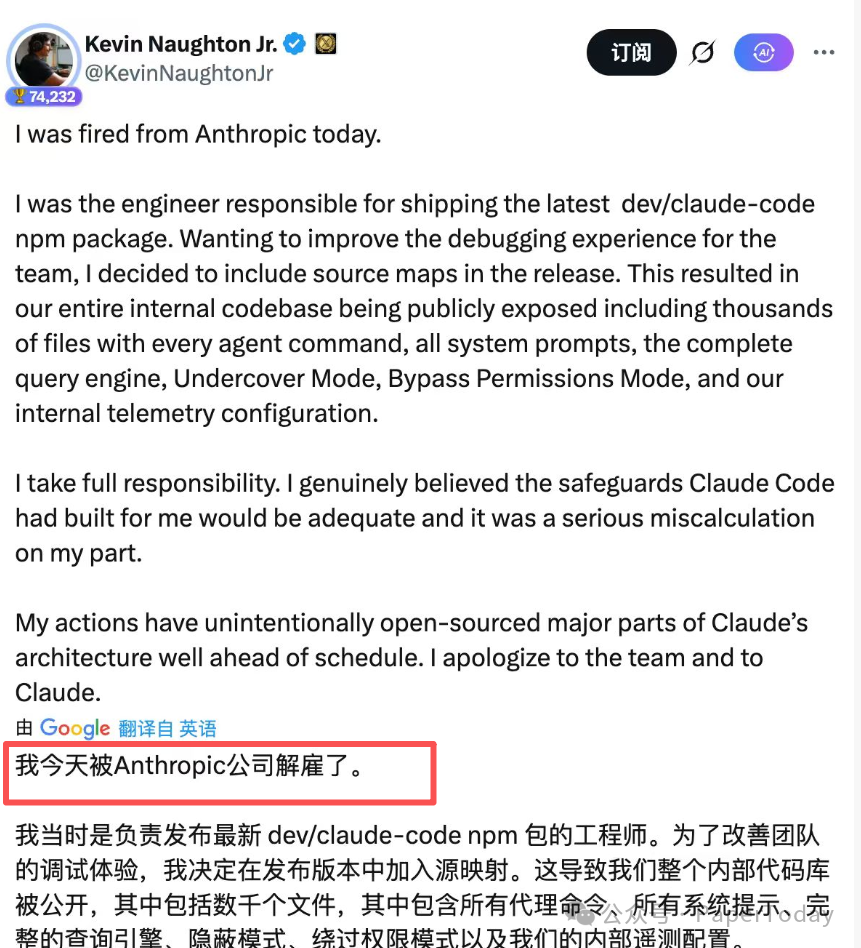
随后,事件的“主角”也出面认领了责任。一位自称是 Anthropic 前工程师的网友在社交平台发文,解释其因在发布的 npm 包中误包含 source map 文件,导致整个内部代码库被公开。
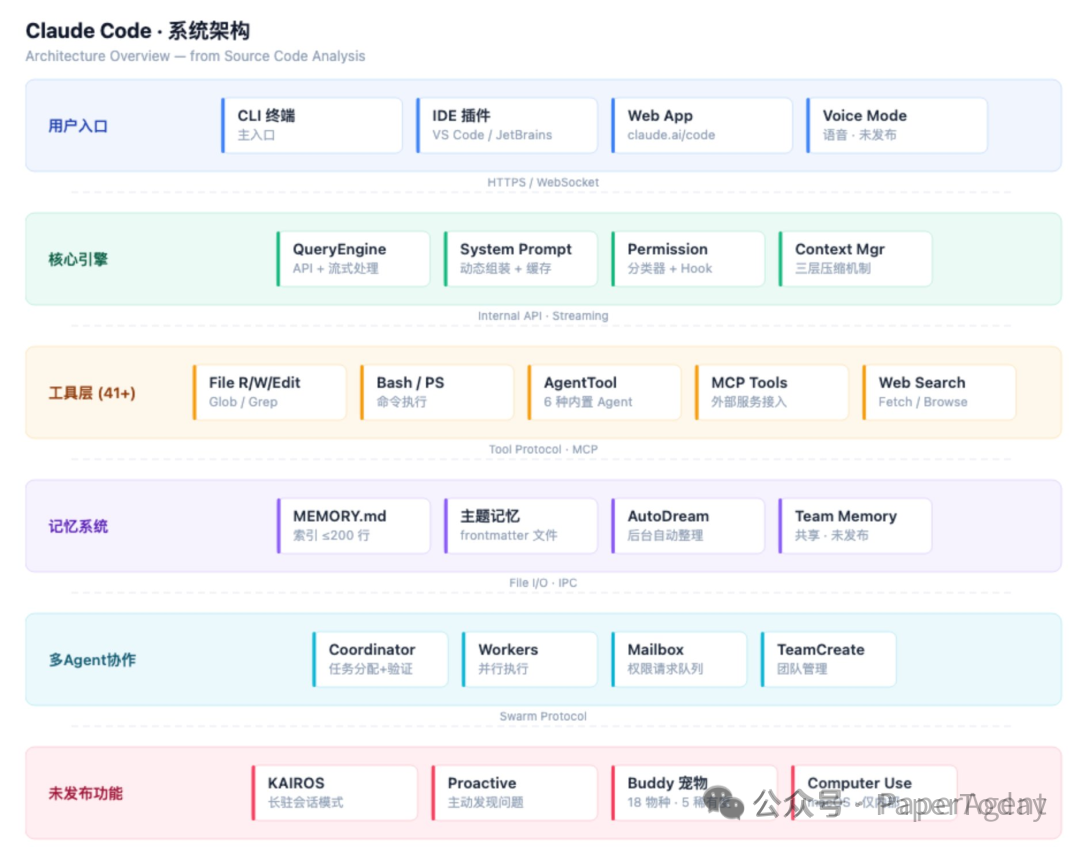
在仔细翻阅了从 npm 包的 cli.js.map 逆向还原出的 4756 个文件后,我发现了一个与主流认知截然不同的技术事实:Claude Code 所展示的 RAG(检索增强生成) 思路,早已超越了我们常见的“切文档、存向量、再召回”的初级阶段。
它对知识的组织和使用方式,更像是一个“操作系统级的内存管理器”,而不仅仅是外挂了一个知识库。
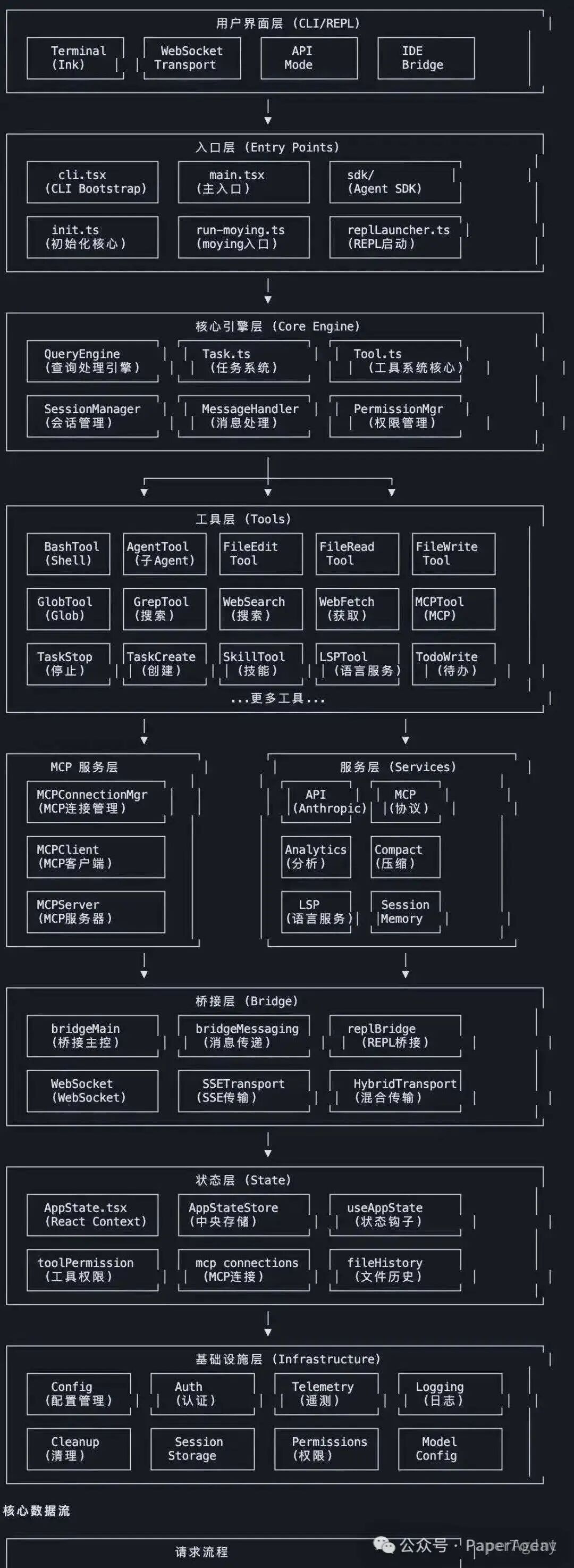
以下是我从这次深入的 源码分析 中提炼出的四个“反常识”却极具价值的高级技巧。
01 不用向量库的“即时检索”
很多团队在实践 RAG 时,第一反应就是搭建向量数据库。Embedding、存储、召回,这套标准流程面临着延迟、成本和准确率的“三角困境”。
但 Claude Code 里的 Explore Agent 选择了一条完全不同的路径:它完全不用向量库。
这个 Agent 是一个专为代码探索设计的纯读专家。当主 Agent 需要理解某个模块、查找某个函数或理清一段逻辑时,Explore Agent 不会去向量库进行“语义相似度”检索,而是直接调用 Glob 和 Grep 工具进行实时文件系统搜索。
这其中的差异是本质性的:
- 向量检索 依赖语义相似度,在代码场景下容易“误伤”——注释相似但功能迥异的函数可能被高召回,而真正需要查找的精确符号却排名靠后。
- Glob/Grep 检索 则是查找“精确存在”。需要找一个接口定义?直接 Grep 其函数签名。需要定位一个模块的所有文件?直接 Glob 其路径模式。
最关键的是,这种检索并非预先构建的索引,而是在 Agent 思考过程中动态触发的。模型根据任务自行决策:现在是否需要搜索?用什么工具搜?搜到后该读取哪个文件?
这实质上是一种 “带工具的实时检索”。它比依赖向量索引的 RAG 更精准,架构上也更轻量。如果你想深入了解这种将工具调用与智能体结合的前沿范式,可以关注 人工智能 领域的相关进展。
02 Prompt 里藏着的“缓存经济学”
撰写系统提示词(System Prompt)时,很多人倾向于将所有规则、范例和说明都塞进去,导致 Prompt 日益臃肿,每次 API 调用都消耗大量 Token。
Claude Code 对 Prompt 的处理方式则体现了精细的成本控制思维:他们按照“是否可缓存”来切分 Prompt。
具体来说,System Prompt 被明确分为两部分:
- 静态前缀:包含身份定位、行为哲学、基础工具使用规范等在整个会话周期内基本不变的内容。这部分可以被 API 服务端缓存,后续调用的成本极低。
- 动态后缀:包含与会话强相关的信息,例如当前激活的技能(Skill)、已连接的 MCP 工具说明、会话特有的临时指令等。
这一设计的精妙之处在于,它不再将 Prompt 视为一段单纯的文本,而是当作 “可缓存的运行时资源” 来管理。
更“极致”的是,在 Agent 的 fork(派生)机制中,系统会刻意让子 Agent 继承主 Agent 的 System Prompt 和工具定义,目的是确保 API 请求的前缀字节完全相同,从而最大限度地命中缓存。
这传递了一个清晰的信号:他们不是在把 Token 当作“消耗品”,而是当作需要精打细算的“预算”来管理。一个懂得“算账”的 RAG 或 Agent 系统,才具备大规模生产部署的可行性。对于希望深入优化大模型应用成本的开发者,可以参考 智能 & 数据 & 云 板块中关于计算资源管理的讨论。
03 用“上下文压缩”替代“向量索引预筛选”
在标准 RAG 流程中,检索出的上下文经常过长,无法全部塞入模型的上下文窗口。常见的解决方案是进行“预筛选”,例如通过向量相似度分数只保留最相关的几条。
Claude Code 采用了一种更高级的策略:它不做预筛选,而是授权让模型自己执行压缩。
在源码中,存在明确的会话专属指导(Session-specific guidance)和 Token 预算管理逻辑。当对话上下文长度逼近窗口上限时,系统不会粗暴地丢弃早期消息,而是会触发一个压缩过程——要求模型将之前的对话历史、工具调用结果、中间思考过程等,提炼成一个 “紧凑的结构化摘要”。
这个摘要保留了所有关键决策、状态和结论,但剔除了冗长的细节。经过压缩,原本占用 10000 Token 的上下文可能被精简到 2000 Token,而核心信息无损。
这相当于把 RAG 的“筛选”动作,从检索阶段后置到了模型消费阶段。那么,谁更擅长判断“哪些信息对完成当前任务最关键”呢?无疑是模型自身。向量相似度永远无法理解任务的深层意图,但模型可以。
04 “MCP 不只是工具桥,还是行为规范注入通道”
最后一个技巧藏得最深,也最具启发性。
大多数人将 MCP(Model Context Protocol) 仅仅视为一个“工具桥”,其作用是让模型能够调用外部工具。然而,在 Claude Code 的 prompts.ts 文件中,存在一段关键逻辑:getMcpInstructionsSection()。
这段代码会遍历所有已连接的 MCP Server,如果某个 Server 提供了 instructions 字段,就会将这些说明文本直接拼接到系统提示词中。
这意味着什么?意味着 MCP 不仅能给模型“注入工具”,还能注入“如何使用这些工具的行为规范与最佳实践”。
例如,一个数据库 MCP 工具可以在 instructions 中写明:“执行查询时应优先使用索引字段;处理大批量数据需采用分页策略,避免单次拉取全部数据。” 这些说明会成为模型认知的一部分,直接影响其调用工具时的决策逻辑。
这不正是 RAG 的核心思想吗?RAG 的本质是将外部知识注入模型上下文以提升其回答质量。而 MCP Instructions 所做的,是将“工具的使用知识”这一特定领域的知识注入模型上下文。
它检索的不是文档,而是“工具的行为规范”。这个思路一旦打开,RAG 的应用边界就不再局限于搜索网页或文档,可以扩展到搜索“如何操作某个复杂系统”、“如何遵循特定工作流”等更广阔的领域。对于希望集成或开发 MCP 工具的开发者,开源实战 社区中有许多相关的项目案例和协议分析可供参考。
总结
回顾这四点,它们都指向同一个核心洞察:RAG 的本质不是“外挂一个知识库”,而是“确保模型在正确的时机,获得正确的信息”。
向量数据库只是实现该目标的一种手段,而非唯一或总是最优的选择。
- Explore Agent 的实时检索,在代码场景下比向量库更精准。
- Prompt 的缓存切分,比无节制堆砌 Token 更经济。
- 上下文的动态压缩,比基于相似度的预筛选更智能。
- MCP 的行为说明注入,比单纯提供工具接口更具指导性。
这些设计技巧,任何一个单独拿出来都足以优化现有的系统。而当它们被有机地组合在 Claude Code 中时,便共同塑造了其流畅而高效的用户体验。
如果你也在设计或优化 Agent 与 RAG 系统,不妨反思一下:你的系统还停留在“向量库 + 简单召回”的初级阶段吗?是否已经开始朝着“操作系统级的内存与知识管理”这个更本质的方向演进了?技术探索永无止境,欢迎在 云栈社区 与我们分享你的见解与实践。
 发表于 2026-4-2 01:54:39
|
查看: 199|
回复: 0
发表于 2026-4-2 01:54:39
|
查看: 199|
回复: 0
