今天,阿里巴巴正式发布了其图像生成与编辑的统一模型 Wan2.7-Image。这次更新旨在解决当前 AI 生图中普遍存在的审美疲劳、色彩失控等痛点,带来了更具“活人感”的人物生成能力、精确到像素级的色彩控制以及强大的超长文本渲染功能。
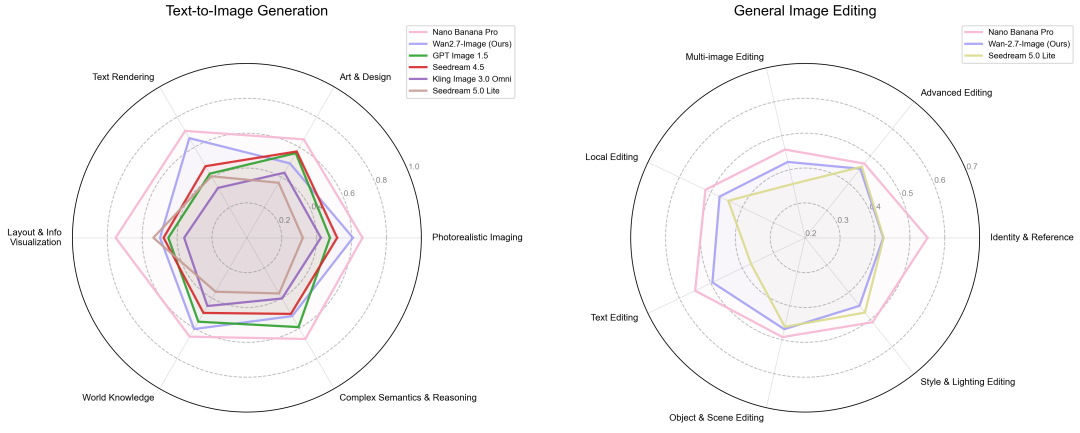
在权威的人类偏好盲测中,Wan2.7-Image 的评分位列国内模型第一,展现出其在复杂语义理解与美学表现上的综合实力。这标志着人工智能领域在图像生成与理解层面的又一次重要进步。
塑造“千人千面”:告别同质化的虚拟面孔
为了让 AI 生成的人物彻底摆脱“网红脸”或“标准脸”的同质化问题,Wan2.7-Image 深度强化了其虚拟形象捏脸功能。
模型通过对骨相、眼眸及五官细节的全方位定制支持,允许用户在提示词中灵活指定脸型(如鹅蛋脸、国字脸、圆脸)与眼部特征(如丹凤眼、深邃眼窝、笑眼)。这意味着,AI 不再只能输出一种“完美”但缺乏个性的面容,而是能根据创作者的独特需求,塑造出具有高辨识度、富有真实生命力的面孔。

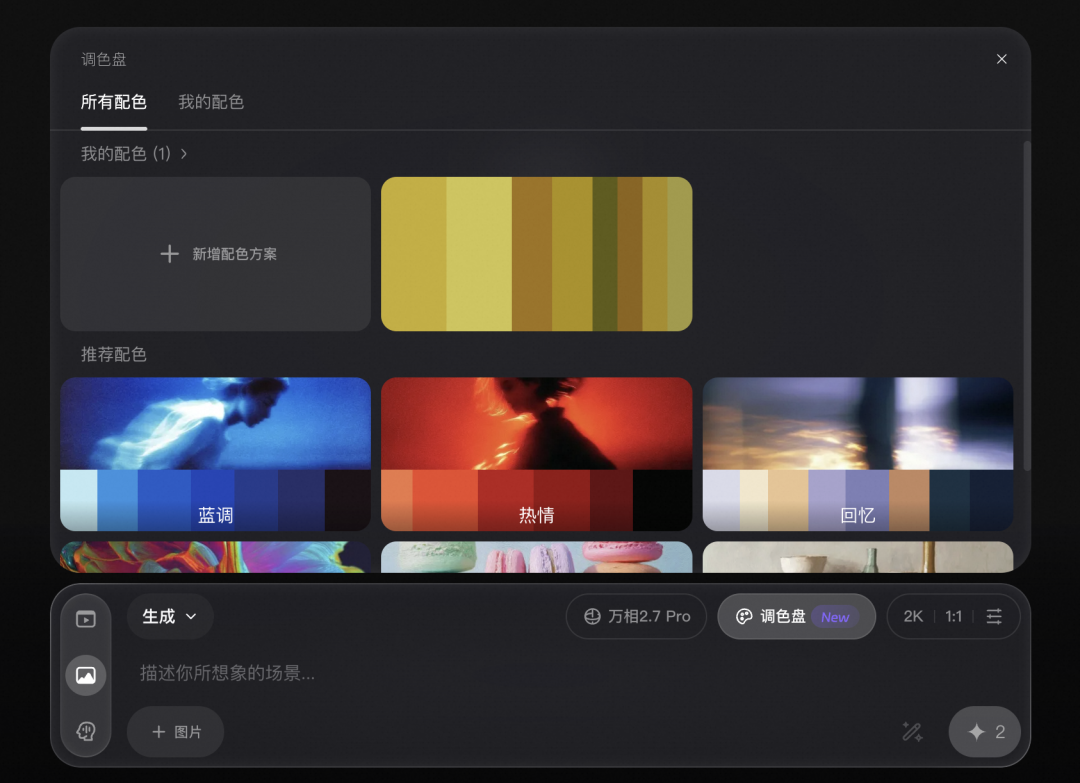
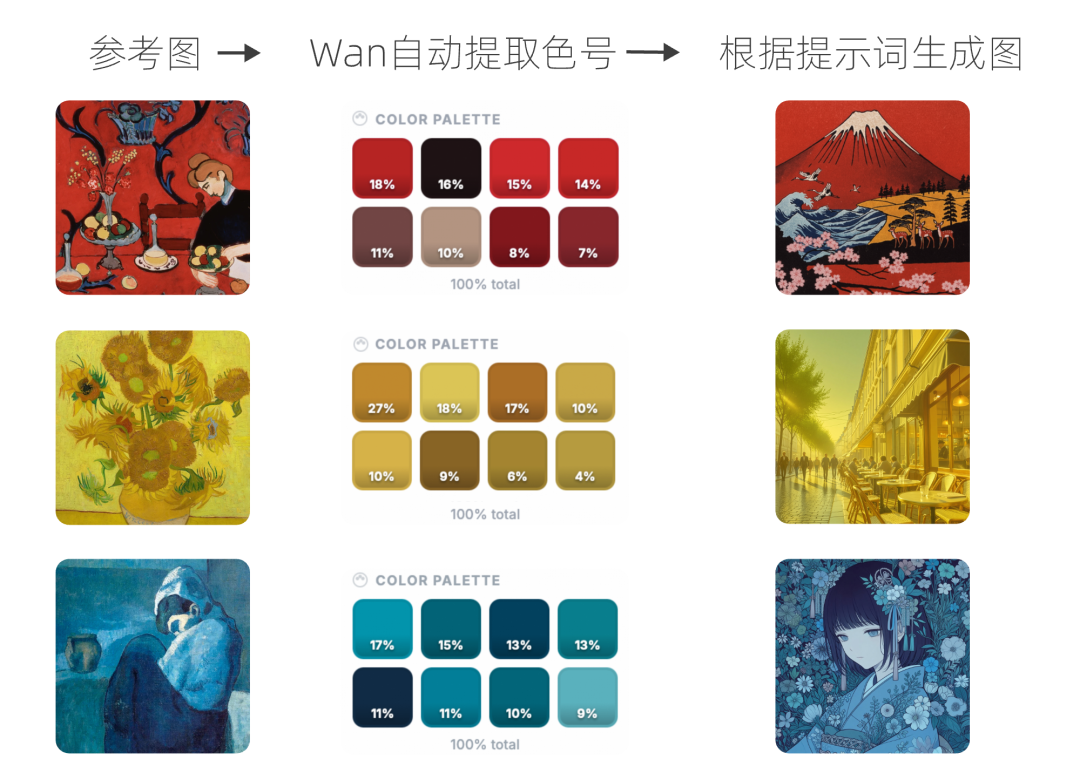
玩转“调色盘”:精准对齐设计师的创作意图
对于专业设计师而言,色彩的精确控制是商业设计的基石,也是过去许多 AI 工具的短板。
Wan2.7-Image 全新引入了“调色盘”功能。用户可以一键上传任何参考图片,模型会自动分析并提取其色彩构成与分布比例。无论是想要复刻一幅古典名画的经典色系,还是严格对齐品牌视觉手册的配色规范,这个功能都能在保持原有构图和内容的同时,实现色彩的精准迁移与复现。
3K Token 超长文本渲染:挑战排版与逻辑极限
文本渲染一直是图像生成模型的“硬伤”,经常出现文字模糊、内容错乱或直接遗漏的情况。Wan2.7-Image 尝试正面突破这一技术瓶颈。
得益于对超长序列的深度记忆与解析能力,该模型最高支持 3K token 的复杂长文本输入。无论是包含复杂排版的数据表格、严谨的数学公式,还是需要铺满整张 A4 纸的密集文字段落,Wan2.7-Image 都能实现媲美印刷品的清晰度与准确度,并支持中文、英文等 12 种语言。

交互式编辑与多主体一致性:让控制更随心所欲
除了高质量的生成能力,Wan2.7-Image 更强调“可操控性”。它原生集成了交互式编辑模块,用户只需通过简单的框选和文字指令,就能在图像的特定区域内实现元素的精准添加、替换、对齐或移动,真正做到“指哪改哪”。

同时,模型在主体一致性方面表现强劲,最高可支持 9 张参考图输入。这使得它在生成漫画分镜脚本、电商产品套图、系列宣传海报等内容时,能够有效保持角色形象、物体特征和整体风格的统一,极大降低了创作过程中的“随机性”干扰。

组图生成:批量创作的效率利器
Wan2.7-Image 还具备强大的组图生成能力,单次可生成最多 12 张图像。这一功能非常适合用于批量制作同风格系列插图、PPT 配图、故事分镜、电商模特展示图以及建筑的多视角效果图,显著提升内容生产的效率。

技术架构的突破:从“像素拟合”到“语义认知”
更精准的理解与控制能力,源于底层架构的革新。Wan2.7-Image 采用了生成与理解相统一的先进架构。通过在共享的隐性空间内实现语义的精确映射,让文本描述能更“紧密”地关联到视觉元素,减少了模型“猜测”的模糊地带。
同时,在训练流程中引入了丰富的多模态指令(如“文字+图片”组合),推动模型实现了从单纯的“像素级拟合”到“底层语义认知”的关键飞跃。
为了应对各类长尾和复杂场景,研发团队构建了一个涵盖布局、光影、角度等多维度的精细化标注体系,确保模型在面对复杂、罕见的指令时,依然能保持极高的生成稳健度与可靠性。
基于更大规模数据和参数量训练而成的 Wan2.7-Image-pro 版本也已同步上线。Pro 版本在图像构图的稳定性、复杂语义的理解精准度上均有进一步提升。
即刻体验
对 Wan2.7-Image 感兴趣的用户和开发者可以立即体验:
据悉,千问 App 也即将接入该模型,值得期待。
注:Wan2.7-image 现已支持 Skill 调用,极大地拓展了生成模型的应用场景和自动化可能性。关于更多 AI 技术的实践与讨论,欢迎访问 云栈社区 与广大开发者交流。
 发表于 2026-4-2 06:32:42
|
查看: 168|
回复: 0
发表于 2026-4-2 06:32:42
|
查看: 168|
回复: 0
