随着AI技术日益成为开发者工具箱的核心,大语言模型正深刻改变着我们的开发方式。从代码辅助到内容生成,其应用场景不断拓展。本文将聚焦于如何在资源受限的嵌入式AI设备部署轻量级的DeepSeek-1.5B与中量级的Qwen2.5-3B模型,为你提供一份实用高效的部署实战指南。
01 小模型DeepSeek-1.5B部署
为什么选择DeepSeek-1.5B?在模型选择上,合适的才是最好的。DeepSeek-1.5B作为一个拥有15亿参数的小型语言模型,在性能与资源消耗间取得了出色的平衡。相比动辄数百亿参数的大模型,它仅需约3GB内存即可流畅运行,对普通开发机非常友好。它支持中英文,能够处理文本生成、问答、摘要等多种常见任务,足以应对大多数开发场景。
环境搭建
首先,我们需要准备好运行环境。
# 创建并激活虚拟环境
conda create -n python312 python=3.12
conda activate python312
# 安装必要的依赖
pip install torch transformers
核心代码
以下是加载并使用DeepSeek-1.5B模型进行对话的核心Python代码:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 模型路径
model_path = "/LLM/deepseek-1.5b"
print("正在加载模型和分词器...")
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(model_path, dtype=torch.float16)
# 移动模型到GPU
if torch.cuda.is_available():
model = model.to("cuda")
print("模型已移动到GPU")
else:
print("使用CPU运行模型")
print("模型加载完成,开始对话!")
print("输入问题进行问答,输入 'exit' 或 'quit' 退出程序")
print("=" * 50)
# 实时问答函数
def chat():
# 系统提示,指导模型生成合适的回答
system_prompt = """你是一个智能助手,能够提供准确、有用的信息。请用自然、友好的语言回答用户的问题,不要重复问题,直接给出详细的回答。"""
while True:
# 获取用户输入
user_input = input("你: ")
# 退出条件
if user_input.lower() in ["exit", "quit"]:
print("对话结束,再见!")
break
# 构建简洁的提示,只包含系统提示和当前问题
prompt = f"{system_prompt}\n\n用户: {user_input}\n助手: "
# 编码输入
inputs = tokenizer(prompt, return_tensors="pt")
# 移动到相同设备
if torch.cuda.is_available():
inputs = {k: v.to("cuda") for k, v in inputs.items()}
# 生成回答
outputs = model.generate(
**inputs,
max_length=300, # 适当减少最大长度
temperature=0.8, # 稍微增加随机性
top_p=0.9, # 调整词汇多样性
pad_token_id=tokenizer.eos_token_id,
do_sample=True, # 启用采样
repetition_penalty=1.1 # 惩罚重复
)
# 解码输出
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取助手的回答(去除输入部分)
assistant_response = response.replace(prompt, "").strip()
# 显示回答
print(f"助手: {assistant_response}")
if __name__ == "__main__":
try:
chat()
except KeyboardInterrupt:
print("\n对话被用户中断,再见!")
except Exception as e:
print(f"发生错误: {e}")
import traceback
traceback.print_exc()
测试结果
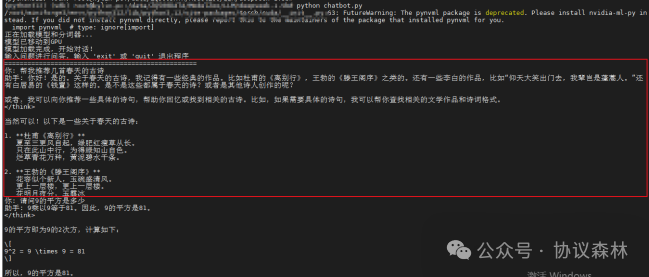
运行上述代码后,你可以在终端与模型进行交互。一个简单的测试示例如下,模型能够根据提示生成相关的诗句并尝试进行统计分析:
02 中模型Qwen2.5-3B部署
Qwen2.5-3B-Instruct有什么不一样?作为阿里达摩院推出的中量级模型,它在3B参数规模下提供了更强的理解和推理能力。它经过了专门的指令调优,对用户指令的响应更加精准,在中文理解上表现尤为出色,且经过了安全对齐,更适合企业级应用场景。
核心代码
部署Qwen2.5-3B-Instruct的代码结构与DeepSeek类似,但需要注意其特定的提示词格式。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 模型路径
model_path = "/LLM/Qwen2.5-3B-Instruct"
print("正在加载模型和分词器...")
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 检测设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_path,
dtype=torch.float16
)
# 移动模型到设备
model = model.to(device)
print("模型已移动到设备")
print("模型加载完成,开始对话!")
print("输入问题进行问答,输入 'exit' 或 'quit' 退出程序")
print("=" * 50)
# 系统提示
system_prompt = "你是一个智能助手,能够提供准确、有用的信息。请用自然、友好的语言回答用户的问题。"
# 实时问答函数
def chat():
while True:
# 获取用户输入
user_input = input("你: ")
# 退出条件
if user_input.lower() in ["exit", "quit"]:
print("对话结束,再见!")
break
# 构建Qwen2.5的提示格式
prompt = f"{system_prompt}\n\nHuman: {user_input}\nAssistant: "
# 编码输入
inputs = tokenizer(prompt, return_tensors="pt")
# 移动到相同设备
inputs = {k: v.to(device) for k, v in inputs.items()}
# 生成回答
outputs = model.generate(
**inputs,
max_new_tokens=500, # 控制生成的新 tokens 数量
temperature=0.7,
top_p=0.95,
pad_token_id=tokenizer.eos_token_id,
do_sample=True,
repetition_penalty=1.1
)
# 解码输出
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取助手的回答
assistant_response = response.replace(prompt, "").strip()
# 显示回答
print(f"助手: {assistant_response}")
if __name__ == "__main__":
try:
chat()
except KeyboardInterrupt:
print("\n对话被用户中断,再见!")
except Exception as e:
print(f"发生错误: {e}")
import traceback
traceback.print_exc()
03 性能优化
为了让模型在嵌入式设备上跑得更快、更省资源,以下是一些关键的优化技巧。
1. 模型量化,内存大瘦身
使用INT8或INT4量化可以显著减少模型大小和内存占用。
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
# 配置4位量化
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
# 加载量化模型
model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=quantization_config
)
2. 批处理,效率大提升
对于多个输入,使用批处理能极大提高推理效率。
def generate_batch(prompts, max_length=200):
# 批量编码
inputs = tokenizer(prompts, return_tensors="pt", padding=True, truncation=True)
if torch.cuda.is_available():
inputs = {k: v.to("cuda") for k, v in inputs.items()}
# 批量生成
outputs = model.generate(
**inputs,
max_length=max_length,
temperature=0.7,
top_p=0.95,
pad_token_id=tokenizer.eos_token_id
)
# 批量解码
results = [tokenizer.decode(output, skip_special_tokens=True) for output in outputs]
return results
04 嵌入式AI,让模型无处不在
将LLM部署到嵌入式设备面临独特挑战:内存、计算资源有限,功耗敏感,且往往要求实时响应。DeepSeek-1.5B这类小型模型经过量化后,优势明显:能在资源受限环境下运行,响应速度快,且基本功能已覆盖多数嵌入式场景需求,如智能音箱的本地指令处理、工业设备的实时诊断等。
05 AI开发进阶
对于开发者而言,构建高质量的人工智能应用需要扎实的基础。这包括理解机器学习的核心范式、深度学习的组件(如神经网络、损失函数),以及语言模型的底层原理(如注意力机制)。在编程层面,熟练使用PyTorch等框架进行模型操作和调优是关键。
06 结语
从轻量的DeepSeek-1.5B到能力更强的Qwen2.5-3B,我们看到了LLM技术快速落地应用的潜力。对于开发者,这些模型是强大的创新工具。掌握其部署与优化技巧,意味着我们能将智能带到更多边缘场景,创造切实的价值。如果你在部署过程中遇到了其他有趣的问题或心得,欢迎到云栈社区与更多开发者交流探讨。
 发表于 2026-4-2 07:53:04
|
查看: 200|
回复: 0
发表于 2026-4-2 07:53:04
|
查看: 200|
回复: 0
