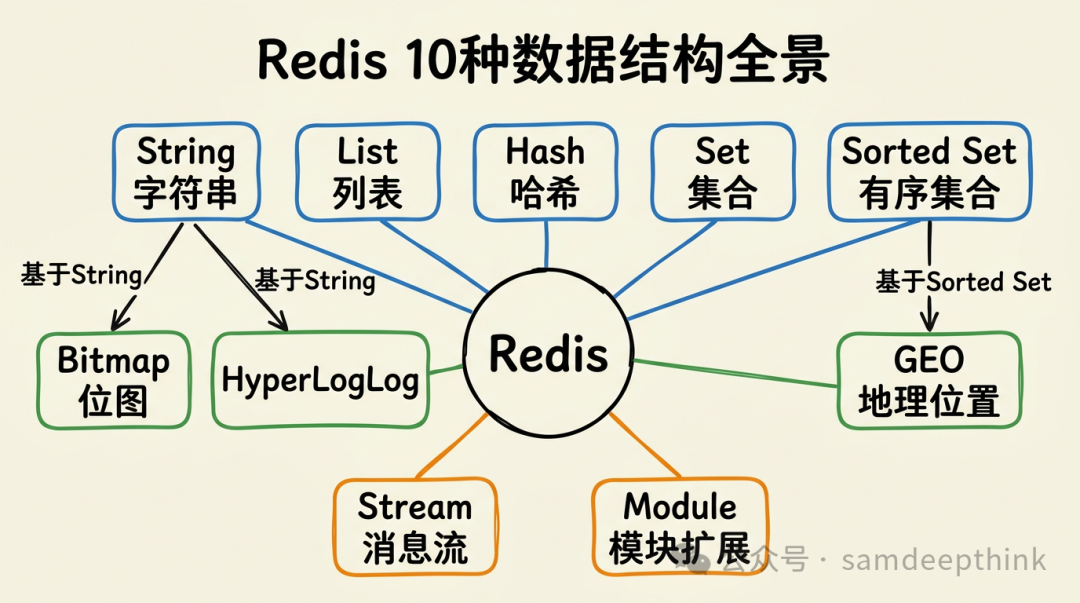
Redis有多少种数据结构?大多数人的回答是5种:String、List、Hash、Set、Sorted Set。这个答案放在Redis 3.x的时代没问题,但到了Redis 7.x,实际可用的数据结构已经有10种。除了上面5种基础类型,还有Bitmap、HyperLogLog、GEO、Stream,以及Module扩展类型。
这10种数据结构,大厂在线上系统里并不是只用其中两三种。
- 京东的购物车用Hash
- 微博的转评赞用String
- 美团的排行榜用Sorted Set,外卖的附近商家搜索用GEO,用户签到用Bitmap。
每种数据结构被选中,背后都有具体的业务原因。
下面我们先从大厂的真实使用场景出发,看看它们各自用了什么数据结构、为什么这么选,然后系统梳理Redis全部10种数据结构的特点和选型方法,末尾附了一张可以直接拿来用的选型速查表。
大厂怎么用Redis数据结构
京东到家购物车:Hash
京东到家的购物车系统,用的是Redis的Hash。
购物车的数据有一个明显的特点:一个用户在一个门店下,可能会加好几件商品,每件商品又有商品ID、数量、价格等多个属性。这种「一个Key下面挂多个字段」的结构,和Hash天然匹配。
京东到家最初的Key设计是:以用户标识作为Key,每个门店的商品作为Hash的Field。用户打开购物车时,一次HGETALL就能把这个用户在某个门店的所有商品拉出来。修改某件商品的数量时,用HSET只更新对应的Field,不需要把整个购物车的数据取出来再序列化写回去。
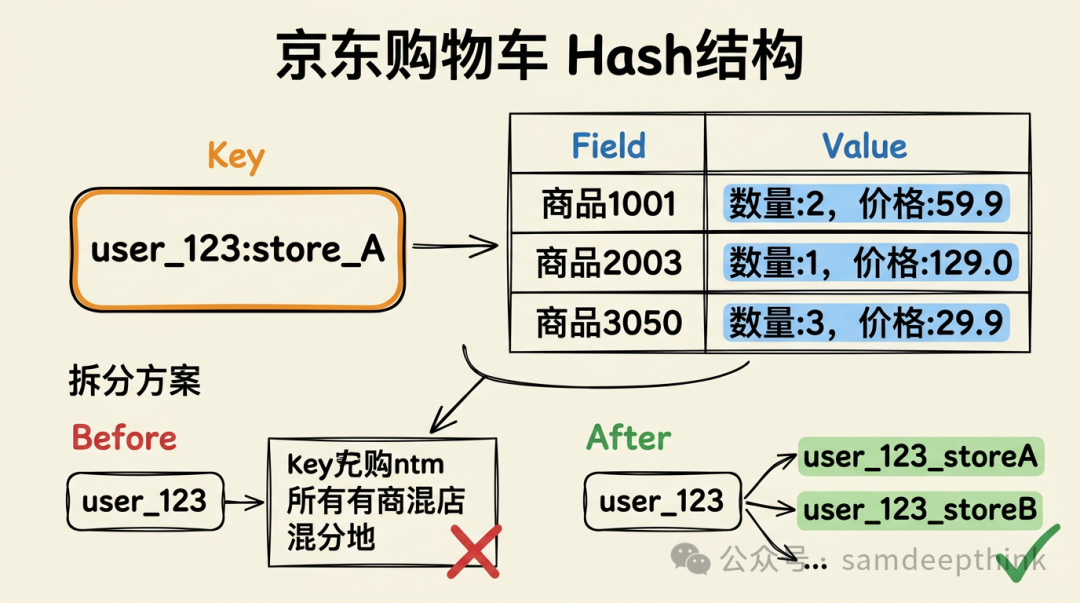
这里有个容易踩的坑。京东到家后来发现,有些用户在多个门店都加了大量商品,导致单个Hash的Field数量过多,形成了大Key。大Key的问题:
HGETALL的时间复杂度是O(n),Field越多,阻塞时间越长,严重时会影响Redis其他请求的响应。
京东云技术团队对这个问题的解决方案是拆Key:把原来的 userPin 作为Key改成 userPin_storeId,按门店维度把一个大Hash拆成多个小Hash。每个Hash只存一个门店下的商品,Field数量可控。
来源:京东云技术团队《浅析Redis大Key》 https://juejin.cn/post/7295694519184441353
为什么用Hash而不是String?如果用String存购物车,常见做法是把整个购物车序列化成JSON字符串存进去。问题在于:每次改一件商品的数量,都得先GET整个JSON,反序列化,修改,再序列化,最后SET回去。高并发下还要处理并发写入的覆盖问题。Hash天然支持字段级的读写,HSET只改一个Field,不影响其他Field,操作粒度更细、性能更好。
用Hash存购物车这种多字段对象时,Key的粒度要控制好。一个Hash里Field太多,就是大Key,读写性能都会下降。按业务维度拆Key是标准做法。
微博转评赞计数:String
微博每条内容下面的转发数、评论数、点赞数,背后用的是Redis的String。
计数场景的数据特点是:值只有一个数字,操作只有加1、减1、读取。Redis的String类型有一个INCR命令,单线程模型下天然是原子操作,不需要加锁。每条微博的转发数、评论数、点赞数各用一个独立的Key存储。
一条热门微博的点赞数可能每秒几万次写入,INCR在Redis单实例上每秒可以执行10万次以上,扛得住这个量级。
微博的关注关系也用到了Redis。用户A关注了哪些人,最初用Redis的原生Set存储,每个元素是被关注者的用户ID。这个方案功能上没问题,但内存开销大。微博后来自研了一个叫LongSet的数据结构,把用户ID当成long类型直接存储,去掉了Set底层哈希表里每个entry的指针和元数据开销,内存占用降了一个量级。
微博的信息流(关注的人发的最新内容)用的是Sorted Set,以时间戳作为分数排序。用户刷新首页时,用ZREVRANGEBYSCORE按时间倒序取最新的内容ID列表。
来源:微博技术团队陈波《新浪微博Redis优化历程》 https://www.slidestalk.com/u65/redis25919
为什么计数用String而不是Hash?假设把一条微博的转发数、评论数、点赞数都放到一个Hash里,三个计数器共享一个Key。看起来更整齐,但在Redis Cluster环境下,三个计数器放在一个Key里意味着它们一定落在同一个节点上。如果某条微博突然成为热点,三个计数器的写入压力全部集中在一个节点。拆成三个独立的String Key,有机会分散到不同的节点上,负载更均衡。单实例模式下差别不大,但在集群规模大的时候,这个设计的收益很明显。
美团排行榜和最新列表:Sorted Set与List
美团的商家排行榜、销量榜这类场景,用的是Redis的Sorted Set。
排行榜的数据有两个核心需求:每个元素有一个可比较的分数,需要按分数排序后取前N名。Sorted Set每个元素都关联一个分数(score),内部按分数自动排序。获取排名前10的商家,一条ZREVRANGE就能拿到,时间复杂度O(logN + M),N是集合大小,M是返回的元素数。
更新排名时,商家每成交一单,ZINCRBY给这个商家的分数加1。Sorted Set会自动维护排序位置,不需要应用层排序。
美团还把List用在了「最新列表」的场景上。比如最新的订单列表、最新的评价列表,这类数据的特点是只需要最近的N条,不需要排序。用LPUSH往头部插入新数据,用LTRIM保持列表长度不超过N,两条命令组合就实现了固定长度的滑动窗口。
美团的统一KV存储系统叫Squirrel,底层基于Redis Cluster构建,日均访问量达到万亿级别。
来源:美团技术博客《美团万亿级KV存储架构与实践》 https://tech.meituan.com/2020/07/01/kv-squirrel-cellar.html
来源:美团技术博客《缓存那些事》 https://tech.meituan.com/2017/03/17/cache-about.html
Sorted Set和List在「取最新N条」的场景下都能用,怎么选?关键看是否需要按分数排序。如果只需要按插入时间取最近的N条,List就够了,LPUSH + LTRIM组合效率高。如果需要按某个维度(比如销量、热度)排序,用Sorted Set。
淘宝秒杀库存扣减:String + Lua
秒杀场景的核心挑战是库存扣减。短时间内几十万请求同时抢同一个商品,库存数字必须精确,不能超卖。
阿里的做法是用Redis的String存库存数量,用DECR做原子扣减。DECR是原子操作,不存在两个请求同时读到同一个值然后各自减1的问题。
实际场景中,库存扣减通常不是只执行一个DECR,还需要先判断库存是否大于0。「判断 + 扣减」这两步如果分开执行,中间可能被其他请求插入,导致超卖。解决方案是用Lua脚本把两步操作打包成一个原子操作,Redis会把整个Lua脚本的执行当成一个不可分割的命令来处理。
-- 库存扣减Lua脚本
local stock = tonumber(redis.call('GET', KEYS[1]))
if stock > 0 then
redis.call('DECR', KEYS[1])
return 1
end
return 0
分布式锁也是String的典型应用。SET命令带上NX(不存在才设置)和EX(设置过期时间)参数,一条命令实现加锁。这个在阿里的秒杀系统里用来做请求去重和资源互斥。
来源:阿里云开发者社区《电商秒杀系统架构实战》 https://developer.aliyun.com/article/1702168
外卖和打车的附近搜索:GEO
美团外卖展示附近3公里内的商家,滴滴匹配附近的可用车辆,这类位置服务场景用的是Redis的GEO。
GEO的使用方式是:用GEOADD把商家或司机的经纬度写入Redis,用GEOSEARCH(Redis 6.2+,替代了老的GEORADIUS命令)按距离范围查询附近的元素。
GEOADD merchants:beijing 116.397128 39.916527 "shop_001"
GEOSEARCH merchants:beijing FROMLONLAT 116.40 39.92 BYRADIUS 3 km ASC COUNT 20
GEO底层并不是一种独立的数据结构,它基于Sorted Set实现。Redis把二维经纬度通过GeoHash算法编码成一个一维的52位整数,作为Sorted Set的分数存储。GeoHash的编码原理是交替对经度和纬度做二分,把二维平面递归地划分成越来越小的格子。距离相近的点,GeoHash值也相近(存在边界情况除外),这使得范围查询可以利用Sorted Set的有序性来高效完成。
GEO有一个限制:它只支持二维平面上的距离计算,不考虑海拔。对于外卖和打车场景足够了,但如果需要三维空间距离,需要应用层自己计算。
日活统计和用户签到:Bitmap与HyperLogLog
统计每天有多少用户登录了系统(日活),或者记录用户本月哪几天签到了,这类场景适合用Bitmap。
Bitmap本质上是String类型的按位操作。用SETBIT把用户ID对应的位设成1,表示该用户今天活跃。统计日活就是BITCOUNT,数一下有多少个位是1。1亿用户的日活统计只需要约12MB内存(1亿bit ≈ 12.5MB),BITCOUNT在这个数据量下的执行时间在毫秒级。
用户签到场景类似。以 sign:{userId}:{yearMonth} 作为Key,一个月最多31天,用31个bit就能表示一个用户一个月的签到记录。GETBIT查某天是否签到,BITCOUNT统计本月签到天数。
如果不需要精确数字,只需要一个大致的去重统计结果,可以用HyperLogLog。HyperLogLog是一种概率数据结构,无论统计多少个不同元素,固定占用12KB内存,标准误差0.81%。用PFADD添加元素,PFCOUNT获取去重后的近似数量。
Bitmap和HyperLogLog的选择边界:需要知道「某个用户今天有没有活跃」用Bitmap,它保留了每个用户的状态信息;只需要知道「今天总共有多少活跃用户」且允许0.81%的误差用HyperLogLog,它只保留一个聚合结果,无法查询单个用户的状态。
Redis全部数据结构速查
Redis 7.2的源码定义了7种对象类型:String、List、Set、Sorted Set、Hash、Stream、Module。加上基于String实现的Bitmap和HyperLogLog、基于Sorted Set实现的GEO,一共10种可用的数据结构。
| 数据结构 |
底层编码 |
典型命令 |
适用场景 |
大厂案例 |
| String |
RAW / EMBSTR / INT |
GET SET INCR DECR SETNX |
缓存、计数器、分布式锁、库存 |
微博转评赞计数、淘宝秒杀库存 |
| List |
QUICKLIST / LISTPACK |
LPUSH RPUSH LPOP RPOP LRANGE |
最新列表、消息队列(简易) |
美团最新订单列表 |
| Hash |
LISTPACK / HT |
HSET HGET HGETALL HINCRBY |
对象缓存、购物车、用户信息 |
京东到家购物车 |
| Set |
INTSET / LISTPACK / HT |
SADD SREM SISMEMBER SINTER |
标签、去重、交集计算 |
微博共同关注 |
| Sorted Set |
LISTPACK / SKIPLIST |
ZADD ZRANGE ZREVRANGE ZINCRBY |
排行榜、延迟队列、信息流 |
美团排行榜、微博信息流 |
| Bitmap |
基于String |
SETBIT GETBIT BITCOUNT BITOP |
签到、日活统计、布隆过滤器 |
用户签到打卡、日活统计 |
| HyperLogLog |
基于String |
PFADD PFCOUNT PFMERGE |
UV统计、去重计数(允许误差) |
页面独立访客统计 |
| GEO |
基于Sorted Set |
GEOADD GEOSEARCH GEODIST |
附近的人/商家、距离计算 |
美团外卖附近商家、打车匹配 |
| Stream |
Radix树 + LISTPACK |
XADD XREAD XGROUP XACK |
消息队列(支持消费者组) |
轻量级事件流处理 |
上面这张表覆盖了日常开发中最常用的9种数据结构。Module类型比较特殊,它是Redis的扩展机制,允许通过加载模块来定义全新的数据类型,比如RedisJSON、RediSearch、RedisTimeSeries等。Module不是Redis内置的数据结构,需要单独安装对应的模块,这里不展开。
底层编码与自动转换
Redis对同一种数据类型,会根据数据量的大小自动选择不同的底层编码方式。数据量小的时候用内存紧凑的编码(如listpack、intset),数据量大了自动转换为性能更好的编码(如哈希表、跳表)。这个转换对使用者是透明的,不需要手动干预。
以Redis 7.2源码中的默认阈值为参考:
- Hash:Field数量不超过512且每个Field和Value的长度不超过64字节时,用listpack编码;超过后转为哈希表
- Set:所有元素都是整数且数量不超过512时,用intset编码;包含非整数元素但数量不超过128且元素长度不超过64字节时,用listpack编码;超过后转为哈希表
- Sorted Set:元素数量不超过128且Value长度不超过64字节时,用listpack编码;超过后转为跳表 + 哈希表
- List:在Redis 7.2中统一使用quicklist编码,quicklist内部由listpack节点组成的双向链表构成
以上阈值来自Redis 7.2源码的默认配置值,可通过CONFIG SET命令动态调整。
这些编码转换阈值在生产环境中一般不需要改动。但如果遇到内存敏感的场景,比如有几千万个小Hash,可以适当调大listpack的阈值,让更多的Hash使用内存更紧凑的编码。反过来,如果Hash的Field数量经常超过阈值导致频繁转换,可以在Key设计时就控制好每个Hash的Field数量。
数据结构选型决策

按业务场景选数据结构,可以参考这张对照表:
| 业务场景 |
推荐数据结构 |
选型理由 |
| 缓存单个值(字符串、数字、序列化对象) |
String |
操作简单,GET/SET即可 |
| 缓存多字段对象(用户信息、商品详情、购物车) |
Hash |
字段级读写,不需要整体序列化反序列化 |
| 计数器(点赞数、浏览量、库存) |
String |
INCR/DECR原子操作,天然并发安全 |
| 排行榜(销量榜、积分榜) |
Sorted Set |
自动按分数排序,ZREVRANGE取前N名 |
| 最新列表(最新订单、最新评论,只取最近N条) |
List |
LPUSH + LTRIM固定长度滑动窗口 |
| 信息流/时间线(需要按时间排序、支持分页) |
Sorted Set |
时间戳作分数,ZRANGEBYSCORE范围查询 |
| 去重集合(标签、已读列表、共同好友) |
Set |
SADD自动去重,SINTER求交集 |
| 大规模去重计数(UV、独立IP,允许误差) |
HyperLogLog |
12KB固定内存,0.81%标准误差 |
| 二值状态记录(签到、日活、功能开关) |
Bitmap |
1亿用户只需12MB,按位操作 |
| 地理位置查询(附近商家、附近的人) |
GEO |
基于GeoHash,支持半径查询和距离计算 |
| 消息队列(需要消费者组、消息确认) |
Stream |
XGROUP + XACK,支持多消费者和消息回溯 |
| 分布式锁 |
String |
SET NX EX组合,一条命令加锁 |
| 限流(滑动窗口) |
Sorted Set |
时间戳作分数,ZRANGEBYSCORE + ZCARD统计窗口内请求数 |
有几个常见的选型纠结点值得说一下。
缓存对象用String还是Hash? 如果对象是一个整体,每次都是整体读写(比如缓存一段HTML、一个配置文件),用String更合适,一次GET拿到所有数据。如果对象有多个字段,经常只读写其中几个字段(比如用户信息里只改昵称),用Hash更合适,省掉整体序列化反序列化的开销。两者不是非此即彼的关系,同一个系统里可以根据访问模式分别使用。
消息队列用Stream还是专业MQ? Stream适合轻量级的消息场景,比如系统内部的事件通知、状态变更同步。它的优势是不需要额外部署中间件,Redis本身就能用。劣势是功能上和Kafka、RocketMQ相比有差距,没有事务消息、没有消息过滤、集群模式下的可靠性也不如专业MQ。数据量大、可靠性要求高的场景,还是用专业的消息队列。
Set和Sorted Set怎么选? Set是无序的、Sorted Set是有序的,这是最直观的区别。如果只需要去重和集合运算(交集、并集、差集),用Set。如果还需要按某个维度排序,用Sorted Set。Sorted Set每个元素多存了一个8字节的分数,内存开销比Set大一些,不需要排序的场景没必要用它。
小结
数据结构选型这件事,工作越久越觉得它不是一个技术问题,而是一个对业务数据理解程度的问题。同一个「缓存用户信息」的需求,一个人用String把JSON整体丢进去,另一个人用Hash按字段存,都能跑通。差别在高并发场景下才显现出来:前者每次改昵称都要全量读写,后者只改一个Field。这个差别不是Redis的问题,是对「这个数据会怎么被访问」的理解深度不同。
从上面这些大厂案例里能看到一个共性:它们选数据结构的依据不是「哪个功能多」,而是「数据的访问模式是什么」。京东的购物车选Hash,是因为购物车需要字段级读写。微博的计数器选String,是因为计数只需要原子递增。美团的排行榜选Sorted Set,是因为排行榜需要按分数排序。每一个选择都指向同一个判断标准:数据怎么写、怎么读、并发有多高,这三个问题的答案决定了该用哪种数据结构。
Redis给了我们10种数据结构,但日常开发中真正高频使用的就那么五六种。与其把每种数据结构的命令都背一遍,不如把业务数据的访问模式想清楚,答案自然就出来了。如果你对更多后端架构与数据库技术实践感兴趣,可以到云栈社区交流探讨。
参考的内容
- 京东云技术团队《浅析Redis大Key》
- 微博技术团队陈波《新浪微博Redis优化历程》
- 美团技术博客《美团万亿级KV存储架构与实践》
- 美团技术博客《缓存那些事》
- 阿里云开发者社区《电商秒杀系统架构实战》
另外这些文章有些是比较久了的,新的文章我没有找到。但是它至少表示了当年他们的技术选择策略,我们依然可以参考的。
 发表于 2026-4-2 08:33:55
|
查看: 181|
回复: 0
发表于 2026-4-2 08:33:55
|
查看: 181|
回复: 0
