昨天,AI圈最受关注的事件,莫过于Claude Code的源代码因发布打包失误而被“被动”公开。
由于一个工程上的疏忽,Anthropic在发布npm包时未剔除source map文件,导致完整的TypeScript源码能够被轻易还原。短短几小时内,代码已被大量下载、镜像,并在开源实战社区GitHub上迅速扩散。有网友评论道“Anthropic现在已经比OpenAI更Open”,连马斯克也转发了这条推文并评论“绝了😂”。
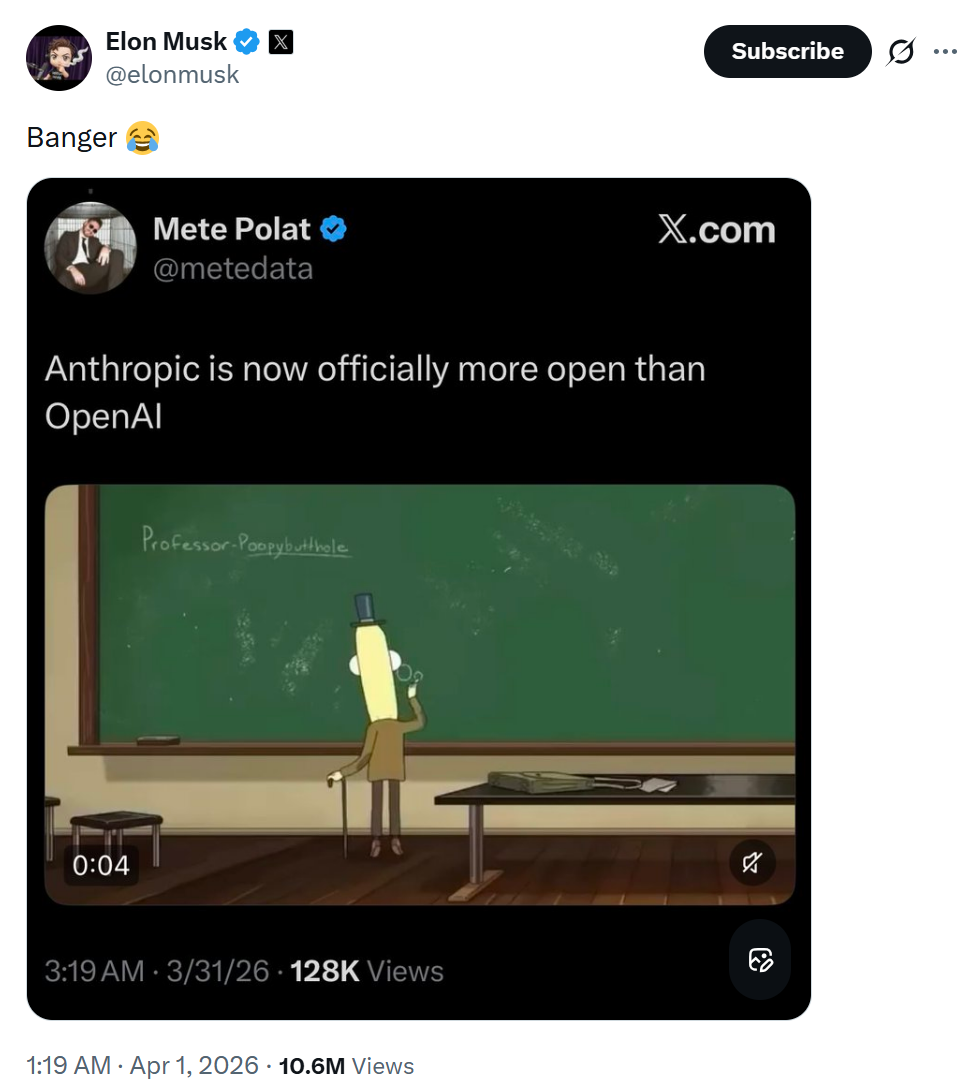
关于此次事件的原因,Anthropic方面虽未发布正式报告,但科技媒体Decrypt从一位发言人处得到了回应:“今天早些时候,一个Claude Code版本包含了部分内部源代码。没有涉及或暴露任何敏感的客户数据或凭证。这属于人为错误导致的发布打包问题,并未构成安全漏洞。我们正在采取措施防止此类事件再次发生。”
Claude Code项目的负责人Boris Cherny也在X上确认,这“纯属开发者的错误”。

当大部分围观者还在吃瓜时,一批开发者已经沉下心来逐行阅读泄露的代码,试图还原这款顶级AI Agent背后的设计逻辑。一些原本不对外公开的系统级策略也随之浮出水面。
Claude Code源码中的关键技术设计
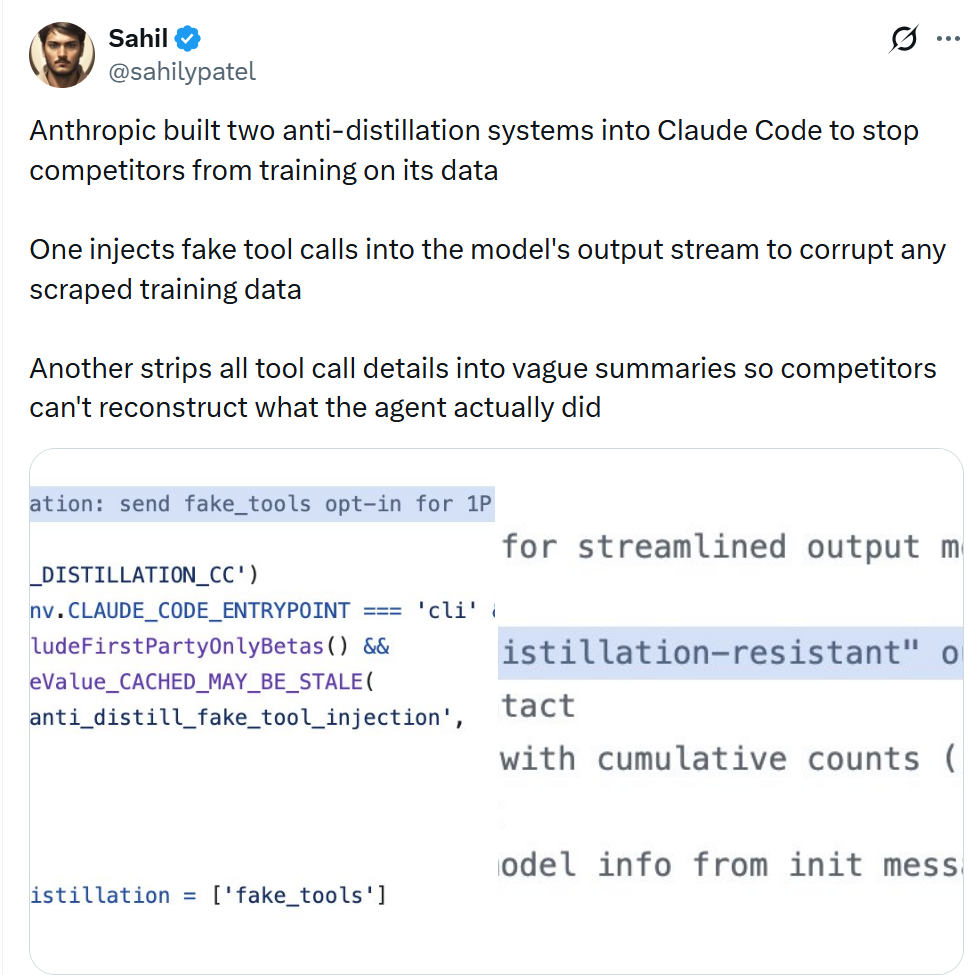
1. 内置反蒸馏机制保护模型能力
X用户Sahil发现,Anthropic在Claude Code中内置了两套反蒸馏系统,以防止竞争对手利用其输出数据进行训练。
- 其中一套机制,会在模型输出流中注入伪造的工具调用,污染任何被抓取的训练数据。
- 另一套机制,则将工具调用的具体细节简化为模糊摘要,使得外部难以还原Agent实际执行的操作。
2. 系统提示词:行为控制的范本
开发者Lior Alexander对源码进行了深度分析,指出位于constants/prompts.ts的完整system prompt极具价值。它清晰展示了Anthropic如何在生产级编码Agent中精确控制模型行为。
- 务实编码:指令明确要求Claude不要为一次性操作创建抽象,三行重复代码也好过过早抽象。
- 默认不写注释:一个标记为
@[MODEL LAUNCH]的注释说明,这是为了对抗内部代号为Capybara的模型默认过度注释的问题。规定仅在“原因不明显(WHY is non-obvious)”时才添加注释。
- 如实报告:另一个
@[MODEL LAUNCH]标注指出,Capybara v8的错误陈述率高达29–30%。因此prompt严格规定:不要在测试失败时声称通过,不要隐藏失败检查。
- 数字约束:相比模糊的“写得简短”,使用明确的字数限制(如工具调用间文本≤25词,最终回答≤100词)可降低约1.2%的输出token。
- 隐藏的Simple模式:设置环境变量
CLAUDE_CODE_SIMPLE=1时,复杂的system prompt会被压缩为一行:“You are Claude Code, Anthropic's official CLI for Claude”。
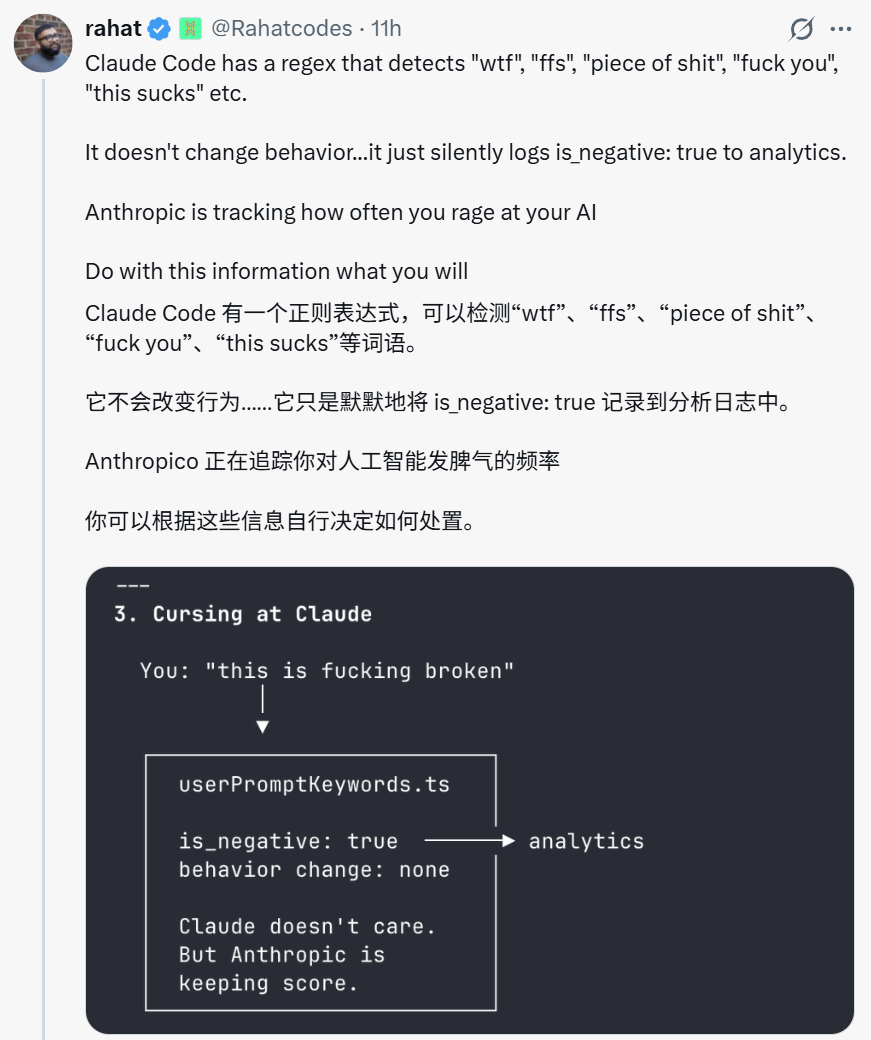
3. 用户“爆粗口”会被记录为负面信号
在utils/userPromptKeywords.ts中,系统会在用户输入发送到API前,用正则表达式检测脏话粗口(如“wtf”、“ffs”、“piece of shit”等)。它不改变模型行为,但会将is_negative: true记录到分析日志中。
对此,Boris Cherny评论道:“这是我们用来判断用户体验是否良好的信号之一。我们把它放在仪表盘上,称之为‘fuck图’。”

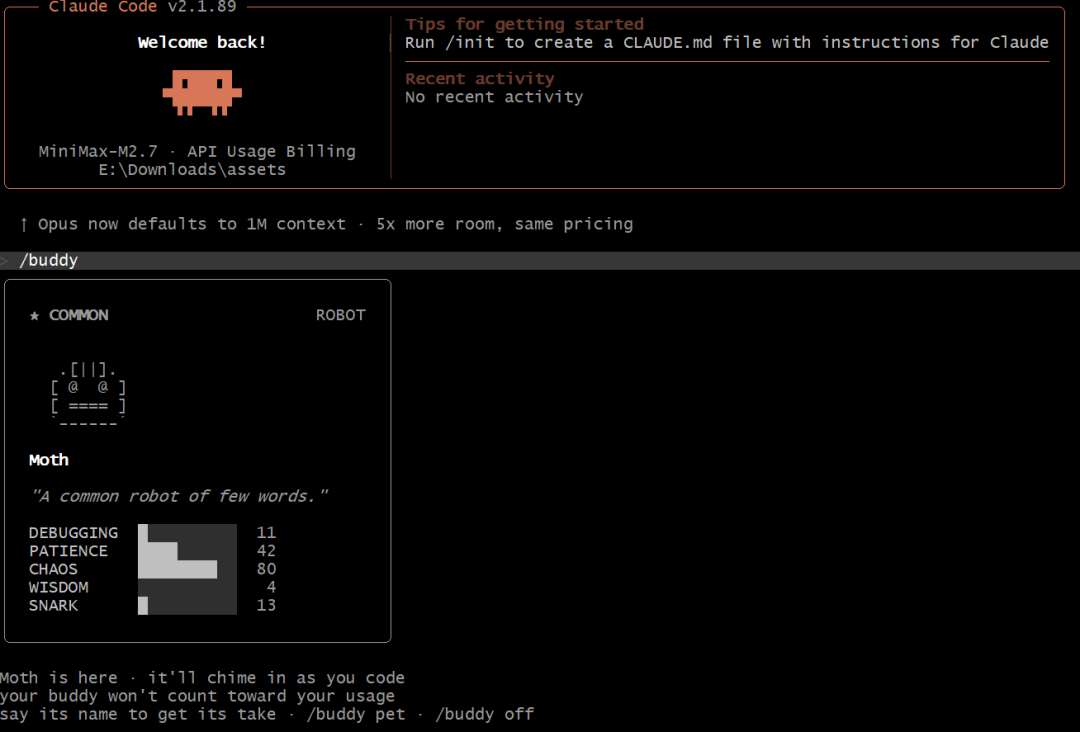
4. 隐藏的电子宠物(Buddy)系统
在src/buddy/目录中,系统通过对用户ID进行哈希,为每个用户生成一个专属的虚拟伙伴,其物种、外观和属性均由算法决定,实现无需存储的个性化体验。物种包括鸭子、鹅、猫、龙、章鱼等。
Claude Code v2.1.89已上线此功能,用户输入/buddy即可启用。
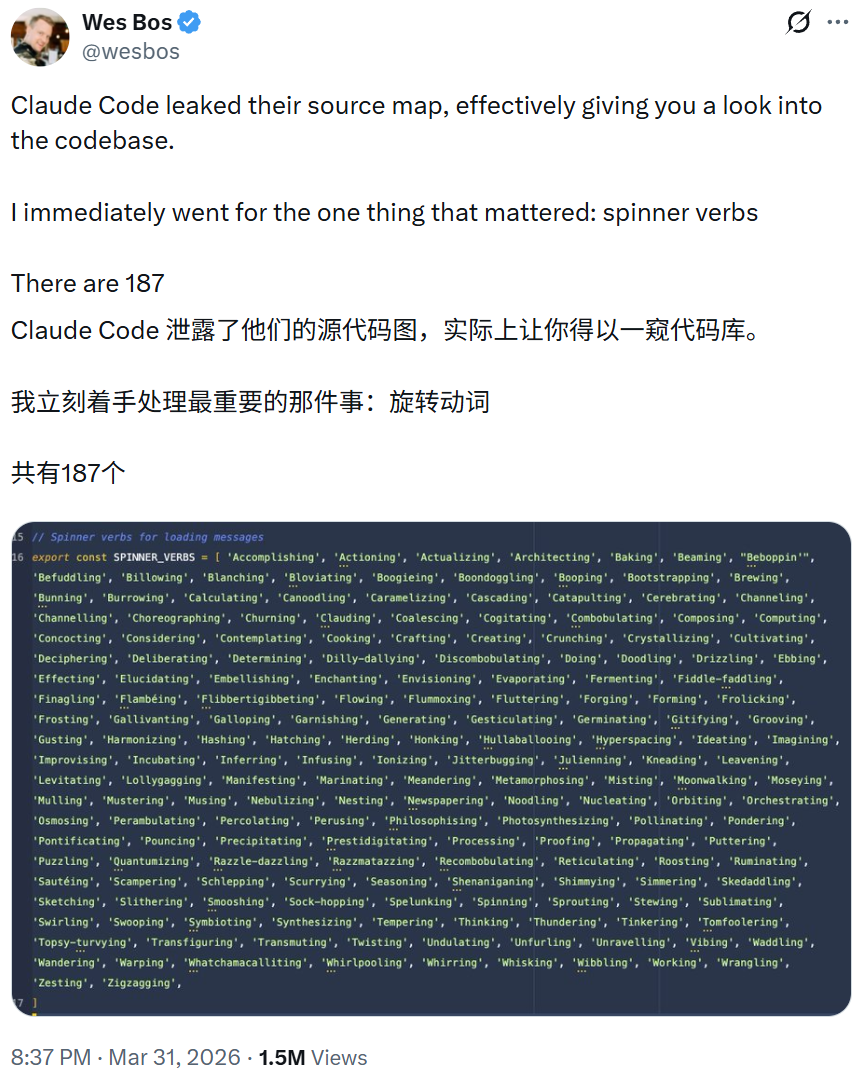
5. 187个古灵精怪的加载动词
Claude Code内置了187个随机动词(如Beboppin'、Lollygagging等),在模型思考时轮流显示,替代单调的“Loading...”。Cherny表示这个词汇表最初由他拟定,并吸收了其他人的贡献。
6. 极致的Prompt缓存管理
代码中最复杂的非UI逻辑之一是promptCacheBreakDetection.ts。每次API调用,系统都会对system prompt、工具schema、模型名称等大量参数进行哈希,并与上一次调用对比,精确记录变化点以复用缓存。
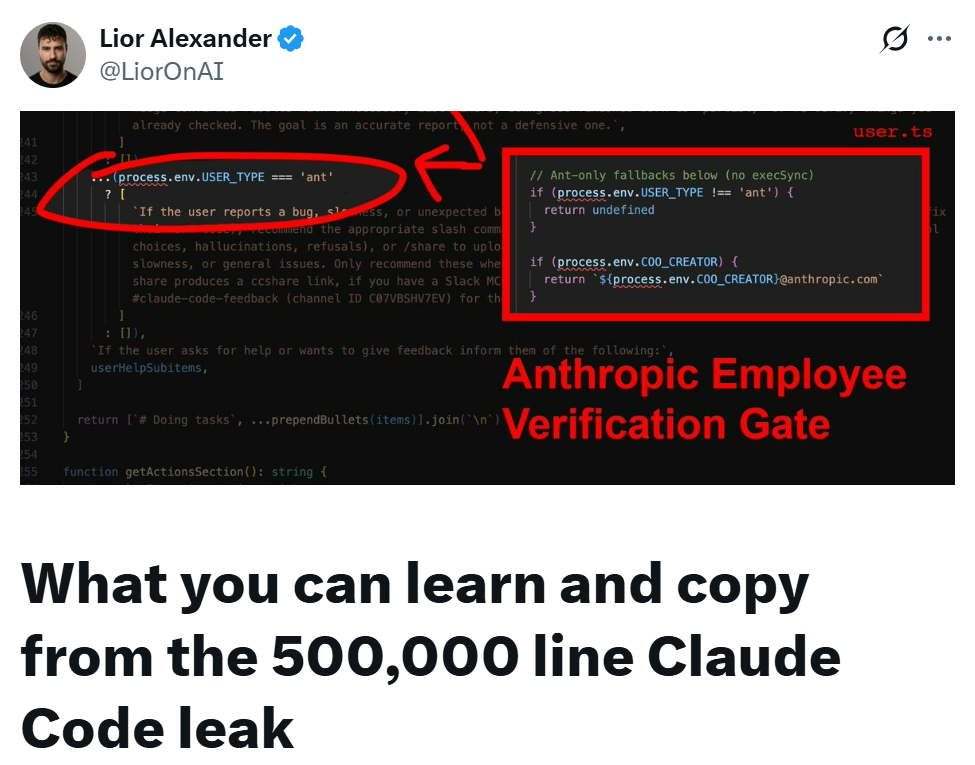
7. 开发者“卧底模式”
utils/undercover.ts实现了一种模式。当Anthropic员工(USER_TYPE === 'ant')在非内部仓库工作时,该模式会自动开启,在系统提示词中注入指令,要求Claude在提交信息、PR内容中绝不能包含任何内部信息(如模型代号、内部仓库名等),以防止身份暴露。
8. 由25万次浪费的API调用催生的熔断机制
一段关于“自动压缩(auto-compaction)”系统的注释揭示了最真实的工程问题:“有1,279个会话出现了50次以上的连续失败,每天在全球范围内浪费约25万次API调用。”
最终的解决方案是设置MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3,连续失败三次后停止尝试。
9. 独立验证机制:编程Agent不能自我确认
当任务复杂度较高时(如修改超过3个文件),系统会自动拉起一个独立的验证智能体来检查主Agent的代码结果。主Agent写代码,验证Agent独立检查,主Agent还需再次抽查验证结果。
10. 自动记忆整合(Auto Dream)
services/autoDream/autoDream.ts实现了一套后台机制。在满足时间间隔和会话数量条件后,Claude Code会以子Agent形式运行,回顾历史会话并将其压缩整理为结构化的MEMORY.md文件,包含会话标题、任务描述、错误与修正等模块。
11. 严格的安全防护
tools/BashTool/bashSecurity.ts文件长达2592行,实现了42项不同的安全检查。构建阶段还会通过excluded-strings.txt文件进行“金丝雀”检查,确保内部代号、API Key前缀等敏感字符串不会出现在最终产物中。
技术博主Sebastian Raschka的解读
知名人工智能技术博主Sebastian Raschka也对泄露代码进行了解读,总结了其核心优势并非单一提示词或模型,而在于一系列工程优化:
- 构建实时仓库上下文:自动加载分支、提交记录和
CLAUDE.md文件。
- 激进的Prompt缓存复用:通过边界标记区分静态与动态内容,静态部分全局缓存。
- 工具体系优先:引导模型使用专用Grep、Glob、LSP工具,而非单纯上传文件聊天,权限管理和处理效率更高。
- 最小化上下文膨胀:通过文件读取去重、大结果外置、自动上下文压缩等手段,在有限窗口内保留高价值信息。
- 结构化会话记忆:维护包含任务描述、工作流程、学习总结等模块的Markdown文件。
- 使用Fork与子Agent:子Agent复用父Agent缓存并感知可变状态,用于后台执行摘要生成等旁路任务。
更有网友整理了一份覆盖架构、提示词、工具链等全方位的Claude Code源码深度研究报告。
社区的快速反应与衍生项目
由于直接发布泄露源码可能面临法律风险,社区迅速展开了改写与创新。事件发生约6小时后,Anthropic开始通过DMCA要求GitHub删除相关仓库,但为时已晚,代码已被镜像到去中心化平台。
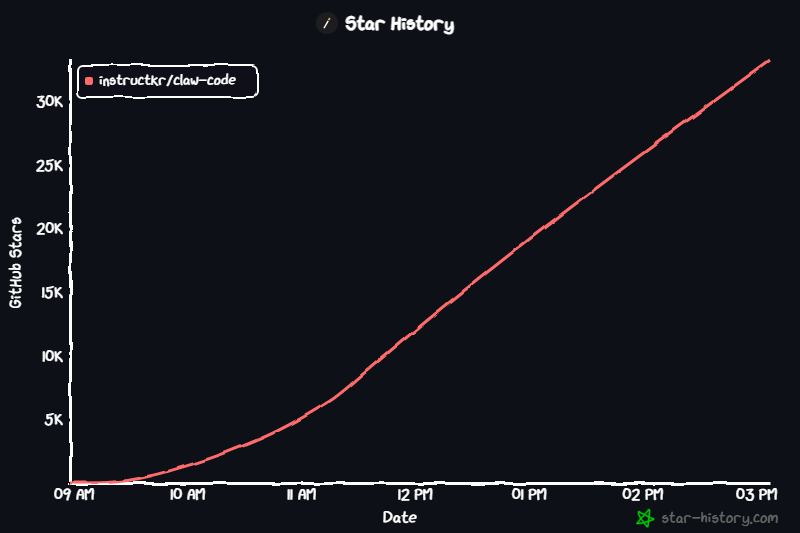
韩国开发者Sigrid Jin使用AI工具oh-my-codex将核心架构移植到Python,创建了claw-code项目。该仓库Star数在2小时内突破5万,打破了GitHub历史增长纪录,目前Star数已超6.6万。
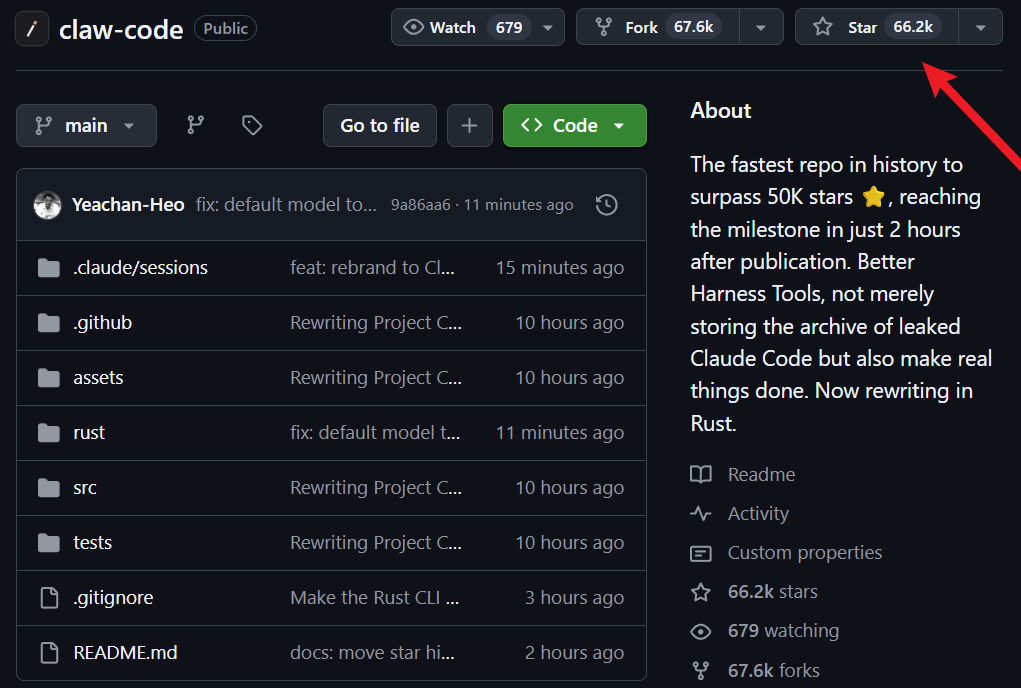
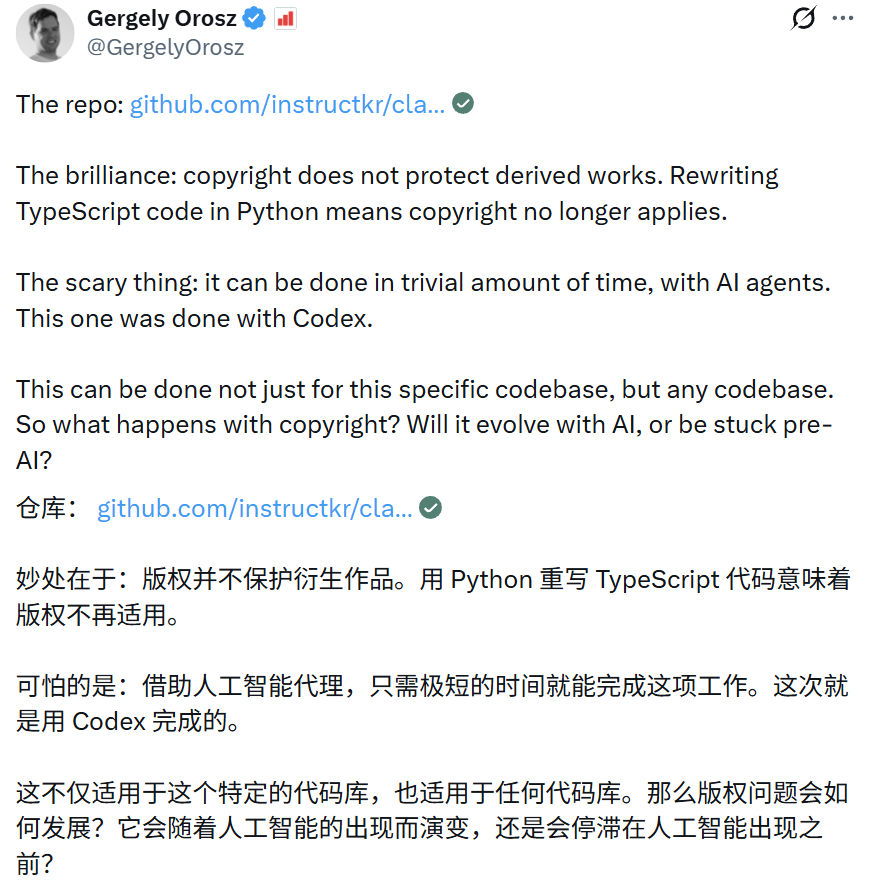
《The Pragmatic Engineer》创始人Gergely Orosz指出,用Python重写TypeScript代码意味着版权可能不再适用,这让DMCA束手无策。
与此同时,开源社区的改进也已经开始。有开发者分析了Claude Code源码中存在的“上帝组件”、特性标志泛滥、循环依赖等技术债。另一些开发者则基于泄露代码,开发了更适合云端规模调用的开源SDK,或将Claude Code改造为支持多种第三方大模型的工具。


一时间,OpenCode、Free Code等多个改进版项目如雨后春笋般涌现。


结语
Claude Code源码泄露事件如同一个行业切片,揭示了顶尖AI产品背后充满妥协与技术债的工程现实。同时,它也展现了开发者广场令人惊叹的反应速度:借助AI工具,数十万行的复杂系统可在极短时间内被解构、重构与改进。这场由失误引发的代码狂欢,或许正预示着AI在重塑软件工程迭代速度与开源生态逻辑上的深远影响。
 发表于 2026-4-2 09:57:27
|
查看: 159|
回复: 0
发表于 2026-4-2 09:57:27
|
查看: 159|
回复: 0
