前几天反思了用AI工具时的心态和方法问题。那么今天,我们回到技术本身,继续探讨高频交易系统中一个非常底层的优化手段——CPU绑核。
我们将聚焦于行情模块,结合之前文章提到的线程模型,详细拆解不同线程(如行情接收、排序、核心串行处理)的绑核逻辑、必要的Linux系统级配置,以及绑核后的效果验证方法。
绑核的核心目的是什么?
简单来说,就是避免操作系统的线程调度切换,并最大化CPU缓存的利用率。
在默认的调度策略下,操作系统会将线程随机分配到不同的CPU核心上执行。这会导致两个主要问题:
- 线程上下文切换:每次切换都会引入1~10微秒的额外时延。
- CPU缓存失效:线程被切换到另一个核心后,之前核心缓存的热数据(比如行情快照)就失效了,新核心需要重新从内存加载,这会造成巨大的性能损失。
通过绑核(CPU Affinity),我们将特定线程强制绑定到指定的物理核心上,从而保证:
- 该线程终身只在一个核心上运行,消除了切换开销。
- 该核心的L1/L2缓存始终为这个线程服务,缓存命中率可以接近100%。
实施前的关键前提
在进行绑核前,有几个系统层面的准备必须做好:
- 区分物理核心与超线程核心:高频场景下,应优先绑定物理核心。超线程核心是逻辑核心,会共享物理核心的执行单元,可能引入资源竞争,影响确定性。
- 关闭
irqbalance 服务:这个服务会自动平衡硬件中断,可能会让中断跑到你绑定的核心上,造成干扰。
systemctl stop irqbalance && systemctl disable irqbalance
- 关闭CPU超线程(极致优化,可选):
# 在BIOS中关闭,或通过内核参数关闭
echo off > /sys/devices/system/cpu/smt/control
可复用的通用绑核函数
首先,我们封装一个跨平台的绑核工具函数。这里以Linux平台(基于pthread)为例,代码具备良好的错误处理和验证机制。
#include<thread>
#include<pthread.h>
#include<stdexcept>
#include<iostream>
#include<sched.h> // for cpu_set_t
// 通用绑核函数(Linux)
// cpu_id:要绑定的核心ID(从0开始,如0、1、2...)
// t:要绑定的线程(std::jthread/std::thread)
void bind_thread_to_cpu(std::jthread& t, int cpu_id){
// 1. 校验CPU ID有效性
int cpu_count = std::thread::hardware_concurrency();
if (cpu_id < 0 || cpu_id >= cpu_count) {
throw std::invalid_argument("CPU ID " + std::to_string(cpu_id) + " is invalid (total: " + std::to_string(cpu_count) + ")");
}
// 2. 初始化CPU集合
cpu_set_t cpuset;
CPU_ZERO(&cpuset); // 清空集合
CPU_SET(cpu_id, &cpuset); // 将指定CPU加入集合
// 3. 绑定线程到CPU核心
int ret = pthread_setaffinity_np(
t.native_handle(), // 线程原生句柄
sizeof(cpu_set_t), // 集合大小
&cpuset // 要绑定的CPU集合
);
// 4. 错误处理
if (ret != 0) {
throw std::runtime_error("Failed to bind thread to CPU " + std::to_string(cpu_id) + ", errno: " + std::to_string(ret));
}
// 可选:验证绑定结果
cpu_set_t get_cpuset;
CPU_ZERO(&get_cpuset);
pthread_getaffinity_np(t.native_handle(), sizeof(cpu_set_t), &get_cpuset);
if (!CPU_ISSET(cpu_id, &get_cpuset)) {
std::cerr << "Warning: Thread bind to CPU " << cpu_id << " failed (fallback to system scheduling)" << std::endl;
} else {
std::cout << "Thread " << t.get_id() << " bound to CPU " << cpu_id << std::endl;
}
}
// 绑定当前线程到CPU核心(适用于线程内部自我绑定)
void bind_current_thread_to_cpu(int cpu_id){
std::jthread t(std::this_thread::get_id());
bind_thread_to_cpu(t, cpu_id);
}
行情模块各线程的绑核落地
结合行情模块的特点,我们按照“核心隔离”原则来分配CPU核心。以下是一个概念示例,具体分配需根据实际设计的线程数量和订阅规模调整。
| 线程类型 |
绑定核心建议 |
核心原则 |
| 行情接收线程(4个) |
CPU 0、1、2、3 |
独占物理核心,避免与其他线程共享 |
| 排序线程(4个) |
CPU 4、5、6、7 |
与接收线程对应,就近分配核心(减少缓存跨核心传输) |
| 串行核心线程(因子/模型) |
CPU 8 |
独占一个物理核心,无任何其他线程干扰 |
| 监控/日志线程 |
CPU 15(超线程核心) |
低优先级,使用非核心资源 |
(1) 行情接收线程绑核示例
// 行情接收线程池
class MarketDataReceiver {
private:
static constexpr size_t kRecvThreadNum = 4; // 4个接收线程
std::array<std::jthread, kRecvThreadNum> recv_threads_;
// 接收线程工作函数
void recv_worker(int thread_id, int nic_queue_id){
// 可选:线程内部自我绑定(兜底,避免外部绑定失效)
bind_current_thread_to_cpu(thread_id);
// 原有行情接收逻辑
MD_SDK_Init(nic_queue_id);
auto stock_list = get_stock_range(thread_id);
MD_SDK_Subscribe(stock_list.data(), stock_list.size());
MD_SDK_Run();
}
public:
MarketDataReceiver() {
// 初始化接收线程并绑核
for (int i = 0; i < kRecvThreadNum; ++i) {
// 创建线程(绑定到网卡队列i)
recv_threads_[i] = std::jthread(
&MarketDataReceiver::recv_worker,
this,
i, // 线程ID
i // 网卡队列ID(与CPU核心一一对应)
);
// 绑定到CPU i(物理核心)
bind_thread_to_cpu(recv_threads_[i], i);
}
}
};
(2) 排序线程绑核示例
// 线程级排序器
class ThreadLevelSorter {
private:
static constexpr size_t kSortThreadNum = 4;
std::array<std::jthread, kSortThreadNum> sort_threads_;
// 排序线程工作函数
void sort_worker(int thread_id, OutputFunc output_func){
// 自我绑定到CPU 4+thread_id(如thread_id=0→CPU4,thread_id=1→CPU5)
bind_current_thread_to_cpu(4 + thread_id);
// 原有排序逻辑
std::unordered_map<std::string_view, StockSortBuffer<128>> stock_buffers_;
MarketData md;
while (true) {
// 处理行情排序...
_mm_pause();
}
}
public:
ThreadLevelSorter(OutputFunc output_func) {
// 初始化排序线程并绑核
for (int i = 0; i < kSortThreadNum; ++i) {
sort_threads_[i] = std::jthread(
&ThreadLevelSorter::sort_worker,
this,
i,
output_func
);
// 绑定到CPU 4+i
bind_thread_to_cpu(sort_threads_[i], 4 + i);
}
}
};
(3) 串行核心线程绑核示例
// 串行核心(因子/模型/策略)
class SerialCore {
private:
std::jthread core_thread_;
void core_worker(){
// 自我绑定到CPU 8(独占核心)
bind_current_thread_to_cpu(8);
// 原有串行处理逻辑
MarketData md;
while (true) {
if (global_mpsc_queue.pop(md)) {
calculate_factor(md);
model_inference(md);
strategy_logic(md);
} else {
_mm_pause();
}
}
}
public:
SerialCore() {
core_thread_ = std::jthread(&SerialCore::core_worker, this);
// 绑定到CPU 8
bind_thread_to_cpu(core_thread_, 8);
}
};
系统级核隔离配置
为了让绑定的核心能被我们完全独占(避免系统进程或内核线程的抢占),可以进行系统级核隔离。这需要在Linux内核启动参数中进行配置。
- 编辑
/etc/default/grub,在 GRUB_CMDLINE_LINUX_DEFAULT 参数中添加:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash isolcpus=0-8 nohz_full=0-8 rcu_nocbs=0-8"
isolcpus=0-8:隔离CPU 0~8,系统默认的调度器不会将普通进程调度到这些核心上。nohz_full=0-8:为CPU 0~8启用完全无滴答模式(Tickless),减少时钟中断的干扰。rcu_nocbs=0-8:指定这些核心不处理RCU回调,进一步降低内核开销。
- 更新grub配置并重启系统:
update-grub && reboot
绑核效果验证方法
绑核是否生效,需要从代码、系统和性能三个层面进行验证。
(1) 代码层验证
可以在线程函数中插入检查逻辑。
// 验证当前线程绑定的CPU核心
int get_current_thread_cpu_id(){
int cpu_id = sched_getcpu();
if (cpu_id == -1) {
throw std::runtime_error("Failed to get current CPU ID");
}
return cpu_id;
}
// 在线程工作函数中添加验证
void core_worker(){
bind_current_thread_to_cpu(8);
std::cout << "Current thread CPU ID: " << get_current_thread_cpu_id() << std::endl;
// 输出应为8,验证绑核成功
}
(2) 系统级验证
使用Linux命令工具进行查看。
# 查看线程的CPU亲和性(替换<pid>为进程ID)
ps -eo pid,pcpu,cmd | grep <你的程序名>
# 查看指定线程的绑核情况(替换<tid>为线程ID)
taskset -cp <tid>
# 示例输出(线程12345绑定到CPU8)
pid 12345's current affinity list: 8
(3) 性能验证
- 绑核前:使用
perf stat -p <pid> 查看线程的上下文切换次数 (context-switches),每秒可能高达数千次。
- 绑核后:上下文切换次数应降至极低水平(0~10次/秒),同时缓存未命中率 (
cache-misses) 应有显著下降(通常可降低80%以上)。这是衡量绑核优化是否有效的黄金标准。
必须警惕的跨NUMA问题
在多路服务器上,绑核有一个核心风险点:跨NUMA访问。
NUMA(Non-Uniform Memory Access) 是一种内存架构设计。简单理解,你的服务器如果有两个CPU插槽,通常就对应两个NUMA节点。每个节点有自己的“本地”内存,访问速度很快。但如果运行在CPU0上的线程,去访问CPU1管理的内存(即“远程内存”),延迟会大幅增加。
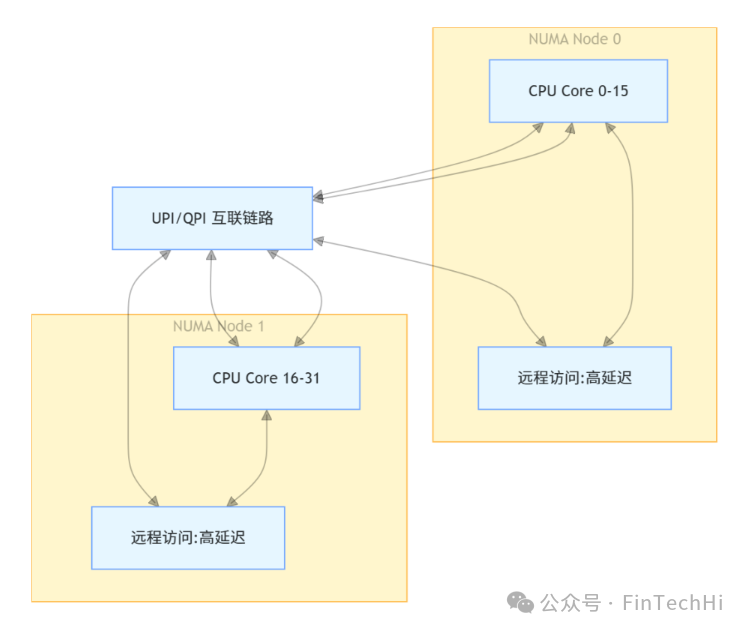
对于行情模块,线程、该线程访问的内存、以及它收包所用的网卡队列,这三者必须严格处于同一个NUMA节点内。如果线程绑在节点0,内存分配在节点1,网卡队列在节点2,那延迟将会是灾难性的。
优化原则:遵循“同NUMA节点绑定”。可以使用 numactl、lstopo 等工具查看系统拓扑,确保关键线程和资源位于同一节点。关闭NUMA自动均衡,并优先从本地节点分配内存。
总结
行情模块的CPU绑核是实现低延迟的关键手段。通过封装通用的绑核工具函数,我们可以灵活地将行情接收、排序、核心处理等线程绑定到指定的物理核心上。配合系统级的核心隔离、中断关闭等优化,可以最大化CPU的独占性和缓存效率。实施后,务必通过代码检查、系统命令和性能剖析工具进行三重验证,并特别注意规避跨NUMA访问带来的性能陷阱。
希望这篇关于高频交易系统绑核实践的分享能对你有所启发。如果你想了解更多关于系统设计或底层优化的内容,欢迎持续关注云栈社区的后续更新。
 发表于 2026-4-3 03:06:36
|
查看: 194|
回复: 0
发表于 2026-4-3 03:06:36
|
查看: 194|
回复: 0
