当 Linux 内核发生致命错误时,只要 CPU 还能继续运行,最重要的任务就是向用户输出详细的错误信息,并保存问题发生时的现场。这些致命错误通常分为两种类型:
- 硬件检测到的错误:例如非法内存访问、执行非法指令等。此时 CPU 会触发异常,并进入预设的异常处理流程,最终在处理流程中触发 oops 或 panic。
- 代码逻辑进入异常分支:内核代码在某些情况下进入无法正常处理的代码路径,如果继续执行可能导致不可预知的后果。此时,相关代码会主动调用 oops 或 panic 函数。
其中,panic 意味着内核已无法继续运行。它会根据配置决定是否进行 crash dump 内存转储,向关注 panic 事件的模块发送通知,并打印相关的系统信息,最后将系统挂起或重启。
oops 的严重程度通常低于 panic,因此一般情况下它只会输出错误信息并终止出错的进程,而不会挂起整个内核。但是,如果 oops 发生在中断上下文中,或者内核配置了 panic_on_oops 选项,那么它也会升级并进入 panic 流程。
2 ARM64 架构的异常信息寄存器
对于 ARM64 架构,如果 CPU 因内存访问错误等原因进入异常状态,可以通过 ESR_EL1 寄存器获取异常原因,并通过 FAR_EL1 寄存器获取触发异常的内存地址信息。
ESR_EL1 (Exception Syndrome Register) 寄存器的位域结构如下:

上图中,EC (Exception Class) 字段表示异常类型。以下是部分典型的 EC 取值及其含义:
- b100000:来自较低异常等级(如用户态)的指令错误。
- b100001:当前异常等级(如内核态)的指令错误。
- b100010:程序计数器 (PC) 对齐错误。
- b100100:来自较低异常等级的 data abort 异常(如用户态内存访问错误)。
- b100101:当前异常等级的 data abort 异常(如内核态内存访问错误)。
- b100110:栈指针 (SP) 对齐错误。
- b101111:SError(系统错误)中断。这是一种异步异常,通常来自外部 Abort,例如在内存访问总线上产生的错误。
IL (Instruction Length) 字段表示异常发生时正在执行的指令长度:
- 0:表示 16 位的 Thumb 指令。
- 1:表示 32 位的 AArch32 指令或 64 位的 AArch64 指令。
ISS (Instruction Specific Syndrome) 字段给出了每种异常类型的具体原因,其具体含义取决于 EC 字段的值。以 EC 为 data abort 为例,其 ISS 的位域定义如下(详细说明可参考 ARMv8 技术参考手册):
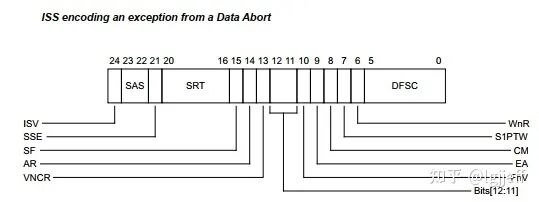
其中,DFSC (Data Fault Status Code) 用于提供 data abort 相关的详细信息,以下为其部分定义:

此外,对于 data abort 类型的异常,发生错误的地址对于分析问题至关重要。ARMv8 架构通过 FAR_EL1 (Fault Address Register) 寄存器提供了该地址(虚拟地址)的值,其寄存器定义如下:

3 内核异常处理流程
当内核发生同步异常后,会根据异常发生时所处的异常等级(当前等级还是较低等级)以及使用的栈指针类型(sp_el0 还是 sp_el1),跳转到相应的异常向量表入口。
异常处理函数在执行一些基础工作(如保存上下文、切换栈指针)后,会跳转到特定类型的 handler。例如,如果 CPU 在 AArch64 模式下触发异常,且使用的是 sp_el1 栈指针,则会跳转到 el1h_64_sync_handler 函数。
该函数会读取 ESR_EL1 寄存器,解析其中的 EC 字段值以确定异常类型,然后调用该类型对应的处理函数。在处理函数中,通常会进一步解析 ESR_EL1 寄存器中 ISS 字段的值来获取具体原因,并执行相应操作。
在处理流程中,如果确认异常是由非法操作引起的(注意:并非所有异常都是错误,例如缺页异常、调试断点都属于正常的处理逻辑),则会调用 oops 或 panic 向用户报告错误,并终止当前进程或挂起系统。
由于内核的异常种类繁多,而处理流程又大同小异,下面我们以 AArch64 模式下内核态非法地址访问为例,来梳理其处理路径:

3.1 Data Abort 处理流程
el1h_64_sync_handler 首先读取 ESR_EL1 寄存器的值,解析 EC 字段,并根据 EC 值调用对应的处理函数。对于 data abort 异常,它会调用 el1_abort 函数。以下是其代码片段:
asmlinkage void noinstr el1h_64_sync_handler(struct pt_regs *regs)
{
unsigned long esr = read_sysreg(esr_el1);
switch (ESR_ELx_EC(esr)) {
case ESR_ELx_EC_DABT_CUR:
case ESR_ELx_EC_IABT_CUR:
el1_abort(regs, esr);
break;
case ESR_ELx_EC_PC_ALIGN:
el1_pc(regs, esr);
break;
…
default:
__panic_unhandled(regs, “64-bit el1h sync”, esr);
}
}
el1_abort 会进一步调用 do_mem_abort。这个函数会根据 ESR_EL1 寄存器中 DFSC 字段的值,调用对应的具体处理函数。这些函数通过一个名为 fault_info 的数组来定义:
static const struct fault_info fault_info[] = {
…
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, “level 0 translation fault” },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, “level 1 translation fault” },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, “level 2 translation fault” },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, “level 3 translation fault” },
{ do_bad, SIGKILL, SI_KERNEL, “unknown 8” },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, “level 1 access flag fault” },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, “level 2 access flag fault” },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, “level 3 access flag fault” },
…
}
do_mem_abort 的代码如下:
void do_mem_abort(unsigned long far, unsigned int esr, struct pt_regs *regs)
{
const struct fault_info *inf = esr_to_fault_info(esr); // (1)
unsigned long addr = untagged_addr(far); // (2)
if (!inf->fn(far, esr, regs)) // (3)
return;
if (!user_mode(regs)) { // (4)
pr_alert(“Unhandled fault at 0x%016lx\n”, addr);
mem_abort_decode(esr);
show_pte(addr);
}
arm64_notify_die(inf->name, regs, inf->sig, inf->code, addr, esr);
}
- 根据 DFSC 值在
fault_info 数组中选择对应的处理函数指针。
- ARM64 架构可能利用虚拟地址的高位存储 tag 信息以支持 MTE 特性,因此获取真实虚拟地址时需要移除 tag。
- 调用
fault_info 中获取到的回调函数。对于地址翻译错误,回调函数通常是 do_translation_fault。
- 如果是未知的异常类型,则执行后续的错误处理流程。
do_translation_fault 会根据异常是由用户态还是内核态触发,分别调用对应的处理函数:
static int __kprobes do_translation_fault(unsigned long far,
unsigned int esr,
struct pt_regs *regs)
{
…
if (is_ttbr0_addr(addr))
return do_page_fault(far, esr, regs); // (1)
do_bad_area(far, esr, regs); // (2)
return 0;
}
- 用户态地址错误处理。
- 内核态地址错误处理。
对于内核态的情形,最终会调用 die_kernel_fault 执行实际的错误处理:
static void die_kernel_fault(const char *msg, unsigned long addr,
unsigned int esr, struct pt_regs *regs)
{
…
mem_abort_decode(esr); // (1)
show_pte(addr); // (2)
die(“Oops”, regs, esr); // (3)
bust_spinlocks(0);
do_exit(SIGKILL); // (4)
}
- 解析
ESR_EL1 寄存器的值,并分别打印 EC、IL、DFSC 等内容。
- 打印异常地址对应的各级页表(PGD、P4D、PUD、PMD、PTE)信息。
- 执行核心的 die 操作,此流程将在下一节详述。
- 杀死当前进程。
3.2 die 处理流程
die 函数主要执行 oops 相关流程。如果异常发生在中断上下文中,或者内核配置了 panic_on_oops 选项,则会进一步调用 panic 挂起系统。其主要流程如下:
void die(const char *str, struct pt_regs *regs, int err)
{
…
ret = __die(str, err, regs); // (1)
if (regs && kexec_should_crash(current))
crash_kexec(regs); // (2)
…
if (in_interrupt())
panic(“%s: Fatal exception in interrupt”, str);
if (panic_on_oops) // (3)
panic(“%s: Fatal exception”, str);
…
}
- 调用已注册的 die 通知链函数,执行相关操作,并打印 oops 信息。
- 如果需要 crash 系统(例如配置了 kdump),则此函数会启动一个新的 crash 内核来转储系统内存信息以供事后分析。
- 如果异常发生在中断中,或者设置了
panic_on_oops,则调用 panic 挂起系统。理解这些底层机制对于深入计算机基础原理至关重要。
3.3 panic 处理流程
当内核执行到 panic 时,表明系统已无法继续运行,需要执行一些系统挂死前的准备工作,主要包括:
- 防止并发 panic:在 SMP 系统中,一个 CPU 正在处理 panic 时,另一个 CPU 可能也会触发 panic。由于 panic 流程涉及错误信息收集和内存转储等操作,通常不需要也不支持并发执行。因此,后续触发的 CPU 将不会重复执行主要流程。
- 调试器接管:如果正在使用 kgdb 调试内核,控制权会转交给调试器,而不是立即挂死系统。
- 内存转储:如果配置了 kdump 等功能,则会启动内存转储流程。
- 停止其他 CPU:在 SMP 系统中挂死前,需要停止所有其他 CPU 的运行。
- 最终操作:打印相关系统信息后,使系统重启或进入死循环。
其核心代码实现如下:
void panic(const char *fmt, ...)
{
…
this_cpu = raw_smp_processor_id();
old_cpu = atomic_cmpxchg(&panic_cpu, PANIC_CPU_INVALID, this_cpu);
if (old_cpu != PANIC_CPU_INVALID && old_cpu != this_cpu) // (1)
panic_smp_self_stop();
…
pr_emerg(“Kernel panic - not syncing: %s\n”, buf);
…
kgdb_panic(buf); // (2)
if (!_crash_kexec_post_notifiers) {
printk_safe_flush_on_panic();
__crash_kexec(NULL); // (3)
smp_send_stop(); // (4)
} else {
crash_smp_send_stop(); // (5)
}
atomic_notifier_call_chain(&panic_notifier_list, 0, buf); // (6)
printk_safe_flush_on_panic();
kmsg_dump(KMSG_DUMP_PANIC); // (7)
if (_crash_kexec_post_notifiers)
__crash_kexec(NULL); // (8)
…
panic_print_sys_info(); // (9)
if (!panic_blink)
panic_blink = no_blink;
if (panic_timeout > 0) {
pr_emerg(“Rebooting in %d seconds..\n”, panic_timeout);
for (i = 0; i < panic_timeout * 1000; i += PANIC_TIMER_STEP) {
touch_nmi_watchdog();
if (i >= i_next) {
i += panic_blink(state ^= 1);
i_next = i + 3600 / PANIC_BLINK_SPD;
}
mdelay(PANIC_TIMER_STEP); // (10)
}
}
if (panic_timeout != 0) {
if (panic_reboot_mode != REBOOT_UNDEFINED)
reboot_mode = panic_reboot_mode;
emergency_restart(); // (11)
}
…
pr_emerg(“—[ end Kernel panic - not syncing: %s ]—\n”, buf);
suppress_printk = 1;
local_irq_enable();
for (i = 0; ; i += PANIC_TIMER_STEP) {
touch_softlockup_watchdog();
if (i >= i_next) {
i += panic_blink(state ^= 1);
i_next = i + 3600 / PANIC_BLINK_SPD;
}
mdelay(PANIC_TIMER_STEP); // (12)
}
}
- 如果已经有其他 CPU 正在处理 panic,当前 CPU 只需停止自身,不再重复处理主流程。
- 打印 panic 原因信息。系统级别的严重故障往往与网络/系统层面的深层交互有关。
- 如果信任内存转储的可靠性(
_crash_kexec_post_notifiers 为假),则优先执行转储操作。__crash_kexec 会根据是否配置了转储内核来决定是否真正执行 kexec 切换。若执行,则不会返回。
- 停止当前 CPU 之外的所有其他 CPU。
- 另一种停止其他 CPU 的方式(用于
_crash_kexec_post_notifiers 为真的情况)。
- 调用已注册的 panic 事件通知链函数。
- 转储内核 log buffer 中的日志信息。
- 如果设置了
_crash_kexec_post_notifiers,则在此处根据配置决定是否执行内存转储。
- 如果不执行内存转储,则打印系统相关信息(如活动任务列表等)。
- 如果设置了
panic_timeout 超时值,则执行超时等待。
- 超时等待完成后,重启系统。
- 如果未设置
panic_timeout 超时值,则系统进入死循环,完全挂死。
4 如何手动触发 oops 和 panic
在开发过程中,可能会遇到一些非预期的代码分支,进入这些分支意味着出现了问题或严重错误。根据问题的严重程度,我们可能希望程序打印警告信息、触发 oops,甚至直接 panic。
内核提供了一些宏和函数来支持这些需求,以下是一些常用的:
WARN_ON():打印警告信息和调用栈,但不会进入 oops 或 panic。BUG_ON():打印 bug 相关信息,并进入 oops 流程。panic():该函数将直接触发 panic 流程,导致系统挂死。
除了在代码中调用,用户还可以通过 SysRq 魔术键来触发 panic。以下是通过 proc 文件系统触发 SysRq panic 的命令:
echo c > /proc/sysrq-trigger
原文链接:https://www.zhihu.com/column/c_1533871448917118976 版权归原作者所有,如有侵权,请联系作者删除。
希望本文对您理解 Linux 内核错误处理机制有所帮助。更多关于操作系统、编译原理等深度技术讨论,欢迎访问 云栈社区 与广大开发者交流。
 发表于 2026-4-3 04:22:17
|
查看: 160|
回复: 0
发表于 2026-4-3 04:22:17
|
查看: 160|
回复: 0
