核心成果速览
本文还原了2026腾讯游戏安全技术竞赛安卓决赛的完整技术链路。最终产物为 flag_tool.exe,输入屏幕左上角的8位十六进制Token,可同时输出三个Flag。完整工具调用:
flag_tool.exe encrypt <token>
以 Token a2d576a6 为例,三个部分的算法与Flag对应关系如下:

该工具源码支持加密/解密/验证功能,16组测试向量全部通过。
01 引擎识别与资源提取
1.1 引擎识别
APK解包后在 assets/ 目录下发现 assets.sparsepck,结合 lib/arm64-v8a/libgodot_android.so 以及 AndroidManifest 中的 com.godot.game 包名,可以确认引擎为 Godot 4.5(开源游戏引擎)。
关键二进制文件及其用途:

1.2 AES密钥提取
PCK资源经AES-256-CFB128加密。在IDA中追踪密钥的完整链路如下:
① 定位 open_and_parse
搜索RTTI字符串 "19FileAccessEncrypted"(地址 0x945101),通过typeinfo交叉引用找到 sub_38013D0(即 FileAccessEncrypted::open_and_parse,9处调用)。
② 确认AES调用
sub_38013D0 内部的AES初始化序列:
// sub_38013D0 (open_and_parse) 伪代码摘录
sub_376EDC0(ctx); // mbedtls_aes_init
sub_376EE1C(ctx, *(this + 352), 256); // mbedtls_aes_setkey_enc(ctx, key, 256)
sub_376EF88(ctx, len, *(this + 336), in, out); // mbedtls_aes_crypt_cfb128
sub_376EDF0(ctx); // mbedtls_aes_free
③ 追踪密钥来源
this+352 处的密钥由调用者传入。反查交叉引用,sub_3804BEC(xref 0x3804F08)和 sub_3805E9C(xref 0x3806140)均通过逐字节循环从 byte_400EF18 复制密钥:
// sub_3805E9C 伪代码摘录
do {
v23 = byte_400EF18[i]; // .data 段静态密钥
key_buf[i++] = v23;
} while (...);
sub_38013D0(fae, &file, &key_vec, 0, 0, &iv); // open_and_parse
④ 读取密钥
在IDA中直接读取 byte_400EF18,32字节即为AES-256密钥:
地址 0x400EF18:
CE 4D F8 75 3B 59 A5 A3 9A DE 58 AC 07 EF 94 7A
3D A3 9F 2A F7 5E 32 84 D5 12 17 C0 4D 49 A0 61
1.3 CFB128解密
APK解包后 assets/ 目录下的 .gdc/.scn 均为加密文件,格式如下:
[0..16] MD5(明文校验)
[16..24] uint64 LE 明文长度
[24..40] 16-byte IV
[40..] AES-256-CFB128 密文
用1.2节提取的密钥做标准CFB128解密,校验 MD5(明文) == 文件头MD5 通过,确认决赛使用标准CFB128(初赛为position-XOR变体)。解密后得到10个 .gdc(GDSC magic)和7个 .scn(场景文件)。
加密输入: final/assets/(10个 .gdc + 7个 .scn)
解密产物: solve/decrypted/(仅 .gdc;.scn 在 patch_trigger4_scn.py 中就地解密处理)
CFB128实现在 patch_trigger4_scn.py 的 cfb128_decrypt_standard() 函数中。
02 GDScript字节码反混淆
2.1 问题发现
标准 gdre_tools 反编译输出乱码——关键字错位(if 变成 match,func 变成 signal 等),说明自定义引擎对GDScript tokenizer的token ID做了重映射。
对照Godot 4.5开源代码 modules/gdscript/gdscript_tokenizer.h 的标准GDSC格式,定位到两处自定义修改:
标识符 XOR 加密
标准Godot的identifier pool是明文UTF-32 LE,解密后字节码的标识符全部乱码。利用已知明文推断(标识符中必然包含 _ready、extends 等),用预期ASCII与实际字节逐字节XOR,得到固定密钥 0xB6。
Token ID 重映射
标准枚举中 FUNC=74, VAR=77, IF=58 等被打乱为 FUNC=71, VAR=81, IF=51 等。
2.2 GDSC二进制格式
[0..4] "GDSC" magic → [4..8] version (0x65=Godot4.5) → [8..12] decompressed_size
[12..] zstd payload → 解压后: 标识符池 → 常量池 → 行号表 → token 流
标识符UTF-32 LE每字节XOR 0xB6(解密后得到合法ASCII变量名)。Token流每项4/8字节,word1[0:7] = token type(重映射ID),word1[8:] = pool index,word2 = 行号(可选)。
2.3 Token重映射表恢复
从最简单的脚本(label2.gdc、token.gdc)开始,利用GDScript语法结构逐步推断映射:
IDENTIFIER(12) / LITERAL(13)
最先确定——它们携带pool index,出现频率最高。
结构关键字
func name(args): 模式 → 确定 FUNC(71)、PAREN_OPEN(88)、PAREN_CLOSE(89)、COLON(95)。
控制流
if ... : / while ... : / for ... in ... → 确定 IF(51)、WHILE(55)、FOR(54)、IN(72)。
运算符
结合加密代码上下文,& 0xFF → AMPERSAND(26),^ key → CARET(29),<< 3 → LESS_LESS(30)。
共恢复35+个映射(部分摘录):
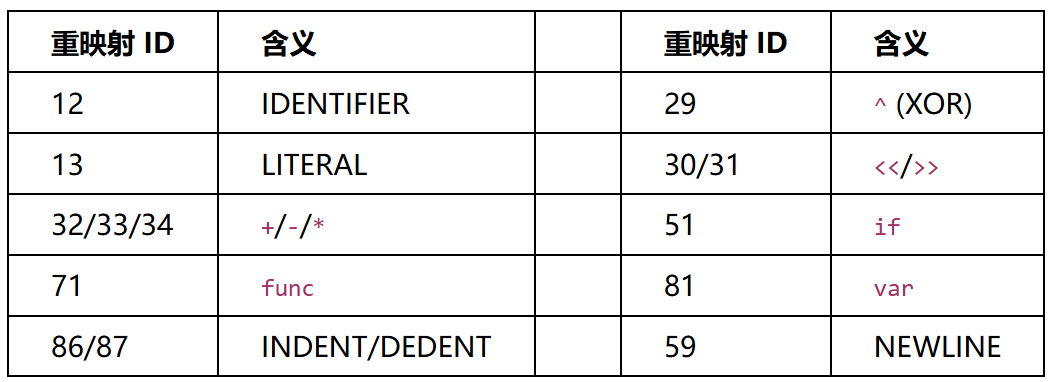
由于token枚举表内联在引擎解释器中,未以独立数据结构存在,无法直接从二进制提取,改用上述语义推断法逐一恢复。完整映射表见 parse_gdc.py。
2.4 自定义解析器
python solve/godot/parse_gdc.py <file.gdc> --reconstruct # 反编译为 GDScript
python solve/godot/parse_gdc.py <file.gdc> --raw # 原始 token 流
所有10个 .gdc 均成功反编译为可读GDScript。
产物: solve/godot/parse_gdc.py
2.5 反编译结果——三个计分Trigger
反编译后可读出完整flag生成逻辑。完整反编译源码见 solve/decompiled/Trigger/。
trigger2.gd — PART1(纯GDScript Feistel)
碰撞回调 _w7 读取Token,调用 _fe() 做8轮Feistel加密,密钥 "Sec2026_Godot",输出flag。算法完全在GDScript中,无native参与:
func _w7(_ar):
var _tk := str(_lt.text).substr(7) # "Token: a1b2c3d4" → "a1b2c3d4"
var _rs := _fe(_tk) # Feistel 加密
_lb.text = "flag{" + _rs + "}" # flag{sec2026_PART1_XXXXXXXX}
trigger3.gd — PART2(调native Process)
碰撞回调将Token的UTF-8字节(注意:不是hex→bytes,是ASCII直传)传给 GameExtension.Process(),由 libsec2026.so 的自定义AES加密:
func _w7(_ar):
var _raw := str(_lt.text).substr(7) # "a1b2c3d4"
var _buf := _raw.to_utf8_buffer() # ASCII 字节,不是 hex decode
var _rv := _gx.Process(_buf) # ★ native 加密
_lb.text = "flag{sec2026_PART2_" + _rv + "}"
trigger4.gd — PART3(完全native)
没有 body_entered.connect(),碰撞不由GDScript处理。GDScript侧仅有 _gx.Tick() 每帧调用(后续逆向证实Tick仅做反剥离计时,见4.3节)。真正的flag生成由碰撞触发的native隐藏回调完成(见第七章7.3节):
func _ready():
_gx = GameExtension.new()
func _process(_d):
_gx.Tick() # 仅反剥离计时,不触发 PART3 计算
_rv = _d # delta time
_tv += _d * 2.0
_m3()
03 libsec2026.so 逆向基础
3.1 字符串解密
IDA打开 libsec2026.so 后,搜不到任何明文字符串("Process"、"Tick"、"ClassDB" 等均不存在)。观察到大量函数具有相同的prologue特征(FFC300D1 E01700F9 E11300F9 E20F00F9 E31700B9),其反编译结果为XOR解密循环,将 .rodata 密文写入 .bss 段:
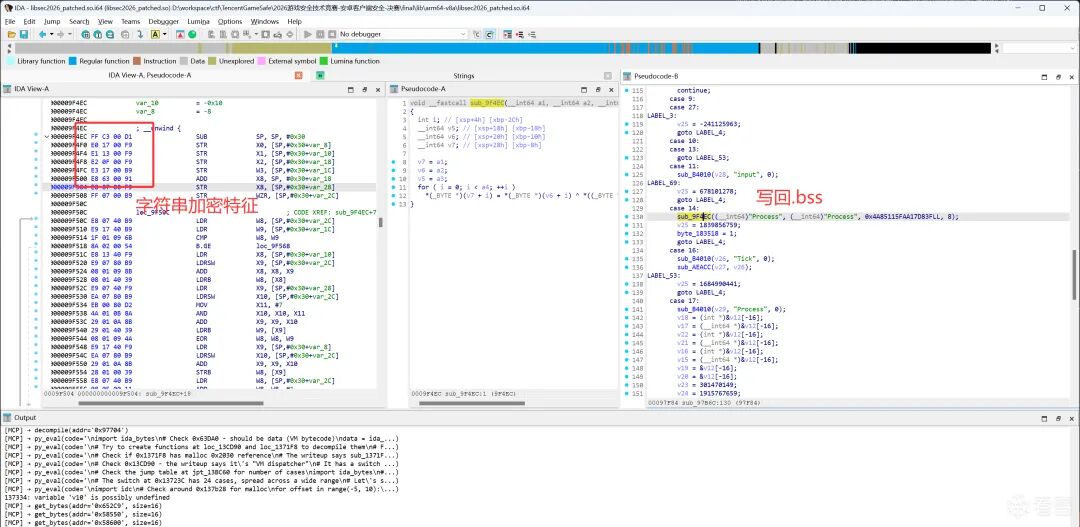
两种变体:
- XOR_PLAIN:
out[i] = cipher[i] ^ key[i % 8]
- XOR_WITH_INDEX:
out[i] = cipher[i] ^ i ^ key[i % 8]
编写IDAPython脚本 ida_decrypt_strings.py:搜索 .text 段中具有上述prologue特征的解密函数(共31个),反编译每个调用者提取 (dest, src, key, len) 四元组,批量解密并在IDA中添加注释。
解密后发现的关键字符串和对应功能:

通过字符串解密,定位到 sub_97B6C 为方法注册入口(注册Process/Tick/input三个GDExtension方法),进而追踪到PART2 handler(sub_97704)和Tick handler(sub_9AD68)。
3.2 CFF去混淆
libsec2026.so 全部函数均被CFF(Control Flow Flattening)混淆,存在两种变体。
变体A — 集中式CMP树
用于辅助函数(字符串解密、反调试等)。所有基本块共享一个中央dispatcher,state是32-bit编码hash,经 EOR+ADD 解码后通过CMP二叉搜索树匹配目标块:
block_i:
... 业务代码 ...
MOV W8, #0x7DDB08B6 // 下一个 state(编码 hash)
CSEL W8, W9, W8, EQ // 条件分支:根据结果选 hash
B dispatcher
dispatcher: // 全函数唯一
EOR W8, W8, #0xC3 // 解码 step 1
ADD W8, W8, #0x71 // 解码 step 2
CMP W8, #0x1EE0E901 // CMP 二叉搜索树
B.LE lower_half
CMP W8, #0x316195C5
B.EQ block_17 // 匹配 → 跳转
...
IDA需手动解析hash解码 + CMP树。
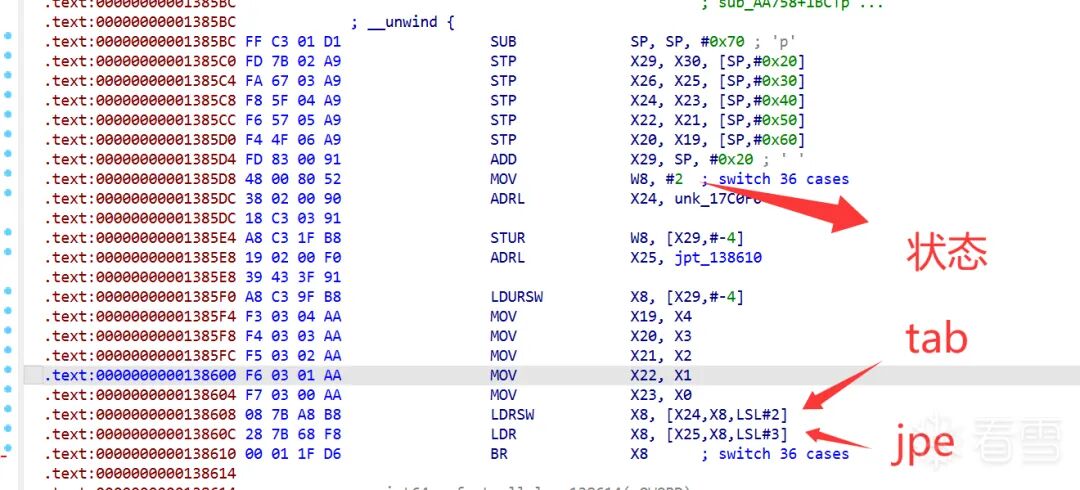
变体B — 内联双表派发
用于核心加密函数(AES sub_A936C、TEA sub_A9A7C 等,共约136个)。没有中央dispatcher,每个块后内联一套两级查找:
prologue:
ADRL X22, state_tab // dword 查找表
ADRL X23, jpt // qword 跳转表
block_i:
... 业务代码 ...
MOV W8, #next_state // state = 小整数 (0~127)
STUR W8, [X29, #-4]
LDURSW X8, [X29, #-4] // ① 读 state
LDRSW X8, [X22, X8, LSL#2] // ② state_tab[state] → jpt 索引
LDR X8, [X23, X8, LSL#3] // ③ jpt[idx] → 代码块地址
BR X8 // ④ 间接跳转(每个块都有完整副本)
两级查找的反分析效果:
state_tab[] (dword): jpt[] (qword):
┌────────┬──────┐ ┌─────┬────────────┐
│state 0 │→ 10 │ │ [0] │ 0x130644 │
│state 1 │→ 5 │ │ [1] │ 0x130184 │
│state 2 │→ 26 │ │ ... │ ... │
│ ... │ ... │ │[44] │ 0x13031C │
└────────┴──────┘ └─────┴────────────┘
① 多个 state 可映射到同一 jpt 索引(代码块共享)
② jpt 中混入冗余条目,干扰静态枚举
③ state 常量不直接对应跳转目标,对抗常量传播
内联派发消除了集中dispatcher这个单点突破口;间接表使state常量不再直接对应跳转目标——同时对抗两类自动化攻击。
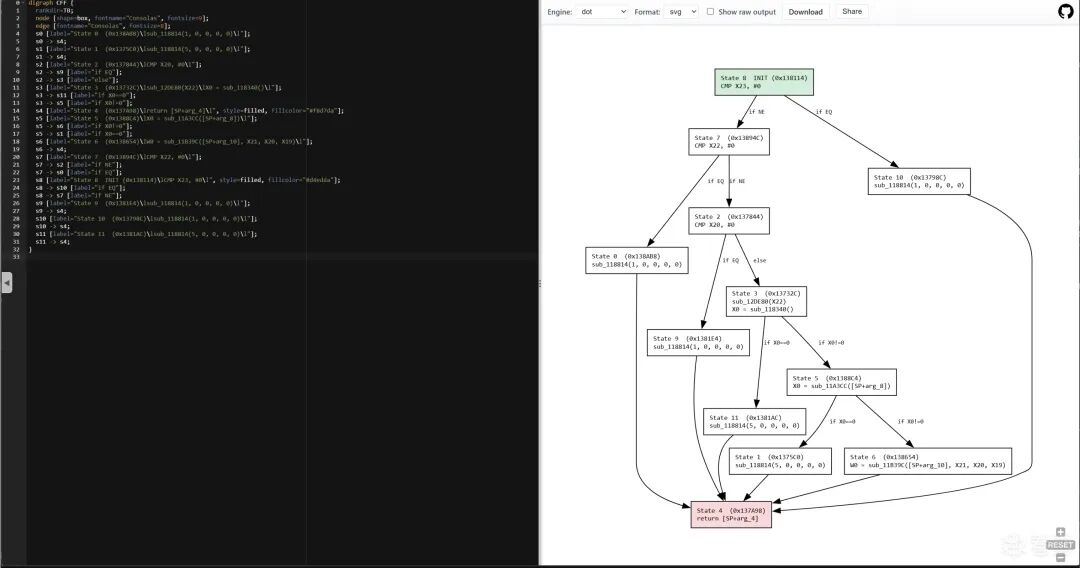
去混淆方案
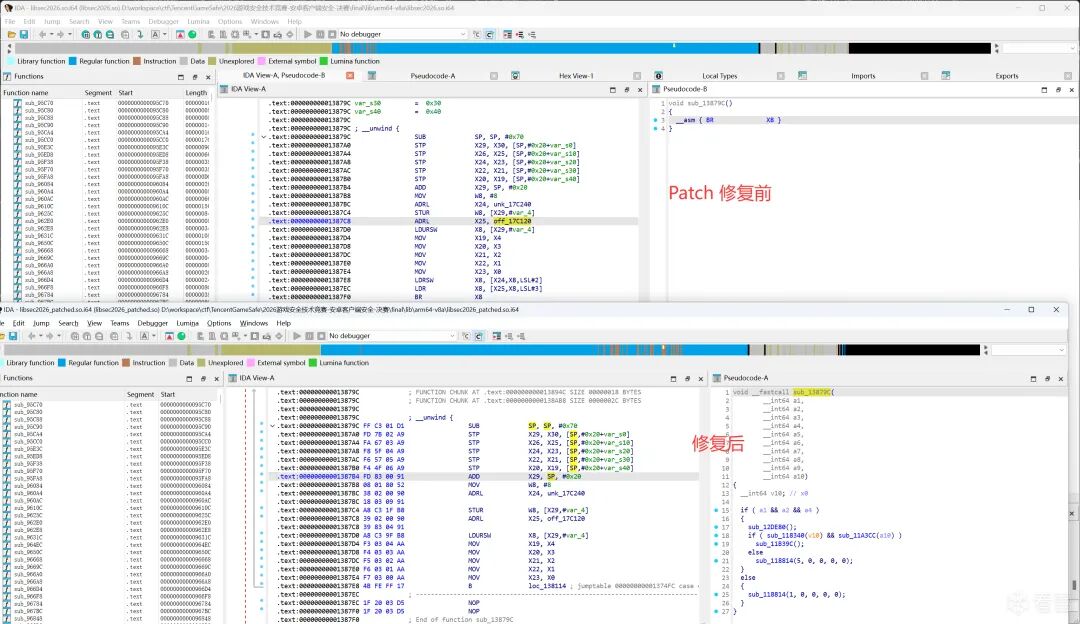
三种方案逐步演进,最终IDA工具链覆盖全部变体B函数:
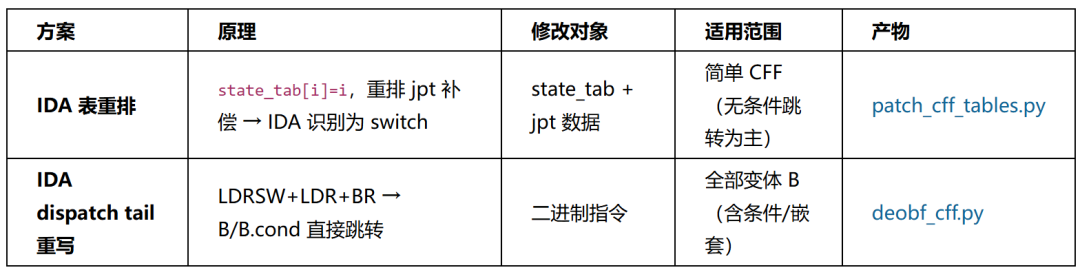
IDA dispatch tail重写覆盖率 134/136(98.5%),2个跨块寄存器传递需手动处理。花指令NOP(patch_junk_code.py)作为预处理步骤清除干扰指令。
单层CFF(变体A:集中式CMP树dispatcher):
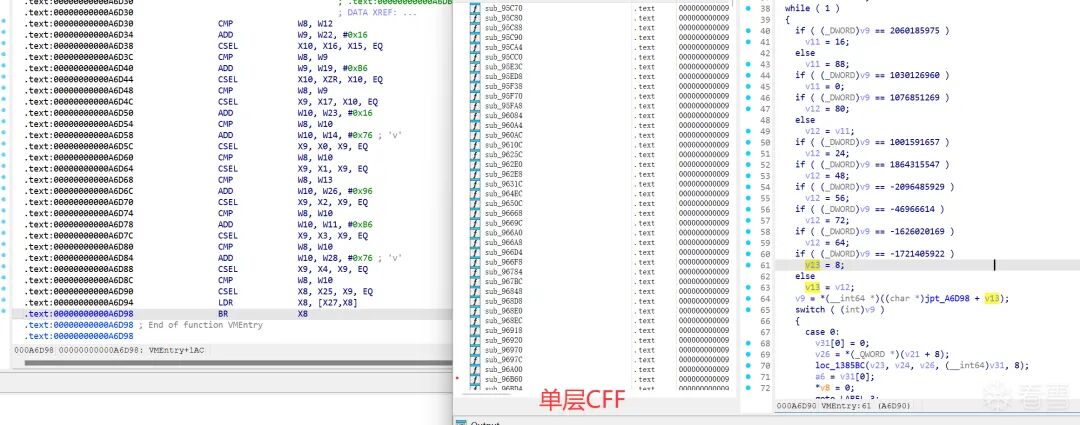
双层CFF(变体B:内联双表 state_tab[state] → jpt[idx] → BR):
Patch修复前后对比(IDA函数列表 + 反编译,修复前截断 vs 修复后完整):
还原后的控制流图(CFG状态机可视化):
04 反调试绕过
4.0 检测发现方法
直接Frida attach会被秒杀(exit_group(0)),静态分析面对全函数CFF混淆也很难枚举所有检测点。这里采用了自研模拟器沙箱完整捕获 libsec2026.so 的运行时行为。
日志规模:单次运行产生约1.5GB trace,包含每条syscall的编号、参数、返回值,以及每个库函数调用的函数名和参数。
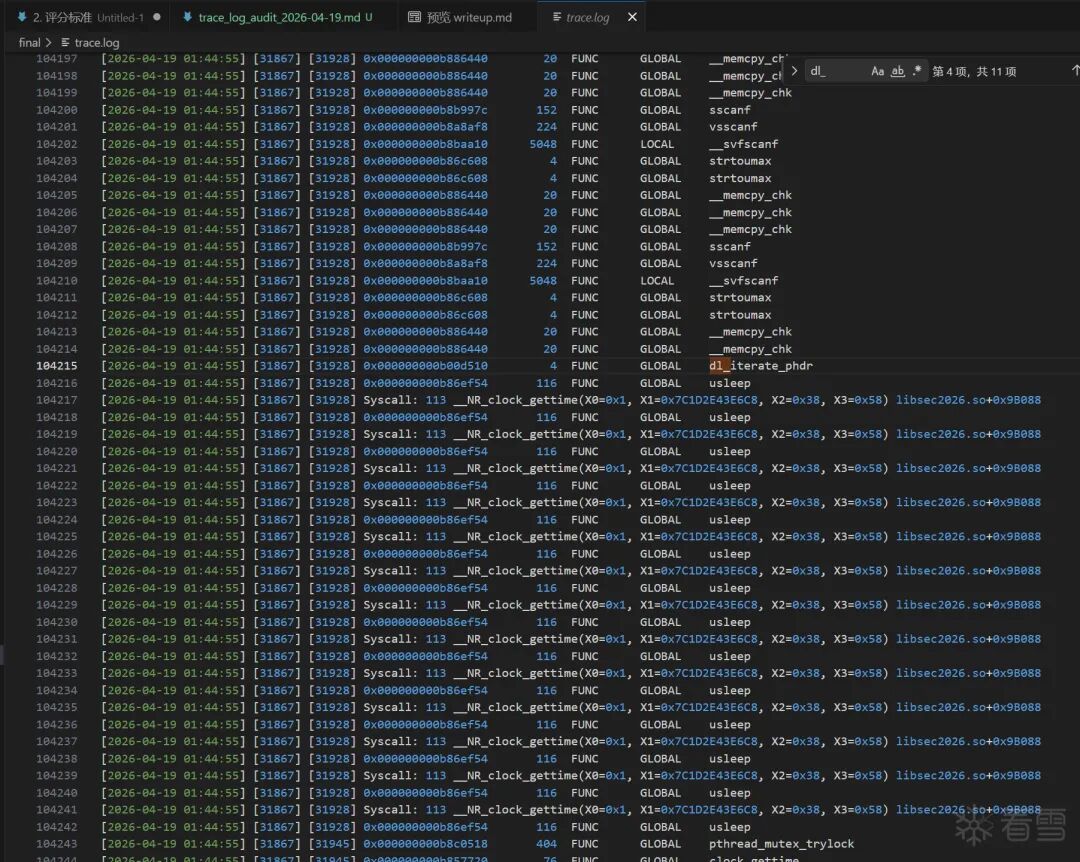
筛选过程:将trace日志交由AI分析,按syscall编号和参数模式自动分类——标记出 openat("/proc/self/task")、openat("/proc/self/fd")、openat("/proc/self/maps")、ptrace(ATTACH)、process_vm_readv、clock_gettime 高频调用等异常模式。每个AI标记的检测点再回到IDA中定位对应函数、反编译确认逻辑。最终梳理出3个检测线程共9项检测机制。
检测总入口 — sub_99094 创建3个pthread:
// sub_99094 — 检测线程总入口
void sub_99094() {
pthread_create(&t1, 0, sub_9C654, 0); // ptrace 自保护 + 硬件断点清除
pthread_create(&t2, 0, sub_9CDC4, 0); // Frida 线程名 + 注入器检测
pthread_create(&t3, 0, sub_9B7D8, 0); // exit 反 hook + CRC32 完整性心跳 + maps 扫描
}
4.1 Frida线程检测(sub_9CDC4)
后台线程循环扫描 /proc/self/task/*/status,搜索线程名 gum-js-loop(Frida)/ gmain(GLib),检测到则 exit_group(0)。
// sub_9CDC4 (0x9CDC4 ~ 0x9EA1C) — 约70 case CFF,精简后:
void frida_detection_thread() {
sleep(1);
// 解密字符串
// sub_97AE0 → "/proc/self/task"
// sub_96848 → "gum-js-loop"
// sub_9A9A8 → "gmain"
DIR *dir = opendir("/proc/self/task");
while ((ent = readdir(dir)) != NULL) {
snprintf(path, 256, "/proc/self/task/%s/status", ent->d_name);
int fd = syscall(56 /*openat*/, AT_FDCWD, path, O_RDONLY);
// 逐行读取,搜索 "gum-js-loop" 或 "gmain"
if (strstr(line, "gum-js-loop") || strstr(line, "gmain"))
syscall(94 /*exit_group*/, 0); // 杀进程
}
sub_99418(); // 接着执行注入器检测
}
绕过:Hook openat,当路径含 /proc/self/task 时替换为无效路径。
4.2 注入器检测(sub_99418)
扫描 /proc/self/fd,readlinkat 读取每个fd的符号链接目标,搜索 linjector。
// sub_99418 (0x99418 ~ 0x9A1EC) — 精简后:
void injector_detection() {
// 解密: "/proc/self/fd", "linjector"
DIR *dir = opendir("/proc/self/fd");
while ((ent = readdir(dir)) != NULL) {
snprintf(path, 256, "/proc/self/fd/%s", ent->d_name);
lstat(path, &st);
if ((st.st_mode & S_IFMT) == S_IFLNK) {
syscall(78 /*readlinkat*/, AT_FDCWD, path, buf, 256);
if (strstr(buf, "linjector"))
syscall(94 /*exit_group*/, 0);
}
}
}
绕过:同上,Hook openat 拦截 /proc/self/fd。
4.3 检测线程心跳 + CRC32完整性互锁(sub_9AD68 ↔ sub_9AF98 ↔ sub_96A00)
通过逆向 sub_9AD68(Tick handler)和交叉引用 data_1834b8,发现它并非简单的"帧间隔检测",而是与代码完整性校验构成心跳互锁机制。
写端 — 检测线程(sub_96A00 → sub_9AF98):
sub_96A00 每约14秒通过 dl_iterate_phdr 获取 .text 段,调用 sub_9AF98 计算CRC32(多项式 0xEDB88320)。关键在于 sub_9AF98 的CRC32循环中,每处理4096字节就执行一次 usleep(10μs) + clock_gettime 并更新全局变量 data_1834b8(心跳时间戳)。
// sub_9AF98 — CRC32 + 心跳
uint32_t crc32_with_heartbeat(uint8_t *data, size_t len, uint32_t init) {
uint32_t crc = init;
for (size_t i = 0; i < len; i++) {
uint32_t val = crc ^ data[i];
for (int j = 0; j < 8; j++) // 标准 CRC32
val = (val & 1) ? (0xEDB88320 ^ (val >> 1)) : (val >> 1);
crc = val;
if ((i & 0xFFF) == 0) { // 每 4096 字节
usleep(10);
clock_gettime(CLOCK_MONOTONIC, &ts);
data_1834b8 = ts.tv_sec * 1000000 + ts.tv_nsec / 1000; // 更新心跳
}
}
return ~crc;
}
校验结果不匹配 → exit_group(0) 杀进程。
读端 — Tick handler(sub_9AD68)
每帧读取 data_1834b8,与当前时间比对:
// sub_9AD68 — Tick handler
void tick_handler() {
if (data_1834b8 == 0) { // 首次调用:初始化
clock_gettime(CLOCK_MONOTONIC, &ts);
data_1834b8 = ts.tv_sec * 1000000 + ts.tv_nsec / 1000;
return;
}
clock_gettime(CLOCK_MONOTONIC, &ts);
int64_t now = ts.tv_sec * 1000000 + ts.tv_nsec / 1000;
if (llabs(now - data_1834b8) > 10000000) // > 10 秒
return; // 心跳超时 → 停止处理
}
互锁设计:
- 检测线程存活时:CRC32循环不断更新
data_1834b8 → Tick读到新鲜心跳 → 正常
- 检测线程被kill/freeze:
data_1834b8 停止更新 → Tick检测到超时 → 游戏停止处理
- CRC32与心跳在同一循环中交织,无法单独绕过任何一方
绕过:不kill检测线程,采用数据层Patch不改 .text 段 → CRC32自然通过 → 心跳持续。
4.4 exit反hook + CRC32完整性心跳(sub_9B7D8)
sub_9B7D8 是检测最密集的线程,包含3种校验。
初始化阶段:sleep(3) → setpriority(nice=19) → 以下检查按顺序执行。
exit() inline hook检测:检查 *(uint32_t*)exit == 0x50000058,即exit函数的首条ARM64指令是否被篡改。如果被inline hook则标记异常。
exit页面写保护:mprotect(page_align(&exit), page_size, PROT_READ|PROT_EXEC) — 去掉exit所在页的写权限,防止后续inline hook注入。
/proc/self/maps段定位(sub_98564 + sub_9A470):
- raw syscall
openat 打开 /proc/self/maps(防Frida hook libc IO)
- 逐字节读取每行,
sub_98564 用sscanf解析 start-end perms
sub_9A470 将段名与目标库名比较(字符串匹配),定位 .text 段基址供CRC32校验使用
// sub_9B7D8 — exit 反 hook + CRC32 完整性校验(去除 CFF 后还原)
// @ 0x9B7D8, 子函数 0x98564, 0x9A470, 0x96A00
void* integrity_guard_thread(void* arg) {
sleep(3);
setpriority(PRIO_PROCESS, 0, 19);
// Step 1: exit inline hook 检测
if (*(uint32_t*)exit != 0x50000058)
flag_abnormal();
// Step 2: 保护 exit 页面,防 inline hook
void* exit_page = (void*)(-page_size & (uint64_t)&exit);
mprotect(exit_page, page_size, PROT_READ | PROT_EXEC);
// Step 3: raw syscall 打开 maps → 定位 .text 段
int fd = syscall(SYS_openat, AT_FDCWD,
decrypt_str(data_1682d0), 0, 0); // → "/proc/self/maps"
char line[512]; int pos = 0; char c;
while (syscall(SYS_read, fd, &c, 1) == 1) {
if (c == '\n') {
line[pos] = 0;
locate_text_segment(line); // sub_98564
pos = 0;
} else line[pos++] = c;
}
// Step 4: CRC32 循环(每 3 秒)
while (1) { crc32_check(); sleep(3); }
}
// sub_98564 — maps 行解析 + 段定位
void locate_text_segment(char* line) { // @ 0x98564
uint64_t start, end; char perms[8];
sscanf(line, "%lx-%lx %s", &start, &end, perms);
if (perms == "r--p" || perms == "rw-p")
match_and_store(start, end); // → sub_9A470(字符串匹配,非解密)
}
// sub_96A00 — CRC32 完整性校验
void crc32_check() { // @ 0x96A00
dl_iterate_phdr(find_text_phdr, &ctx); // sub_9EFB4: 定位 .text PT_LOAD 段
uint32_t crc = crc32(ctx.base, ctx.size); // sub_9AF98: 多项式 0xEDB88320
if (crc != expected_crc) // dword_1682C8
syscall(SYS_exit_group, 0); // 杀进程
}
循环阶段(每3秒):
CRC32完整性校验: sub_96A00 → dl_iterate_phdr(sub_9EFB4)定位 .text 段 → sub_9AF98 计算CRC32(多项式 0xEDB88320)→ 不匹配则 exit_group(0)。CRC32循环中每次更新心跳 data_1834b8(即4.3节的写端)。
绕过:采用数据层Patch(修改 .scn 场景资源)而非代码层Patch,完全不改 .text 段。不hook exit,不改内存权限,CRC32校验自然通过,心跳持续。
4.5 ptrace自保护 + 硬件断点清除(sub_9C654)
sub_9C654 使用fork + ptrace自附加,实现三层反调试:
// sub_9C654 — 逆向还原
void* ptrace_guard_thread(void* arg) {
pid_t pid = getpid();
pid_t child = fork();
if (child == 0) {
// 子进程
if (ptrace(PTRACE_ATTACH, pid, 0, 0) == -1)
exit(1); // 已有调试器 → 退出
while (1) {
waitpid(pid, &status, 0);
if (WIFEXITED(status)) break;
if (WIFSTOPPED(status)) {
int sig = WSTOPSIG(status);
sub_95CC0(pid); // 清除硬件断点
if (sig == SIGSTOP || sig == SIGTRAP)
ptrace(PTRACE_CONT, pid, 0, 0); // 吞掉调试信号
else
ptrace(PTRACE_CONT, pid, 0, sig); // 转发其他信号
}
}
}
return 0;
}
// sub_95CC0 — 硬件断点清除
void clear_hw_breakpoints(pid_t pid) {
uint32_t regs[17];
struct iovec iov = {regs, 0x44};
ptrace(PTRACE_GETREGSET, pid, NT_ARM_HW_BREAK/*0x402*/, &iov);
int num_brps = min((regs[0] >> 12) & 0xFF, 8);
for (int i = 0; i < num_brps; i++) {
regs[1 + i*2] = 0; // 地址清零
regs[2 + i*2] = 7; // 控制位:地址=0 时断点无效
}
ptrace(PTRACE_SETREGSET, pid, NT_ARM_HW_BREAK, &iov);
}
- 第1层: ptrace(ATTACH) 占住调试位,外部调试器无法attach
- 第2层: 每次父进程被信号暂停时,清除所有ARM64硬件断点寄存器(NT_ARM_HW_BREAK)
- 第3层: 正确转发信号,使父进程在被跟踪状态下仍正常运行
绕过:Frida spawn模式不依赖ptrace和硬件断点,不受影响。
4.6 /proc/self/maps Frida注入检测(T3 sub_9B7D8状态机)
属于T3线程 sub_9B7D8 状态机的一个分支(case 10 → case 8 → case 1)。与4.1节的 /proc/self/task 线程名扫描不同,这里扫描 /proc/self/maps 寻找Frida注入痕迹:
// sub_9B7D8 case 10: 用 raw syscall 打开 maps(绕过 libc hook)
int fd = syscall(SYS_openat/*56*/, AT_FDCWD, "/proc/self/maps", 0, 0);
// case 8: 逐字节读取(绕过缓冲区级 hook)
while (syscall(SYS_read/*63*/, fd, &byte, 1) == 1) {
if (byte == '\n') {
line[pos] = '\0';
sub_98564(line); // 解析并检测
pos = 0;
} else {
line[pos++] = byte; // 最大 510 字节
}
}
核心检测在 sub_98564(maps行解析器):
int sub_98564(const char* maps_line) {
// 3 个字符串均为 XOR 加密存储(密钥 byte_1834B0),运行时解密
char* frida_str = decrypt("frida"); // data_1682F4
char* memfd_str = decrypt("/memfd:"); // data_1682FA
char* fmt = decrypt("%lx-%lx %s"); // data_168302
unsigned long start, end;
char perms[256];
sscanf(maps_line, fmt, &start, &end, perms);
// 检测 1: 路径中包含 "frida"(Frida agent .so)
if (strstr(maps_line, "frida")) return 1; // DETECTED
// 检测 2: 路径中包含 "/memfd:"(Frida 匿名内存注入)
if (strstr(maps_line, "/memfd:")) return 1; // DETECTED
return 0;
}
反分析手段:① raw syscall绕过LD_PRELOAD/libc hook;② 逐字节读取绕过缓冲区拦截;③ 关键字XOR加密;④ CFF状态机约19个case混淆控制流。
绕过:数据层Patch不注入任何 .so,maps中无异常条目。
4.7 process_vm_readv交叉完整性校验(libgodot_android.so → libsec2026.so)
沙箱trace发现libgodot_android.so中的 sub_10B9E4C 每帧检查libsec2026.so的 .text 段(不是自身)——形成交叉校验,两个库互相守护:
// sub_10B9E4C (libgodot_android.so) — 每帧调用,跳过前 480 帧(约8秒热身)
void integrity_check() {
// 定位 libsec2026.so 基址
void* ext_init = dlsym(libsec2026, "extension_init"); // offset 0xA4074
void* base = ext_init - 0xA4074;
// 用 process_vm_readv 读取 libsec2026 的 .text 段
// 范围: base+0x95C70 ~ base+0x15FE80, 大小 0xCA210 (827920 字节)
struct iovec local = { heap_buf, 0xCA210 };
struct iovec remote = { base + 0x95C70, 0xCA210 };
syscall(SYS_process_vm_readv/*270*/, self_pid, &local, 1, &remote, 1, 0);
// 每帧处理 0x19000 字节(分帧校验,约9帧完成一轮)
for (i = offset; i < offset + 0x19000 && i < 0xCA210; i++)
sum = (sum + heap_buf[i]) % 0xFFFFFF;
if (done_full_pass) {
if (sum != 0x11FFDD) { // 期望校验和
// 篡改检出!静默关闭游戏
pthread_create(&t, 0, Main_Cleanup, 0); // 新线程执行引擎清理
}
sum = 0; // 重置,开始下一轮
}
}
设计精妙之处:
- 跨库守护: libgodot校验libsec2026的
.text(本节),libsec2026的T3校验自身 .text(4.4节的CRC32)→ libsec2026的 .text 受双重保护
- 分帧处理: 每帧仅处理100KB,不影响渲染帧率
- 静默退出: 不调用
exit_group,而是 pthread_create 新线程执行 Main::Cleanup,游戏"正常关闭",难以定位检测点
- 热身跳过: 前480帧(约8秒)不检测,等libsec2026完成初始化
| 参数 |
值 |
说明 |
.text 偏移 |
0x95C70 |
libsec2026.so .text 段起始 |
.text 大小 |
0xCA210 (808KB) |
完整 .text 段 |
| 校验算法 |
逐字节累加 mod 0xFFFFFF |
简单但覆盖全段 |
| 期望值 |
0x11FFDD |
存储在libgodot dword_400A050 |
| 每帧处理量 |
0x19000 (100KB) |
约9帧完成一轮 |
绕过:数据层Patch不修改任何 .text 段,校验和自然通过。若必须Patch .text,需同步修改libgodot中的期望值 dword_400A050。
4.8 策略总结
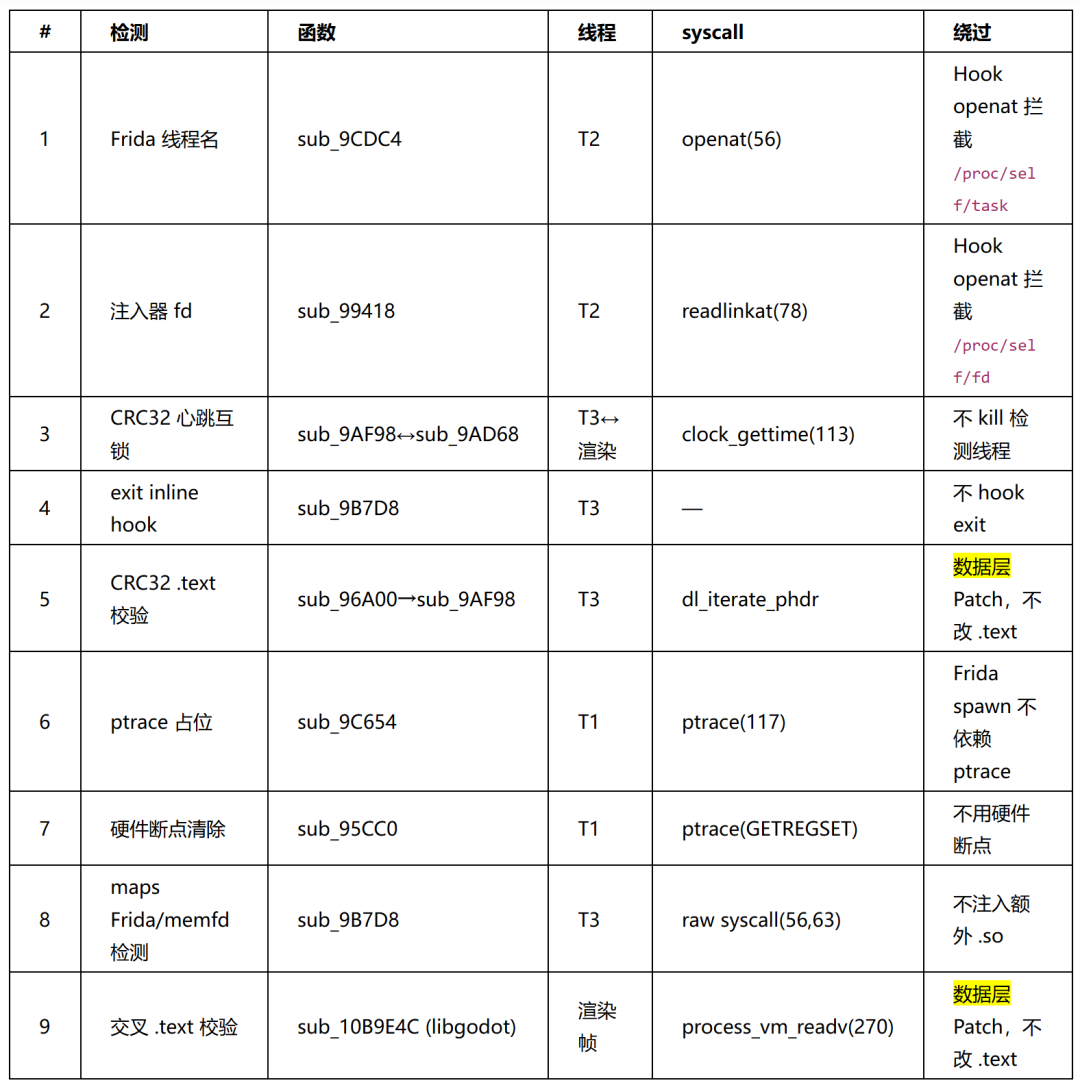
T1=sub_9C654, T2=sub_9CDC4, T3=sub_9B7D8。
统一绕过策略:采用数据层Patch(修改 .scn 场景资源触发flag计算),不修改任何 .text 段代码、不hook任何函数、不kill任何检测线程。9项检测全部自然通过。
05 PART1 — Feistel加密
5.1 算法
反编译 trigger2.gdc,_w7 回调中包含完整加密代码(纯GDScript,不涉及native)。
8轮Feistel网络,输入4字节(Token hex→bytes),分组2+2字节:
密钥 K = b"Sec2026_Godot" (13 字节)
轮函数 F(block, K, r):
对每字节 j: v = block[j] ^ K[(j+r) % 13] // XOR 密钥
v = (v × 7 + r) & 0xFF // 仿射变换
v = ROL3(v) // 8-bit 左旋 3 位
加密: lo, hi = token[0:2], token[2:4]
重复 8 轮: lo, hi = hi, lo ⊕ F(hi, K, r)
解密: 轮序反转 (r: 7→0),交换 lo/hi
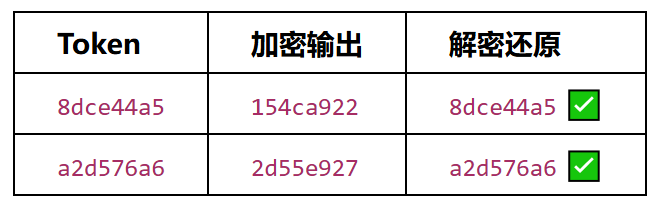
5.2 验证
5.3 运行时字节码Patch验证
trigger2需要碰撞触发(3D场景中撞到Trigger2),可通过Hook GDScriptTokenizerBuffer::set_code_buffer 在运行时修改字节码,将 _process() 中的动画调用 _m3(_d) 替换为flag回调 _w7(_d),使flag每帧自动生成。
关键地址(libgodot_android.so):
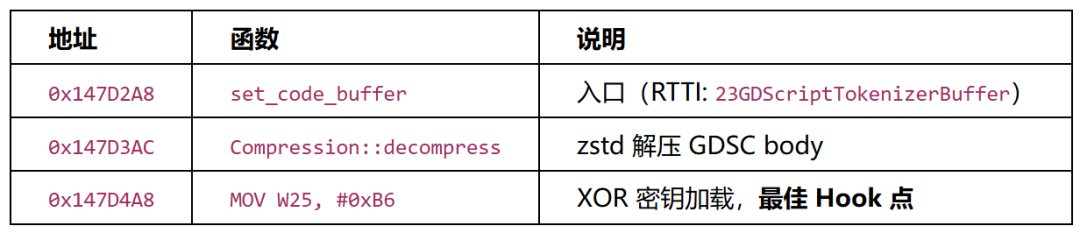
Patch细节:解压后偏移 0x1F80 处为Token[603]:0x00003C8C(IDENTIFIER, pidx=60 → _m3),将 buf[0x1F81] 从 0x3C 改为 0x30,pidx从60(_m3)变为48(_w7)。
// Hook at MOV W25, #0xB6 inside set_code_buffer
Hook::AddExecuteHandler(base + 0x147D4A8,
[](Hook::VContext* ctx, uintptr_t pc, bool after) -> void {
if (after) return;
uint8_t* buf = (uint8_t*)(ctx->x[20] - 0x10);
// trigger2: offset 0x1F80 = 0x00003C8C (_m3) → _w7
if (*(uint32_t*)(buf + 0x1F80) == 0x00003C8C) {
buf[0x1F81] = 0x30; // _m3(idx=60) → _w7(idx=48)
}
});
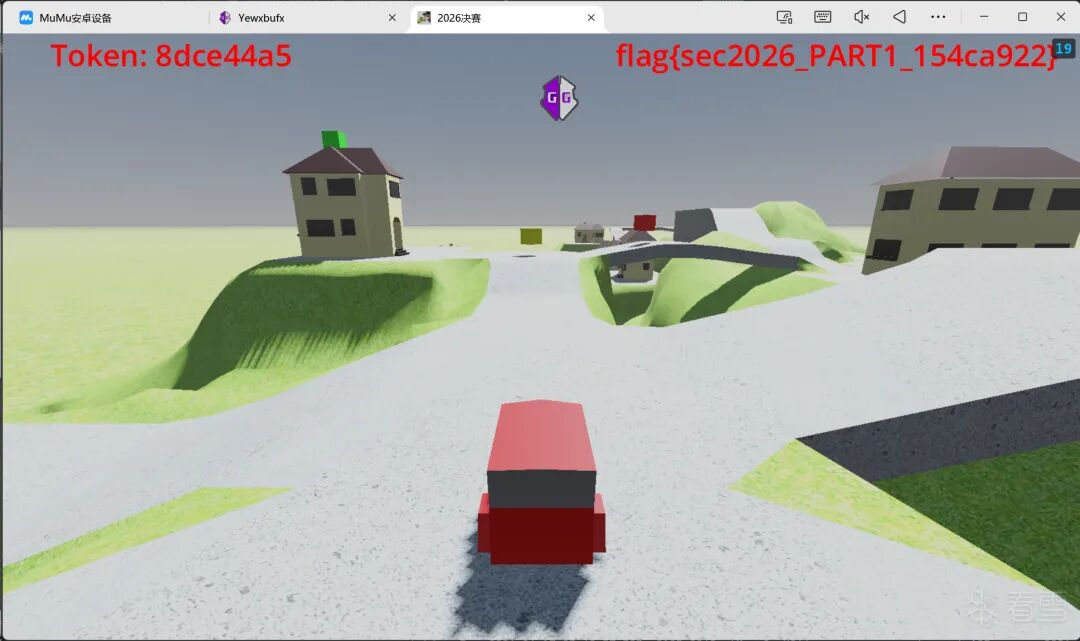
运行结果:Token 8dce44a5,输出 flag{sec2026_PART1_154ca922} ✅
真机验证(MuMu模拟器,Token 8dce44a5,碰撞Trigger2后显示flag):
C++核心实现(part1_feistel.cpp):
static void round_fn(const uint8_t* block, int len, int round_num, uint8_t* out) {
for (int j = 0; j < len; j++) {
uint8_t v = block[j] ^ KEY[(j + round_num) % KEY_LEN];
v = (uint8_t)((v * 7 + round_num) & 0xFF);
v = (uint8_t)(((v << 3) | (v >> 5)) & 0xFF); // ROL3
out[j] = v;
}
}
std::string part1::encrypt(const std::string& token_hex) {
uint8_t lo[2] = {data[0], data[1]}, hi[2] = {data[2], data[3]};
for (int rn = 0; rn < ROUNDS; rn++) {
uint8_t fv[2], new_hi[2];
round_fn(hi, 2, rn, fv);
xor_bytes(lo, fv, 2, new_hi); // new_hi = lo ^ F(hi)
lo[0] = hi[0]; lo[1] = hi[1]; // lo ← hi
hi[0] = new_hi[0]; hi[1] = new_hi[1];
}
return bytes_to_hex({lo[0], lo[1], hi[0], hi[1]}, 4);
}
std::string part1::decrypt(const std::string& cipher_hex) {
// 逆向:从最后一轮往回推,交换 lo/hi 角色
for (int rn = ROUNDS - 1; rn >= 0; rn--) {
round_fn(lo, 2, rn, fv);
xor_bytes(hi, fv, 2, new_lo);
hi = lo; lo = new_lo;
}
}
产物: part1_feistel.cpp(C++加密+解密), flag.py(Python)
运行: flag_tool.exe encrypt <token> / flag_tool.exe decrypt 1 <hex>
06 PART2 — 自定义AES-128-CBC
6.1 发现过程
反编译 trigger3.gdc,_w7 回调将Token的UTF-8字节传入 GameExtension.Process(),返回32字符hex拼为flag:
var _rv := _gx.Process(_buf)
_lb.text = "flag{sec2026_PART2_" + _rv + "}"
6.2 IDA逆向调用链
CFF去混淆后追踪 Process() handler(sub_97704)→ sub_A936C。
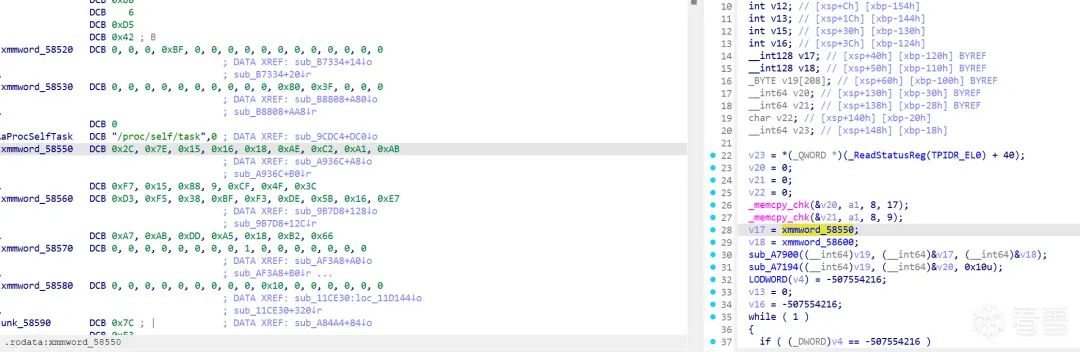
以下为CFF状态机精简后的等价伪代码:
// sub_A936C (0xA936C ~ 0xA9664) — PART2 加密入口
__int64 sub_A936C(__int64 token, __int64 a2, __int64 output) {
__int64 v20 = 0, v21 = 0; // 16 字节明文缓冲
_memcpy_chk(&v20, token, 8, 17); // buf[0:8] = token
_memcpy_chk(&v21, token, 8, 9); // buf[8:16] = token (重复!)
v17 = xmmword_58550; // AES key
v18 = xmmword_58600; // AES IV
sub_A7900(v19, &v17, &v18); // 密钥扩展
sub_A7194(v19, &v20, 0x10); // CBC 加密 16 bytes in-place
// CFF 状态机: for v15=0..15, snprintf("%02x", buf[v15])
// → 输出 32 字符 hex 到 output
}
// sub_A7DE8 (0xA7DE8 ~ 0xA7F80) — 密钥扩展(48 words = 11 轮)
void sub_A7DE8(__int64 ctx, __int64 key) {
sub_A9884(); // 生成自定义 S-box → byte_183700[256]
// 复制 4 words 初始密钥 ctx[0..15] = key[0..15]
// for v2 = 4 .. 47:
// if (v2 % 4 == 0): RotWord + SubBytes(byte_183700) + Rcon(byte_652C9)
// ctx[4*v2+j] = ctx[4*(v2-4)+j] ^ rotated[j]
}
// sub_A7194 (0xA7194 ~ 0xA7308) — AES-CBC 加密
__int64 sub_A7194(__int64 ctx, __int64 pt, unsigned __int64 size) {
// for each 16-byte block:
// sub_AA9B0(block, iv); // twisted IV XOR: even→^iv[15-i], odd→^iv[i]
// sub_A8D44(block, ctx); // AES 加密单块 (11 轮, 全部非标准操作)
// iv = block; // CBC: 密文作为下一块 IV
}
6.3 算法识别:为什么是AES
密钥扩展 sub_A7DE8(下图):循环 v2 = 4..47 → 48 words = 12组轮密钥(11轮 + 初始轮),比标准AES-128的44 words多一轮。


单块加密 sub_A8D44(下图):轮循环 v5 = 1..11,末轮(case 2)无MixColumns。与标准AES的SubBytes → ShiftRows → MixColumns → AddRoundKey四步结构一致,但多了RoundMix、首尾Transform,轮数11而非10。

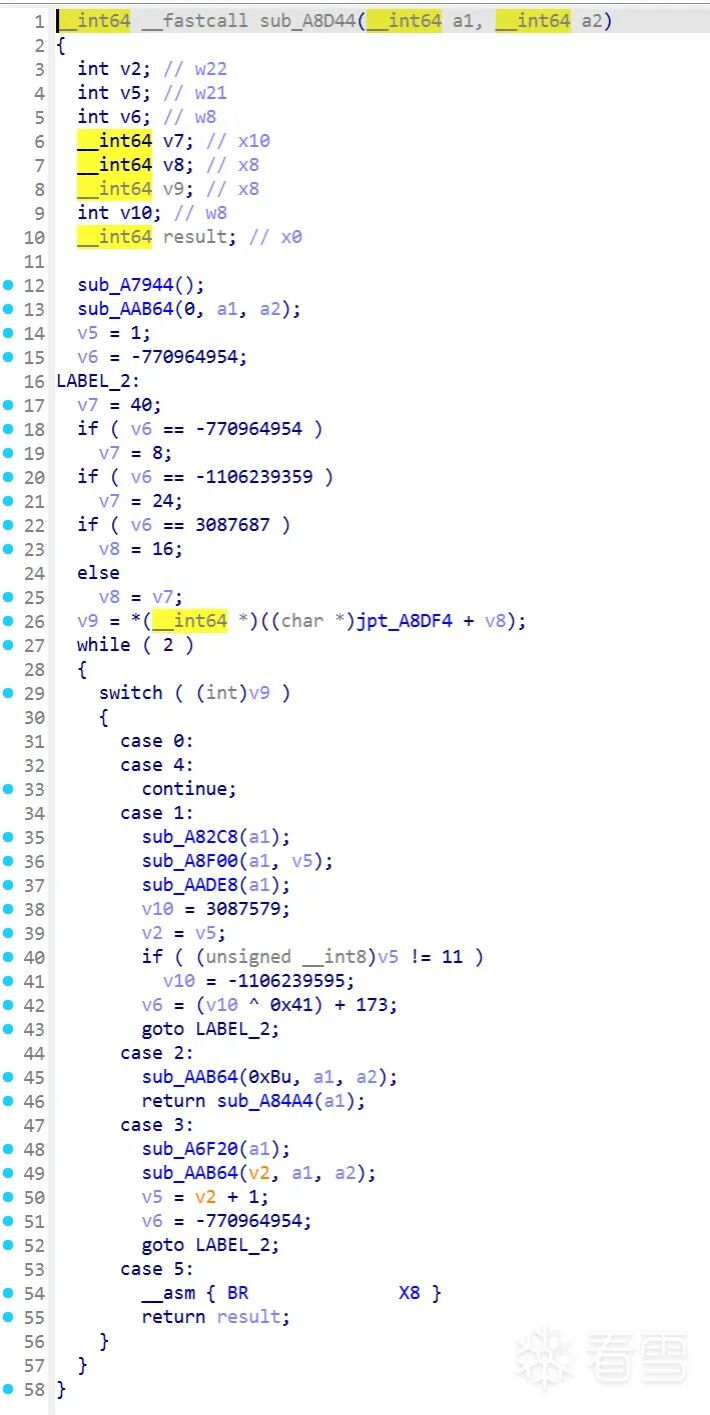
确认框架是AES变种后,逐一定位每个非标准参数。
6.4 与标准AES-128的差异

参数提取:CFF去混淆后从IDA伪代码逐一读取,以下为关键证据。
S-box仿射变换(sub_A8C8C)— 常数 0x8F 和ROL5直接可见:
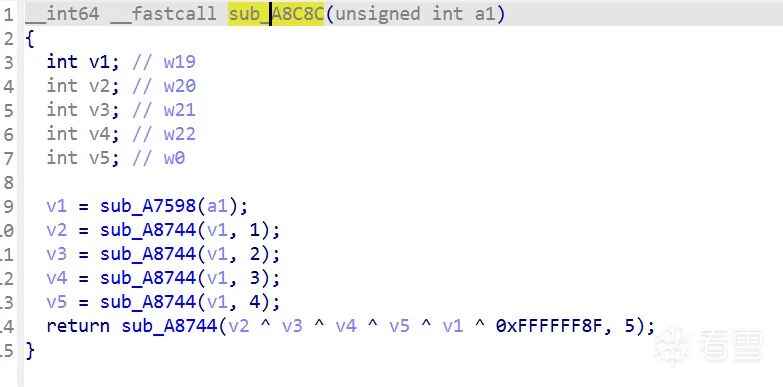
// sub_A8C8C — S-box 仿射变换
v1 = sub_A7598(a1); // GF(2^8) 求逆
v2 = sub_A8744(v1, 1); v3 = sub_A8744(v1, 2);
v4 = sub_A8744(v1, 3); v5 = sub_A8744(v1, 4);
return sub_A8744(v2 ^ v3 ^ v4 ^ v5 ^ v1 ^ 0x8F, 5); // ← affine 0x8F + ROL5
GF(2^8)多项式(sub_A96F0)— & 0x71 即reduction poly 0x171:
// sub_A96F0 — GF 乘法 (gf_mul)
a1 = ((unsigned int)(char)v3 >> 7) & 0x71 ^ (2 * v3); // ← poly = 0x171
MixColumns系数(sub_A6F20)— [6,3,5,2] 循环矩阵:
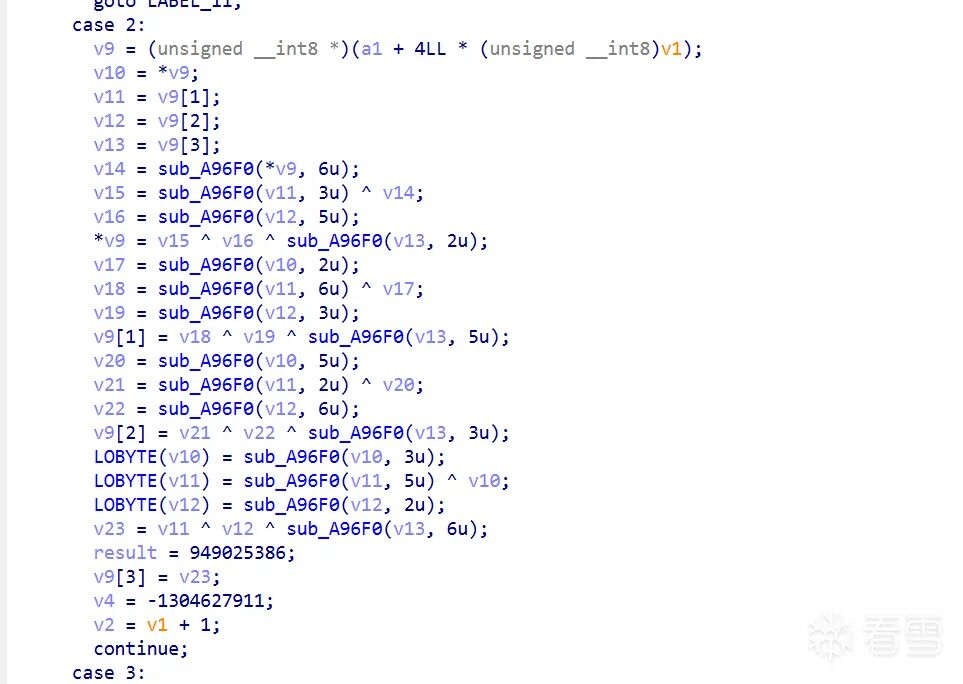
// sub_A6F20 — MixColumns
v9[0] = gf_mul(v10,6) ^ gf_mul(v11,3) ^ gf_mul(v12,5) ^ gf_mul(v13,2); // [6,3,5,2]
v9[1] = gf_mul(v10,2) ^ gf_mul(v11,6) ^ gf_mul(v12,3) ^ gf_mul(v13,5); // [2,6,3,5]
v9[2] = gf_mul(v10,5) ^ gf_mul(v11,2) ^ gf_mul(v12,6) ^ gf_mul(v13,3); // [5,2,6,3]
v9[3] = gf_mul(v10,3) ^ gf_mul(v11,5) ^ gf_mul(v12,2) ^ gf_mul(v13,6); // [3,5,2,6]
Rcon表(byte_652C9,IDA hex dump):
A7 A6 A5 A3 AF B7 87 E7 27 D6 45 FC 25 30 38 78
ShiftRows置换(sub_AADE8)— IDA完整反编译(无CFF),直接读出字节置换:
// sub_AADE8 — ShiftRows (固定置换,IDA 完整反编译)
// 追踪每个赋值: out[i] ← in[src[i]]
// 源索引: [0, 13, 6, 11, 4, 1, 10, 15, 8, 5, 14, 3, 12, 9, 2, 7]
v1=r[5]; v2=r[1]; v3=r[13];
r[13]=r[9]; r[9]=v1; r[5]=v2; r[1]=v3; // 列 1 循环: 1←13←9←5←1
v4=r[6]; v5=r[10]; v6=r[14]; v7=r[2];
r[2]=v4; r[6]=v5; r[10]=v6; r[14]=v7; // 列 2 循环: 2←6←10←14←2
v8=r[11]; v9=r[3]; v10=r[15]; v11=r[7];
r[3]=v8; r[11]=v9; r[7]=v10; r[15]=v11; // 列 3 循环: 3←11←3, 7←15←7
RoundMix(sub_A8F00)— CFF混淆,通过Unicorn差分提取:
# 可见初始化: var_dc = 0x47 + arg2 * 0xffffff9d
# 即 seed = (71 - 99 * round_num) & 0xFF
def roundmix(state, round_num):
v = (71 - 99 * round_num) & 0xFF # PRNG 种子(0x47 + r*0xffffff9d)
prng = []
for _ in range(16):
prng.append(v)
v = (47 - 61 * v) & 0xFF # PRNG 步进(IDA case 7: 47 - 61*v19)
old = list(state)
for j in range(16): # 列反转 + XOR
col, row = j // 4, j % 4
state[j] = old[(3 - row) * 4 + col] ^ prng[j]
InitTransform / FinalTransform — CFF混淆,但引用的数据地址可直接读取:
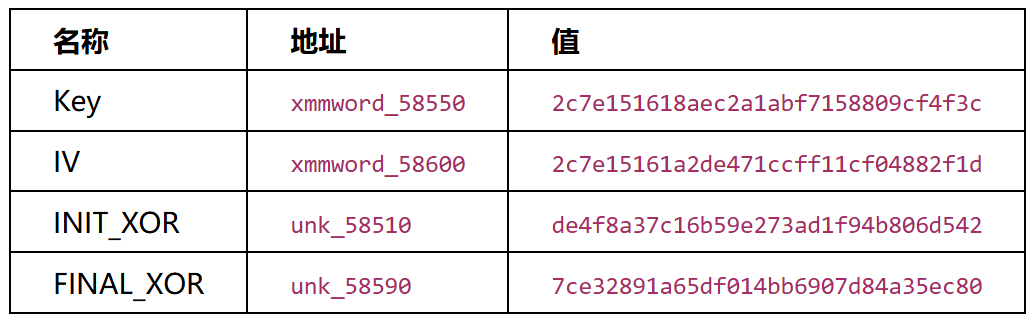
sub_A7944 (InitTransform) 引用 unk_58510:
DE 4F 8A 37 C1 6B 59 E2 73 AD 1F 94 B8 06 D5 42
→ state[i] ^= INIT_XOR[i] (加密前)
sub_A84A4 (FinalTransform) 引用 unk_58590:
7C E3 28 91 A6 5D F0 14 BB 69 07 D8 4A 35 EC 80
→ state[i] ^= FINAL_XOR[i] (加密后)
常量(从 libsec2026.so 提取):
6.5 解密实现
InvMixColumns:正向矩阵 [6,3,5,2] 在GF(2^8, 0x171)上的逆矩阵通过高斯消元法求解(part2_aes.py 中 _compute_inv_mix_matrix()),结果为 [0x80, 0xf3, 0x64, 0xaf] 循环矩阵。可逆性由GF(2^8)的域性质保证(非零行列式)。
完整解密流程(严格逆序):
FinalTransform → AddRoundKey(11) → InvShiftRows → InvRoundMix(11) → InvSubBytes
→ 循环 r=10..1: AddRoundKey(r) → InvMixColumns → InvShiftRows → InvRoundMix(r) → InvSubBytes
→ AddRoundKey(0) → InitTransform → Twisted IV XOR
6.6 验证(5组测试向量)

6.7 运行时字节码Patch验证
与PART1相同方法:Hook set_code_buffer 中 MOV W25, #0xB6(地址 0x147D4A8),在解压后修改 _process() 中的 _m3(_d) 调用为 _w7(_d)。
// trigger3: offset 0x1CD4 = 0x00003B8C (_m3) → _w7
if (*(uint32_t*)(buf + 0x1CD4) == 0x00003B8C) {
buf[0x1CD5] = 0x29; // _m3(idx=59) → _w7(idx=41)
}
Patch对比表:

运行结果:Token 1af763af,输出 flag{sec2026_PART2_52f0ab0970da6f1d7c516d0813acc998} ✅
真机验证(Token 1af763af,通过字节码Patch自动触发,右上角显示flag):

C++核心实现(part2_aes.cpp,约300行):
// GF(2^8) 乘法 — 约化多项式 x^8+x^6+x^5+x^4+1 = 0x171(非标准 0x11B)
static uint8_t gf_mul(uint8_t a, uint8_t b) {
uint8_t p = 0;
for (int i = 0; i < 8; i++) {
if (b & 1) p ^= a;
uint8_t hi = a & 0x80;
a = (a << 1) & 0xFF;
if (hi) a ^= 0x71; // 0x171 的低 8 位
b >>= 1;
}
return p;
}
// MixColumns 矩阵 [6,3,5,2](标准 AES 为 [2,3,1,1])
static const uint8_t MIX[4][4] = {
{6,3,5,2}, {2,6,3,5}, {5,2,6,3}, {3,5,2,6}
};
// AddRoundKey — 额外 XOR (row + 91*round_idx) & 0xFF
static void add_round_key(uint8_t s[16], int rk_idx) {
uint8_t extra_base = (uint8_t)((91 * rk_idx) & 0xFF);
for (int i = 0; i < 16; i++) {
uint8_t row = i % 4;
s[i] ^= ROUND_KEYS[rk_idx][i] ^ ((row + extra_base) & 0xFF);
}
}
// RoundMix — 置换 + PRNG 异或(每轮不同的伪随机扰动)
static void roundmix(uint8_t s[16], int rn) {
uint8_t prng[16]; roundmix_prng(rn, prng);
uint8_t t[16]; memcpy(t, s, 16);
for (int j = 0; j < 16; j++) s[j] = t[RMIX_FWD[j]] ^ prng[j];
}
// Twisted IV XOR — even 位置倒序、odd 位置正序
static void twisted_xor(uint8_t s[16], const uint8_t iv[16]) {
for (int i = 0; i < 16; i++)
s[i] ^= (i % 2 == 0) ? iv[15 - i] : iv[i];
}
// 11 轮加密(标准 AES 为 10 轮)
static void aes_encrypt_block(uint8_t s[16]) {
init_transform(s); // INIT_XOR
add_round_key(s, 0);
for (int r = 1; r <= 11; r++) {
sub_bytes(s); // 自定义 S-box(affine 0x8F + ROL5)
roundmix(s, r); // 置换+PRNG(标准 AES 无此步骤)
shift_rows(s); // 自定义置换表
if (r < 11) { mix_columns(s); add_round_key(s, r); }
else { add_round_key(s, 11); final_transform(s); }
}
}
产物: part2_aes.cpp(C++加密+解密, 约300行,含完整S-box/GF(2^8)/MixColumns), part2_aes.py(Python)
运行: flag_tool.exe encrypt <token> / flag_tool.exe decrypt 2 <hex>
07 PART3 — VM中的TEA变种分组密码
7.1 发现:Trigger4被刻意禁用
反编译 trigger4.gdc 发现:GDScript侧没有任何flag逻辑,没有 body_entered.connect(),仅有 GameExtension.new() 和 Tick() 调用。
解析 town_scene.scn(Godot PackedScene RSRC v6格式)发现Trigger4被刻意禁用:
反编译 trigger4.gd(代码见第二章2.5节):没有 body_entered.connect(),signal collided_with 声明但GDScript侧从未emit。
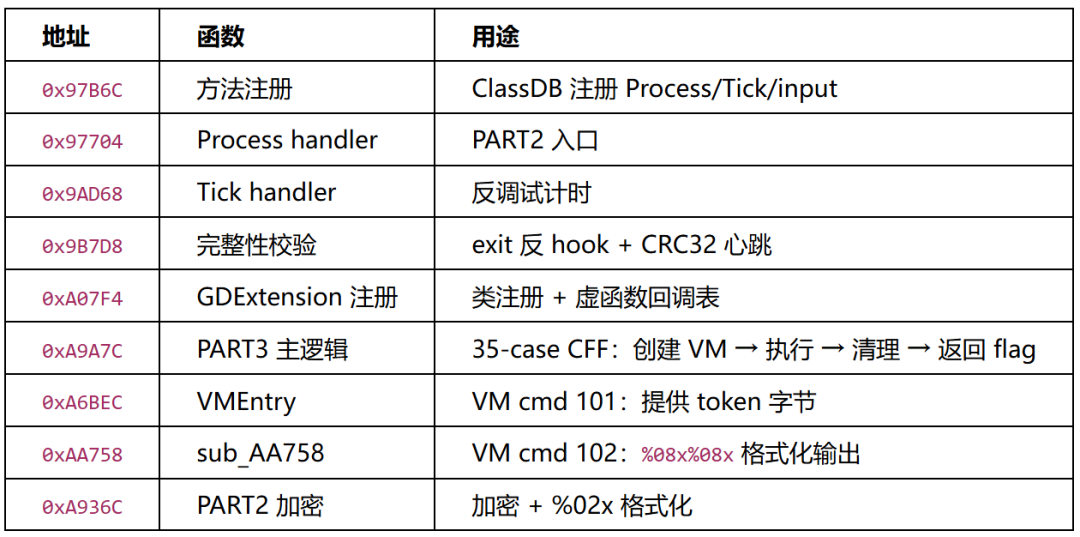
碰撞回调必须由native层实现——通过字符串解密定位到 sub_A07F4(GDExtension类注册,下图),发现PART3碰撞回调注册在虚函数表中,最终指向 sub_A9A7C(静态二进制中0 xref,通过GDExtension虚表间接调用,IDA无法静态追踪)。
结论:Trigger4在游戏中既不可见也无法通过物理碰撞触发,必须修改场景才能触发。
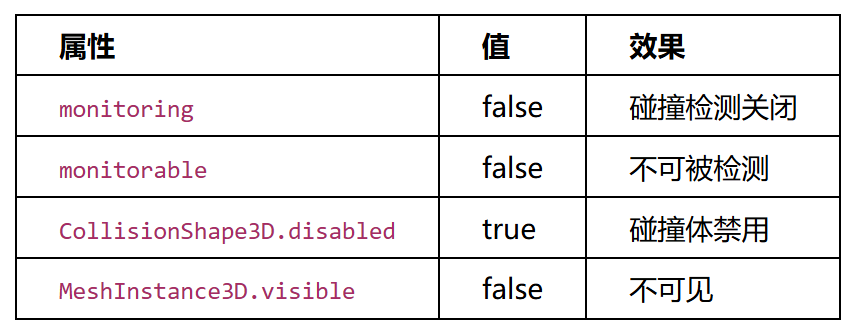
7.2 场景Patch
解密 .scn 后,在RSRC的nodes数组中修改variant index指针,将属性指向正确的true/false variant:
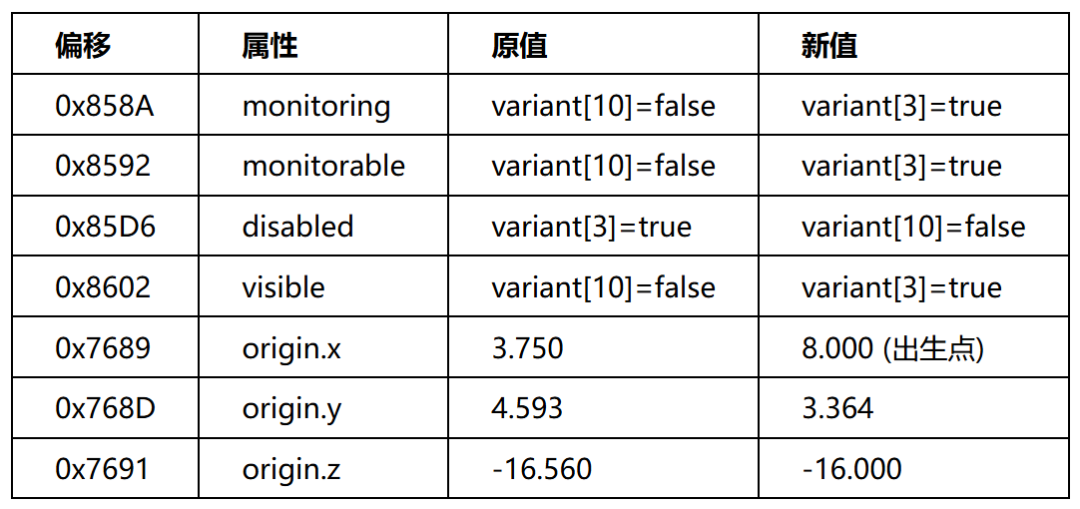
前4处启用碰撞和可见性,后3处将Trigger4移到玩家出生点(开局即碰撞)。
解密 .scn:加密文件格式 [md5:16][pt_len:8][iv:16][ciphertext:...],AES-256-CFB128解密后验证 md5(pt) == stored_md5 且 pt[:4] == b"RSRC"。
重加密部署:
# 应用 7 处 patch 后
pt = bytes(patched_plaintext)
ct_new = cfb128_encrypt_standard(KEY, iv, pt + b"\x00" * pad_len)
out = hashlib.md5(pt).digest() + struct.pack("<Q", len(pt)) + iv + ct_new
# Round-trip 验证
assert cfb128_decrypt_standard(KEY, iv, ct_new)[:len(pt)] == pt
替换APK中的 assets/.godot/exported/133200997/export-...-town_scene.scn,重签名安装。
产物: patch_trigger4_scn.py, parse_scene.py
7.3 Native逆向架构
方法注册(sub_97B6C)
// sub_97B6C — GDExtension 方法注册(CFF 去混淆后)
// case 14: 注册 Process
sub_9F4EC("Process", "Process", 0x4A85115FAA17D83FLL, 8);
sub_9B5E8(v30, sub_97704, 0); // sub_97704 = Process handler → PART2
// case 0: 注册 Tick
sub_97358("Tick", "Tick", 0x97A36EF7A74F5E4ELL, 5);
sub_9610C(v27, sub_9AD68, 0); // sub_9AD68 = Tick handler → 反调试计时
// case 28: 注册 input
sub_9CB50("input", "input", 0x7B88A8A1801FE656LL, 6);
PART3完整执行架构
┌──────────────────────────────────────────────────────────┐
│ 后台线程 sub_9B7D8:完整性校验(详见 4.4 节) │
│ │
│ exit 反 hook + maps 段定位 + CRC32 完整性心跳 │
│ CRC32 不通过 → exit_group 杀进程 │
│ │
│ ★ sub_A9A7C 通过 GDExtension 虚表间接调用 │
│ (静态二进制中 0 xref,IDA 无法追踪) │
└──────────────────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────┐
│ 每帧调用:GDScript _process() → _gx.Tick() │
│ │
│ sub_9AD68 (Tick handler) — 仅做反调试计时: │
│ ├─ clock_gettime(CLOCK_MONOTONIC) │
│ ├─ 首次调用:记录初始时间 → data_1834b8 │
│ └─ 后续调用:检查帧间隔 │
│ ├─ > 10秒 → return(反调试:暂停过久则停止) │
│ └─ ≤ 10秒 → 正常返回 │
│ ⚠ Tick 不触发 PART3 计算! │
└──────────────────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────┐
│ 碰撞触发(GDExtension 虚表隐藏路径) │
│ │
│ 车碰撞 trigger4 (Area3D) → Godot 物理引擎 │
│ → notification_func / get_virtual_func 回调 │
│ → (虚表间接调用,静态 0 xref) → sub_A9A7C(token) │
│ │
│ sub_A9A7C (35-case CFF 状态机,IDA 反编译见下图): │
│ ├─ mutex_lock │
│ ├─ 检查 qword_183498 != 0(缓冲区已分配?) │
│ ├─ memcpy token(8B) → byte_1836C0 │
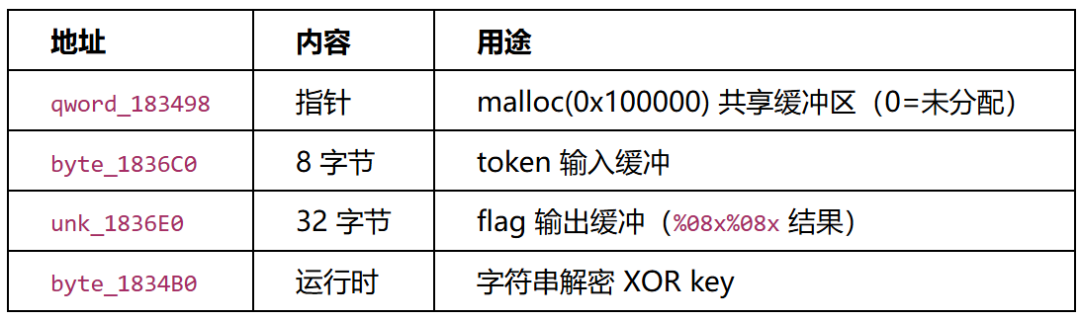
│ ├─ socket (port 5414 = 0x1526) │
│ ├─ sub_1371F8: VM 初始化 (malloc 0x2030) │
│ ├─ sub_1374A0 注册 VM handlers: │
│ │ ├─ cmd 101: VMEntry — 提供 token 字节 │
│ │ └─ cmd 102: sub_AA758 — 格式化 %08x%08x │
│ ├─ sub_13CD90: VM dispatcher 执行循环 │
│ │ └─ sub_13C67C: 56-case CFF 线性 PC 解释器 │
│ │ → 执行 TEA 变种算法 │
│ ├─ 清理: sub_13D374, sub_13C5C8, sub_137360 │
│ ├─ mutex_unlock │
│ └─ return &unk_1836E0 (flag string, 16 hex) │
└──────────────────────────────────────────────────────────┘
│
▼
flag{sec2026_PART3_XXXXXXXXXXXXXXXX}
(16 hex, 两个 u32: %08x%08x)
7.4 VM算法提取:Unicorn差分trace
面对56-case解释器 + CFF混淆,直接静态分析不现实。采用Unicorn模拟 + 差分taint方案。
关键前提验证:5组不同输入的指令执行数均为 20,019,435 条——控制流完全数据无关,算法是固定顺序的算术操作序列。
差分方法:
- 对两组仅1字节不同的输入分别执行,挂
UC_HOOK_MEM_WRITE 记录全部写入
- 对比同一位置的写入值差异,定位输入敏感的内存slot(约10个)
- 追踪关键slot的值变化序列,识别轮结构
性能优化:初版用Python回调实现libc函数,每token约30s。改用Keystone生成ARM64原生stub(memcpy/memset/strlen等),降至约0.5s/token(60x加速)。
产物: vm_fast.py(Unicorn模拟器), vm_trace.py(差分trace)
7.5 算法还原过程
Step 1 — 差分taint定位输入敏感地址
挂载 UC_HOOK_MEM_WRITE,记录全部写入 (地址, 值)。两组仅首字节不同的输入对比后,约1400万次写入中约5000处值不同,聚类后集中在10个slot:
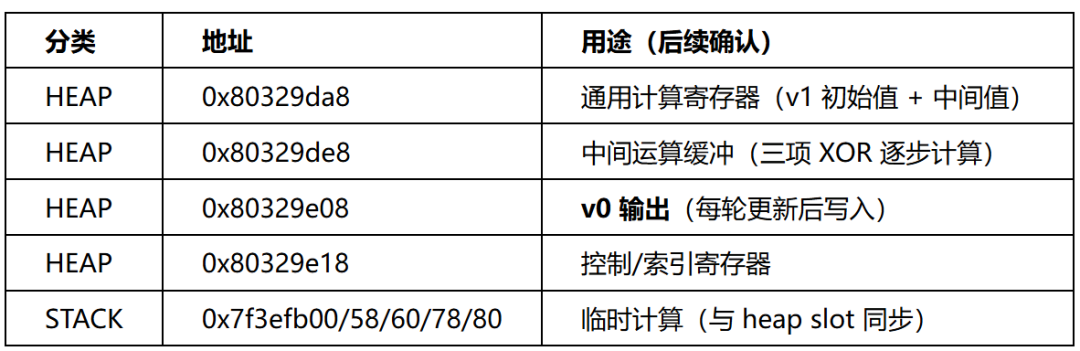
Step 2 — 轮数识别
追踪 0x80329e08(v0输出slot)的值变化序列:
Transitions for 0x80329e08 (input=0x00*8):
[ 0] 0x00000000 (初始)
[ 1] 0xe3546957
[ 2] 0x9c660d6c
...
[27] 0xaf607752
[28] 0x268193dc (= 最终输出高 32 位)
29次transition = 初始值 + 28轮更新。
Step 3 — 轮函数还原
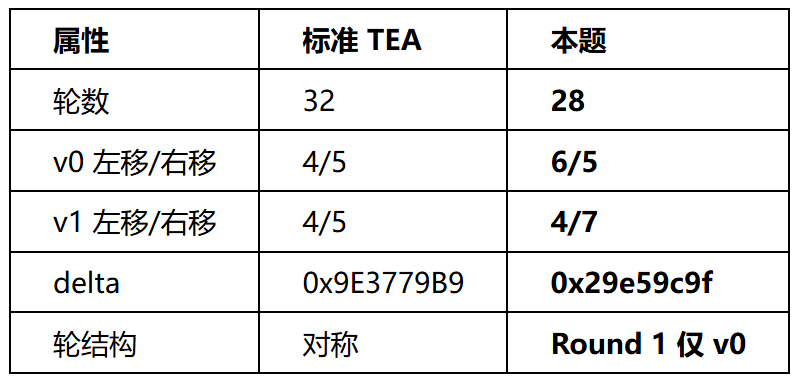
通过交叉验证移位量、确认da8多用途寄存器、最终识别出两阶段轮结构:
Round 1 仅 v0 update
Round 2~28 先 v1(用v0的 <<4/>>7)再 v0(用新v1的 <<6/>>5)
Step 4 — delta的真实身份
通过trace反推sum,证实 delta = 0x29e59c9f(非 0xaabbccdd,后者是v0右项加数,即7.6表中的 key[0])。
Step 5 — 4个候选模型淘汰赛

7.6 提取结果
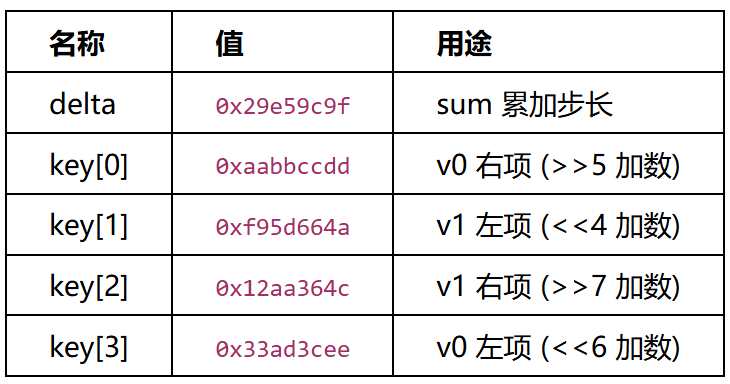
常量:
与标准TEA差异:
加密/解密:
def encrypt(v0, v1):
sum = delta
v0 += ((v1<<6)+key[3]) ^ (v1+sum) ^ ((v1>>5)+0xaabbccdd) # Round 1
for r in range(2, 29):
sum += delta
v1 += ((v0<<4)+key[1]) ^ (v0+sum) ^ ((v0>>7)+key[2]) # v1 先
v0 += ((v1<<6)+key[3]) ^ (v1+sum) ^ ((v1>>5)+0xaabbccdd) # v0 后
return v0 & M, v1 & M
def decrypt(v0, v1): # 严格逆序
sum = 28 * delta
for r in range(28, 1, -1):
v0 -= ((v1<<6)+key[3]) ^ (v1+sum) ^ ((v1>>5)+0xaabbccdd)
v1 -= ((v0<<4)+key[1]) ^ (v0+sum) ^ ((v0>>7)+key[2])
sum -= delta
v0 -= ((v1<<6)+key[3]) ^ (v1+sum) ^ ((v1>>5)+0xaabbccdd) # Round 1
return v0 & M, v1 & M
7.7 验证(7+1组测试向量)
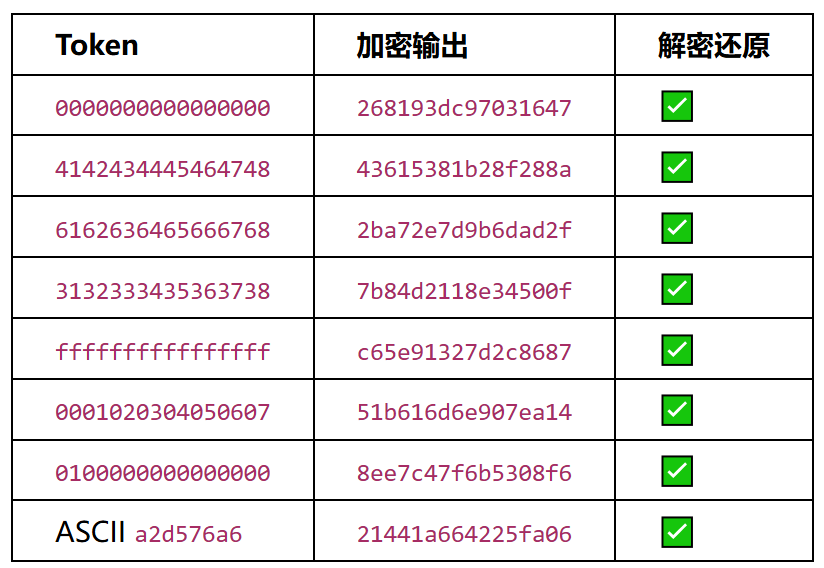
7/7正向 + 7/7逆向 + 1组ASCII真实场景,全部匹配Unicorn ground truth。
真机验证(MuMu模拟器,Token a2d576a6,场景Patch后碰撞Trigger4显示flag):
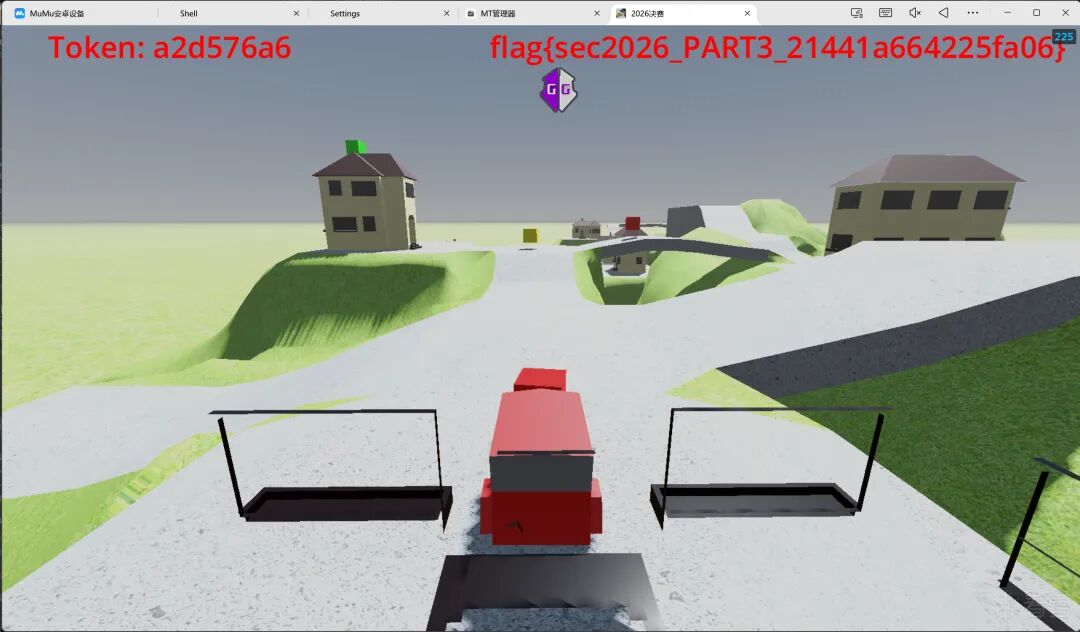
C++核心实现(part3_tea.cpp):
命名约定:C++中 KEY[0]=delta=0x29e59c9f,MAGIC=0xaabbccdd;VM反编译器中 key[0]=0xaabbccdd(7.6表采用VM约定)。两套索引不同,常量值一致。
static const uint32_t KEY[4] = {0x29e59c9f, 0xf95d664a, 0x12aa364c, 0x33ad3cee};
static const uint32_t MAGIC = 0xaabbccdd; // VM 反编译器中的 key[0]
static const uint32_t DELTA = KEY[0]; // 0x29e59c9f
static const int ROUNDS = 28;
// 轮函数 — v0 用 <<6/>>5,v1 用 <<4/>>7(标准 TEA 均为 <<4/>>5)
static uint32_t f_v0(uint32_t v1, uint32_t s) {
return ((v1 << 6) + KEY[3]) ^ (v1 + s) ^ ((v1 >> 5) + MAGIC);
}
static uint32_t f_v1(uint32_t v0, uint32_t s) {
return ((v0 << 4) + KEY[1]) ^ (v0 + s) ^ ((v0 >> 7) + KEY[2]);
}
// 非对称 Feistel — 第 1 轮仅更新 v0,第 2~28 轮先 v1 后 v0
static void encrypt(uint32_t& v0, uint32_t& v1) {
uint32_t s = DELTA;
v0 += f_v0(v1, s); // 第 1 轮:仅 v0
for (int i = 1; i < ROUNDS; i++) {
s += DELTA;
v1 += f_v1(v0, s); // 第 2~28 轮:先 v1
v0 += f_v0(v1, s); // 再 v0
}
}
static void decrypt(uint32_t& v0, uint32_t& v1) {
uint32_t s = (uint32_t)((uint64_t)ROUNDS * DELTA);
for (int i = ROUNDS - 1; i >= 1; i--) {
v0 -= f_v0(v1, s);
v1 -= f_v1(v0, s);
s -= DELTA;
}
v0 -= f_v0(v1, s); // 逆向第 1 轮
}
// 输入映射:token[0:4]→lo, token[4:8]→hi=v0, v1=f_v1(v0,δ)+lo
static void token_to_state(const uint8_t token[8], uint32_t& v0, uint32_t& v1) {
v0 = le32(token + 4);
v1 = f_v1(v0, DELTA) + le32(token);
}
产物: part3_tea.cpp(C++加密+解密), part3_tea.py(Python)
运行: flag_tool.exe encrypt <token> / flag_tool.exe decrypt 3 <hex>
08 VM逆向与静态反编译器(附加分析)
算法已在第七章通过Unicorn差分trace完全还原后,回过头来对VM本身进行完整逆向,构建了不依赖模拟器的纯静态反编译器,从原始字节码直接产出可读伪代码。
8.1 VM执行架构
启动链
sub_A9A7C(token)
├─ sub_12DE80() → 创建 runtime 对象
├─ loc_119DA8(rt, 0x63DA0, 5414) → 加载字节码到 runtime
├─ sub_13BFD4(..., &vm_machine) → 创建 vm_machine (0x110 字节)
│ └─ 安装 7 个 family descriptor → vm+0x100
│ └─ 安装 sub_13C430 (selector) → vm+0xA0
├─ sub_1371F8(0, &host_table) → 创建 host_table (malloc 0x2030)
├─ sub_13D278(vm, ht) → 绑定: vm+0x98 = host_table
├─ sub_1374A0(ht, 101, VMEntry) → 注册 BRIDGE cmd 101
├─ sub_1374A0(ht, 102, sub_AA758) → 注册 BRIDGE cmd 102
├─ sub_13CD90(vm_machine) → 驱动循环
│ └─ while (sub_13C67C(vm) == 0x604) {}
├─ sub_13D374, sub_13C5C8, loc_137360 → 清理
└─ return &unk_1836E0 → flag 字符串
sub_A9A7C case 33(VM调用核心)— 启动链中每个函数调用均可在IDA反编译中一一对应:

sub_13CD90 是驱动循环,每次调用 sub_13C67C 执行一条VM指令。返回 0x604(CONTINUE)继续,0(SUCCESS)结束。额外保护:vm[6] >= vm[1] 时强制退出(PC越界)。
双对象模型
VM运行时由两个独立对象组成:

sub_13D278 绑定两者:*(vm_machine + 0x98) = host_table,使VM执行时能通过BRIDGE指令调用宿主函数。
数据结构布局
vm_machine (0x110字节):
+0x00 runtime_ptr 指向 runtime 对象
+0x08 bytecode_limit 字节码长度(PC 越界检查用)
+0x30 PC counter 当前字节码 PC(= vm[6],每条指令执行后推进)
+0x60 insn_count 指令计数器(= vm[0xC])
+0x98 host_table_ptr 绑定的 host_table
+0xA0 selector_func sub_13C430(family 选择器函数指针)
+0x100 descriptor_array 指向 7 个 FamilyDescriptor 的指针数组
host_table (0x2030字节):
+0x0000..+0x1FFF 256 个 handler 槽位,每个 0x20 字节:
+0x00 name_ptr handler 名字符串
+0x08 handler_func 回调函数指针
+0x10 opaque 用户数据
+0x19 registered 1=已注册
+0x2000 handler_count 已注册数量
+0x2008 allocator malloc 函数指针
+0x2010 free_func free 函数指针
FamilyDescriptor (40字节),7个连续存放在 .data:0x163948:
+0x00 slot0 共享 RET stub (0x13D4F8,所有 family 相同)
+0x08 slot1 各 family 独立辅助 stub
+0x10 handler ★ family handler 函数指针(BLR X8 调用目标)
+0x18 (zero)
+0x20 (zero)
寄存器文件(通过 sub_118340 从runtime取出):
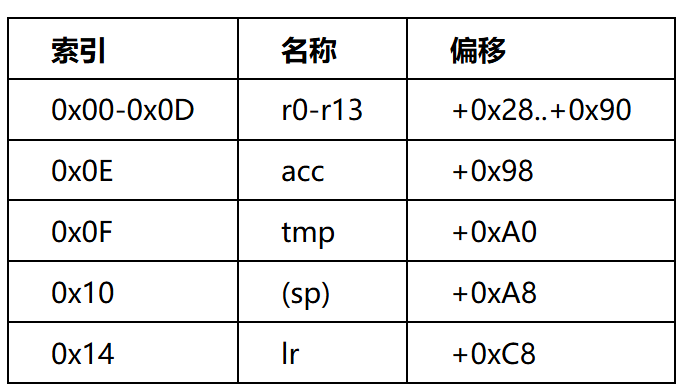
寄存器存储在 regfile + 0x28 + reg_idx * 8,最多 32 个
内存上下文在 regfile + 0x128
BRIDGE handler伪代码
sub_AA758(VM cmd 102: PART3结果格式化):
// sub_AA758 (0xAA758 ~ 0xAA9B0) — VM cmd 102
void sub_AA758(a1, a2, a3, a4, a5) {
int64_t v0, v1;
int64_t ctx = *(a3 + 8);
loc_1385BC(a1, a2, ctx + 16, &v1, 8); // 读第一个 u32
loc_1385BC(a1, a2, ctx + 24, &v0, 8); // 读第二个 u32
sub_A9664("%08x%08x", ...); // 解密格式字符串
sub_AA6AC(&unk_1836E0, 32, "%08x%08x", v1, v0);
}
VMEntry(VM cmd 101: 提供token字节):
// VMEntry (0xA6BEC ~ 0xA6F10) — VM 读取 token 字节
int64_t VMEntry(a1, a2, a3, a4, a5, a6) {
uint32_t idx = *v8;
if (idx >= a6)
*v7 = 0; // 超出范围返回 0
else
*v7 = byte_1836C0[idx]; // token 第 idx 字节
sub_13879C(a1, a2, ctx + 8*idx + 16, &v30, 8); // 写入 VM 上下文
*v8 = idx + 1;
}
本质上是标准线性PC解释器,但整体被56-case CFF(控制流平坦化)混淆包裹,静态看起来极其复杂。IDA完全无法反编译(SP分析失败,仅输出3行),成功还原全部56个CFF状态。去掉CFF外壳后,每条指令的执行流程为:
sub_13C67C(vm_machine) {
1. 取指:从 bytecode[PC] 读 4 字节 header → opcode, flags, cls
2. 解码:按 cls 个数读操作数(fmt=0x04 → 4字节立即数,其他 → 1字节寄存器索引)
3. 分派:sub_13C430 按 opcode 高字节选 family → descriptor[family].handler
4. 执行:BLR X8 @ 0x139684 → 调用 family handler
5. 推进:PC += instruction_size, insn_count++
6. 返回:0x604 (CONTINUE) 或 0 (HALT)
}
反编译关键CFF状态(地址→语义):

handler分派点在ARM64层为 BLR X8 @ 0x139684(动态反编译器hook的位置),调用前X2指向112字节指令描述符,SP+0xF0为当前bytecode PC。
寄存器/内存访问函数
Family handler内部通过以下函数操作VM状态:

例如Family1(算术,sub_139060)执行 ADD 的核心路径:
- 读opcode:
*arg3 = 0x0100 → switch到ADD分支
- 读源操作数:
reg_read(regfile, op1_slot, &val1), reg_read(regfile, op2_slot, &val2)
- 计算:
result = val1 + val2
- 写目标:
reg_write(regfile, dst_slot, result)
Family3(传送,sub_139D70)的PUSH/POP操作VM栈指针(reg[0x10]),每次移动8字节。LOAD/STORE通过 mem_read/mem_write 访问VM内存。
Family selector — sub_13C430
sub_13C430 读 *(bytecode_ptr + 1)(opcode高字节),映射到family:
0 → Family0 (0x138BBC) 5,6,7,8 → Family5 (0x13AC3C)
1 → Family1 (0x139060) 9 → Family6 (0x13BBD4)
2 → Family2 (0x139A44)
3 → Family3 (0x139D70) 调用方式: (*descriptor->handler)(desc, host, bytecode, ctx)
4 → Family4 (0x13A440)
Family handler表
7个Family handler按opcode高字节分派:
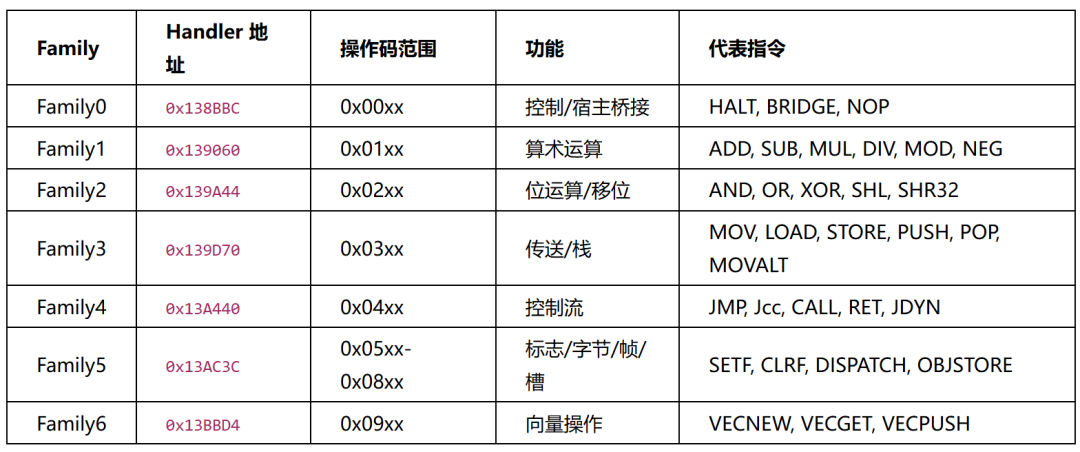
opcode高字节5/6/7/8全部路由到Family5(sub_13C430中确认),Family5内部再按完整opcode二次分派。BRIDGE(func, nargs) 是VM↔Native桥接指令:func=0x65调用VMEntry读token,func=0x66调用sub_AA758输出结果。
8.2 SBC0字节码格式还原
指令编码
通过Unicorn hook sub_13C67C 的 BLR X8(handler分派点),截获每条指令执行前的112字节结构体,逆推编码格式:
Header (4 bytes):
[opcode_lo] [opcode_hi] [flags] [cls]
└────────────────┘ └───┘ └─┘
16-bit opcode 标志 操作数个数
Operand × cls:
[fmt] (1 byte)
fmt == 0x04 → [imm32_le] (4 bytes, 小端立即数)
fmt == 0x01 → [reg] (1 byte, 寄存器索引)
示例 ADD acc, acc, tmp(.sbc:100AB):
Raw: 00 01 00 03 01 0E 01 0E 01 0F
^^^^ ^^^^^ ^^^^^ ^^^^^
opcode op0 op1 op2
0x0100 acc acc tmp
=ADD r14 r14 r15
Header: opcode=0x0100(ADD), flags=0x00, cls=0x03(3 operands)
Op0: fmt=0x01(reg), idx=0x0E(acc) → 目标
Op1: fmt=0x01(reg), idx=0x0E(acc) → 源1
Op2: fmt=0x01(reg), idx=0x0F(tmp) → 源2
长度: 4 + 3×2 = 10 字节
验证方法:将推测的编码格式直接解码 .rodata:0x63DA0 处的5414字节原始数据,逐条与Unicorn动态trace的指令序列比对——684条指令全部吻合,证明编码格式正确。
指令集总表(60+条)

8.3 从反汇编到反编译
Step 1 — 线性反汇编
直接按偏移解码字节流,输出IDA风格汇编:
.sbc:10892 06 03 00 02 01 0E 04 9F 9C E5 29 MOVALT acc, #0x29E59C9F ; delta
.sbc:1089D 03 03 00 01 01 00 PUSH r0
.sbc:108A3 00 03 00 02 01 00 01 0B MOV r0, r11
.sbc:108AB 03 03 00 01 01 01 PUSH r1
...
.sbc:108E7 04 03 00 01 01 01 POP r1
.sbc:108ED 06 03 00 02 01 0F 04 09 00 01 00 MOVALT lr, #0x10009
.sbc:108F8 00 04 00 01 04 09 00 01 00 JMP u32_truncate
问题:684条原始指令中大量PUSH/POP/MOV是寄存器保存/恢复,直接看完全不可读。
Step 2 — 递归下降 + 函数识别
改为递归下降解码:从入口0x10000跟随控制流,遇到JMP/条件跳转加入工作队列,跳过不可达代码。
函数识别模式:MOVALT lr, #ret_addr; JMP target = 函数调用(lr保存返回地址)。以 JMP [lr] 或 HALT 为函数结束。识别出5个函数,其中 u32_truncate 被18处调用。
Step 3 — 模式匹配提升为伪代码
反编译器的核心是多模式识别,将固定的指令序列折叠为高级语句。
模式A — u32表达式块:7个PUSH(保存寄存器上下文)→ 算术/位运算序列 → CALL u32_truncate → 7个POP。整个序列折叠为一行 tN = u32(expr),其中expr通过栈式符号执行构建。
模式B — 向量操作:PUSH r0; MOVALT acc, #imm; POP r0; VECPUSH r0, acc → vec.push(imm)。连续多个合并为 vec.push(0) x 10。
模式C — 常数赋值:MOVALT r0, #val; MOV rX, r0 → rX = val(消除r0中转)。
模式D — 内存操作:MOVALT tmp, #addr; STORE/LOAD r0, [tmp] → mem[addr] = r0/r0 = mem[addr],已知地址替换为符号名(v0, v1, sum等)。
模式E — 自赋值消除:MOV链传播后产生 r0 = r0 的无效赋值,直接删除。
Step 4 — 常量识别与标注
预定义TEA相关常量表,出现时自动标注:
KNOWN_CONSTANTS = {
0x29e59c9f: "delta", 0xf95d664a: "key[1]",
0x12aa364c: "key[2]", 0x33ad3cee: "key[3]",
0xaabbccdd: "key[0]",
}
Step 5 — 交错输出
最终产出三种视图,其中交错视图将每行伪代码与其对应的原始汇编以注释形式交织,便于逐行验证:
; .sbc:10892 06 03 00 02 01 0E 04 9F 9C E5 29 MOVALT acc, #0x29E59C9F ; delta
; .sbc:1089D 03 03 00 01 01 00 PUSH r0
; .sbc:108A3 00 03 00 02 01 00 01 0B MOV r0, r11
; ... (共 ~30 条)
; .sbc:108F8 00 04 00 01 04 09 00 01 00 JMP u32_truncate
r13 = u32(r11 + delta)
8.4 反编译结果
684条指令 → 约40行伪代码,TEA循环体完整可读(注意:VM内部v0/v1命名与算法相反,输出时 push(v1,v0) 交换回来):
func main():
vec.push(0) x 10 // 分配 10 个 slot
bridge(func=0x65, nargs=1) // 读 token 字节
...
counter = 0x1
loop:
if (counter >= 0x1C) goto done // 28 轮
// Phase 1: 算法的 v1 更新(VM 变量名 v0,<<4, >>7, key[1], key[2])
r13 = u32(r11 + delta) // sum += delta
t0 = u32(r12 << 0x4)
t1 = u32(t0 + key[1])
t2 = u32(r12 + r13)
t3 = u32(t1 ^ t2)
t4 = u32(r12 >> 0x7)
t5 = u32(t4 + key[2])
t6 = u32(t3 ^ t5)
v0 = u32(sum + t6) // VM 的 v0 = 算法的 v1_new
// Phase 2: 算法的 v0 更新(VM 变量名 v1,<<6, >>5, key[3], key[0]=0xAABBCCDD)
t8 = u32(v0 << 0x6)
t9 = u32(t8 + key[3])
t10 = u32(v0 + r13)
t11 = u32(t9 ^ t10)
t12 = u32(v0 >> 0x5)
t13 = u32(t12 + key[0]) // + 0xAABBCCDD
t14 = u32(t11 ^ t13)
v1 = u32(r12 + t14) // VM 的 v1 = 算法的 v0_new
counter++; goto loop
done:
vec.push(v1); vec.push(v0)
bridge(func=0x66, nargs=1) // 输出 %08x%08x
halt
反编译结果与第七章Unicorn trace还原的算法完全吻合:移位量、密钥、delta、轮数、轮结构全部一致,形成交叉验证。
产物: vm_static_disasm.py(静态反汇编+反编译), vm_decompile.py(Unicorn动态反编译)
输出: vm_static_output.txt(交错视图), vm_disasm.txt(纯汇编), vm_decompiled.txt(纯伪代码)
8.5 关键地址表
函数:
VM基础设施:

VM寄存器/内存访问:

Family handler:
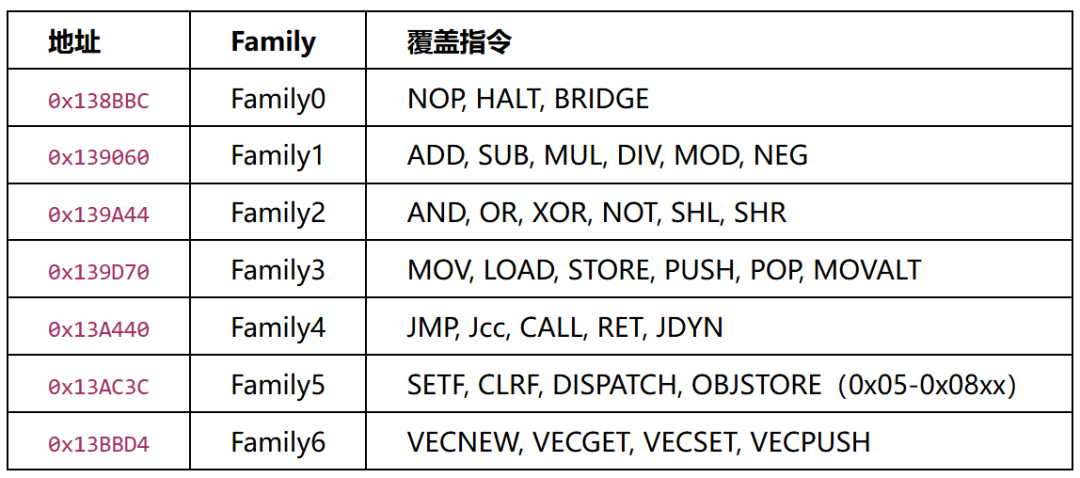
静态数据:
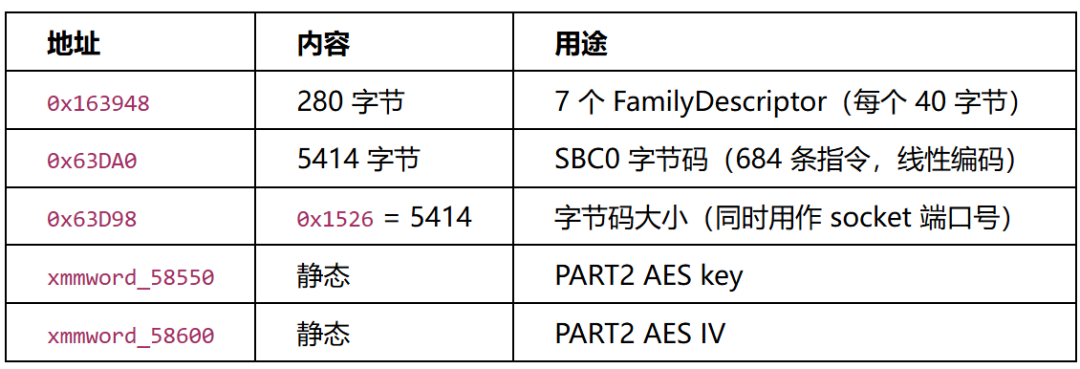
运行时缓冲区:
09 C++实现与交付物
三个PART的加密和解密算法均用C++实现,支持Token→Flag和Flag→Token双向转换。
> flag_tool.exe encrypt a2d576a6
Token: a2d576a6
PART1: flag{sec2026_PART1_2d55e927}
PART2: flag{sec2026_PART2_be088bdac626fff5c3eb0e12265ab9d4}
PART3: flag{sec2026_PART3_21441a664225fa06}
> flag_tool.exe decrypt 2 be088bdac626fff5c3eb0e12265ab9d4
Token: a2d576a6
Verify: encrypt(a2d576a6) = be088bdac626fff5c3eb0e12265ab9d4 OK
> flag_tool.exe verify
=== 16 passed, 0 failed ===
编译:cl /EHsc /O2 /std:c++17 /Fe:flag_tool.exe main.cpp part1_feistel.cpp part2_aes.cpp part3_tea.cpp
9.2 源码说明

9.3 全部交付物索引
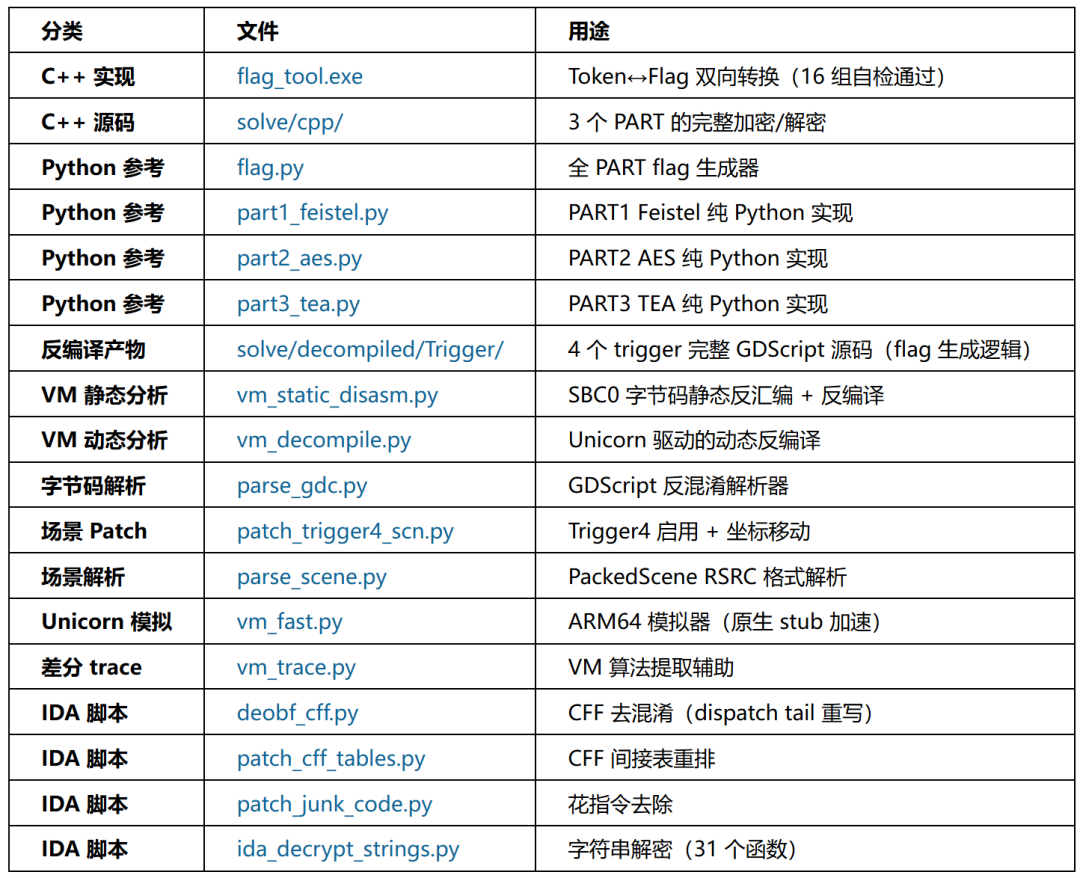
以上就是针对2026腾讯游戏安全技术竞赛安卓决赛的完整VM分析与还原过程。从引擎识别、资源提取、GDScript反混淆、反调试绕过,到三个加密算法的逆向还原,再到自研VM静态反编译器的构建,形成了一套完整的分析工具链。最终产物 flag_tool.exe 可双向转换Token与Flag,16组测试向量全部通过验证。
若对文中涉及的Reverse Engineering或Computer Arch相关技术有更深入的兴趣,欢迎来云栈社区与更多同好交流探讨。
 发表于 2026-5-20 04:27:37
|
查看: 148|
回复: 0
发表于 2026-5-20 04:27:37
|
查看: 148|
回复: 0
