在 Linux 内核开发中,sg (scatter/gather) DMA 缓冲区的相关 dma_sync 同步操作频繁发生,涉及的 API 包括:
dma_sync_sg_for_cpu()dma_sync_sg_for_device()dma_map_sg()dma_unmap_sg()dma_sync_sgtable_for_device()dma_sync_sgtable_for_cpu()- ...
这类操作为许多外设所必需,例如 GPU、NPU、MMC、UFS 等,可以说是无处不在。部分硬件平台提供了 CPU 与设备间的硬件缓存一致性支持,通常会在设备树(dts)节点中标注 dma-coherent 属性,例如:
sata0: sata@e0300000 {
compatible = "snps,dwc-ahci";
reg = <0 0xe0300000 0 0xf0000>;
...
dma-coherent;
};
然而,有大量硬件并不支持 CPU 与外设之间的缓存一致性。对于这些情况,无论是面向 CPU 还是设备,都可能需要进行昂贵的缓存清理(clean)或无效化(invalidate)操作,这常常成为性能分析中的热点。特别是在端侧 AI 推理场景下,模型大到几百 MB 甚至 1GB 的 DMA 缓冲区,其同步操作的耗时变得非常可观。
例如,在 Android 内核的 system_heap_do_allocate() 函数中,以下两行代码就可能导致处理器流水线的严重停滞:
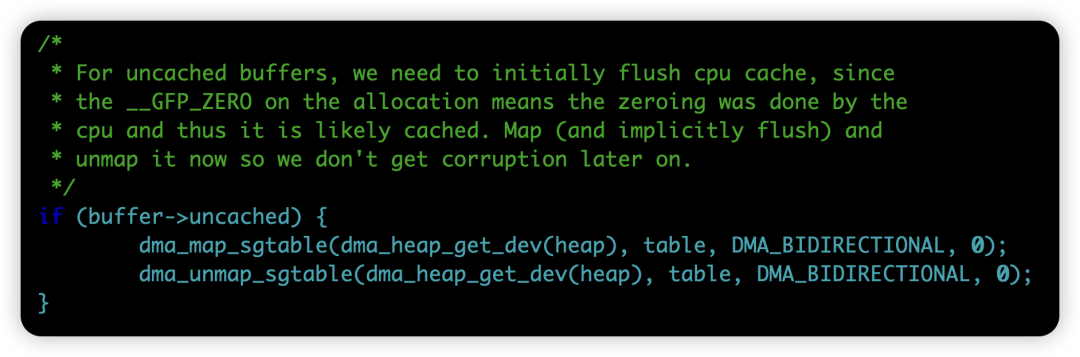
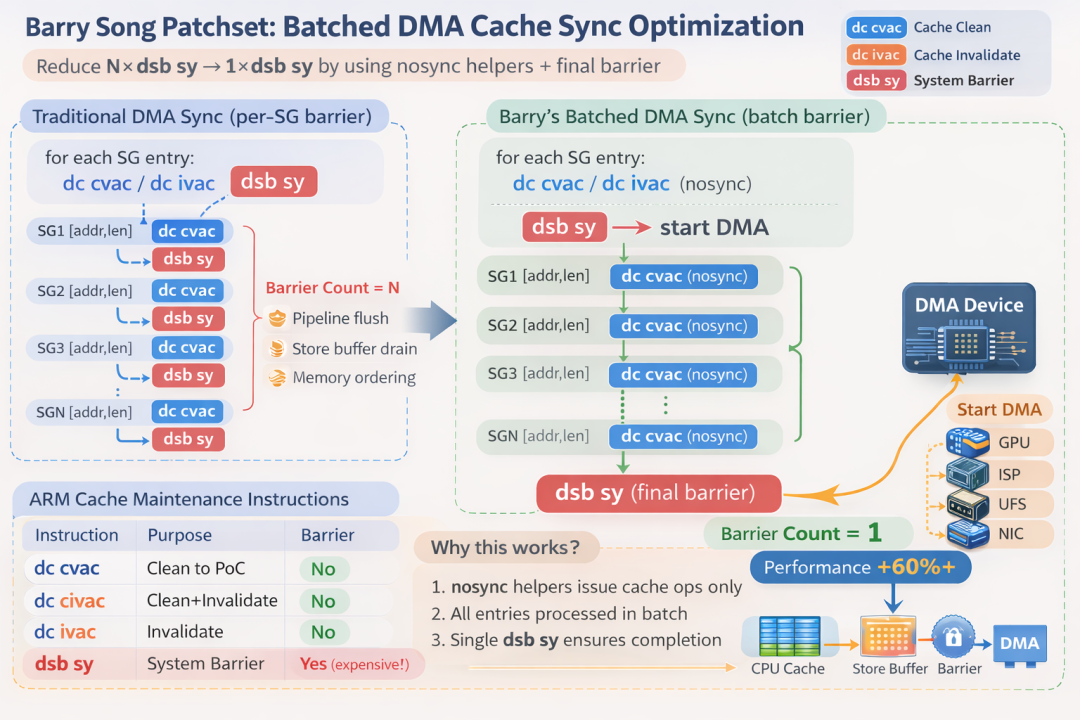
笔者通过观察发现,当前 ARM64 架构的相关实现,采用的是对每个 sg 条目(entry)执行一次缓存操作后,立即发出 dsb 指令进行同步等待的模式:
SG1: dc cvac → dsb sy
SG2: dc cvac → dsb sy
SG3: dc cvac → dsb sy
...
SGN: dc cvac → dsb sy
Barrier count = N
这意味着昂贵的 dsb 指令需要执行 N 次。结合对 ARM64 微架构及 dsb 指令原理的理解,这里存在一个明显的优化机会:我们可以将 N 次 dsb 合并为一次,即在处理完所有 sg 条目后,执行一次最终的 dsb 来确保前面所有的缓存操作完成。
SG1: dc cvac (nosync)
SG2: dc cvac (nosync)
SG3: dc cvac (nosync)
...
SGN: dc cvac (nosync)
dsb sy
由于 dsb 指令开销巨大,如果将其从 N 次减少到 1 次,将带来显著的性能提升。根据在 MediaTek 天玑 9500 平台上的测试,优化后可录得高达 66% 的耗时降低。
其工作原理可以通过下图清晰展示(此图由 ChatGPT 在阅读相关补丁集后生成):
目前,笔者的这一系列补丁集已进入 dma-mapping 子系统维护者的代码树,等待下一个合并窗口(预计为 Linux 内核 7.1 版本)。你可以在诸如 云栈社区 这样的技术论坛关注 Linux内核 开发的最新动态。
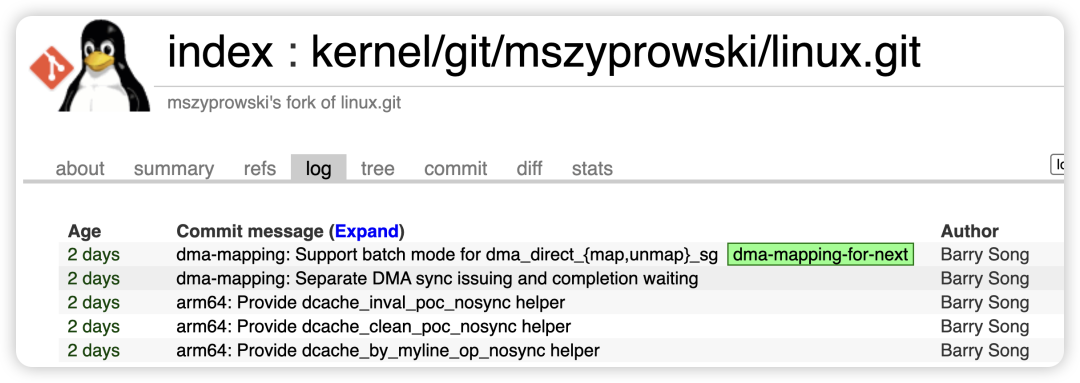
主要的代码修改涉及 arch/arm64 的缓存同步操作,以及 dma-mapping、swiotlb、iommu 等模块的批处理支持:

这项优化工作得到了社区志愿者陈雪原的测试支持。大量的验证工作在 Radxa 的 rock-5b-plus 开发板上完成,在此感谢 Radxa 提供的板卡支持,以及 Rockchip 的闫孝军、陈家立等专家和 Radxa 汤亮等工程师提供的宝贵技术支持。这项优化本质上是对 ARM64 平台下 DMA 操作流程的一次重要性能调优。 |  发表于 2026-3-17 00:14:50
|
查看: 132|
回复: 0
发表于 2026-3-17 00:14:50
|
查看: 132|
回复: 0
