随着自然语言处理技术的飞速发展,法律判决预测已成为法律科技领域的核心任务之一。然而,现有研究主要基于既定的法律事实进行预测,这与诉讼早期只有证据的实际情况存在时序矛盾。最新的研究探索了一种全新的任务范式——基于证据的法律事实预测。该任务旨在填补从证据到判决的关键缺失环节,并基于首个LFP基准数据集LFPBench进行了深入的实证分析。
5.1 LFP对判决预测的性能提升
下表详细列出了各模型在三种不同流程下的判决预测准确率,这是本研究最核心的数据成果。
表3:不同LJP流程与模型下的判决预测准确率 (%)
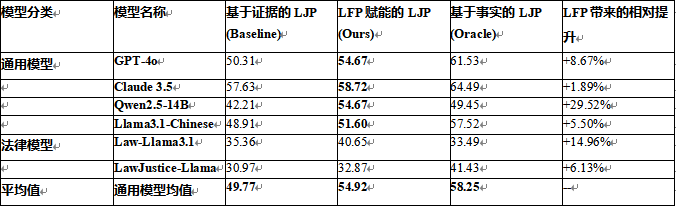
依据表3数据可以得出以下结论:
-
LFP的“桥梁”作用显著:
- 如果不进行事实预测,直接从证据跳到判决,通用模型的平均准确率仅为49.77%,远低于基于完美事实的58.25%。这证实了“缺少事实”是LJP的巨大短板。
- 引入LFP任务后,通用模型的平均准确率提升至54.92%。这意味着LFP成功填补了约38.5%的性能鸿沟。这有力地证明了LFP作为中间推理步骤的必要性。
-
Qwen2.5的惊人表现:
- 值得注意的是,Qwen2.5在直接预测时表现较差(42.21%),但在引入LFP后,其准确率飙升至54.67%,甚至超过了其基于事实的预测表现。这表明该模型具有极强的推理潜力,但需要正确的引导(即LFP任务)来激发。这种对复杂任务范式的适应性,体现了先进大语言模型在特定引导下的强大能力。
-
Claude 3.5的领先地位:
- Claude 3.5在所有通用模型中表现最佳,无论是在证据处理还是事实推理上,都展现出了顶尖的水平,其基于事实的预测准确率高达64.49%,确立了当前的性能天花板。
5.2 法律垂域大模型的“灾难性遗忘”
实验结果揭示了一个值得深思的现象:部分所谓的“法律垂域大模型”在处理复杂LFP任务时,表现远不如通用大模型,甚至接近随机猜测。
基于对多个模型在复杂法律任务上表现的深度分析,一个尤为值得关注的发现是:专门的领域微调模型(如Law-Llama3.1和LawJustice-Llama)的整体性能不仅未能超越其通用基础模型,反而在多项关键指标上表现最差。
这一反常现象极有可能是由“灾难性遗忘”所导致的。这类模型通常采用“通用基础模型 + 领域数据微调”的范式进行训练,即在通用底座上使用大量简短的法律问答对进行指令微调。此过程虽然让模型高效记忆了大量的法律术语和表面知识,但大量短文本指令对的强化学习,很可能覆盖并严重削弱了基础模型原本具备的、对处理长文本、进行复杂逻辑链推理以及遵循多步指令至关重要的通用核心能力。这提醒我们,在追求领域专业化时,必须警惕训练方法对模型底层深度学习能力的潜在损害。
5.3 事实质量与判决质量的正相关性
研究进一步探究了预测事实的质量如何影响最终判决。通过生成不同相似度的法律事实,并观察对应的LJP准确率,研究发现了明确的相关性。
表4:事实相似度与判决准确率的相关性分析
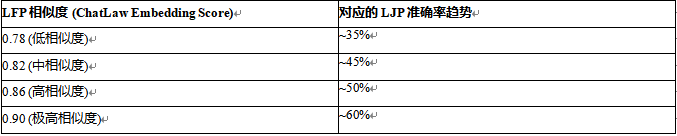
由表4可以看出,数据呈现出严格的正相关性。预测的法律事实越接近真相,判决预测就越准确。这不仅反向验证了LFP任务的重要性,也说明LFP模块并非仅仅是产生“中间文本”,其实质性的推理质量直接决定了下游任务的成败。
第六章 挑战与系统性偏见分析
在验证了LFP有效性的同时,研究也深入剖析了当前模型在面对复杂法律场景时的局限性与系统性偏见。
6.1 “败诉”预测的极高难度
模型在预测原告“完全胜诉”时的表现远好于预测“败诉”或“部分胜诉”。
表5:不同判决结果下的预测准确率分析

根据表5可知,当前大模型对司法案件的预测存在盲目乐观倾向,倾向于高估原告的胜诉概率。这一缺陷突出表现为对“败诉”案件的预测准确率断崖式下跌至平均仅11.99%。究其原因,完全胜诉的案件通常证据确凿、逻辑简单,而败诉或部分胜诉案件往往涉及复杂的证据博弈与事实认定。目前模型难以深入理解“证据不足”或“反证有效”的法律逻辑,倾向于简单地将原告提交证据等同于主张成立,在实际应用中可能误导用户盲目诉讼,具有显著的风险性。
6.2 被告证据的干扰效应
数据表明,当被告提交证据时,模型的预测性能普遍下降。这同时说明模型在处理冲突信息时存在短板。当面对“原告说东,被告说西”的罗生门时,模型难以像人类法官一样通过证据效力层级来裁决真伪。
6.3 证据形式带来的挑战:文本 vs 非文本
通过对不同案由的细分化分析,我们发现模型的表现存在显著差异。例如,在以合同等书面文本为主要证据的案件中,模型表现较好。而在依赖医疗影像、照片等非文本信息作为关键证据的案件中,模型表现明显欠佳。由于当前的LFP系统仅基于文本描述进行推理,大量多模态细节丢失,导致预测准确性受限。由此可见,未来的LFP系统亟需向多模态方向发展。
6.4 位置偏见:先后顺序决定胜负?
研究发现,证据输入的顺序竟然会左右模型的判断,这揭示了大模型底层的注意力机制缺陷。
表6:证据顺序对判决预测的偏差影响

依据表6可知,模型表现出显著的近因效应。当某一方的证据放在最后输入时,模型对其更加关注。特别是当原告证据放在最后时,模型预测其“完全胜诉”的概率远超真实值。而这种非理性的偏见在法律场景中是不可接受的。
6.5 数量偏见:多即是正义?
数据分析显示,模型存在简单的启发式思维:证据越多,胜算越大。
图3:证据数量差值对判决预测偏差的影响

随着原告证据数量优势的扩大,模型预测“完全胜诉”的概率显著高于真实值。然而在法律实践中,证据在质不在量。一份关键的证据胜过一百份无关痛痒的证词。目前的大模型显然还未掌握这一法律逻辑,容易被“证据轰炸”所迷惑。
总结
本次实证研究清晰地表明,引入LFP任务能有效弥合基于证据与基于事实的判决预测之间的性能鸿沟,证明了其作为法律AI关键中间步骤的价值。然而,研究也暴露了当前模型,包括部分法律垂域模型,在处理复杂法律推理时存在的严重短板与系统性偏见,如对败诉预测困难、易受证据顺序和数量干扰等。这些发现为未来法律AI的研究与发展指明了方向:不仅需要更高质量的任务范式与数据集,还需要在模型训练中着重解决偏见问题,并探索多模态等更全面的技术路径。深入的技术探讨与实践经验分享,也欢迎大家在云栈社区的相关板块进一步交流。
 发表于 2026-3-17 00:17:19
|
查看: 153|
回复: 0
发表于 2026-3-17 00:17:19
|
查看: 153|
回复: 0
