项目卡片
- 项目:OpenAI Privacy Filter[1]
- 状态:v0.1.0 / 1.5K Stars(10 天内)/ Apache 2.0
- 一句话判断:目前最值得关注的本地 PII 检测模型——体积小、上下文长、架构精巧、完全开源可商用
4 月 17 日,OpenAI 在 GitHub 上公开了 Privacy Filter(简称 OPF)——一个完整的本地 PII(个人身份信息)检测与脱敏工具链,模型权重采用 Apache 2.0 协议开源。
几个关键数字:128K token 上下文、50M 活跃参数(总参 1.5B)、支持微调。目前能将这四点同时做好的 PII 方案,我还没看到第二个。
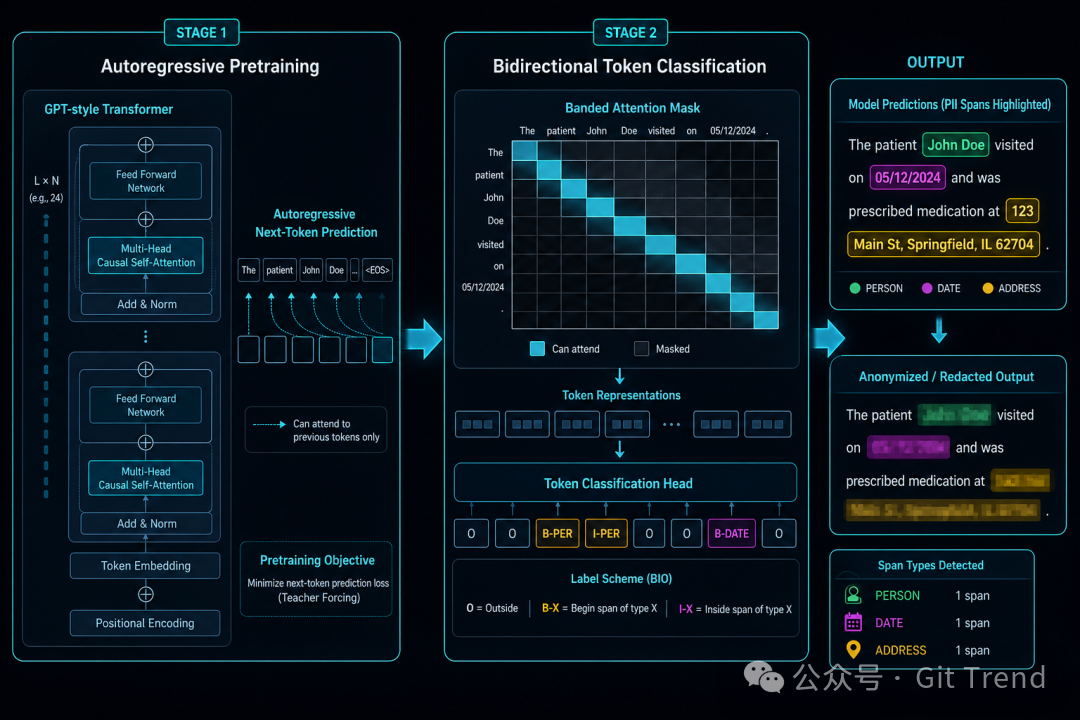
架构:从自回归基座改造来的双向分类器
我一开始以为它会像 Presidio 那样走规则 + ML 混合路线,看完源码才发现设计意图完全不同。
训练分两个阶段。第一阶段做自回归预训练,得到一个类似 GPT 架构的基座模型。第二阶段把这个模型改造成双向 token 分类器——语言模型输出头换成隐私标签分类头,用监督分类损失做后训练。
具体到模型结构:8 层 Transformer block,使用分组查询注意力(14 个 query head、2 个 KV head),RoPE 位置编码,以及 128 个专家的稀疏 MoE 前馈网络(每个 token 激活 top-4)。总参数 1.5B,但因为 MoE 的存在,每次推理只激活约 50M 参数。
注意力机制也做了关键改造:因果掩码被替换成带状双向注意力(band size 128,左右各 128 token,共 257 token 有效窗口)。这对 PII 检测来说很关键——判断 "123 Main St" 是不是地址,往往需要同时参考前后的上下文,单向注意力做不到这一点。
权重存储使用了 MXFP4 量化(一种 4-bit 浮点格式,16 个查找值 + int8 指数缩放),加载时会自动反量化为 bfloat16。这让模型文件更小,同时推理时保持数值精度。如果你想深入了解类似高效架构的设计思路,可以参考社区里对 Transformer 及其变体的讨论。
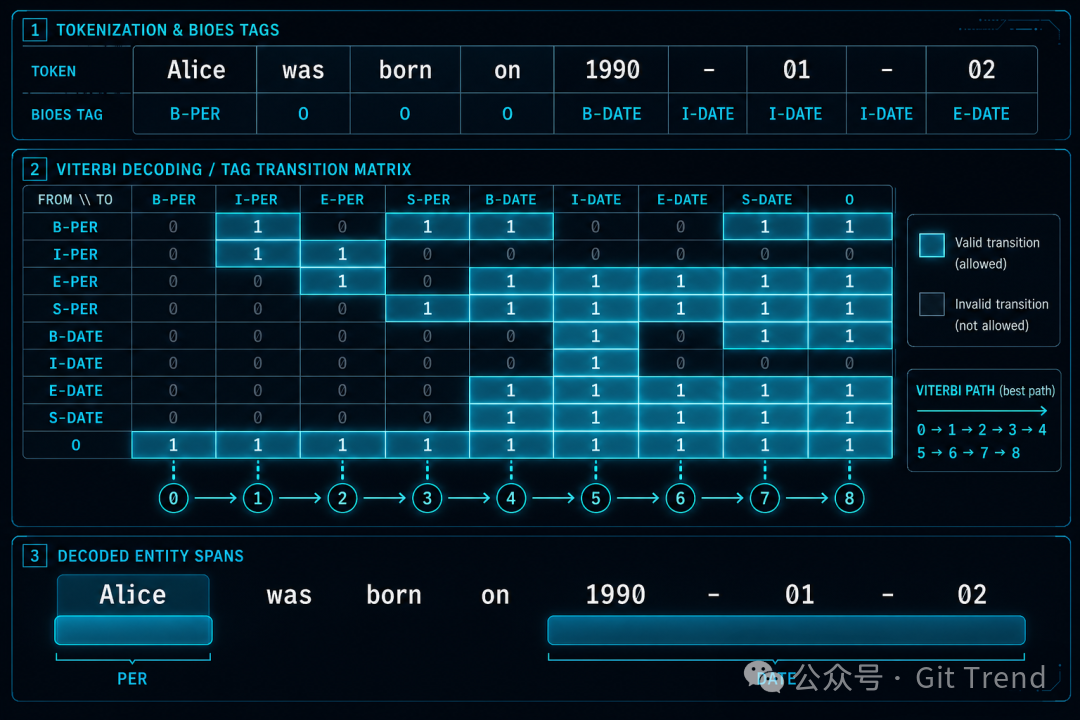
解码:Viterbi 约束解码,不是逐 token 独立决策
模型对每个 token 输出 33 个类别的 logits(1 个背景 + 8 类 PII × 4 个 BIOES 标签)。但问题来了:怎么把这些逐 token 预测变成连贯的实体 span?
最简单的做法是对每个 token 独立取 argmax。OPF 则用了约束 Viterbi 解码器——CRF 风格的全局路径优化。解码器维护一张 BIOES 转移分数表,只允许合法的标签转移(B-person 后面只能跟 I-person 或 E-person),然后找出全局最优路径。
这个设计让它在噪声文本里也能输出连贯的 span。单看某个 token 的局部预测可能不稳定,但全局约束能把碎片化的标签修正成完整的实体。
解码器还暴露了 6 个运行时可调的转移偏置参数,控制"倾向于留在背景"、"倾向于开启新 span"、"倾向于延续当前 span"等行为。调节这些参数,用户就能在精确率和召回率之间做运行时权衡——不需要重新训练模型。
检测的 8 类隐私信息
OPF v2 标签体系覆盖 8 个类别:
| 类别 |
示例 |
private_person |
人名、代号 |
private_email |
电子邮箱 |
private_phone |
电话号码 |
private_address |
物理地址 |
private_url |
个人 URL |
private_date |
日期 |
account_number |
账号 |
secret |
密钥、凭证 |
代码中已经预留了 v4(12 类)和 v7(24 类)两个更大标签体系的定义,说明 OpenAI 内部在持续推进粒度迭代。当前开源的 v2 足以作为起点。
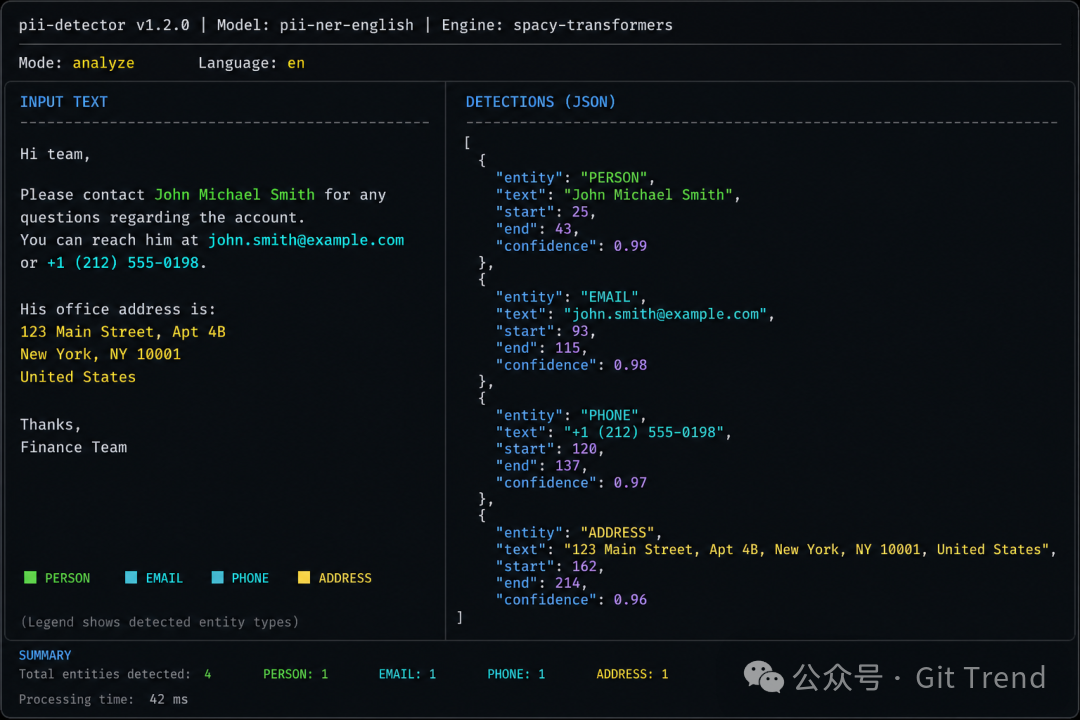
用法:三行命令上手
pip install -e .
opf "Alice was born on 1990-01-02."
首次运行会自动从 HuggingFace 下载模型到 ~/.opf/privacy_filter。也可以指定自定义路径:
opf --checkpoint /path/to/checkpoint --device cpu "Alice was born on 1990-01-02."
输出示例(JSON 模式):
{
"schema_version": 1,
"summary": {
"output_mode": "typed",
"span_count": 2,
"by_label": {"private_person": 1, "private_date": 1}
},
"redacted_text": "<PRIVATE_PERSON> was born on <PRIVATE_DATE>."
}
除了单行输入,还支持文件处理(opf -f file.txt)和管道操作(cat file | opf)。无输入时进入交互模式,终端会显示彩色标注预览。
Python API 同样简洁:
from opf import OPF
redactor = OPF(device="cpu")
result = redactor.redact("Alice was born on 1990-01-02.")
print(result.redacted_text)
# <PRIVATE_PERSON> was born on <PRIVATE_DATE>.
微调:标签体系可以换
在实际场景中,很多团队要检测的不是"通用 PII",而是公司自己定义的敏感信息。OPF 的微调流程直接解决了这个问题。
opf train /path/to/train.jsonl --output-dir /path/to/finetuned_checkpoint
更灵活的是自定义标签空间。通过 --label-space-json 可以定义完全不同的隐私分类体系,比如把 account_number 替换成公司特有的 employee_id:
{
"category_version": "custom_v1",
"span_class_names": ["O", "custom_account_id", "custom_secret"]
}
仓库里有两个可复现的微调 demo:一个演示策略迁移(把 account_number 重标注为 secret),另一个从零定义新标签空间。用的 toy 数据集——每个 split 才 1 条样本——但流程本身是对的,换成真实数据就能直接跑。
和常见方案的差异
vs Presidio(Microsoft):Presidio 是规则 + ML 混合方案,对格式化数据(邮箱、手机号)效果很好,但对人名、地址等需要上下文判断的类别较弱。OPF 是纯模型方案,上下文理解能力更强。
vs LLM API 方案:用 GPT-4 做 PII 检测效果不错,但要发数据到外部、成本高、延迟大。OPF 全部本地运行,Apache 2.0 协议可商用,128K 上下文一次处理整篇文档。
vs 开源 NER 模型(如 spaCy):spaCy 的 NER 主要是通用实体识别,PII 检测不是其主要目标。OPF 是专门为隐私过滤设计的,标签体系、解码策略、运行时调优都围绕这个目标。
核心差异总结:OPF 是目前唯一一个同时做到"本地运行、128K 上下文、MoE 小体积、可微调、Apache 2.0 可商用"的 PII 检测方案。
需要注意的地方
README 对局限性的描述很坦诚,有几点值得提前了解:
- 非英语和特殊命名:非拉丁文字、受保护群体的命名模式、非常规格式可能检测不准
- 标签策略是静态的:运行时不能动态增减检测类别,得走微调
- 不是合规工具:官方原文写的是"数据脱敏辅助工具",不是匿名化保证
- 高敏感场景需人工兜底:医疗、法律、金融等场景,漏检和过度脱敏都有代价
如果是我自己用,会在生产前先用自己领域的数据跑一轮 eval(opf eval 命令直接支持),看基线模型在本场景的 precision/recall 再决定是否微调。
值不值得试
以下场景值得认真评估 OPF:
- 构建数据清洗管线,送入 LLM 前脱敏
- 处理长文档(合同、病历、日志),不想切分
- 数据不能出域,需要本地部署
- 有自定义 PII 定义,需要微调适配
但如果只是脱敏几条短文本,或者需要 100% 召回的合规级脱敏呢?那还是先看 Presidio 或规则方案更稳妥。
另外,这个仓库的源码质量值得细读。从自回归到双向分类的后训练转换、MoE 在分类任务上的用法、带状双向注意力、Viterbi 约束解码——都不是教科书上的标准做法,但都有清晰的工程动机。对关注 ML 模型设计的人来说,光看 opf/_model/model.py 和 opf/_core/decoding.py 这两个文件就够消化一阵子了。
有兴趣深入了解这类前沿开源项目的实现细节,不妨多逛逛 云栈社区 的开源实战板块,那里沉淀了不少高质量的源码分析与技术讨论。
引用链接
[1] OpenAI Privacy Filter: https://github.com/openai/privacy-filter
 发表于 2026-5-1 23:01:50
|
查看: 298|
回复: 0
发表于 2026-5-1 23:01:50
|
查看: 298|
回复: 0
