最近有读者提出了一个很好的技术问题:在ARM汇编中,既然已经使用了 bl 指令进行跳转,为什么有时还需要 push/pop(对应ARM64的 stp/ldp)指令来保存和恢复寄存器?本文将通过一个完整的实验来验证,为什么在调用的函数内部还包含 bl 指令时,必须提前保存返回地址,否则程序会直接“跑飞”。
实验结论先行:如果不写 push/pop(ARM64下为 stp/ldp)这两行关键指令,真的会导致程序崩溃。 为了彻底弄懂这个问题,笔者用 AArch64 的交叉编译链亲自进行了调测,并将完整的分析过程与调试步骤呈现出来。
一、核心原理:两个必须理解的底层规则
在进行实验前,必须先搞清楚两个导致所有问题的底层规则。
规则一:bl 指令的副作用
bl 函数名 是 ARM 架构的函数调用指令,它实际上做了两件事:
- 跳转到目标函数的地址执行。
- 自动把“下一条指令的地址”写入
x30(64位)或 lr(32位)寄存器。
这里有一个关键点:执行 bl 时,硬件会直接覆盖 x30/lr 原有的值!
规则二:返回地址的本质
一个函数能够正确返回,完全依赖于 x30/lr 寄存器中存储的那个“调用者的返回地址”。如果你的函数内部还需要调用其他函数(即再次使用 bl),那么原来从主调函数那里得来的返回地址就会被新的 bl 指令覆盖掉。因此,在调用内部函数之前,你必须将当前的返回地址提前保存到栈上!
理解这两个规则后,我们通过实验来直观感受它们的作用。
二、AArch64 (ARM64) 实验:正常版本 vs 崩溃版本
我们先从当前主流的 64 位架构开始,用两份几乎一模一样的代码,来对比那几行关键指令的作用。
首先,看一个简单的 C 语言源代码 day3.c:
#include <stdio.h>
#include <stdlib.h>
int add(int a, int b) {
printf("a=%d, b=%d, a+b=%d\n", a, b, a+b);
return a+b;
}
int main() {
return add(1, 2);
}
将其编译并反汇编,可以看到编译器自动生成的代码遵守了所有规则。但为了更好地理解,我们手动编写与之行为完全一致的汇编代码。
[1] 正常工作版本:day3_ok.s
这是遵循所有规范的汇编代码,逻辑与上面的 C 代码完全一致。
.global add
.global main
.global printf
add:
// 第一步:在调用任何其他函数前,先保存上下文
// 将帧指针(x29)和返回地址(x30)保存到栈,并保持16字节对齐
stp x29, x30, [sp, #-16]!
// 输入参数:a = x0, b = x1 (AArch64调用约定)
// 将参数备份到临时寄存器,避免后续调用被覆盖
mov x4, x0 // x4 = a
mov x5, x1 // x5 = b
add x6, x4, x5 // 预计算 a+b,结果存入 x6
// 为 printf 调用设置参数
adrp x0, fmt
add x0, x0, :lo12:fmt
mov x1, x4 // printf 参数1: a
mov x2, x5 // printf 参数2: b
mov x3, x6 // printf 参数3: a+b
bl printf // 调用 printf。x30 已保存,可以安全地被覆盖
// 设置返回值:将 a+b 放入 x0 (ARM64的返回值寄存器)
mov x0, x6
// 返回前恢复上下文
ldp x29, x30, [sp], #16
ret
main:
// 主函数:同样先保存上下文
stp x29, x30, [sp, #-16]!
// 调用 add(1, 2),完全匹配 C 代码逻辑
mov x0, #1 // add 参数1: a=1
mov x1, #2 // add 参数2: b=2
bl add
// 恢复上下文,add 的返回值已存入 x0
ldp x29, x30, [sp], #16
ret
fmt:
.string "a=%d, b=%d, a+b=%d\n"
使用以下命令编译:
aarch64-linux-gnu-gcc -o day3_ok day3_ok.s
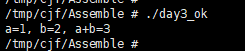
运行结果正常,正确打印了相加结果并退出。
[2] 崩溃版本:day3_crash.s
这个版本我只注释了函数开头保存上下文的 stp 指令和结尾恢复上下文的 ldp 指令,并添加了在返回前打印 x30 地址的调试代码。其他逻辑与正常版完全相同。
.global add
.global main
.global printf
add:
// 第一步:在调用任何其他函数前,先保存上下文(已注释掉关键指令)
// stp x29, x30, [sp, #-16]!
mov x4, x0 // x4 = a
mov x5, x1 // x5 = b
add x6, x4, x5 // 预计算 a+b
adrp x0, fmt
add x0, x0, :lo12:fmt
mov x1, x4
mov x2, x5
mov x3, x6
bl printf // 调用 printf!这里会覆盖 x30
mov x0, x6
// 添加调试代码:打印此时 x30 寄存器的值
adrp x0, debug_fmt
add x0, x0, :lo12:debug_fmt
mov x1, x30
bl printf
// 恢复上下文(也已注释掉)
// ldp x29, x30, [sp], #16
ret
main:
stp x29, x30, [sp, #-16]!
mov x0, #1
mov x1, #2
bl add
ldp x29, x30, [sp], #16
ret
debug_fmt:
.string "Before return, x30 = %p\n"
fmt:
.string "a=%d, b=%d, a+b=%d\n"
使用以下命令编译:
aarch64-linux-gnu-gcc -o day3_crash day3_crash.s
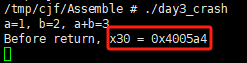
运行结果如下图所示,程序打印了加法结果和 x30 的值后,便卡住或发生段错误,未能正常退出。
调试分析:为什么程序会跑飞?
我们使用 GDB 来一探究竟。在 add 函数的 ret 指令处下断点:
gdb day3_crash
在 GDB 中执行:
b *add+0x2c
run
p/x $x30
打印出的 x30 值为 0x00000000004005a4。这个地址根本不是 main 函数中 bl add 指令之后的返回地址,而是 printf 函数的返回地址!
原因分析: 当我们在 add 函数中执行 bl printf 时,根据规则一,硬件自动将 printf 的返回地址写入了 x30 寄存器。由于我们在进入 add 函数时没有用 stp 指令将 main 函数赋予的原始返回地址保存到栈中,这个原始地址就被永久覆盖、丢失了。最后,ret 指令会读取 x30 的当前值(即 printf 的返回地址)并跳转过去,这显然是一个错误地址,直接导致了程序卡死或段错误。
这个实验完美地验证了开头提到的底层规则。在涉及多层函数调用的计算机基础知识中,对调用栈和寄存器状态的清晰理解至关重要,尤其是在进行底层调试时。
三、不同架构的指令差异:ARM32 vs AArch64
理解了核心原理后,我们来看一下不同 ARM 架构在实现这一机制时的语法差异。下表清晰地展示了 ARM32 (ARMv7) 与 AArch64 (ARM64) 的关键区别。

简要说明:
- ARM32:使用
push {r7, lr} 保存帧指针和返回地址,使用 pop {r7, pc} 恢复并直接跳转返回。
- AArch64:使用
stp x29, x30, [sp, #-16]! 保存帧指针和返回地址,使用 ldp x29, x30, [sp], #16 恢复,并使用专门的 ret 指令返回。
尽管具体的汇编指令和寄存器名称不同,但其核心逻辑是完全一致的:如果一个函数内部使用了 bl 指令调用了其他函数,则必须在调用前将当前的返回地址(lr/x30)保存到栈内存中,否则它将被覆盖,导致无法正确返回。
希望通过这个从理论到实践、再到调试验证的完整过程,能帮助你深刻理解ARM汇编中函数调用的这一关键机制。在实践中遇到程序莫名跑飞时,不妨检查一下是否遗漏了这些保存上下文的指令。如果在学习过程中有更多心得或疑问,欢迎在云栈社区与大家交流探讨。
 发表于 2026-3-26 03:55:16
|
查看: 149|
回复: 0
发表于 2026-3-26 03:55:16
|
查看: 149|
回复: 0
