同一个大语言模型,仅仅更换一套外围的调用框架,其在编程基准测试中的得分就能实现翻倍。围绕这个名为 Harness 的工程概念,业界已经争论了近两个月。现在,斯坦福大学的研究团队给出了一个意想不到的答案:别吵了,让AI自己来做这件事。
Harness为何成为争议焦点?
2026年初,Harness 无疑是AI工程领域最热门的概念之一。它指的是模型之外的一切——包括提示词模板、上下文管理策略、检索增强逻辑、多步推理编排以及工具调用流程。简单来说,你怎么调用模型,其重要性可能与模型本身旗鼓相当,甚至更高。
一系列数据证实了这一点:OpenAI Codex团队在编写了百万行Agent代码后,总结出“Agent不难,Harness才难”的教训;在SWE-Bench Mobile评测中,同一个Claude Opus 4.5模型在不同的Harness下,成功率从2%跃升至12%,差距高达6倍;LangChain的编码Agent在Terminal Bench 2.0上,仅通过优化Harness而不改动底层模型,得分就从52.8%提升至66.5%,排名飙升。
然而,争议随之而来。反对者如OpenAI的Noam Brown认为,Harness本质是“拐杖”,终将被更强大的模型所超越——推理模型问世后,大量精心设计的智能体系统被迅速淘汰便是明证。Claude Code团队也主张“所有秘密都在模型本身”,应追求最简洁的包装。
Anthropic的实践提供了一个微妙视角。他们曾为Opus 4.5设计了一套复杂的Harness,但在Opus 4.6发布后,他们果断对Harness做了减法:简化流程、移除冗余,不仅性能提升,成本也从6小时200美元降至3.8小时125美元。这套操作被称为 “Build to Delete”——Harness的复杂度应随模型能力边界的变化而动态调整。
因此,争论的核心并非Harness是否重要,而在于认识到 Harness并非静态产物。它需要随着模型迭代、任务变迁和能力演进而持续优化。正是基于这一洞察,斯坦福大学的Yoonho Lee团队与MIT的Omar Khattab合作,提出了一个颠覆性的解决方案:让AI自主优化自己的Harness。

这项名为 “Meta-Harness: End-to-End Optimization of Model Harnesses” 的研究,其核心思路看似“反智”,实则暴力:让一个足够强大的编码智能体,通过多轮迭代不断优化用于调用另一个模型的Harness。整个过程不进行任何信息压缩,将所有历史尝试完整保存,供智能体自行查阅、分析,并生成更好的框架。
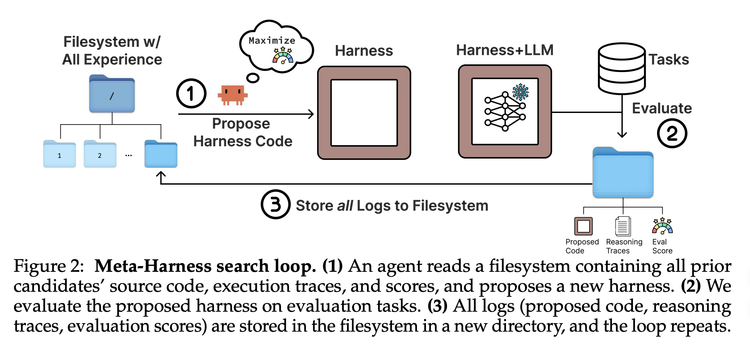
具体流程如下:每一轮迭代产生的所有内容——候选Harness的完整源代码、每个样本的详细执行轨迹、以及最终的评分结果——都会以文件形式保存到结构化的目录中。没有复杂的数据库或向量检索,仅仅是最朴素的文件系统。
随后,一个编码智能体会被置入该系统,它的唯一任务是:“基于之前所有的尝试经验,编写一个性能更好的Harness。” 外层循环极其简洁:生成候选 → 评估 → 保存完整结果 → 智能体分析全量历史 → 生成新候选 → 重复。整个过程不依赖花哨的搜索算法,全部的“智能”都来源于智能体自身的代码理解与推理能力。
为何传统优化方法失效?
Meta-Harness的方案虽然朴素,却解决了以往自动优化方法的一个通病:信息丢失。过去的文本优化器,如Google的OPRO、TextGrad等,通常对历史反馈进行过度压缩:有的只保留一个标量分数(如“准确率62%”),有的则将冗长的执行过程摘要成几句话。
这好比让工程师调试一个复杂系统,却只告知他上一个版本得了62分,没有日志、没有错误信息。他该如何改进?
Meta-Harness反其道而行。单轮评估可能产生高达1000万tokens的诊断信息,包括每个样本的输入、模型输出、正确答案及完整的中间推理步骤。智能体并非被动接收摘要,而是主动“进行研究”——自主决定阅读哪些文件。据统计,智能体每轮中位数会读取82个文件。它会分析表现最佳和最差的Harness源码,抽查特定样本的执行轨迹,从而发现诸如“模型总是将A类误判为B类”的模式,并通过对比不同设计的差异,推断出导致性能变化的关键决策。
为何现在才可行?
研究团队特别指出,Meta-Harness在2026年初才变得切实可行。这完全得益于过去一年中,编码智能体能力发生了质变。几年前的智能体根本无法在包含数百个文件的目录中自主导航、进行有意义的分析并编写出可运行的代码。如今,这已成为现实。这不仅是一个方法论的突破,更是一个关于技术成熟时机的故事。
三大任务验证:效果与效率的全面超越
理论需要数据支撑。Meta-Harness在文本分类、数学推理和编程智能体这三个差异巨大的任务上进行了验证,结果均显著优于现有方法。
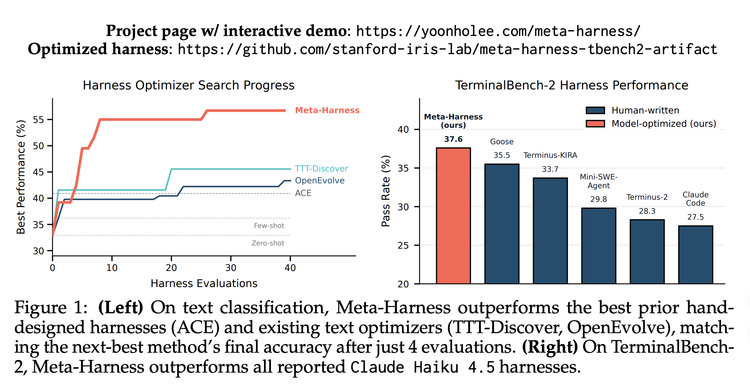
战场一:文本分类——4次迭代抵别人40次
在文本分类任务中,Meta-Harness取得了 48.6% 的准确率,比之前最强的手工基线ACE高出 7.7个百分点。更值得注意的是效率:其上下文token用量仅为11.4K,而ACE需要50.8K,减少了近4倍,实现了效果与成本的双赢。
收敛速度同样惊人:Meta-Harness仅需 4次评估迭代,就能达到其他优化器需要40次评估才能获得的性能。这证明,从完整执行轨迹中提取的信息密度,远高于只看分数或摘要的优化方式。
在分布外泛化测试中,将在5个数据集上搜索到的最优Harness直接应用于9个未见过的数据集,Meta-Harness的表现依然优于ACE。这表明它发现的是更优的通用框架设计,而非针对特定数据集的技巧。
| Table 5: OOD文本分类数据集评估结果 (部分) |
Harness |
Avg Acc |
| Few-shot (32) |
68.9 |
| ACE |
73.1 |
| Meta-Harness |
76.0 |
表:Meta-Harness在9个未见任务上的平均准确率超出次优方法2.9分。
战场二:数学推理——自动发现精细路由策略
在IMO难度的检索增强数学推理任务上,Meta-Harness自动发现了一种 “4路路由BM25检索策略”。系统学会了将数学题自动分类为组合、几何、数论和默认四类,并对每个类别应用差异化的检索参数。这种精细化的路由设计,并未经过任何人类工程师的预先指定。
其迁移能力同样出色:使用GPT-OSS-20B搜索到的最优Harness,在零样本迁移到5个未见过的推理模型时,性能均有提升。这说明优秀的框架设计具有普适性,Harness优化与模型选择是两个正交的维度,在Harness工程上的投入不会因更换模型而失效。
战场三:编程智能体——超越人类手工方案
在基于Claude Haiku 4.5的评测中,Meta-Harness以 37.6% 的通过率位列第一,超越了所有已知的手工Harness(如Goose及官方的Claude Code)。在Claude Opus 4.6组别中,也以 76.4% 的成绩获得第二。
更重要的是,Meta-Harness在此任务中自主发现了一个关键技巧——“Environment Bootstrapping”(环境自举):在智能体开始执行任务前,先自动运行shell命令收集沙箱环境快照(如OS版本、已安装软件包、目录结构等),并将其注入初始提示中。这消除了智能体通常需要的2到4轮探索步骤,为有限的推理预算节省了宝贵资源。这个优化点完全由系统在搜索过程中自行发现。
消融实验:信息完整性是成败关键
研究通过消融实验对比了不同信息保留策略的效果,结论一目了然:

- 仅保留分数 → 中位准确率 34.6%
- 分数 + 摘要 → 34.9%
- 完整执行轨迹(Meta-Harness) → 50.0%
提供完整轨迹带来了近15个百分点的性能提升,而摘要几乎毫无帮助,有时甚至因丢失关键细节而产生负面影响。这对整个“AI优化AI”领域是一个深刻启示:当智能体足够强大时,人为的信息预处理和压缩可能弊大于利。 将原始信息全量交付,让智能体自主决定关注点,往往能取得更佳效果。
重新审视“苦涩的教训”:自动化是终极答案
让我们回到最初的行业争论。将Meta-Harness置于其中,会发现有趣的调和。
Noam Brown的观点常被归入“苦涩的教训”阵营:依赖人类精心设计的工程终将被更暴力的计算规模所碾压,因此不应在框架工程上过度投入,而应赌注于模型能力的无限增长。
Meta-Harness同样基于“苦涩的教训”:通用搜索终将击败手工设计。因此,它没有否认Harness的重要性,也未否定模型会持续变强。它的主张是:既然手工设计的Harness终将过时,何不让AI来自动化这一过程?
简而言之,Noam Brown的版本是“别费力做Harness了”,而Meta-Harness的版本是“别费力手工做Harness了”。它重新定义了争论的坐标:模型与Harness并非对立。当Harness优化本身被自动化后,两条路线自然融合——模型变强,Meta-Harness搜索出的最优Harness也会随之变得更精简、高效。Anthropic手动实践的“Build to Delete”,在这套框架下将自动发生。
论文最后展望了一个更远的未来:Harness与模型权重的协同进化。目前,模型训练与框架设计仍是分离的。但如果Harness能够被自动优化,未来的训练过程能否将Harness也纳入优化循环?这与前阿里Qwen技术负责人林俊旸近期提出的“从推理思维到智能体思维”的观点不谋而合,即将Harness视为训练阶段的核心基础设施。
推理时的Harness优化,目标明确,易于评估,AI确实比人快。而训练时的Harness,其影响是长期、稀疏且难以归因的,这一层的搭建目前可能仍需人类的顶层设计。方向已然明晰,下一步,就看谁能率先将理念转化为实践。2026年的技术牌桌上,又多了一道待解的难题。
想了解更多前沿AI工程实践与开源项目剖析,可以关注云栈社区的技术动态。本文涉及的详细论文、代码及互动Demo,可在项目页面查看。
 发表于 2026-4-3 05:21:30
|
查看: 199|
回复: 0
发表于 2026-4-3 05:21:30
|
查看: 199|
回复: 0
