谈到高性能缓存与内存数据库,Redis 无疑是绕不开的核心组件。无论是应对高并发读写的缓存场景,还是作为分布式锁、消息队列的解决方案,Redis 都扮演着至关重要的角色。对于开发者而言,深入理解其原理是提升系统设计能力和通过技术面试的关键。本文将带你系统梳理 Redis 的核心知识点,内容源于云栈社区 的技术讨论与实践总结。
什么是 Redis?
- 定义:Redis(Remote Dictionary Server)是一个使用 C语言 编写的、开源(BSD许可)的高性能 非关系型(NoSQL) 键值对数据库。
- 核心能力:它可以存储键与五种不同类型值之间的映射。
- 特性与用途:Redis 支持数据持久化、主从复制、分片等高级特性,读写速度极快,每秒可处理超过 10万次 读写操作,是已知性能最快的 Key-Value 数据库。因此,它被广泛应用于缓存、分布式锁等场景,并支持事务、LUA脚本、LRU驱动事件及多种集群方案。
Redis 为什么那么快?
- 完全基于内存:绝大部分请求是纯粹的内存操作,避免了磁盘I/O的瓶颈。
- 数据结构简单:其数据结构是专门为各种场景设计的,对数据的操作也简单高效。
- 采用单线程模型:避免了不必要的上下文切换和竞争条件,也无需考虑多线程环境下的各种锁问题,如死锁导致的性能消耗。
- 使用多路 I/O 复用模型:基于非阻塞 I/O,可以高效处理大量并发连接。
Redis 的优缺点
优点:
- 读写速度快:数据存在于内存中,类似于 HashMap 的访问效率。
- 支持丰富数据类型:包括 String,List,Hash,Set,Sorted Set(Zset)。
- 支持事务:提供基本的一致性和隔离性保证,结合 RDB 和 AOF 也能实现一定的持久性。
- 支持主从复制:主机自动同步数据到从机,便于实现读写分离。
缺点:
- 缓存和数据库双写一致性问题。
- 缓存雪崩、穿透、击穿问题。
- 在线扩容较复杂,集群容量达到上限时扩容流程繁琐。
- 主机宕机前可能部分数据未及时同步到从机,切换后可能引发数据不一致,影响系统可用性。
- 缓存的并发竞争问题。
Redis 与 Memcached 的区别
- 数据类型
- Memcached 仅支持字符串类型。
- Redis 支持五种不同的数据类型,灵活性更高。
- 数据持久化
- Memcached 不支持持久化。
- Redis 支持两种持久化策略:RDB 快照和 AOF 日志。
- 分布式
- Memcached 本身不支持分布式,需客户端通过一致性哈希实现,存储和查询时都需计算数据所在节点。
- Redis Cluster 原生支持分布式。
- 内存管理机制
- 在 Redis 中,并非所有数据都常驻内存,可以将不常用的 value 交换到磁盘。
- Memcached 的数据始终在内存中,它通过预分配特定长度的内存块来存储数据,以解决内存碎片,但可能导致内存利用率不高(例如128 bytes块只存100 bytes数据,造成浪费)。
Redis 有哪些数据类型?
String(字符串)
List(列表)
Hash(字典)
Set(集合)
ZSet(有序集合)
高级用法:
- BitMap(位图):支持按 bit 位存储信息,可用于实现布隆过滤器 (BloomFilter)。
- HyperLogLog:提供不精确的去重计数,适合大规模数据的去重统计,如统计 UV(独立访客)。
- Geospatial:用于保存地理位置,进行距离计算或根据半径计算位置,可实现“附近的人”、最优路径规划等功能。
什么是 Redis 持久化?
持久化是指将内存中的数据写入磁盘,以防止服务宕机导致内存数据丢失。
Redis 的持久化机制
Redis 提供两种持久化机制:RDB(默认)和 AOF。
RDB(Redis DataBase)
RDB 是 Redis 默认的持久化方式。按照一定的时间周期,将内存的数据以快照形式保存到磁盘,生成 dump.rdb 数据文件。快照周期可通过配置文件中的 save 参数定义。
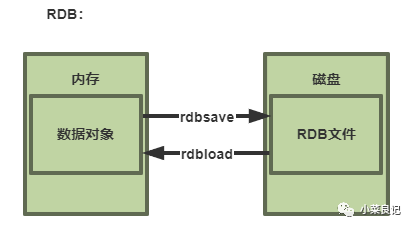
原理:基于 fork 和 cow(Copy-On-Write)。Redis 会定期 fork 出一个子进程,子进程将数据写入一个临时 RDB 文件,写入完成后替换旧的 RDB 文件。这种方式利用了操作系统的写时复制技术。
优点:
- 方便持久化:只有一个文件
dump.rdb,易于管理。
- 容灾性好:单个文件便于备份到安全磁盘。
- 性能最大化:由子进程负责持久化 I/O 操作,主进程继续处理命令,保证 Redis 高性能。
缺点:
- 数据安全性低:两次快照之间的数据可能丢失,更适合对数据一致性要求不高的场景。
- 保存耗时长:如果数据量很大,生成快照的时间会比较长。
AOF(Append-Only-File)
AOF 会将 Redis 执行的每个写命令记录到独立的日志文件中。重启时,Redis 会重新执行 AOF 文件中的命令来恢复数据。

原理:将写命令追加到 AOF 文件末尾。需要通过配置同步选项 (appendfsync) 来控制命令同步到磁盘的时机。
同步选项:
| 选项 |
同步频率 |
| no |
由操作系统决定何时同步 |
| always |
每个写命令都同步 |
| everysec |
每秒同步一次 |
- no:不能显著提升性能,且系统崩溃时数据丢失较多。
- always:数据安全性最高,但会严重降低服务器性能。
- everysec:推荐选项。在保证系统崩溃时最多丢失一秒数据的前提下,对服务器性能影响微乎其微。
随着写操作增多,AOF 文件会膨胀。Redis 提供了 AOF 重写(auto-aof-rewrite) 机制,能够去除文件中的冗余命令。
优点:
- 数据安全:可配置为
always,每次写操作都立即记录。
- 一致性:采用追加写模式,即使服务器中途宕机,也可通过
redis-check-aof 工具修复数据一致性问题。
缺点:
- AOF 文件通常比 RDB 文件大,恢复速度更慢。
- 数据集较大时,启动效率低于 RDB。
RDB 与 AOF 比较
- AOF 文件更新频率高于 RDB,数据恢复时优先使用 AOF。
- AOF 通常比 RDB 更安全、功能更强大(例如记录了所有写操作)。
- RDB 在恢复大数据集时性能优于 AOF。
- 如果同时配置了两种方式,Redis 重启时优先加载 AOF 文件恢复数据。
如何选择合适的持久化方式?
建议两者都配置,形成互补。单独使用 RDB 可能导致较多数据丢失;单独使用 AOF,数据恢复速度不如 RDB 快。实践中,可以先利用 RDB 快速恢复数据主体,再通过 AOF 补全增量数据。这种“冷热备份”结合的方式,能构建健壮性更高的系统。
Redis 的过期键删除策略
- 定时删除:为每个设置过期时间的 key 创建定时器,到期立即删除。对内存友好,但消耗大量 CPU 资源,影响缓存性能。
- 惰性删除:只有当访问一个 key 时,才判断其是否过期,过期则删除。最大化节省 CPU,但对内存不友好,可能导致大量过期 key 未被及时清理。
- 定期删除:每隔一段时间,扫描一定数量的过期字典中的 key 并清除已过期的。是前两种策略的折中,可通过调整扫描间隔和耗时来平衡 CPU 和内存资源。
Redis 通常同时使用 惰性删除 和 定期删除 两种策略。
Redis 内存淘汰策略
当内存不足时,Redis 会根据配置的策略淘汰部分数据。
针对设置了过期时间的 key:
volatile-lru:尝试回收最少使用的键。volatile-random:随机回收键。volatile-ttl:优先回收存活时间较短的键。
针对所有 key:
allkeys-lru:尝试回收最少使用的键。allkeys-random:随机回收键。noeviction:禁止淘汰数据,当内存不足时,新写入操作会返回错误。
Redis 事务
Redis 事务本质是通过 MULTI、EXEC、WATCH、DISCARD 四个原语实现。它支持一次执行多个命令,所有命令会被序列化并顺序执行,且在执行过程中不会被其他客户端命令打断。
特点:
- Redis 不支持回滚:事务中某个命令失败,其余命令仍会继续执行,这是为了保持 Redis 的简单与高效。
- 如果命令入队时出错(如语法错误),所有命令都不会执行。
- 如果命令执行时出错(如对错误类型键操作),正确的命令会被执行。
四个原语:
- WATCH:乐观锁,监控一个或多个键。如果在 EXEC 执行前被修改,则事务不会执行。
- MULTI:开启一个事务,将后续命令放入队列。
- EXEC:执行事务队列中的所有命令。
- DISCARD:清空事务队列,并放弃执行事务。
如何设置键的过期时间和永久有效?
使用 EXPIRE key seconds 设置过期时间,使用 PERSIST key 移除过期时间,使其永久有效。
缓存雪崩
定义:缓存中大量数据在同一时间点失效,导致所有请求直接涌向数据库,造成数据库瞬时压力过大而崩溃。
解决方案:
- 将缓存数据的过期时间设置为随机值,避免同时失效。
- 对于并发量不大的场景,可采用加锁排队的方式控制数据库访问。
- 搭建 Redis 集群,实现高可用,避免单点故障。
缓存击穿
定义:某个热点 key 在缓存中过期(但数据库中仍有数据),此时有大量并发请求同时访问这个 key,全部穿透到数据库,造成数据库压力骤增。
解决方案:
- 设置热点数据永不过期。
- 使用互斥锁(如 Redis 分布式锁),保证同一时间只有一个请求去数据库加载数据。
- 采用随机退避策略,缓存失效时随机等待很短时间再重试查询或更新。
缓存穿透
定义:查询一个缓存和数据库中都不存在的数据。导致每次请求都会落到数据库上,可能压垮数据库。
解决方案:
- 缓存空对象:对于查询不存在的数据,在缓存中保存一个空值(或特殊标记)并设置较短过期时间,防止重复查询数据库。
- 使用布隆过滤器 (BloomFilter):在查询缓存前,先经过布隆过滤器判断数据是否存在。如果过滤器判断不存在,则数据一定不存在,直接返回;如果判断存在,则数据可能存在(有误判率),再去查询缓存和数据库。
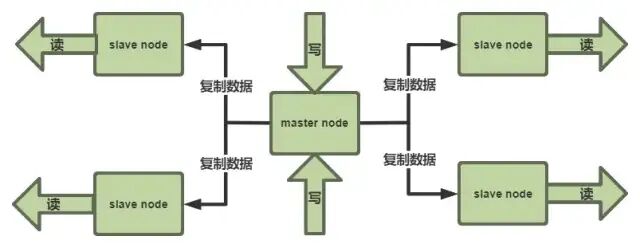
Redis 主从架构
单机 Redis 的 QPS 承载能力有限。为了支撑读高并发,通常采用主从架构(Master-Slave)。Master 节点处理写操作,并将数据同步到多个 Slave 节点,Slave 节点专门负责读操作。这样不仅分摊了读请求压力,也便于水平扩容。
首次全量同步流程:
- Slave 启动后,向 Master 发送
PSYNC 命令请求同步。
- Master 执行
BGSAVE 生成当前数据的 RDB 快照文件,同时将后续的写命令缓冲在内存中。
- RDB 文件生成后,Master 将其发送给 Slave。
- Slave 接收并加载 RDB 文件到内存,完成数据初始化。
- Master 再将缓冲区的写命令(增量数据)发送给 Slave 进行重放,最终实现主从数据一致。
后续的增量数据同步则通过类似于数据库 binlog 的 AOF 日志流进行。
Redis 实现分布式锁
一个简单的实现方式是:使用 SETNX (SET if Not eXists) 命令争抢锁,抢到后再用 EXPIRE 命令为锁设置一个过期时间,防止持有者意外崩溃导致锁无法释放。
SETNX key value:仅当 key 不存在时,将其值设为 value。设置成功返回 1,失败(key已存在)返回 0。
Redis 的同步机制
Redis 支持主从同步和从从同步(级联复制)。其同步机制与上述主从架构中的首次全量同步流程一致,核心是 RDB 快照 + 增量命令缓冲与重放。
Redis 集群原理
Redis 提供了两种集群方案,着眼点不同:
- Redis Sentinel(哨兵):着眼于高可用。当 Master 宕机时,能自动将某个 Slave 提升为新的 Master,继续提供服务。
- Redis Cluster:着眼于扩展性。当单个 Redis 实例内存不足时,通过分片(Sharding)将数据分布到多个节点存储。
Sentinel 选主策略(当原 Master 故障时):
- Slave 优先级(
slave-priority)越低,优先级越高。
- 优先级相同时,复制偏移量(数据同步程度)越大的 Slave 优先级越高。
- 以上都相同时,ID (
runid) 越小的 Slave 越容易被选中。
Redis 哨兵模式
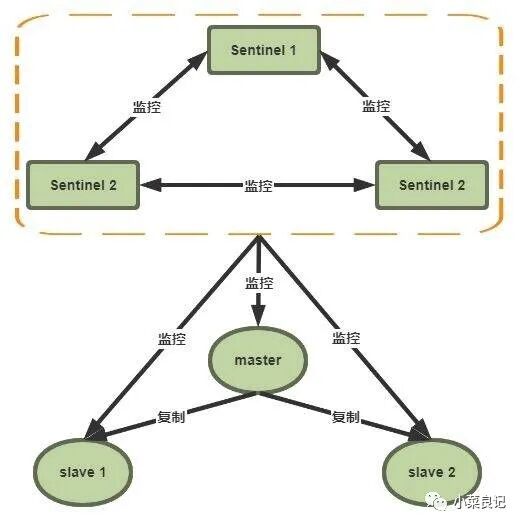
哨兵模式通常需要至少三个 Sentinel 实例来保证自身的健壮性。需要注意的是,哨兵+主从复制 并不能保证数据零丢失,但可以保证集群的高可用性。
工作原理:
- 每个 Sentinel 每秒向所有已知的主、从服务器和其他 Sentinel 发送 PING 命令。
- 如果一个实例在配置的
down-after-milliseconds 时间内未有效回复 PING,则被该 Sentinel 标记为主观下线。
- 如果一个 Master 被标记为主观下线,所有监视它的 Sentinel 会以每秒一次的频率确认其状态。
- 当有足够数量(达到配置的法定人数)的 Sentinel 在指定时间范围内都认为该 Master 下线,则将其标记为客观下线。
- Sentinel 集群会通过投票协议,从该 Master 的 Slaves 中选举出一个新的 Master。
- 将其余 Slaves 指向新的 Master 开始复制数据。
- 通知客户端主从切换的结果。
脑裂问题及解决
何为脑裂?
在 Redis 主从集群中,由于网络分区(Network Partition),导致 Master 节点与其 Slaves 节点以及 Sentinel 集群被隔离在不同的网络区域。Sentinel 集群因无法感知到原 Master 的存在,从而将某个 Slave 提升为新的 Master。此时集群中出现了两个“Master”。如果客户端仍基于原 Master 写入数据,则新 Master 无法同步这些数据。当网络恢复后,原 Master 会被 Sentinel 降级为 Slave 并向新 Master 同步数据,这将导致原 Master 上未被同步的数据永久丢失。
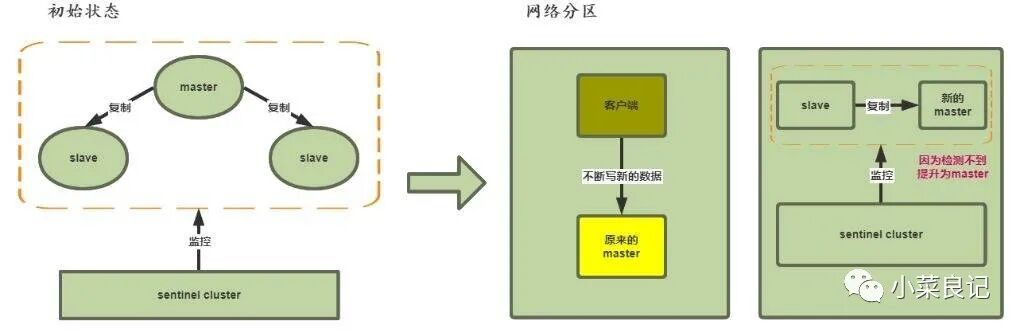
解决方案:
理解了这些核心原理,无论是进行高可用架构设计,还是准备技术面试,都能更有把握。当然,纸上得来终觉浅,最好的学习方式还是在实践中不断探索和验证。
 发表于 2026-4-4 06:55:13
|
查看: 139|
回复: 0
发表于 2026-4-4 06:55:13
|
查看: 139|
回复: 0
