一、理解RPC:从故事开始
张三和李四在同一家公司负责商品交易模块,平日里配合默契。
🙋🏻♂️ 张三:“李四,我这边一个商品下单了,但是付款数额不对,你帮我查下支付有没有问题”
🙋🏻 李四:“张三,支付这边检验价格的时候有点问题,实付金额和预付金额对不上”
过去,他们工位相邻,遇到问题张口就问。但随着业务增长,系统被拆分成不同的子模块,分布式系统的概念开始流行。系统“拆分”计划启动,张三负责订单模块,李四负责交易模块,两人的工位也因此分开了。这时他们意识到,无法再像从前那样即呼即应了。
那么,沟通问题如何解决呢?李四人搬走了,但联系方式还在。张三需要协助时,依然可以打电话给李四。虽然电话沟通略显间接,但解决问题的能力得以保留,只是沟通形式变了。
通过这个小故事,我们可以提炼出几个核心概念:
- 张三李四可以直接交谈。(直接调用)
- 拆分模块(分布式系统)
- 联系方式(接口定位)
- 利用电话沟通(远程通信)
- 打电话的过程(过程调用)
而这几个概念,恰恰构成了 RPC 的核心思想。
二、RPC 概要
RPC (Remote Procedure Call) 是一种用于实现远程通信和分布式计算的协议。它允许在不同的计算机或进程之间进行通信,使得这些计算机或进程能够像调用本地函数一样调用位于远程计算机或进程上的函数或方法。
RPC 协议的基本原理是客户端调用远程服务器上的函数,并将函数参数传递给服务器。 服务器执行相应的函数逻辑,并将结果返回给客户端。从客户端的角度来看,RPC 调用就像是调用本地函数一样,而不需要关心远程函数的实现和通信细节。 简而言之,它让一台机器上的程序能够调用另一台机器上的子程序,而无需感知其远程性。
三、RPC vs HTTP
1、历史渊源:谁先谁后?
RPC 是一个较早的抽象概念,其思想在1970年代早期就已出现,并在1980年代有了重要的里程碑式实现。它代表了一种通用理念:从一个计算机进程中调用另一个进程的函数或过程,无论这两个进程是否在同一台机器上。
HTTP 协议则首次出现在1991年,由蒂姆·伯纳斯-李在万维网(WWW)项目中开发。因此,从时间线上看,RPC 是早于 HTTP 出现的。
2、既生 RPC 何生 HTTP?
既然有了 RPC,理论上可以通过各种协议进行方法调用,为何还需要 HTTP 呢?因为 HTTP 为万维网提供了一个标准化、广泛支持的信息交换方式。它不止于方法调用,还涵盖了数据的获取、提交、更新和删除等更广泛的操作。
举个例子,A 公司内部开发了一套数据管理系统,可以使用 RPC 协议进行高效的方法调用。但当 B 公司想要集成 A 公司的能力时,通过私有的方法调用方式就不大合适了,此时就需要利用万维网上更标准的 HTTP 协议来进行通信。
核心区别
RPC 与 REST(一种基于 HTTP 的架构风格)最大的区别在于抽象层级。RPC 提供了更好的抽象,甚至完全隐藏了网络传输细节;而 REST 至少要求开发者知晓 URL 和请求参数。另一方面,RPC 可以基于任何网络通信协议实现,而 REST 通常基于 HTTP/HTTPS 协议。
主要区别体现在三个方面:
- 设计目标
- RPC 协议更侧重于方法的调用和参数传递,旨在让客户端像调用本地函数一样调用远程函数,常用于构建分布式系统、微服务架构等场景。
- HTTP 协议是一种通用的应用层协议,提供标准的请求-响应语义,支持网页浏览、资源访问、API 调用等多种场景。
- 传输协议
- RPC 协议可以基于多种传输协议实现,如 TCP、UDP、HTTP 等,并常使用自定义的协议栈和编码方式。
- HTTP 协议基于 TCP/IP,使用统一格式(请求行、请求头、请求体)和常见编码(如 JSON、XML)。
- 通信模型
- RPC 协议是一种点对点的通信模型,客户端和服务器之间通常建立直接的连接进行调用。
- HTTP 协议是客户端-服务器模型,遵循“请求-响应”模式,传统上每次请求都可能涉及新连接的建立(现代 HTTP/2、HTTP/3 已有改进)。
3、性能比较
在性能方面,HTTP 和 RPC 协议存在一些差异,主要由以下因素决定:
- 通信开销
- HTTP 通常使用文本格式(JSON、XML),相对冗长,每次请求/响应都包含大量头部信息。
- RPC 通常使用二进制序列化格式(如 Protobuf、Thrift),更为紧凑,专注于方法调用,减少了不必要的开销。
- 连接复用
- 传统 HTTP/1.1 默认使用短连接(虽然可启用 Keep-Alive),频繁请求仍有连接开销。
- RPC 协议通常支持长连接,一个连接上可进行多次方法调用,减少了连接建立和关闭的开销。
- 序列化和反序列化
- HTTP 使用通用文本格式,序列化/反序列化(编码/解码)可能消耗更多时间和资源。
- RPC 使用高效的二进制序列化格式,转换开销更小。
总体而言,由于设计目标更专注,RPC 协议在性能方面通常优于 HTTP 协议,尤其在微服务等高频内部调用场景下。但具体差异仍需结合实际场景进行评估和测试。
四、RPC 如何工作
1、核心概念
- 客户端(Client): 发起远程函数调用的一方。负责将本地调用转化为网络请求,并将网络响应转化回本地结果。
- 客户端存根(Client Stub): 负责将函数调用及其参数编码、序列化后通过网络发送请求。
- 网络模块(Network): 传输远程调用信息的媒介,可以是 TCP/IP、HTTP 或其他网络协议。
- 服务端骨架(Server Skeleton): 与客户端存根对应,负责将接收到的请求解包、反序列化后调用实际服务,并将结果重新包装发送回客户端。
- 服务端(Server): 提供远程过程实际执行的地方,即实现了具体业务逻辑的服务。
2、通信流程
理解了以上五大核心概念后,我们可以通过一张时序图将它们串联起来:
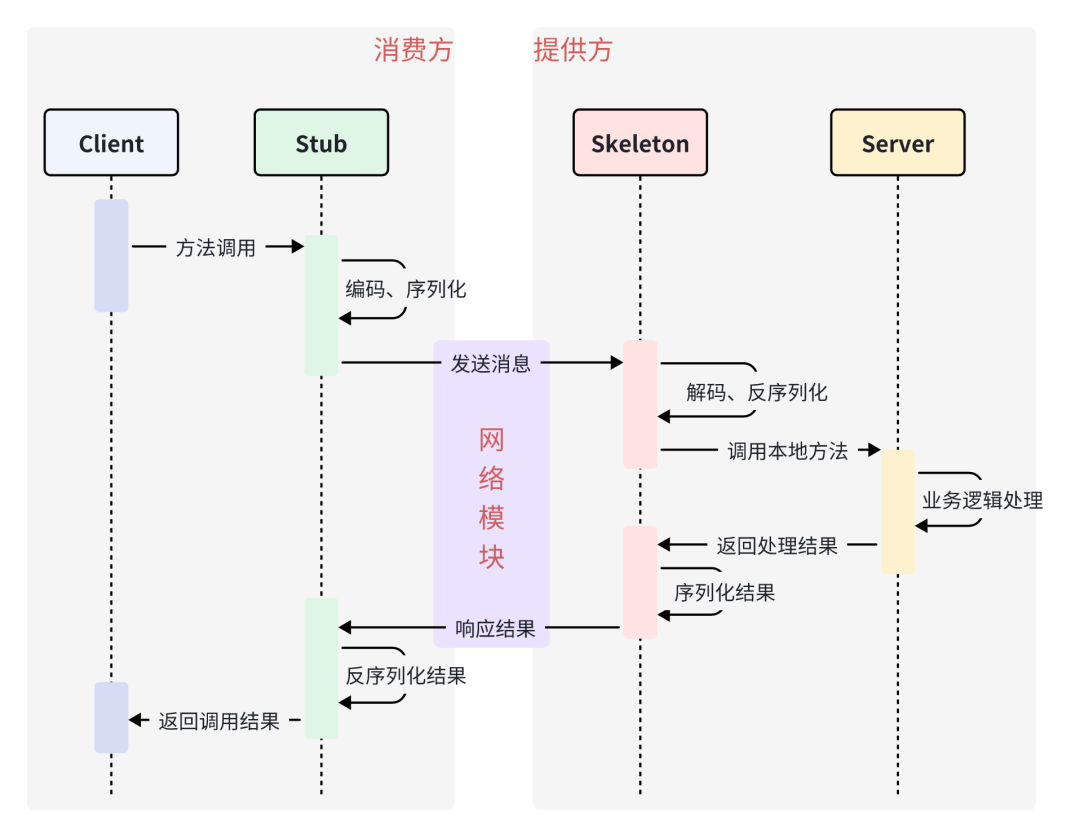
具体流程如下:
- Client 客户端 以调用本地服务的方式发起调用。
- Client Stub 存根 接收请求,将方法、入参等信息序列化成可传输的消息体。
- Client Stub 存根 找到远程服务地址,将消息通过网络发送给服务端。
- Server Stub 服务端骨架 收到消息后进行解码(反序列化)。
- Server Stub 服务端骨架 根据解码结果调用本地的服务。
- Server 服务端 执行具体业务逻辑,并将结果返回给 Server Stub。
- Server Stub 服务端骨架 将返回结果重新打包(序列化)并通过网络发送至客户端。
- Client Stub 存根 接收到消息,并进行解码(反序列化)。
- Client Stub 存根 将解码后的结果返回给 Client 客户端。
3、实现架构
理解了通信流程,我们就可以进一步思考如何实现一个 RPC 框架了。其中 Client 和 Server 是关键角色。为了实现客户端对远程调用的无感知(即感觉像调用本地方法),我们需要引入 Proxy(代理) 机制。代理拦截调用后,需要将数据序列化并发送,这就离不开 Serializer(序列化)模块。序列化后的数据需要通过网络传输,因此 Network(网络)模块 必不可少。而在传输之前,我们必须知道远程服务的地址,于是 Registry(注册中心) 就登场了。
五大模块
简单梳理后,我们得到 RPC 框架的五大核心模块:
- 客户端(Client): 发起远程调用请求。
- 序列化模块(Serializer): 负责数据的序列化和反序列化。
- 网络模块(Network): 用于传输远程调用信息。
- 注册中心(Registry): 负责服务的注册与发现。
- 服务端(Server): 提供远程服务的实际执行环境。
技术选型分析
聊完理论谈实践,为了实现以上模块的协同工作,我们需要用到以下关键技术:
1)动态代理
生成 Client Stub 和 Server Stub 是实现远程调用的关键,这通常借助动态代理技术完成。在 Java 生态中,我们有多种选择:
- JDK 动态代理: 基于
java.lang.reflect.Proxy 和 InvocationHandler,适用于代理接口。
- CGLib: 通过继承方式在运行时生成类的子类,无需接口即可实现代理。
- Javassist: 提供直接操作字节码的能力,可以在不改变原有类结构的情况下修改类行为。
2)序列化
序列化(编码)与反序列化(解码)是数据处理的核心环节,其效率直接影响分布式系统的性能。选择序列化框架时,需权衡效率、灵活性和生态。以下是几个高效的开源选择:
- Kryo: 小巧快速,常用于游戏和高性能计算场景。
- FastJson: 以速度快、使用简单著称,擅长处理 JSON 格式。
- Protobuf: 由 Google 开发,采用二进制格式,高效且跨平台,具有良好的向前/向后兼容性。
3)网络通信
为了应对高并发,传统的同步阻塞IO(BIO)模型不再适用。非阻塞IO(NIO)模型允许线程在等待IO时处理其他任务,能显著提升资源利用率和系统吞吐量。构建高并发网络应用时,可以选择:
- Netty: 应用广泛的高性能框架,API 简单,性能稳定。
- Apache MINA: 另一个易于使用和扩展的异步IO框架。
4)注册中心
服务注册与发现是分布式系统的核心。市面上有多个成熟的注册中心方案,例如 Redis、ZooKeeper、Consul 等。选择时需综合考虑数据一致性、可用性、可扩展性以及与现有系统的兼容性。ZooKeeper 以其强一致性在服务发现场景中应用广泛,能有效避免单点故障。
4、常见 RPC 框架
了解了原理和实现技术后,我们来看看几个流行的开源 RPC 框架,它们封装了上述大部分复杂性:
-
gRPC
- 由 Google 开发的开源框架。
- 使用 HTTP/2 作为传输协议,以 Protocol Buffers 作为接口定义语言。
- 支持多种编程语言,适用于构建跨语言服务。
-
Apache Thrift
- 最初由 Facebook 开发,后贡献给 Apache。
- 支持多种语言,允许通过统一的接口描述语言(IDL)定义数据类型和服务接口。
- 框架会生成不同语言的服务端和客户端代码。
-
Apache Dubbo
- 高性能的 Java RPC 框架。
- 用于构建大规模分布式系统,支持多种通信协议。
- 提供了丰富的服务治理和动态配置功能。
五、总结
本文从一个小故事出发,逐步深入探究了 RPC 的核心概念、工作原理、实现架构以及主流框架。RPC 的魅力在于它让跨网络的服务调用变得透明而简单,这背后体现了分布式系统设计中模块化、服务解耦和可伸缩性的重要思想。随着微服务架构的普及,RPC 技术也在不断演进,以满足更复杂的网络模式和更高的性能要求。无论你是刚接触分布式系统的新手,还是经验丰富的开发者,理解 RPC 都是构建现代后端服务不可或缺的一环。
希望这篇从理论到实践的解析,能帮助你更好地掌握 RPC 技术。如果你想深入探讨更多分布式系统或后端架构的话题,欢迎在 云栈社区 与更多开发者交流学习。
 发表于 2026-4-4 07:00:00
|
查看: 98|
回复: 0
发表于 2026-4-4 07:00:00
|
查看: 98|
回复: 0
