刚刚发布的 Gemma 4 端侧安装全流程体验,不仅推理速度比之前快 3 倍,还原生支持多模态(图像、音频输入)和思考模式。对于想在手机上尝鲜大模型的开发者来说,感觉就像是为老设备量身定制的一样。
今天就来分享 Gemma 4 家族中最为轻量的 E2B 模型在安卓手机上的全流程安装过程。考虑到许多手机不支持 Google 框架,无法直接使用 AICore 预览版,因此我们选择 Termux + llama.cpp 的技术路线来实现。
准备工作
首先,请确认你的手机里没有需要保留的重要资料!因为整个过程涉及系统级操作,存在一定风险。
由于在手机上直接输入命令非常不便,所以第一步是将手机与电脑打通。核心是建立 SSH 连接,以便在电脑上远程操作手机。
第一步:在手机端安装并设置 OpenSSH
在 Termux 应用中执行以下命令:
# 更新并安装 openssh
pkg upgrade
pkg install openssh
# 开启 SSH 服务
sshd
# 查看你的 Termux 用户名
whoami
# 设置登录密码(非常重要,否则无法连接)
passwd
需要输入两次密码,直接输完按回车即可。
第二步:在电脑端连接手机
打开电脑上的 PowerShell(或终端),输入连接命令:
# 格式:ssh [用户名]@[IP地址] -p 8022
ssh 用户名@192.168.*.* -p 8022
例如,我的连接命令是:ssh u0_a333@192.168.0.88 -p 8022
注意事项:
- 首次连接:手机会提示
The authenticity of host... can't be established. Are you sure you want to continue?,此时直接输入 Yes。
- 然后输入你刚才在手机上通过
passwd 设置的密码。
连接成功后,你就能在电脑上远程控制手机的 Termux 终端了,这为后续复杂的命令行操作扫清了障碍。
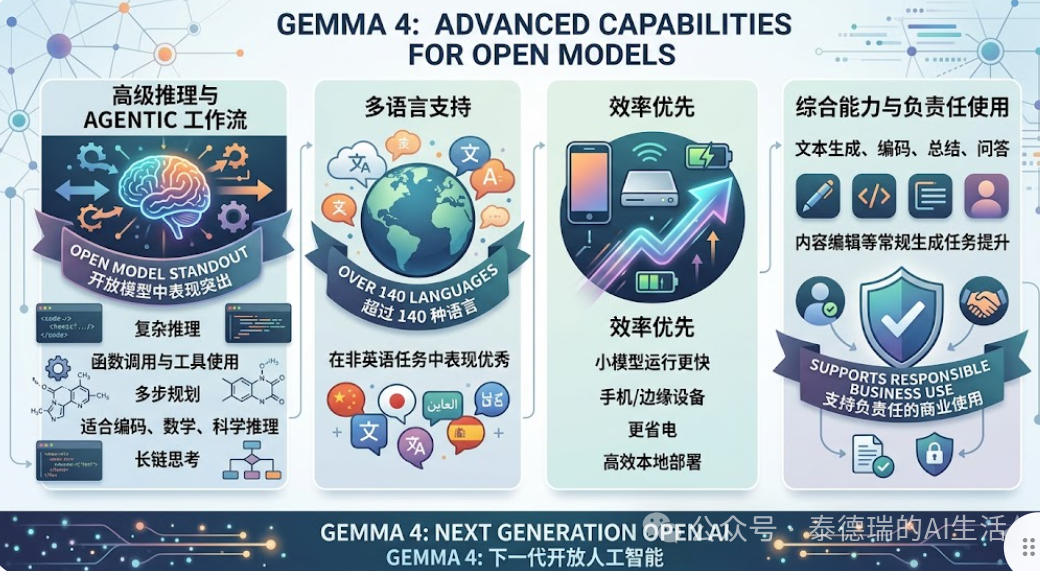
在正式开工前,先来了解一下今天的主角。Gemma 4 E2B 是 Google 推出的轻量级开放模型,专为边缘设备设计,具有多模态和原生思考能力。
启动前的最后确认
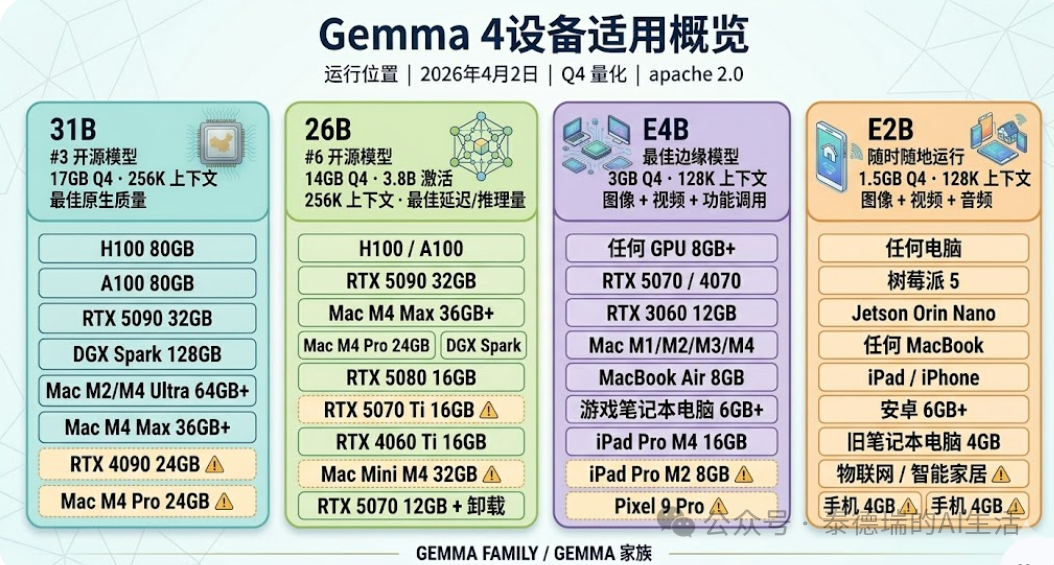
- 再次检查硬件和模型:Gemma 4 E2B 的 4-bit 量化版本(GGUF)大约占用 1.5GB - 2GB 内存。请确认你的手机可用内存情况,如果大于 6GB,则可以顺利进行;配置较好的设备甚至可以尝试 Q8_0(8-bit)量化以获得更高精度。
Termux 部署全流程
(如果尚未安装 Termux,请先自行搜索安装方法)
第一步:环境初始化
在已建立 SSH 连接的电脑终端(或手机 Termux)中,执行以下命令安装必要的编译工具:
apt update && apt upgrade -y
pkg install clang cmake git ninja wget -y
第二步:编译最新版 llama.cpp
由于 Gemma 4 采用了新的架构和特殊的 <|think|> Token 逻辑,必须使用支持该特性的最新版 llama.cpp 源码:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
mkdir build && cd build
cmake .. -G Ninja
ninja
第三步:获取 Gemma 4 E2B 模型文件
直接从 Hugging Face 下载可能会因网络问题失败。建议通过 hf-mirror.com 等镜像站下载,注意选择 gemma-4-e2b-it-Q4_K_M.gguf 这个文件。
假设你已经在电脑的 E 盘下载好了模型文件,接下来需要通过局域网将其推送到手机。
- 在电脑上新开一个 PowerShell 窗口(保持本地状态,不要 SSH 连接到手机)。
- 切换到模型文件所在的目录,例如:
# 切换到 E 盘
E:
# 进入文件所在文件夹
# cd \你的文件夹名
- 执行 SCP 命令传输文件:
# 使用 scp 命令传输,注意端口是 8022
scp -P 8022 ./gemma-4-e2b-it-Q4_K_M.gguf u0_a348@192.168.0.43:~/llama.cpp/models/
- 输入密码:按提示输入之前为 Termux 设置的密码。
- 等待传输:可以看到从 0% 到 100% 的传输进度条。
温馨提示:因为 Gemma 4 E2B 支持图片输入。如果想测试识图功能,可以额外下载一个多模态适配器 (mmproj) 文件。这一步可以先跳过,后续再补充:
aria2c -s 16 -x 16 "https://hf-mirror.com/ggml-org/gemma-4-E2B-it-GGUF/resolve/main/mmproj-gemma-4-e2b-it-f16.gguf" -o mmproj-gemma-4-e2b.gguf
第四步:检查与修复文件路径
传输完成后,最好确认一下文件是否在正确的位置。在 SSH 到手机的终端里执行:
find ~ -name “gemma-4-e2b-it-Q4_K_M.gguf”
如果命令输出了路径但不在 ~/llama.cpp/models/ 下,说明文件放错了位置。假设文件在 ~/llama_models_backup/ 目录下,可以将其移动到正确位置:
# 创建目标目录(确保存在)
mkdir -p ~/llama.cpp/models
# 移动文件
mv ~/llama_models_backup/gemma-4-e2b-it-Q4_K_M.gguf ~/llama.cpp/models/
最后,确认文件已就位:
ls -lh ~/llama.cpp/models/gemma-4-e2b-it-Q4_K_M.gguf
第五步:针对手机进行启动优化
考虑到手机芯片的性能调度,可以调整运行线程数。例如,对于常见的 4+4 或 2+2+4 架构芯片,建议开启 4 或 6 个线程。进入编译目录进行测试运行:
cd ~/llama.cpp/build
./llama-cli -m ../models/gemma-4-e2b-it-Q4_K_M.gguf \
-p “You are a helpful assistant with thinking capabilities.” \
-n 512 \
-t 6 \
--color \
--interactive \
--conversation \
--special \
-cnv \
--temp 1.0 \
--top-p 0.95
第六步:创建一键启动脚本
为了日后运行方便,可以创建一个启动脚本。首先确保安装了 nano 编辑器:
pkg install nano -y
然后创建并编辑脚本文件:
nano ~/run_gemma.sh
在 nano 编辑器中,粘贴以下内容(注意参数已优化):
#!/bin/bash
# 进入程序目录
cd ~/llama.cpp/build
# 启动命令
./llama-cli -m ../models/gemma-4-e2b-it-Q4_K_M.gguf \
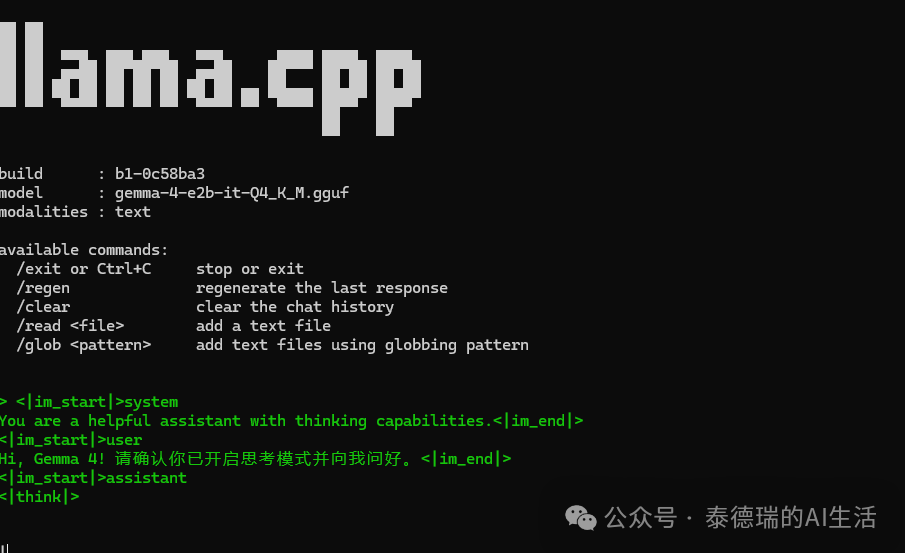
-p “<|im_start|>system
You are a helpful assistant with thinking capabilities.<|im_end|>
<|im_start|>user
Hi, Gemma 4! 请确认你已开启思考模式并向我问好。<|im_end|>
<|im_start|>assistant
<|think|>
” \
-n 512 \
-t 6 \
--color on \
-cnv \
--special \
--temp 0.8
按 CTRL+O 保存,回车确认,再按 CTRL+X 退出编辑器。
最后,给脚本添加执行权限:
chmod +x ~/run_gemma.sh
运行与测试
至此,所有安装和配置工作已完成。现在,只需运行我们创建好的脚本:
~/run_gemma.sh
如果一切顺利,你将看到终端启动并加载模型,随后 Gemma 4 会进行自我介绍并等待你的指令。
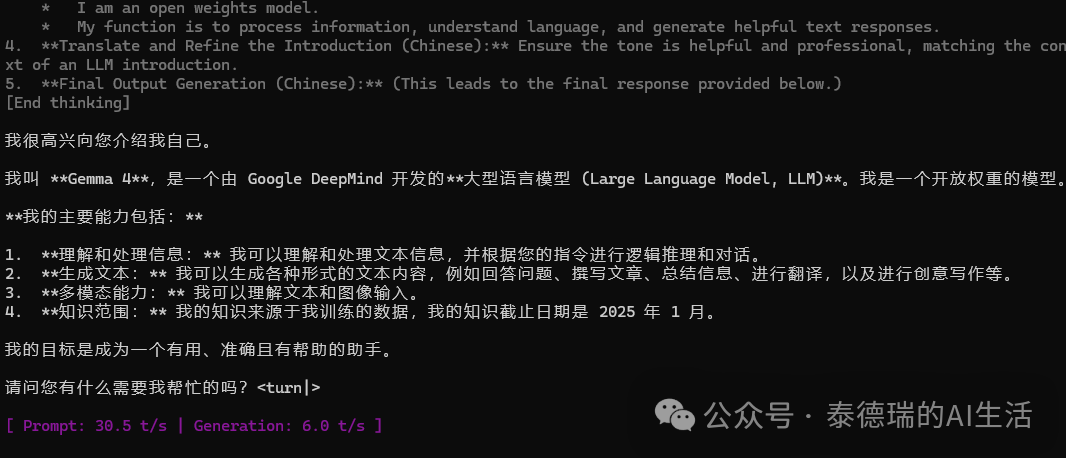

在我的旧款手机上,推理速度能达到约 30 token/s,这个表现相当令人意外!
温馨提示与避坑指南
成功运行后,有几点需要特别注意:
- 温控与降频:手机芯片在高负载下发热很快,可能导致性能下降。建议运行时取下手机壳,保持良好散热。
- 存储路径:请务必将模型文件放在 Termux 的私有目录下(即
~/ 路径下)。如果放在 /sdcard/ 等外部存储,可能会因文件权限或速度问题导致读取异常缓慢。
- 功能支持:Gemma 4 E2B 虽然支持音频输入,但目前
llama.cpp 在移动端的实现主要集中于文本和图像模态。实时音频对话功能可能需要等待社区后续更新。
进阶玩法:开启“思考模式”
如果你习惯像使用 DeepSeek 那样看到模型的思考过程,那么 Gemma 4 原生的思考逻辑可见功能将是最大的亮点。
你可以在对话中直接引导模型进入思考模式。例如,输入:
<|think|> 请帮我分析这段 Python 代码的内存泄漏风险...
你会看到模型在输出最终答案前,先生成一段详细的内部推理过程,就像思维链被可视化了一样。这非常有助于理解模型的“解题思路”。
结语
以上就是通过 llama.cpp 在安卓手机上部署运行轻量级 Gemma 4 E2B 开源模型的全流程。这个方案绕过了对特定厂商框架的依赖,让更多普通手机也能体验最新大模型的能力。
整个流程从环境搭建、模型获取、优化配置到最终运行,涵盖了主要的操作步骤和可能遇到的坑。动手实践是学习 AI 部署最好的方式,希望这篇教程能帮你成功在手机上跑起第一个“思考中”的模型。如果你在 开源实战 中遇到问题,或者有更好的优化技巧,欢迎来 云栈社区 与其他开发者交流分享你的经验和成果。
 发表于 2026-4-4 10:16:10
|
查看: 312|
回复: 0
发表于 2026-4-4 10:16:10
|
查看: 312|
回复: 0
