愚人节当天,一家起源于加州理工学院(Caltech)的AI实验室PrismML发布了他们的首个大模型Bonsai。通过一个概念验证(proof of concept),它仅需约1.5GB内存就能在闲置的M1 Mac上运行一个8B参数的本地模型。
今天,我们不深入分析其底层理论和复杂参数,也不先讨论其核心卖点——极致的1-bit模型压缩、开源特性以及边缘智能。让我们先从一张图来直观了解它:
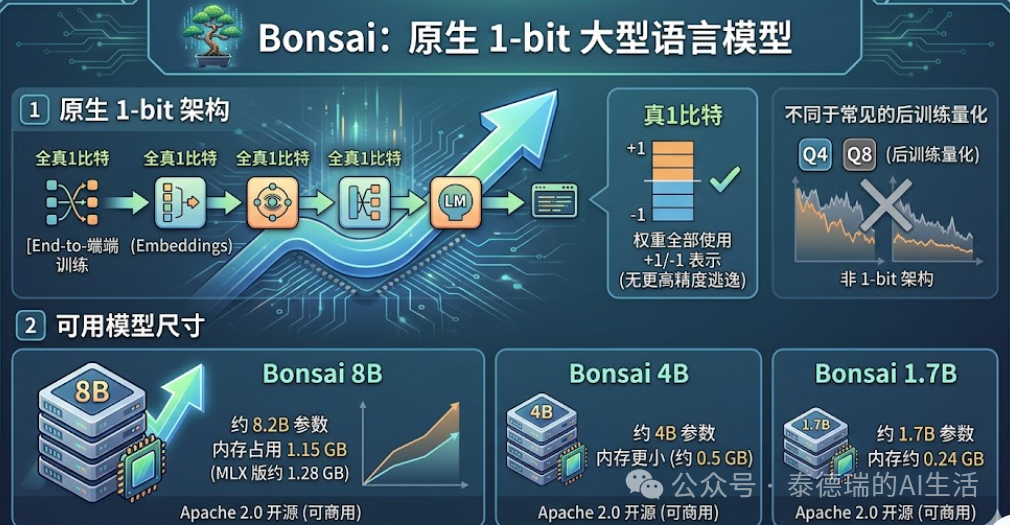
我们将重点探讨一个与过去“越大越强”的主流趋势截然不同的方向:这股由Bonsai刮起的“模型减肥”风潮,可能会给整个行业带来怎样的影响和机遇。最后,我们会分享一些当前的实测数据。
01 边缘计算与端侧AI的进程可能被加速
Bonsai最显著的特点是,它首次将通常需要高端GPU或云服务的8B大模型,压缩到仅需 1.15GB内存,从而让许多老旧设备重获新生(例如M1 MacBook和iPhone)。

这可能导致的影响包括:
- 手机和笔记本上实现真正本地运行的高性能LLM:在发布后不久,已有社区演示了Bonsai 8B在iPhone 17 Pro上跑出了高达 40+ tokens/s 的离线推理速度。
- AI产品创新的窗口可能再次打开:例如本地智能体(Agent)、实时机器人、离线智能助手以及注重隐私的企业应用,都可能迎来更多的实际用例。
- 降低对云端的依赖:由于本地部署的门槛大幅降低,现有商业模式中对云端算力的重度依赖可能被削弱。
02 基础设施的效能可能大幅提升
必须承认,Bonsai通过其1-bit权重技术,显著降低了内存带宽需求和计算开销。它用 不足其他同类模型10%的内存 运行8B模型,这充分展示了改变传统“以功耗换算力”逻辑的可能性。
- 降低能耗与成本:对内存依赖的减少,有助于缓解数据中心的能耗瓶颈,从而降低推理成本,使得大规模部署变得更加经济。
- 催生专用硬件:已有分析指出,这不只是一次增量改进,而是对系统优化方程的重构,未来甚至可能催生新一代专为低精度计算优化的AI硬件。
03 技术路线与范式转移或将到来
Bonsai延续并商业化了微软BitNet(b1.58)等早期的1-bit研究,实现了非量化的、端到端的原生1-bit训练,并直接开源,从而树立了 “第一个商业可行”的里程碑。
- 验证了可行性:它成功证明了“从头开始训练1-bit模型完全可行,并且其性能能够与全精度8B模型竞争”。
- 奠定软硬协同基础:为激发硬件-软件的协同设计打下了基础,未来可能出现专门为1-bit优化设计的CPU、GPU、LPU或NPU。
- 强化“智能密度”理念:从实用角度强化了 “智能密度” 这一概念。未来的行业竞争可能不再只是比拼“谁的参数更多”,而是比较“每GB内存或每瓦功耗能产出多少有用的智能”。

04 开发者生态与应用创新可能被重塑
Bonsai团队以直接开源模型、提供演示仓库、并支持MLX/llama.cpp等流行框架作为开局,使得开发者能够立即在普通硬件上体验和调试。这可能带来以下效果:
- 大幅降低本地LLM部署门槛:个人开发者、中小型企业以及对隐私和合规性要求严格的场景,使用本地大模型的比率有望大幅提升。
- 激活新的AI原生应用场景:以往因资源或功耗限制而难以落地的场景,如实时边缘机器人、离线医疗助手、工业物联网智能分析等,迎来了新的机会窗口。
- 加速混合架构使用:促进云端大模型与本地轻量级模型混合使用的架构模式。
虽然Bonsai发布仅数日,对AI行业的深远影响尚处于早期阶段,更多是概念验证和方向性冲击,但它清晰地加速了“1-bit/极低精度LLM”这一技术路线的商业化进程,并强化了 “智能密度”优于单纯参数量 的行业理念。
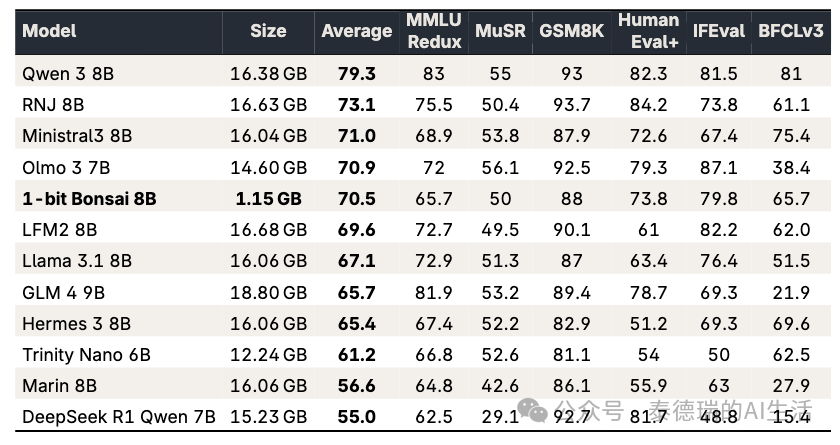
05 实测数据速览
- 内存占用极低:仅需同类模型约 1/12 的内存,即可运行8B参数模型。
- 能效提升显著:能耗效率提升约 5倍。
- 基准测试成绩:在综合基准测试中取得 70.5分 的平均成绩,位列同类模型前茅。
- M1 Air (8GB内存) 实测速度:
- 运行Bonsai 4B模型:超过 23 tokens/s。
- 运行Bonsai 8B模型:约 15–30+ tokens/s。
- 其他设备运行速度:
- M4 Pro Mac:131 tokens/sec,功耗 0.074 mWh/token。
- iPhone 17 Pro Max:~44 tokens/sec。
- iPhone 17 Pro:~40 tokens/sec。
- RTX 4090:368 tokens/sec。
- ⚠️ 注意:目前Bonsai对Windows系统的支持尚不完善,建议想体验的用户优先使用macOS。
06 快速安装与体验指南(附)
第一步:安装必要工具
如果你使用的是macOS,可以通过Homebrew来安装必要的工具。
# 安装 Homebrew(如果尚未安装)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 安装 git-lfs,用于下载大模型文件
brew install git-lfs
第二步:安装 MLX 运行库
Bonsai官方提供了针对Apple Silicon优化的MLX版本,这是目前体验该模型最便捷的方式之一。在终端中执行:
python3 -m pip install mlx-lm
第三步:运行对话
由于Bonsai 8B使用了特殊的1-bit权重,目前建议直接通过 mlx-lm 命令行工具调用(它会自动从Hugging Face下载模型)。
python3 -m mlx_lm.generate --model prism-ml/Bonsai-8B-mlx-1bit --prompt “请自我介绍一下,并告诉我你作为一个1-bit模型的优势。” --temp 0.6
这个来自加州理工学院的Bonsai项目,以其极致的效率,为人工智能在资源受限环境下的部署打开了新的想象空间。随着这类开源模型不断涌现,开发者将拥有更多工具去探索AI应用的边界。如果你对前沿AI模型和落地实践感兴趣,欢迎在云栈社区交流分享你的实测体验与想法。 |  发表于 2026-4-4 10:18:46
|
查看: 230|
回复: 0
发表于 2026-4-4 10:18:46
|
查看: 230|
回复: 0
