本文知识密度较高,建议耐心阅读。
一、基于Tick的任务调度
上篇文章 介绍了如何实现一个最简的手动调度系统。但这显然不够,我们不可能为每个系统都配备一个“操作员”来手动切换任务。
1.1 系统Tick
如何实现自动切换呢?关键在于认识到手动切换的本质:它依赖于一个持续产生的事件(无论是周期性还是随机)。将任务调度与这个事件关联起来,就能实现持续不断的自动调度。
计算机通常都配备有硬件定时器。在RISC-V架构中,标准规范定义了Timer的存在,但并未规定具体实现方式。好在业界已有一些优秀的实践,例如 SiFive 的 CLINT。本文的讨论将基于CLINT提供的核内定时器展开。
这里需要区分两个概念:Timer 和 Tick。Timer是硬件实体,而Tick则是Timer周期性产生的事件。Tick的周期由开发者根据Timer的频率来设定。想深入了解CLINT定时器,可以参考《抢占式多任务的关键一步:彻底搞懂RISC-V定时器》。
那么,系统Tick究竟是什么?它本质上就是 Timer周期性产生的中断。每次中断触发都会进入相应的中断处理函数,这就为我们嵌入任务调度逻辑提供了绝佳的机会。
Tips:
- CLINT:Core Local Interruptor(核内本地中断器),一种硬件实现,提供定时器和软中断能力,符合RISC-V特权架构标准。
- 在实际产品中,SoC通常会集成独立的定时器模块,如Arm的SP-804,作为系统Timer。
- 在数字领域,频率的最小时间单位是Cycle。例如,一个24MHz的Timer,其一个Cycle表示1/24微秒。
1.2 抢占式多任务
抢占式多任务正是依赖于系统Tick来实现的。其核心原理是:在Tick中断处理函数中判断任务优先级,让优先级更高的任务获得CPU执行权。
“抢占”就是抢夺CPU,但具体如何“抢”呢?
CPU执行代码,其实就是顺序执行一条条指令。如果能在一条指令执行完后,显式地告诉CPU下一条指令是什么,就能实现任务的切换。在RISC-V指令集架构中,mret指令就具备这个能力。我们只需将下一条指令的地址存入mepc寄存器,然后执行mret即可,流程非常清晰。

那么,如何中断CPU并保存“下一条指令”的地址呢?答案就是 中断。根据RISC-V规范,任何中断发生时,系统都会自动将被中断指令的下一条指令地址保存到mepc寄存器中。因此,整个任务抢占的流程可以概括为:
- 任务A正在运行,任务B就绪且优先级更高。
- Tick中断产生,在中断处理函数中,保存任务A的“下一条指令”地址(从
mepc寄存器保存到任务控制块TASK_CB的上下文结构体中)。
- 在同一个中断处理函数中,恢复任务B的“下一条指令”地址(从任务B的TASK_CB恢复到
mepc寄存器)。
- 调用
mret指令,CPU便开始执行任务B。
到这里,逻辑还差关键一环:当一个全新的任务(从未运行过)需要抢占时,该如何处理?这个新任务的mepc值需要被预先赋值为一个特殊地址——所有任务的总入口函数。其实现如下:
STATIC VOID inner_task_handler(UINT16 task_id)
{
if (task_id < 0 || task_id > OSZ_CFG_TASK_LIMIT) {
return;
}
g_tasks[task_id].tsk_entry(g_tasks[task_id].data);
}
为新任务填充上下文(包括mepc)的代码示例如下:
STATIC VOID inner_new_task_fill_context(UINT32 task_id)
{
// need to config mepc、mstatus、sp
TASK_CONTEXT *context = (TASK_CONTEXT *)(g_tasks[task_id].tsk_stack_top - sizeof(TASK_CONTEXT));
...
context->mepc = (UINT32)inner_task_handler;
...
}
二、部分任务状态管理
理解了抢占的基本逻辑,下一步是构建一个让任务能够循环运转的状态机。之所以说是“部分”状态管理,是因为目前仅调通了 ready(就绪)、running(运行)、block(阻塞) 三种状态间的切换。本文将先分享这部分实现的心得,后续文章会探讨完整的状态机。
2.1 任务状态机
在OSZ中,任务的状态机模型如下图所示:
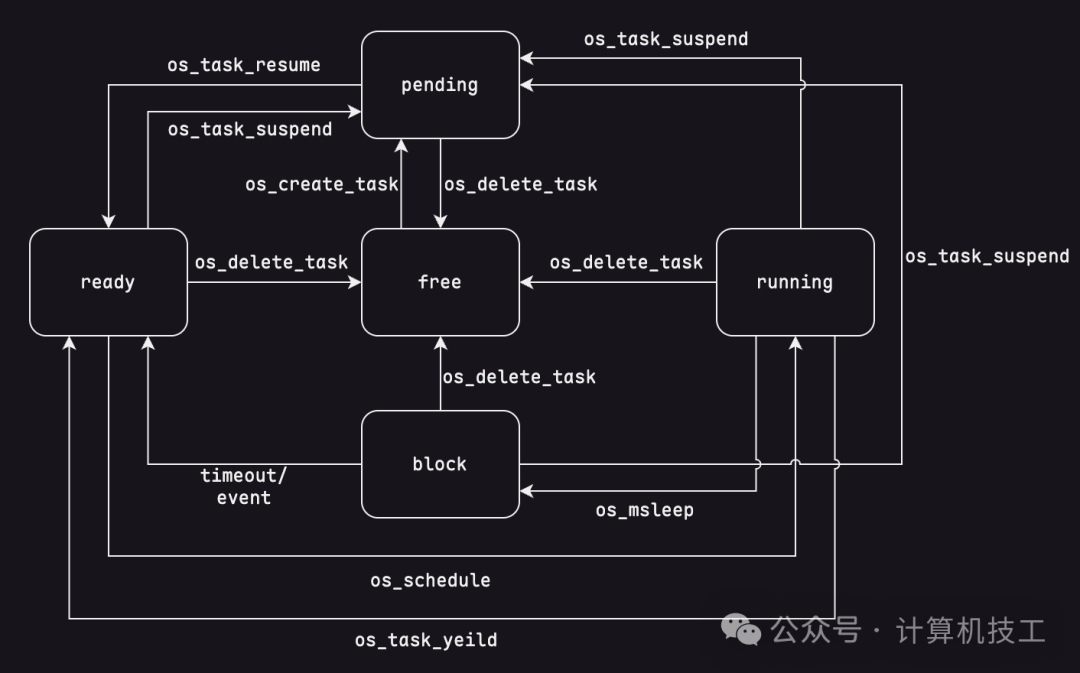
阅读这个图的技巧是:一次只关注一个状态的 入方向箭头。这样可以清晰地理解其他状态是如何转换到当前状态的。
要实现这样的状态机,需要合适的数据结构来管理处于不同状态的任务集合。由于每种状态下都可能存在多个任务,因此可以考虑使用数组或链表。OSZ选择了链表,主要因为其节点插入和删除操作更为灵活高效,这正是数据结构在系统设计中的典型应用。
2.2 双向链表
状态机的基础结构采用了双向链表。其基本结构示意图如下:
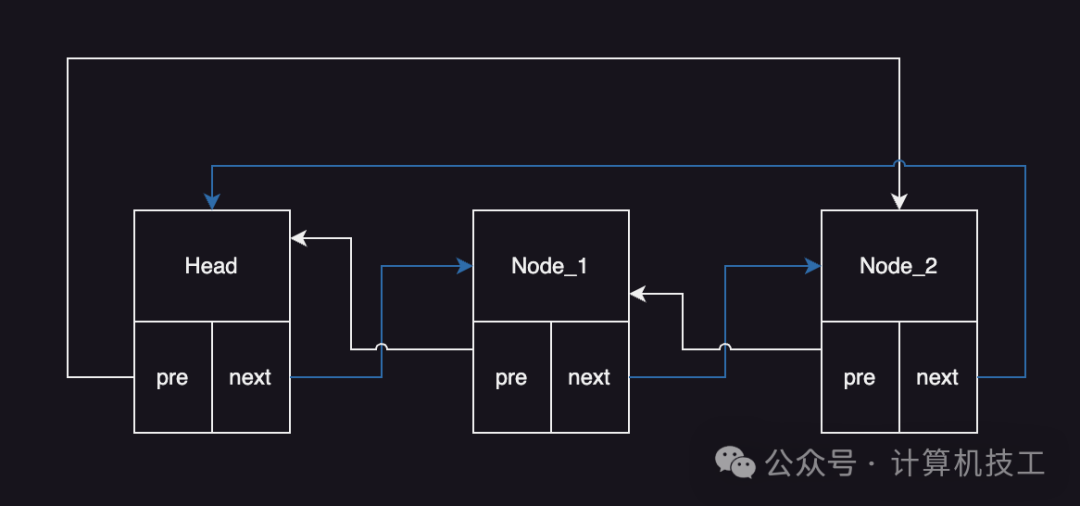
顾名思义,双向链表拥有两个方向(pre 和 next),可以从任意节点出发遍历整个链表。其节点定义非常简单:
typedef struct DLINK_NODE {
struct DLINK_NODE *pre; // 指向前一个节点
struct DLINK_NODE *next; // 指向下一个节点
} DLINK_NODE;
有了数据结构,还需要定义一系列操作接口:
VOID dlink_init(DLINK_NODE *head);
VOID dlink_insert_head(DLINK_NODE *pos, DLINK_NODE *node);
VOID dlink_insert_tail(DLINK_NODE *pos, DLINK_NODE *node);
DLINK_NODE *dlink_del_node(DLINK_NODE *node);
基于此,我们可以进一步完善任务控制块 TASK_CB:
typedef struct {
UINTPTR tsk_context_pointer; // save context info, must need to be first
...
union {
DLINK_NODE tsk_list_free; // free task list, because task only one state at same time.
DLINK_NODE tsk_list_pending; // pending task list
DLINK_NODE tsk_list_ready; // ready task list
};
...
} TASK_CB;
为每个任务都添加了free、pending和ready三个双向链表节点,并使用union来节省内存。由于任务在任意时刻只处于唯一一种状态,所以同一时刻只需使用其中一个链表。
Tips:
- 为了行文简洁,完整的双向链表实现代码可参考项目仓库。
running状态不需要单独的链表,因为同一时刻只有一个任务处于运行态。
2.3 优先级队列
处于ready态的任务会在适当时机被选中进入running态,最重要的选择标准之一就是任务优先级。优先级队列正是用来对就绪任务进行分类存储的容器。它在双向链表的基础上增加了优先级维度,实际上就是一个以优先级为下标的双向链表数组:
STATIC DLINK_NODE g_task_pri_queues[PRI_QUEUE_MAX_NUM];
同一优先级的任务在就绪时会被挂载到对应的优先级队列中。操作优先级队列需要以下接口:
UINT32 pri_queue_enqueue(UINT8 queue_id, DLINK_NODE *node, EQ_MODE mode);
DLINK_NODE *pri_queue_dequeue(UINT8 queue_id, DLINK_NODE *node);
DLINK_NODE *pri_queue_top(UINT8 queue_id);
UINT32 pri_queue_size(UINT8 queue_id);
UINT32 pri_queue_get_bitmap_low_bit(VOID);
除了标准的队列操作,pri_queue_get_bitmap_low_bit这个函数是为了在所有优先级队列中快速找出最高优先级(数值最小)的非空队列。
举个例子:任务A优先级为30,任务B优先级为31(在OSZ中,数字越小,优先级越高)。当两者都进入ready态时,常规做法是遍历队列数组,找到第一个不为空的队列(最多需遍历30次)。但如果使用位图(bitmap),则可以利用类似ctz(计数尾随零)的指令直接获取当前就绪任务的最高优先级。
任务进入就绪队列的时机主要有两类:
- 主动入队:任务自身主动放弃CPU,即调用
os_task_yield函数。
- 被动入队:因超时、被高优先级任务抢占,或其他任务调用
os_task_resume而恢复。
为了支持优先级调度,需要在TASK_CB中增加优先级字段:
typedef struct {
...
UINT32 tsk_stack_size : 16;
UINT32 tsk_priority : 16;
VOID *data; // usually, this filed use to tsk_entry params. if task is used param, this field life must be keeping to task end, suggest defined with malloc.
...
} TASK_CB; // task base cost 44 bytes
Tips:
- 为简化起见,OSZ中
pri_queue_get_bitmap_low_bit函数的实现目前是轮询查找最低有效位。
2.4 排序链表
任务进入block状态的一个常见原因是调用了延时函数。当延时结束时,任务需要自动从block态切换回ready态。这就需要一种机制来跟踪任务何时超时。一种典型做法是为每个任务绑定一个软定时器,超时后触发回调,但实现较为复杂。而使用排序链表可以更巧妙地解决这个问题。
排序链表基于前缀和算法。简单来说就是:链表中第n个节点的实际超时时间,等于从链表头到该节点所有节点的超时时间之和。示意图如下:
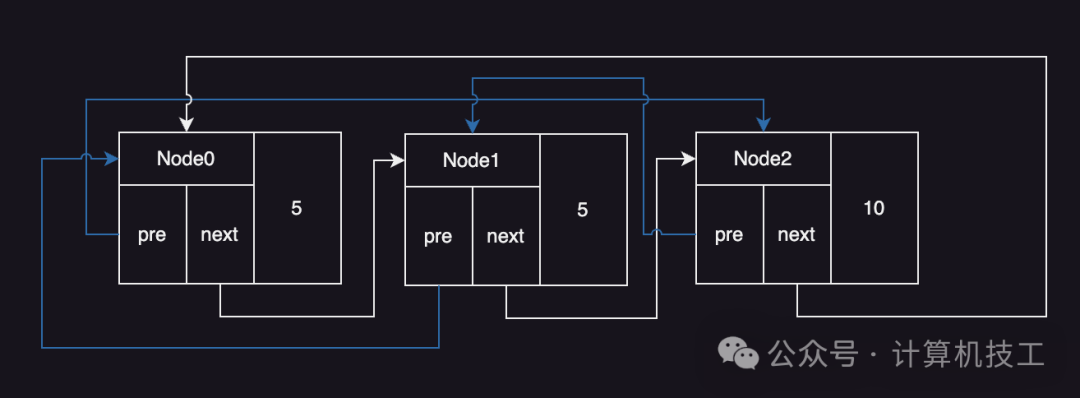
例如上图中三个节点的超时值依次为5、10、20。使用前缀和的好处在于,系统每次tick递减时,只需要更新链表第一个节点的超时值即可。
OSZ中的排序链表同样基于双向链表,只是增加了一个超时时间维度:
typedef struct {
DLINK_NODE list;
UINT32 timeout;
} SORT_LINK;
这里将DLINK_NODE作为结构体的第一个成员是有意设计的。因为list是首成员,所以可以通过C语言的指针转换,将一个指向list成员的指针安全地强制转换回SORT_LINK类型的指针。
在TASK_CB中,只需要挂载上排序链表节点:
typedef struct {
...
union {
DLINK_NODE tsk_list_free; // free task list, because task only one state at same time.
DLINK_NODE tsk_list_pending; // pending task list
DLINK_NODE tsk_list_ready; // ready task list
};
SORT_LINK tsk_list_blocking; // specially, block state need to check timeout, so use TASK_SORT_LINK.
} TASK_CB; // task base cost 44 bytes
2.5 从结构体成员获取结构体本身
C语言的灵活性很大程度上体现在指针的灵活运用上。假设有如下结构体:
typedef struct {
UINT32 a;
UINT32 b;
} Test;
Test t;
现在我们有一个指针UINT32 *pb = &(t.b),如何通过pb得到变量t的地址呢?可以使用以下语句:
(Test *)(void *)((char *)(pb) - (UINT32)&(((Test *)0)->b))
这背后的原理可以用下图清晰表示:
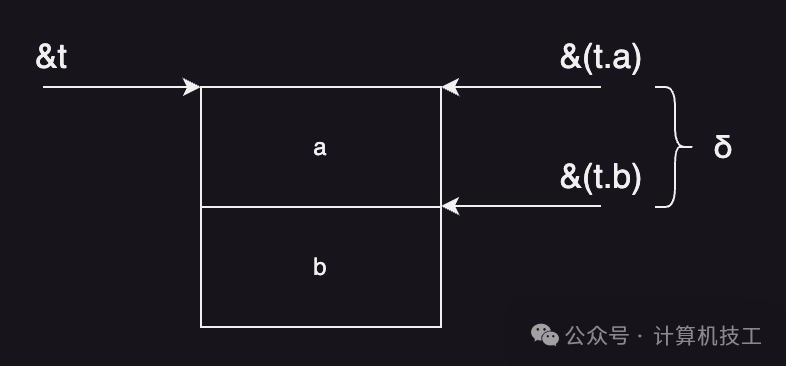
图中δ就是成员b的地址与结构体变量t起始地址之间的差值,也就是上面代码中的(UINT32)&(((Test *)0)->b)。
基于这个技巧,我们就可以直接通过tsk_list_free、tsk_list_pending、tsk_list_ready或tsk_list_blocking这些成员指针,反向获取到其所属的完整TASK_CB结构体地址了。这是一个在操作系统内核开发中非常经典且高效的内存访问模式。
Tips:
- 第2.4和2.5节详细讲解了OSZ中使用的指针技巧,完整实现请参考项目源码。
三、任务管理自动化
3.1 背景任务
具备了上述基础,任务状态机就可以运转起来了。但要实现完全自动化,还需要一个背景任务。因为所有用户任务都可能执行结束,当没有任务可运行时,系统将处于不可预期的状态。为了确保系统行为的可预测性,需要让CPU在空闲时(即无用户任务运行时)执行一个背景任务。
这个背景任务可以什么都不做,仅仅是一个无限循环。但它有一个必要条件:
这是因为,一旦有更高优先级的任务进入就绪态,系统必须能立即从背景任务中切换出去。
3.2 不完整但可运行的例子
一个可用于测试的示例代码可以在项目仓库中找到。通过剖析这些具体的实现,我们能够更深刻地理解抢占式调度器是如何从硬件定时器驱动,到内核数据结构组织,最终形成一个可运行系统的。希望本文的探讨能为你深入理解底层系统调度原理提供帮助。如果你想持续获取更多此类硬核技术解析,欢迎在 云栈社区 与我们交流。
 发表于 2026-4-4 11:45:20
|
查看: 164|
回复: 0
发表于 2026-4-4 11:45:20
|
查看: 164|
回复: 0
