在上一篇文章中,我们使用TensorFlow构建了第一个神经网络,并通过Keras接触了第一个数据集。本篇我们将动手实践,使用数据集来训练模型。同时,我们也将介绍另一个在机器学习领域举足轻重的Python库:scikit-learn。
初识Scikit-learn
Scikit-learn是一个功能非常强大的开源机器学习Python库。它提供了丰富的算法,涵盖分类、回归、聚类和降维等多个领域,例如支持向量机(SVM)、随机森林和k-means等。
我们将通过代码示例来了解支持向量机。SVM是机器学习中一个重要的监督学习模型,可用于分类和回归任务。
以下是一个使用SVM进行分类的示例程序:
from sklearn import svm
X = [[1,1,1], [2,2,2], [3,33,333], [4,44,444]]
y = [0,0,1,1]
clf = svm.SVC()
clf.fit(X, y)
print(clf.predict([5, 5., 5.]))
print(clf.predict([5, 55, 555.]))
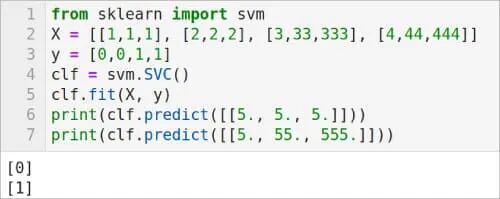
图 1:使用SVM进行分类
第1行从scikit-learn库中导入svm模块。第2行定义了包含训练数据的列表X,其中每个元素都是一个包含3个数值的列表。第3行定义了对应的类别标签列表y。第4行创建了一个支持向量分类器实例。第5行使用fit()方法,根据X和y的数据来训练(拟合)分类器模型。最后两行使用训练好的模型对新数据进行预测。从图中可以看到,模型正确地将两个新样本分别预测为类别0和1。
接下来是使用SVM进行回归的例子:
from sklearn import svm
X = [[1,1], [2,2], [3,3], [4,4], [5,5]]
y = [100.0, 200.0, 300.0, 400.0, 500.0]
regr = svm.SVR()
regr.fit(X, y)
print(regr.predict([[1, 4]]))

图 2:使用SVM进行回归
这段代码的结构与分类示例类似,区别在于y是连续值,并且使用了svm.SVR()来创建支持向量回归模型。程序预测了输入[1, 4]对应的输出值。
训练我们的第一个神经网络模型
现在,让我们回到神经网络,使用MNIST手写数字数据集来训练一个真正的模型,并用我们自己的手写数字图片对其进行测试。
我们将构建一个卷积神经网络来完成手写数字(0-9)的分类任务。完整的digital.py程序如下,为了方便理解,我们分段进行解释。
首先,导入必要的库并加载数据:
import numpy as np
from tensorflow import keras, expand_dims
from tensorflow.keras import layers
num_classes = 10
input_shape = (28,28,1)
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
第1-3行导入了NumPy、TensorFlow和Keras的layers模块。第4行将类别数定义为10(对应数字0-9)。第5行定义了输入图像的形状为28x28像素的灰度图(通道数为1)。第6行加载了MNIST数据集,并将其自动分割为训练集(x_train, y_train)和测试集(x_test, y_test)。
接下来,对数据进行预处理,使其适合模型输入:
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
x_train = np.expand_dims(x_train, 3)
x_test = np.expand_dims(x_test, 3)
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
第7-8行将图像像素值从[0, 255]的整数范围归一化到[0.0, 1.0]的浮点数范围。第9-10行使用np.expand_dims函数为数据增加一个维度,将形状从(样本数, 28, 28)转换为(样本数, 28, 28, 1),这是Keras卷积层所期望的格式。第11-12行将标签(0-9的数字)转换为one-hot编码的二进制类别矩阵。
然后,我们定义、训练并保存模型。为了避免每次运行都重新训练,代码首先尝试加载已保存的模型。
try:
model = keras.models.load_model("existing_model")
except IOError:
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3,3), activation="relu"),
layers.MaxPooling2D(pool_size=(2,2)),
layers.Conv2D(64, kernel_size=(3,3), activation="relu"),
layers.MaxPooling2D(pool_size=(2,2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
batch_size = 64
epochs = 25
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
model.save("existing_model")
第13-14行尝试从existing_model目录加载之前训练好的模型。如果是第一次运行,此目录不存在,会触发IOError异常,从而执行except块内的代码(第16-31行)来创建并训练新模型。
第16-25行定义了模型结构。这是一个顺序模型,包含以下层:
Input: 定义输入形状。Conv2D: 第一层卷积层,使用32个3x3的卷积核,激活函数为ReLU。MaxPooling2D: 2x2的最大池化层,用于降维。- 另一组
Conv2D(64个卷积核)和MaxPooling2D。
Flatten: 将多维数据展平为一维。Dropout: 丢弃率为0.5的Dropout层,用于防止过拟合。Dense: 全连接输出层,10个神经元对应10个类别,使用softmax激活函数输出概率分布。
第26行设置批大小为64,即每次训练使用64个样本。第27行设置训练轮数为25。第28行编译模型,指定损失函数为分类交叉熵,优化器为Adam,评估指标为准确率。第29行开始训练模型,使用10%的训练数据作为验证集。第30行将训练好的模型保存到existing_model目录。
训练完成后,我们评估模型性能并查看摘要:
print(model.summary())
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])
第32行打印模型的结构摘要,如图3所示。第33行使用预留的测试集(x_test, y_test)评估模型性能。第34-35行打印测试损失和测试准确率。
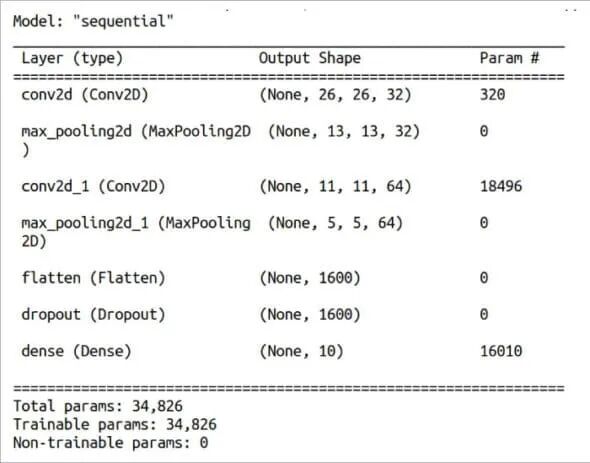
图 3:模型的详细信息
最后,我们用自己手写的数字图片来测试模型:
img = keras.utils.load_img("sample1.png").resize((28,28)).convert('L')
img = keras.utils.img_to_array(img)
img = img.reshape((1,28,28,1))
img = img.astype('float32')/255
score = model.predict(img)
print(score)
print("Number is", np.argmax(score))
print("Accuracy", np.max(score)*100.0)
第36行加载自定义图片sample1.png,将其大小调整为28x28像素并转换为灰度图。第37-39行对图片进行预处理,转换成模型能接受的格式(1, 28, 28, 1)。第40行将像素值归一化。第41行使用模型进行预测。第42-44行打印预测结果,即模型认为图片属于每个数字的概率,以及概率最高的数字(预测结果)及其置信度。

图 4:用于测试的手写数字“7”样例

图 5:digit.py脚本的输出
从图5的输出可以看到,模型在测试集上取得了很高的准确率(约99.4%)。然而,对于我们自己手写的数字“7”(图4),虽然被正确识别,但置信度仅为23.78%,模型对于数字“1”(12.86%)和“8”、“9”(约11.5%)也有一定程度的“怀疑”。这表明模型虽然整体性能不错,但对于训练数据分布之外的、风格可能不同的手写体,泛化能力仍有提升空间。图像分辨率、笔画粗细等因素都可能影响预测结果。
尽管如此,我们已经成功完成了从引入Scikit-learn基础操作,到使用TensorFlow/Keras构建、训练、评估并应用一个卷积神经网络的完整流程。这标志着你已经迈出了深度学习实践的第一步。希望这个实战案例能帮助你更好地理解机器学习的工作流。欢迎在云栈社区分享你的训练成果或遇到的挑战。
 发表于 2026-4-4 11:47:33
|
查看: 99|
回复: 0
发表于 2026-4-4 11:47:33
|
查看: 99|
回复: 0
