
如果未来的某天,AI智能体可以给自己调参数、修bug,会发生什么?
就在这两天,斯坦福IRIS Lab的博士生Yoonho Lee联合MIT、威斯康星大学的研究者发布了一篇新论文,彻底翻转了AI智能体的优化逻辑。这项研究的导师是机器人学习领域的明星学者Chelsea Finn,合作者中还包括了DSPy框架的作者Omar Khattab,阵容堪称豪华。
过去几年,大家卷的是模型本身的参数量、训练数据和RLHF。但这项名为 Meta-Harness 的研究却另辟蹊径:支撑模型运行的那层「脚手架」(Harness),同样决定着任务的成败。
这些东西以前全靠人工调试,而现在,Meta-Harness让AI自己来干这活。
结果令人惊讶:经过Meta-Harness优化后,Claude Haiku 4.5在TerminalBench-2基准上的成功率达到了 37.6% ,登顶所有Haiku智能体榜首;而Claude Opus 4.6更是达到了 76.4% 的成功率,仅次于榜一的ForgeCode。
模型是商品,Harness决定成败
那么,什么是Harness?它指的是一整套使能基础设施:包括系统提示词、工具定义、重试逻辑、上下文管理、子代理协调、生命周期钩子等。
你可以把模型本身看作一个大脑,而Harness才是让这个大脑能实际干活的身体。这个概念在2026年突然爆火,业界终于意识到,同一个模型,换上不同的Harness,性能差距可以大到离谱。
今年2月,工程师Can Bölük做了一个著名的实验。他只改动代码生成的编辑格式(即Harness的一部分),不动模型本身,就让15个LLM的编码性能提升了5到14个百分点,同时输出token还减少了约20%。

更夸张的例子是,GPT-4 Turbo仅仅因为换了一种编辑格式,其在特定任务上的准确率就从26%飙升到了59%。同样的模型,性能差了一倍多,唯一的变量就是Harness。
于是,“智能体 = 模型 + Harness”成了最热门的趋势。模型提供原始的智能,而Harness则负责将这些智能变得切实有用。像Claude Code、Codex这类产品,核心工作之一就是精心设计Harness来弥补模型自身的短板。
但问题随之而来:Harness工程目前高度依赖人工。工程师需要手动编写提示词、调整工具接口、设计重试策略,然后跑测试、看日志、猜测问题所在、修改代码、再跑测试……这个循环不仅费时费力,而且很多复杂的失败模式根本不是人力能轻易诊断的。
Meta-Harness 想做的,就是把这个循环彻底自动化。
400倍信息量:AI自己进行「复盘+迭代」
Meta-Harness的核心思路其实很简单:给优化器看更多、更完整的东西。听起来简单,但这恰恰是过去所有优化方法的瓶颈。
下面这张对比表清晰地列出了主流文本优化方法在每一步迭代中能“看到”多少上下文信息:
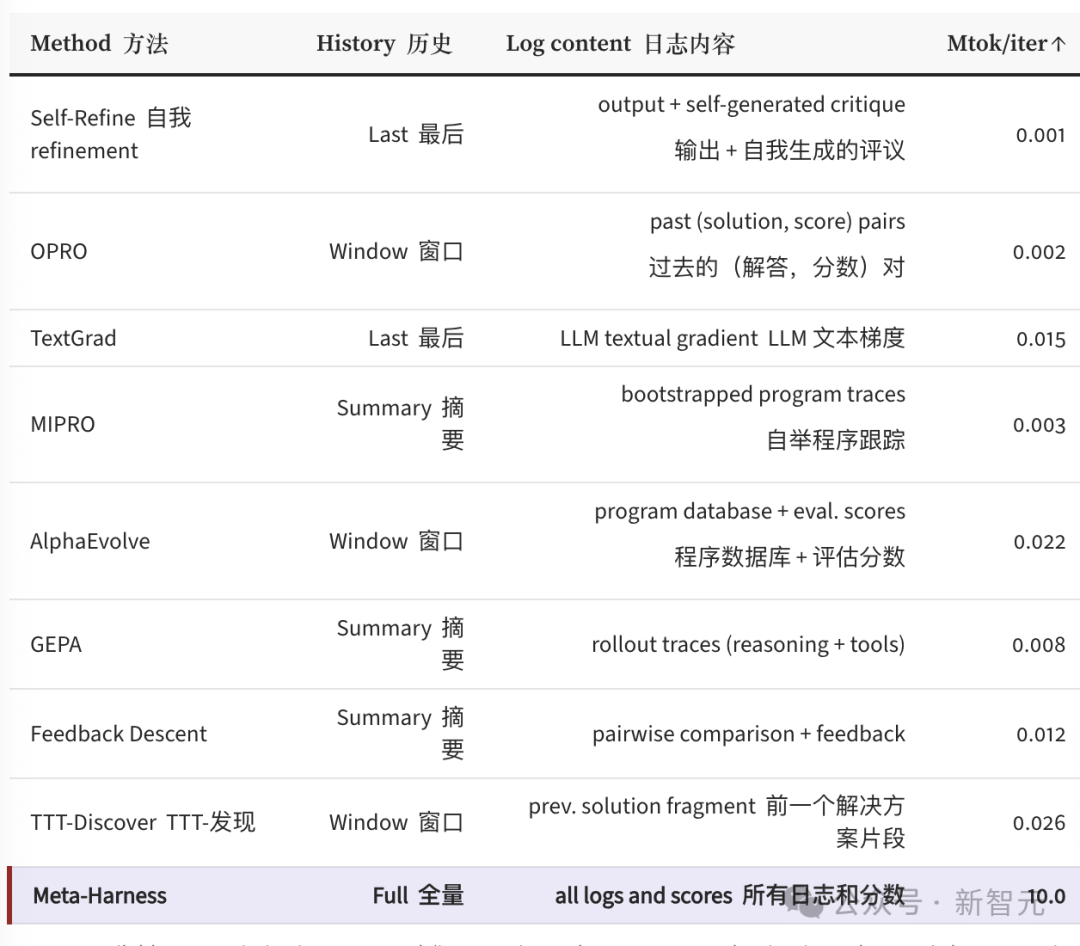
- Self-Refine只看最近一次输出加上自我批评,大约1000个token。
- OPRO会看过去几轮的方案和分数,大约2000个token。
- TextGrad、AlphaEvolve、GEPA这些更先进的方法,观察量也就在8000到26000个token之间。
那么Meta-Harness呢?最高可达1000万个token,差距高达400倍。
为什么需要这么多信息?因为Harness工程中产生的失败模式,往往藏在冗长的执行轨迹细节里。一个任务最终跑失败了,原因可能是在十步之前的某个工具调用返回了被截断的输出,导致后续的推理完全跑偏。如果优化器只能看到一个“失败”的标量分数,或者一段被高度压缩过的任务摘要,它根本没办法定位到真正的问题所在。
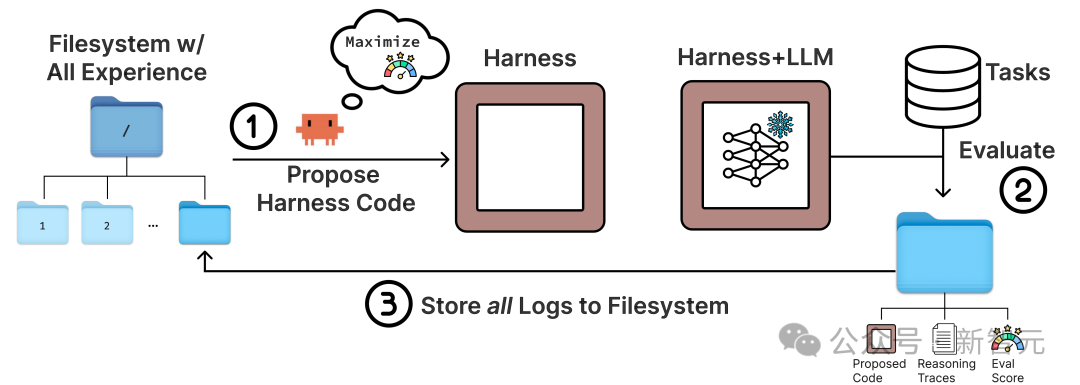
Meta-Harness的做法,是给负责提出改进方案的“提议者”(Proposer)一个完整的、包含所有历史的文件系统。这个文件系统里装着所有历史候选Harness的源代码、每一轮任务执行的完整轨迹、命令日志、错误信息、超时行为以及评分结果。
Proposer(研究中使用了Claude Code)可以像工程师一样,用grep、cat等标准工具自己去翻阅这些日志,想看哪个文件就看哪个,想搜索哪个关键词就搜索哪个。优化器不再是在一个固定格式的Prompt上做推理,而是变成了一个会主动检索信息、浏览历史、并编辑代码的真正代理。
整个搜索循环非常直观:
- Proposer从文件系统中读取所有历史执行记录。
- 分析哪些任务失败了,并推断失败的可能原因。
- 针对性地重写Harness的代码。
- 用新的Harness运行测试,并将完整的执行结果写回文件系统。
- 循环继续。
论文展示了一个在19个任务子集上的搜索过程。从Terminus-KIRA基线28.5%的成功率起步,仅仅经过7轮迭代,成功率就飙升到了46.5%。
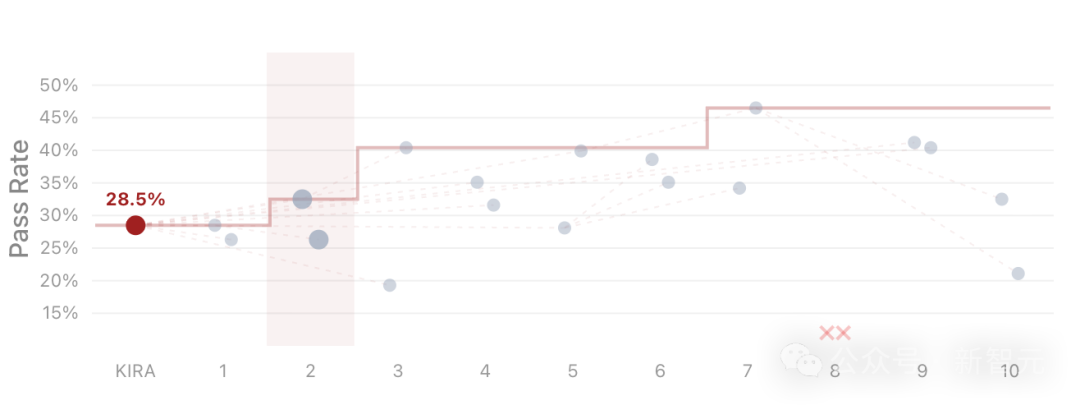
每一轮迭代都基于具体的、完整的执行轨迹进行“反事实诊断”——如果当时在某个环节这样处理,结果会不会不一样?例如,第7轮迭代提出的一个关键改进是:在第一次调用LLM之前,先运行一条shell命令,将环境依赖信息提前注入到初始Prompt中。仅仅添加这一条命令,就省去了大量无谓的试错。这种程度的诊断精度,依靠传统的压缩摘要是绝对做不到的,这充分体现了 开源实战 中推崇的基于完整上下文进行深度分析的价值。
89个真实任务,小模型性能登顶
研究者在三个主要场景测试了Meta-Harness:文本分类、数学推理和代码代理。
其中,代码代理使用的基准是TerminalBench-2。它包含89个被Docker化的真实世界任务,覆盖代码翻译、分布式机器学习配置、系统编程、生物信息学、密码分析等多个领域。每个任务都是二元评分(成功/失败),并运行5次取平均,难度非常高。这些任务需要智能体进行长程自主执行、处理复杂依赖、应对可能被截断的终端输出,并且拥有相当的领域知识。这个基准已被几乎所有主流前沿实验室用作衡量代码代理实际能力的“试金石”,是继SWE-bench之后又一个被广泛认可的“真实工作”测试集。
Meta-Harness在此优化的是完整的编码Harness,包括系统提示词、工具定义、完成检测逻辑、上下文管理等,全部都在优化范围内。Proposer会读取每个失败任务的完整执行轨迹,诊断具体的失败模式,然后提出针对性的修复方案。
结果令人瞩目:
- Claude Haiku 4.5 的成功率达到 37.6%,在所有已报道的Haiku 4.5代理中排名第一,超过了第二名Goose的35.5%。
- Claude Opus 4.6 的成功率高达 76.4%,在所有Opus 4.6代理中排名第二,仅次于ForgeCode的81.8%。
需要特别强调的是,Haiku是Claude系列中定位最轻量的版本,参数量远小于Opus。在传统思路下,小模型的性能天花板是硬伤。但Meta-Harness证明,通过系统化地优化Harness,小模型的性能天花板可以被显著抬高,甚至在 benchmark 上追平更大模型的传统表现。这为 智能 & 数据 & 云 领域的成本优化提供了新的思路。
不止于代码:文本分类与数学推理同样有效
Meta-Harness的威力并不局限于代码任务。
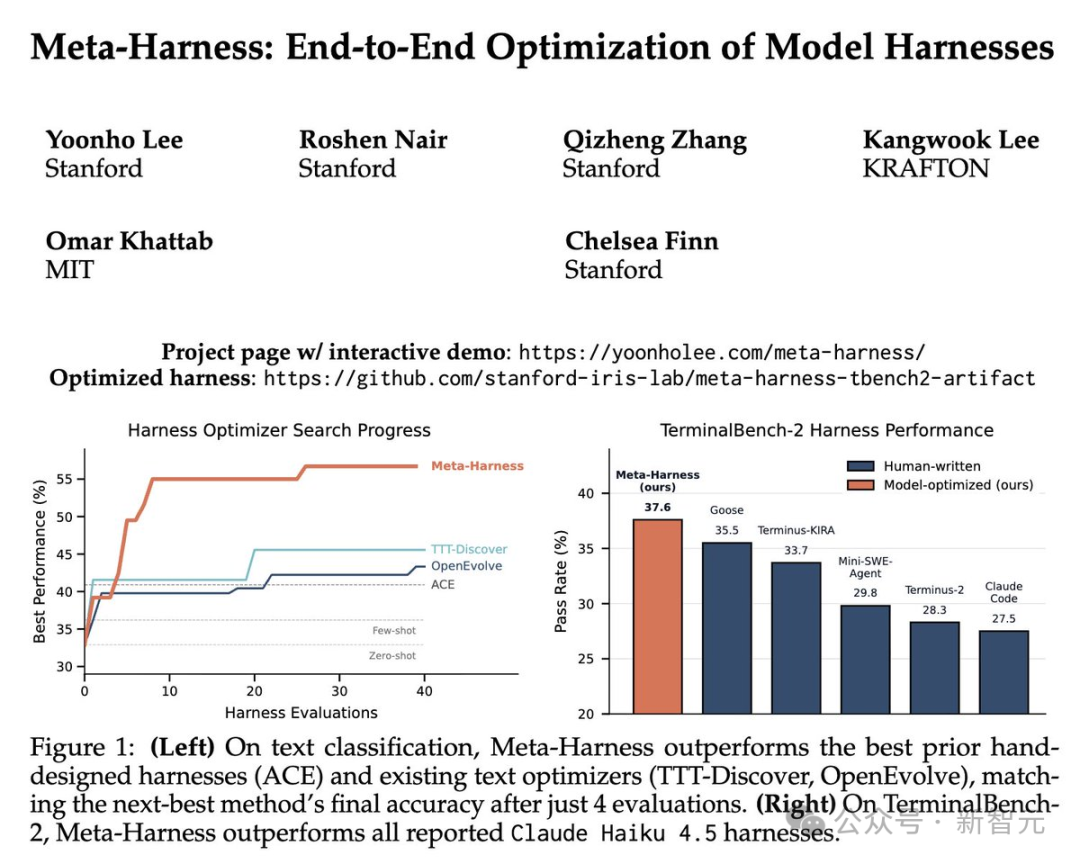
在文本分类场景下,研究者使用了三个数据集:LawBench(215个类别)、Symptom2Disease(22个类别)和USPTO-50k(180个类别),基础模型是GPT-OSS-120B。经过20轮进化迭代,每轮产生2个候选,共产出40个候选Harness。
最终,最佳发现的Harness在测试集上达到了48.6%的准确率,比之前的SOTA方法ACE高出了7.7个百分点。而且它的成本更低——Meta-Harness优化后的方案只使用了45.5K上下文token,而ACE方案需要203K。
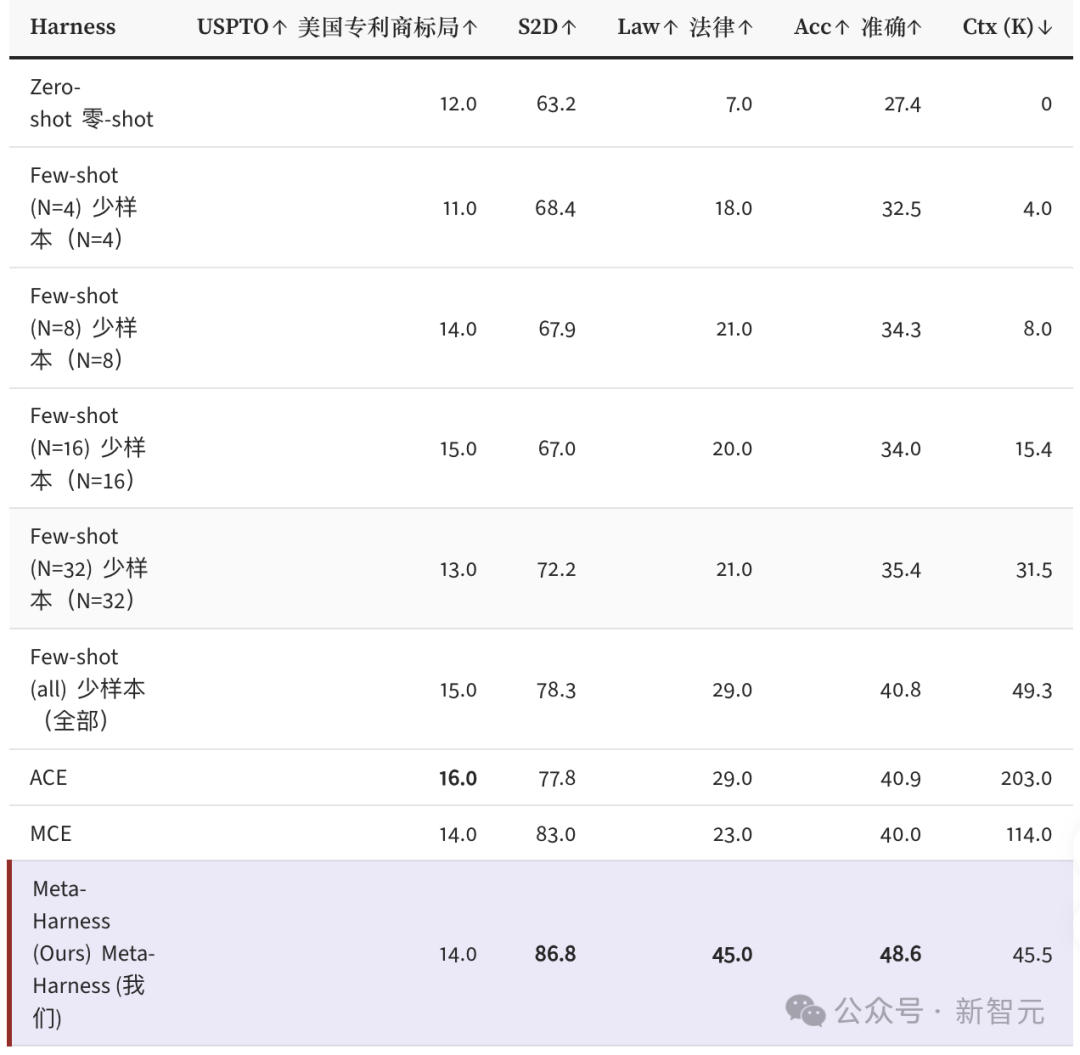
研究者还做了直接对比实验,将Meta-Harness与两个代表性的程序搜索方法放在同一起跑线上,给予相同的Proposer和评估预算。结果是,Meta-Harness仅用十分之一的评估次数就追平了对比方法的最终准确率,并且其最终的准确率还比它们高出10个百分点以上。
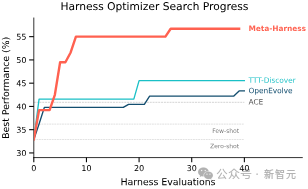
原因在于,像OpenEvolve这样的方法把历史信息压缩成固定的Prompt格式,丢失了宝贵的执行轨迹细节,而Meta-Harness保留了一切。
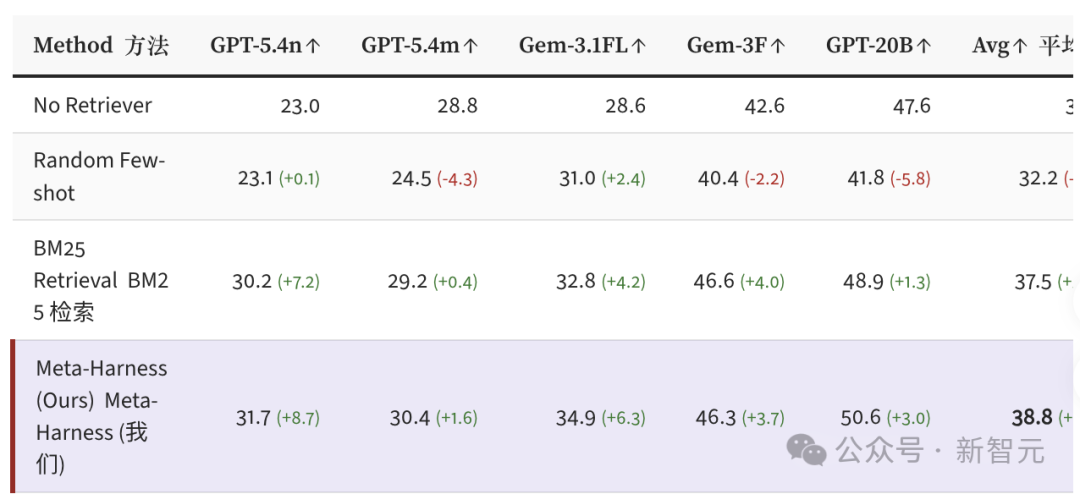
在数学推理场景下,Meta-Harness被用来搜索检索增强的推理策略。语料库包含超过50万道题目,来自8个开源数据集。研究者在250道题的搜索集上进化出一个检索Harness,然后在200道IMO级别的难题上测试,并且额外使用了5个在搜索时从未见过的模型进行验证。
结果显示,这个单一进化出的检索Harness,在5个全新的模型上平均提升了4.7个百分点(从34.1%到38.8%),而这完全是在模型本身不变的情况下实现的。这说明Meta-Harness发现的策略具有良好的可迁移性,而并非只对特定模型有效的过拟合技巧。
总结:LLM应用开发的下一个前沿
模型能力的竞争正在进入一个新阶段。过去几年,前沿实验室比拼的是谁的模型更强、参数更多、训练数据更大。但现在,顶级模型如GPT-4o、Claude 3.5、Gemini 1.5 Pro在很多任务上的表现已经拉不开巨大差距。
真正的差距开始体现在哪里?答案就是Harness。同一个模型,配上不同的Harness,最终性能可以相差一倍以上。而Harness工程目前仍高度依赖人工经验,缺乏系统化的方法论和自动化的工具链。
Meta-Harness的出现指明了一个方向:模型是智能的来源,Harness是智能的放大器。而现在,优化Harness本身这项工作,也可以交给AI来自动完成。这标志着大语言模型的应用开发可能正进入一个以“系统化、自动化工程优化”为核心的新阶段。对于广大开发者和研究者而言,关注并尝试类似Meta-Harness这样的 人工智能 框架,或许比苦苦等待下一代“奇迹模型”更为实际和有效。
这项研究也提醒我们,在 云栈社区 这样的技术交流平台,分享和探讨的不应仅仅是模型的使用,更应包括如何通过工程化方法(如优化Harness)来极致压榨现有模型的潜力,这或许是当前更具普适性的价值所在。
参考资料:
 发表于 2026-4-5 01:23:42
|
查看: 149|
回复: 0
发表于 2026-4-5 01:23:42
|
查看: 149|
回复: 0
