今天,几位活跃的 Linux 内核内存管理开发者,包括 Barry Song、王炼、陈昆吾和陈雪原,又贡献了一系列富有洞察力的讨论与补丁。
其中,王炼和陈昆吾针对 Oven Liyang 和 Barry Song 早前提出的补丁集,给出了一个堪称“完美”的模型回复。该补丁集主题为:mm: continue using per-VMA lock when retrying page faults after I/O。
讨论邮件列表链接:https://lore.kernel.org/linux-mm/20260404091936.51961-1-lianux.mm@gmail.com/
这个用于验证的模型非常精炼,它揭示了问题的核心。程序启动多个线程,每个线程通过 mmap 映射一个文件,并有意让所属的内存控制组(memcg)过载。Memcg 可以通过如下命令启动限制:

原补丁集的构想是:在因 I/O 等待而重试的缺页异常(page fault retry)路径上,采用更细粒度的 per-VMA 锁来替代粗粒度的 mmap_lock 锁,旨在缓解读写信号量(rwsem)可能引发的优先级反转问题。然而,Matthew Wilcox 提出质疑,认为这个方法可能并未解决 Google 遇到的一个实际问题:即当 memcg 过载后,第一次缺页异常虽然为 I/O 申请了内存页(folio),但当重试的缺页异常再次进入时,之前申请的 folio 可能已经被 LRU 回收机制驱逐,从而导致工作负载无法推进。
王炼和陈昆吾通过一个简单却精准的模型给出了实证:在缺页异常重试路径上使用 per-VMA 锁而非 mmap_lock,由于避免了锁竞争,重试的缺页异常等待延迟显著降低。这使得 folio 在等待期间被回收的概率急剧下降(从约45%降至接近0),整个工作负载的吞吐量也因此得到大幅提升。
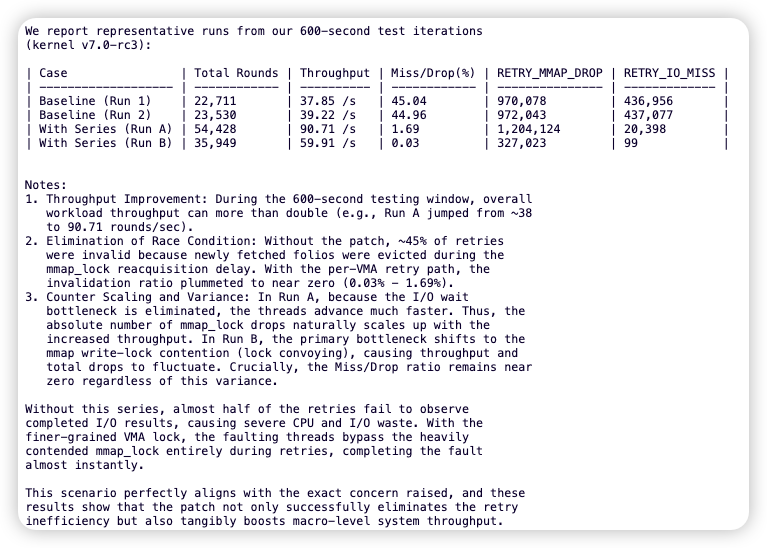
这正是解决问题的关键第一步——建模。 将一个复杂的内核机制问题,通过一个简洁的模型清晰地阐述和验证。模型建立完成后,具体的修复方案反而变得相对直接。
与此同时,Barry Song 今天在 vmalloc/vmap/ioremap 的复合页(compound pages)映射优化上提交了4个补丁,旨在对 DMA-BUF 等场景的映射进行批处理优化。
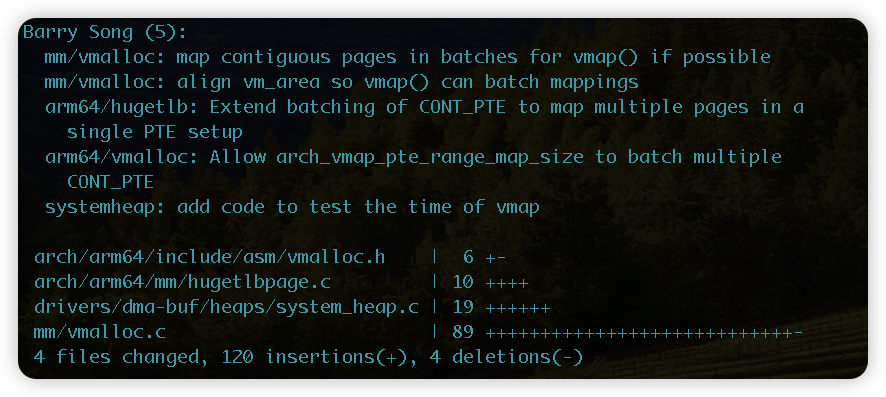
这一优化将显著提升 system_heap 等 DMA-BUF 堆的 vmap 映射/解除映射速度,以及 ioremap 等操作的性能。
陈雪原今天则在两块不同的硬件开发板上对 Barry Song 的 vmalloc 优化进行了测试,验证了数倍的性能提升。在测试过程中,雪原还发现了 system_heap 中存在的另一个性能瓶颈及其优化空间。
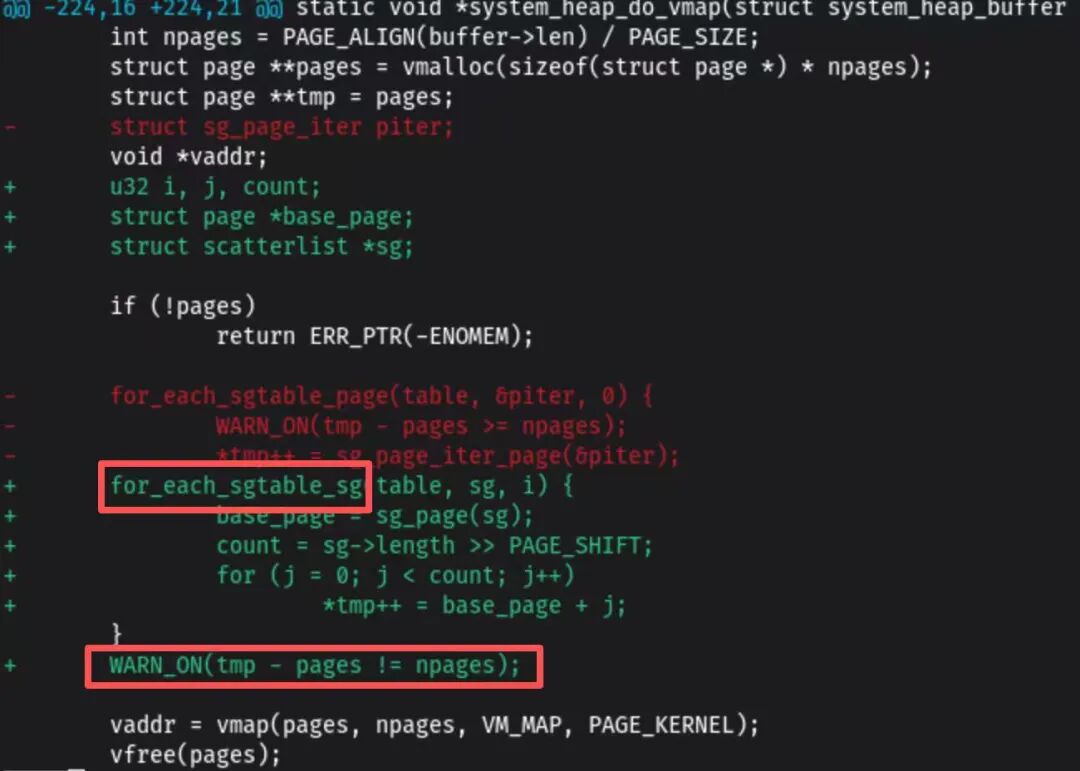
他提出的补丁旨在优化 scatter-gather (sg) 表到 page 数组的转换逻辑,经过测试,此转换速度可提升6-7倍。目前这个补丁正在积极完善中。
此外,王炼和陈昆吾也用简单的模型复现了另一个问题:当 Linux 内核突然出现大量 order-3(即8页)的连续内存申请时,在伙伴系统(buddy)碎片化严重的情况下,会触发剧烈的内存过度回收(over reclamation),导致 kswapd 内核线程的 CPU 利用率飙升至接近90%。这项工作实际上是对 Barry Song 早前在社区提出的一个 RFC 的深入回应,该 RFC 讨论了网络流量突发时手机设备发热的问题:
mm: net: disable kswapd for high-order network buffer allocation
讨论邮件列表链接:https://lore.kernel.org/linux-mm/20251013101636.69220-1-21cnbao@gmail.com/
Order-3 在内核中是一个有点“尴尬”的阶数。原因在于内核中有如下定义:
#define PAGE_ALLOC_COSTLY_ORDER 3
而内存回收(vmscan)逻辑中的典型判断是:
if (order > PAGE_ALLOC_COSTLY_ORDER) {
这意味着,内核并不认为 order-3 是一个昂贵的分配。因为代码逻辑是“大于”而非“大于等于”。因此,当 order-3 分配失败时,它不会像更高阶分配那样触发谨慎的回收策略,但实际申请8页连续内存的代价可能并不低。这便埋下了隐患:vmscan 认为它代价不高,但现实情况中它可能很“昂贵”!
这个关于 order-3 内存分配行为的讨论,预计将掀起一场更深入的内核机制研究。
 发表于 2026-4-5 03:26:12
|
查看: 92|
回复: 0
发表于 2026-4-5 03:26:12
|
查看: 92|
回复: 0
