Mooncake 的 RDMA Transport 实现了一个面向超大规模 AI 训练场景的高性能 RDMA 传输层,其核心不在于简单封装 ibverbs,而在于围绕 多 HCA 协同、NUMA 感知调度、Slice 粒度流控、异步事件自愈 四大设计目标构建的完整闭环。本文聚焦 RdmaContext 与 WorkerPool 这两个承上启下的关键组件,结合源码与架构图,还原其如何将硬件能力转化为可工程化落地的稳定吞吐。
核心组件职责再梳理
RDMA Transport 的分层结构并非扁平抽象,而是严格遵循“设备即资源、连接即状态、执行即调度”的原则:
RdmaTransport:传输门面,负责元数据协同、Segment 生命周期管理与跨 Context 调度策略;RdmaContext:单 HCA 的资源容器,是 ibv_context、ibv_pd、CQ、Comp Channel 等底层对象的 C++ 封装与生命周期管理者;RdmaEndPoint:QP 连接的逻辑抽象,屏蔽了 ibv_qp 状态机细节,提供 submitPostSend() 等高层语义;WorkerPool:真正的执行引擎,它解耦了“任务分发”与“硬件操作”,是性能与可靠性的最终守门人。
这一架构与 网络/系统 中讨论的 RDMA 基础模型完全对齐,但更进一步解决了生产环境中的拓扑感知、故障隔离与资源复用问题。
RdmaContext:HCA 资源的精细化管控者
RdmaContext 是每个物理网卡(如 mlx5_0)在用户态的完整镜像。它的 construct() 函数不是简单的初始化列表堆砌,而是一套严谨的资源编排流程:
int RdmaContext::construct(size_t num_cq_list, size_t num_comp_channels, uint8_t port, int gid_index, size_t max_cqe, int max_endpoints) {
// 步骤1:创建EndpointStore(底层存储实现)
auto &config = globalConfig;
switch (config.endpoint_store_type) {
case EndpointStoreType::FIFO:
endpoint_store_ = std::make_shared<FIFOEndpointStore>(max_endpoints);
LOGINFO << "Using FIFO endpoint store";
break;
case EndpointStoreType::SIEVE:
endpoint_store_ = std::make_shared<SIEVEEndpointStore>(max_endpoints);
LOGINFO << "Using SIEVE endpoint store";
break;
}
// 步骤2:打开 RDMA 设备,获取 ibv_context, GID, LID 等信息
if (openMnabDevice(device_name_, port, gid_index) != 0) {
LOGERROR << "Failed to open device " << device_name_;
return ERR_CONTEXT;
}
// 步骤3:创建 Protection Domain
pd = ibv_alloc_pd(context_);
if (pd == nullptr) {
PLOG_ERROR << "Failed to allocate new protection domain";
return ERR_CONTEXT;
}
// 步骤4:创建 Completion Channels(用于事件通知)
num_comp_channel_ = num_comp_channels;
comp_channel_ = new ibv_comp_channel*[num_comp_channels];
for (size_t i = 0; i < num_comp_channels; ++i) {
comp_channel_[i] = ibv_create_comp_channel(context_);
if (comp_channel_[i] == nullptr) {
PLOG_ERROR << "Failed to create completion channel";
return ERR_CONTEXT;
}
}
// 步骤5:创建 epoll fd 用于非阻塞监听
events_fd_ = epoll_create(0);
if (events_fd_ < 0) {
PLOG_ERROR << "Failed to create epoll";
return ERR_CONTEXT;
}
// 注册 context 的异步事件 fd 到 epoll
if (joinNonBlockingPollList(event_fd_, context_->async_fd) != 0) {
LOGERROR << "Failed to register async fd to epoll";
return ERR_CONTEXT;
}
// 注册所有 completion channel 的 fd 到 epoll
for (size_t i = 0; i < num_comp_channel_; ++i) {
if (joinNonBlockingPollList(event_fd_, comp_channel_[i]->fd) != 0) {
return ERR_CONTEXT;
}
}
// 步骤6:创建 Completion Queues
cq_list.resize(num_cq_list);
for (size_t i = 0; i < num_cq_list; ++i) {
cq_list[i].ibv_create_cq(
context_, max_cqe, NULL, &cq_list[i].outstanding, compChannel(), compVector()
);
if (!cq_list[i].native()) {
PLOG_ERROR << "Failed to create completion queue";
return ERR_CONTEXT;
}
}
// 步骤7:创建 WorkerPool,启动工作线程
worker_pool_ = std::make_shared<WorkerPool>(*this, socketID);
LOGINFO << "RDMA device: " << context_->device_name << ", LID: " << lid << ", GID: " << gid;
return 0;
}
其中最关键的三个设计决策值得深挖:
1. EndpointStore:连接池的智能淘汰策略
EndpointStore 并非简单的 std::map<std::string, std::shared_ptr<RdmaEndPoint>>。它直面一个现实问题:在千节点集群中,一个节点可能需与数百个对端 NIC 建连,若全量缓存,QP 资源将迅速耗尽。
FIFO 策略适用于连接模式高度稳定的场景(如固定拓扑训练),但存在“冷热混杂”导致有效连接被驱逐的风险;SIEVE 策略则借鉴了 NSDI'24 论文思想,通过 visited 标记实现“访问感知淘汰”。每次 getEndpoint() 时置位,evictEndpoint() 时跳过已标记项并清零,确保高频连接永驻内存。这正是 开源实战 中强调的“论文到生产”的典型范例。
2. Completion Channel:为何创建却未使用?
代码中明确调用了 ibv_create_comp_channel() 并将其绑定至 CQ,但后续 WorkerPool::performPollCq() 却采用 ibv_poll_cq() 主动轮询。这不是冗余,而是为未来留出弹性接口:
- 当前
polling 模式保障了最低延迟(< 1μs),契合 AI 训练对尾延迟的严苛要求;
Comp Channel 的 fd 已注册至 epoll,意味着只需修改 performPollCq() 的循环逻辑,即可无缝切换至事件驱动模式,应对低负载或功耗敏感场景。
3. WorkerPool 的构造:线程模型的起点
RdmaContext::construct() 的最后一步,是启动 WorkerPool。这标志着控制权从“资源准备”正式移交至“任务执行”。
WorkerPool::WorkerPool(RdmaContext &context, int numa_socket_id) {
// 创建 kTransferWorkerCount 个传输线程(默认 2)
for (int i = 0; i < kTransferWorkerCount; ++i)
worker_thread_.emplace_back(
std::thread(std::bind(&WorkerPool::transferWorker, this, i))
);
// 额外创建 1 个监控线程
worker_thread_.emplace_back(
std::thread(std::bind(&WorkerPool::monitorWorker, this))
);
}
此处埋下两个伏笔:
kTransferWorkerCount=2 是经验性配置,实际应根据 CQ 数量与 NUMA node 数量动态调整;monitorWorker 与 transferWorker 的分离,是实现“故障处理不阻塞主路径”的基石。
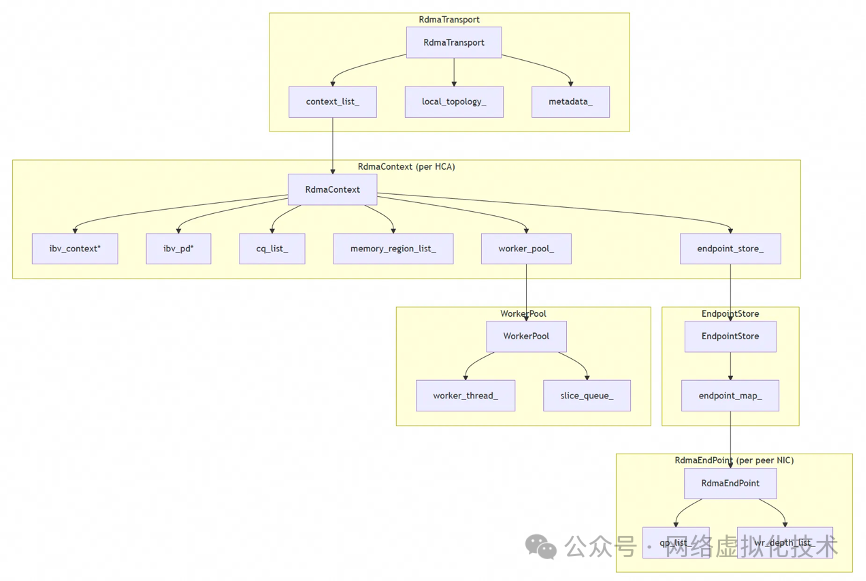
图中清晰展示了 RdmaContext 如何作为枢纽,向上承接 RdmaTransport 的调度指令,向下孵化 WorkerPool 并托管 EndpointStore 与 CQ 列表。这一层级关系是理解整个 RDMA Transport 数据流的关键锚点。
WorkerPool:高并发下的确定性执行引擎
如果说 RdmaContext 是“地基”,那么 WorkerPool 就是“承重墙”。它必须在以下矛盾中取得平衡:高吞吐(大量 Slice 并发提交) vs 低延迟(单 Slice 快速完成) vs 强可靠(故障自动恢复)。
其核心由三大模块构成:
| 模块 |
职责 |
关键机制 |
submitPostSend() |
生产者入口 |
Shard 分片、无锁预分组、条件唤醒 |
transferWorker() |
消费者主循环 |
NUMA 绑定、空闲自适应休眠、PostSend/PollCq 交替执行 |
monitorWorker() |
异步事件看护者 |
epoll 监听 async_fd、分级故障响应、秒级自愈 |
Shard 分片:消除锁竞争的精巧设计
传统全局队列在高并发下极易成为瓶颈。WorkerPool 采用两级缓冲:
- 生产者侧:
submitPostSend() 先将 Slice* 无锁写入本地数组 slice_list_map[kShardCount];
- 消费者侧:每个
transferWorker 线程只消费特定 shard_id 的队列,且 shard_id 计算公式为 (target_id * 10007 + device_id) % kShardCount。
该设计一举三得:
10007 为大素数,避免 target_id 连续导致哈希冲突;+ device_id 确保同一目标节点的不同 NIC 路径被分散;- 最终效果是:发往同一
peer_nic_path 的所有 Slice 必然落入同一 shard,由同一 worker 线程串行处理,天然保证了 QP 连接复用与顺序性。
// shard_id 计算逻辑
int shard_id = (slice->target_id * 10007 + device_id) % KShardCount;
slice_queue_lock_[shard_id].lock();
for (auto &slice : slice_list_map[shard_id]) {
slice_queue_[shard_id].push_back(slice);
slice_queue_count_[shard_id].fetch_add(slice_list_map[shard_id].size());
}
slice_queue_lock_[shard_id].unlock();
transferWorker:空闲感知的节能循环
transferWorker() 的休眠逻辑是性能与能效的精妙权衡:
void WorkerPool::transferWorker(int thread_id) {
bindToSocket(numa_socket_id);
const static uint64_t kWaitPeriodInNano = 100000000; // 100ms
uint64_t last_wait_ts = getCurrentTimeInNano();
while (workers_running_.load(std::memory_order_relaxed)) {
auto processed_slice_count = processed_slice_count_.load();
auto submitted_slice_count = submitted_slice_count_.load();
if (processed_slice_count == submitted_slice_count) {
// 空闲状态:所有提交的 Slice 都已处理完成
uint64_t curr_wait_ts = getCurrentTimeInNano();
if (curr_wait_ts - last_wait_ts > kWaitPeriodInNano) {
// 空闲超过 100ms,进入睡眠等待
std::unique_lock<std::mutex> lock(cond_mutex_);
suspended_flag_.fetch_add(1);
cond_var_.wait_for(lock, std::chrono::seconds(1)); // 睡着1秒或被唤醒
suspended_flag_.fetch_sub(1);
last_wait_ts = curr_wait_ts;
}
continue;
}
// 有工作要做,执行 Post Send 和 Poll CQ
performPostSend(thread_id);
performPollCq(thread_id);
}
}
- Busy-Poll 100ms:应对突发流量,避免频繁系统调用开销;
- Sleep 1s:长空闲期彻底释放 CPU,
suspended_flag_ 为生产者提供精确唤醒信号;
- NUMA 绑定:确保
worker 线程与 RdmaContext 所在 NUMA node 一致,规避跨 NUMA 内存访问延迟。
monitorWorker:硬件故障的“免疫系统”
monitorWorker() 是整个 RDMA Transport 的稳定性守护者。它通过 epoll 监听 context_->async_fd,捕获来自内核的硬件级事件:
void WorkerPool::monitorWorker() {
bindToSocket(numa_socket_id);
auto last_reset_ts = getCurrentTimeInNano();
while (workers_running_) {
auto current_ts = getCurrentTimeInNano();
// 每秒重置 Context 为活跃状态(自愈机制)
if (current_ts - last_reset_ts > 1000000000ll) {
context_.set_active(true);
last_reset_ts = current_ts;
}
// 使用 epoll 等待异步事件(超时 100ms)
struct epoll_event event;
int num_events = epoll_wait(context_.eventFd(), &event, 1, 100);
if (num_events < 0) {
if (errno != EWOULDBLOCK && errno != EINTR) PLOG(ERROR) << "Worker: epoll_wait";
continue;
}
if (num_events == 0) continue; // 超时,无事件
if (!(event.events & EPOLLIN)) continue; // 不是输入事件
// 检查是否是 Context 的异步事件
if (event.data.fd == context_.context()->async_fd)
doProcessContextEvents();
}
}
其 doProcessContextEvents() 对事件进行三级响应:
- QP 级故障(
IBV_EVENT_QP_FATAL):仅禁用对应 RdmaEndPoint,不影响其他连接;
- 设备级故障(
IBV_EVENT_DEVICE_FATAL, IBV_EVENT_PORT_ERR 等):调用 disconnectAllEndpoints(),将所有 QP 置为 RESET,并标记 context_.set_active(false);
- 端口恢复(
IBV_EVENT_PORT_ACTIVE):主动恢复 active 状态,等待下次 performPostSend() 触发重连。
这种分级响应,使得单个网卡故障不会导致整个节点失联,极大提升了系统的韧性。
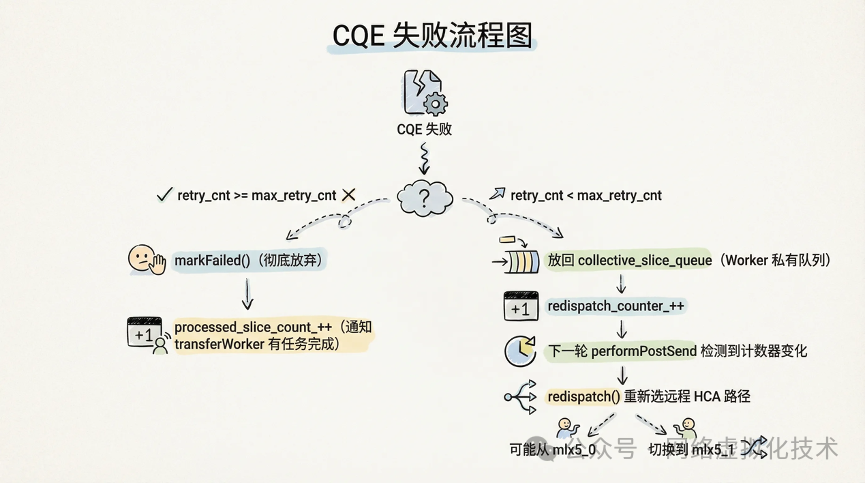
上图揭示了 WorkerPool 如何处理最棘手的 CQE 失败场景:当 retry_cnt < max_retry_cnt 时,并非简单重试,而是调用 redispatch() 重新选择远程 HCA 路径(例如从 mlx5_0 切换到 mlx5_1),实现了真正的“故障转移”而非“故障重试”。
连接建立:懒加载与状态机的精准控制
RdmaEndPoint::setupConnectionsByActive() 的“懒建连”设计,是性能与可靠性的又一典范:
- 不预建连:
EndpointStore::getEndpoint() 未命中时才触发建连,避免海量无效 QP 占用资源;
- 失败即重试:建连失败后,
Slice 进入重试队列,transferWorker 下一轮循环会再次尝试,无需上层干预;
- 状态机驱动:
doSetupConnection() 严格遵循 IB 规范,将 QP 从 RESET → INIT → RTR → RTS 四步推进,每步配置不同属性(port_num, GID, timeout, retry_cnt),确保状态转换的原子性与可追溯性。
// RTR → RTS 时设置
attr.timeout = TIMEOUT; // 超时时间(指数级,如 14 ≈ 68ms)
attr.retry_cnt = RETRY_CNT; // 超时重传次数上限(通常 7)
attr.rnr_retry = 7; // RNR NAK 重传次数上限(7 = 无限重试)
这些参数并非随意设定,而是基于对 InfiniBand 链路特性的深度理解:TIMEOUT 值需覆盖最大往返时延(RTT)与交换机转发延迟;RETRY_CNT=7 是在丢包率与重传开销间的最佳平衡点。
总结:RDMA Transport 的工程哲学
Mooncake 的 RDMA Transport 并非炫技式的“堆砌特性”,而是以解决真实世界问题为出发点的工程结晶:
- 拓扑即代码:
Topology 对象贯穿始终,从 selectDevice() 的亲和性选择,到 monitorWorker 的 NUMA 绑定,硬件拓扑不再是配置项,而是运行时决策的核心依据;
- 错误即常态:
CQE 失败、async_fd 事件、QP 故障均被设计为第一类公民,有完备的检测、隔离、恢复、上报链路;
- 演进即设计:
Comp Channel 的预留、SIEVE 缓存的引入、shard 分片的通用性,都体现了对系统未来演进的前瞻性思考。
这套设计思路,与 后端 & 架构 中倡导的“可观测、可伸缩、可演进”原则高度一致。它证明了:在追求极致性能的同时,工程上的稳健与优雅,从来都不是非此即彼的选择。
 发表于 2026-4-5 03:35:32
|
查看: 167|
回复: 0
发表于 2026-4-5 03:35:32
|
查看: 167|
回复: 0
