多年前,在我职业生涯的一个关键节点,我面临了一个极具挑战性的任务:从零开始搭建一个广告平台。这不仅是证明自己能力的机会,更是一场关乎团队未来的内部竞争。我们的目标很明确:功能要尽可能丰富,尤其要满足业务人员的多样化需求;同时,系统在高并发下的稳定性和可靠性必须达到极致。
随着开发的深入,一个棘手的问题浮出水面:高并发下的复杂查询性能。当时,我的技术栈选择有限,主要依赖 MySQL 数据库。为了应对预期流量,我最初采用了经典的数据库读写分离架构。
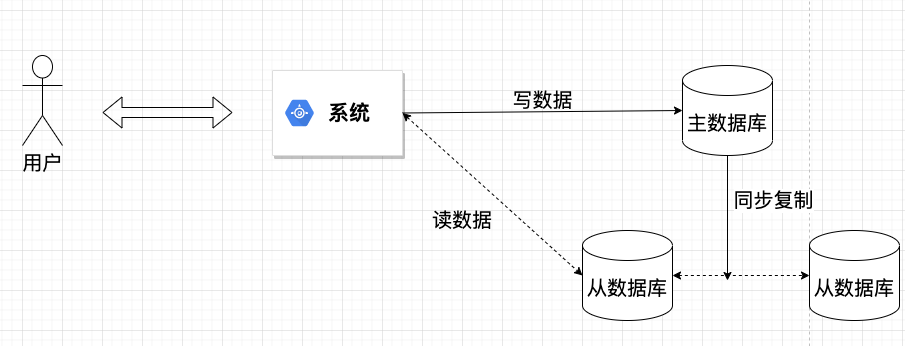
然而,在压力测试中,效果始终不理想。问题的核心源于一个具体的业务需求:一个需要准实时更新的广告投放排行榜。这个排行榜的生成涉及多指标关联统计与复杂排序,SQL 语句异常冗长。更麻烦的是,为了“准实时”,这个复杂查询需要被频繁执行。即便尝试引入缓存,从数据库查询结果到转换成前端可用的 Java 对象这一过程,在并发量上来后,性能损耗依然巨大。
项目上线日期日益临近,性能瓶颈却像一座大山横亘在前。就在我几乎要放弃优化、准备“听天由命”上线时,我从竞争对手那里听到一个关键词:CQRS。
CQRS 的核心思想:读写彻底分离
CQRS,即命令查询职责分离模式。它提出了一种根本性的思路:一个系统中的“读”(查询)和“写”(命令)是两种截然不同的操作,将它们混在一起,就像一边读书一边刷手机,双方都会受到影响,无法达到各自的最优状态。
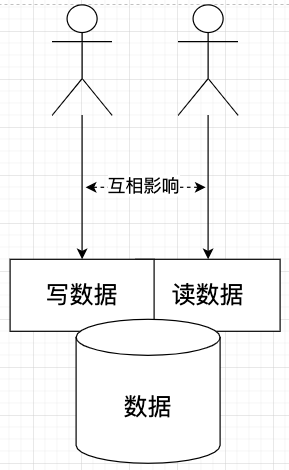
因此,CQRS 主张将读写行为彻底分离,并允许它们使用完全不同的数据模型。这不仅仅是数据库层面的主从分离,更是模型层面的解耦。
突破点:从“同一模型”到“专属模型”
我最初认为 CQRS 不过是数据库读写分离的另一种说法,直到我研究了 Martin Fowler 的原始论述和架构图。
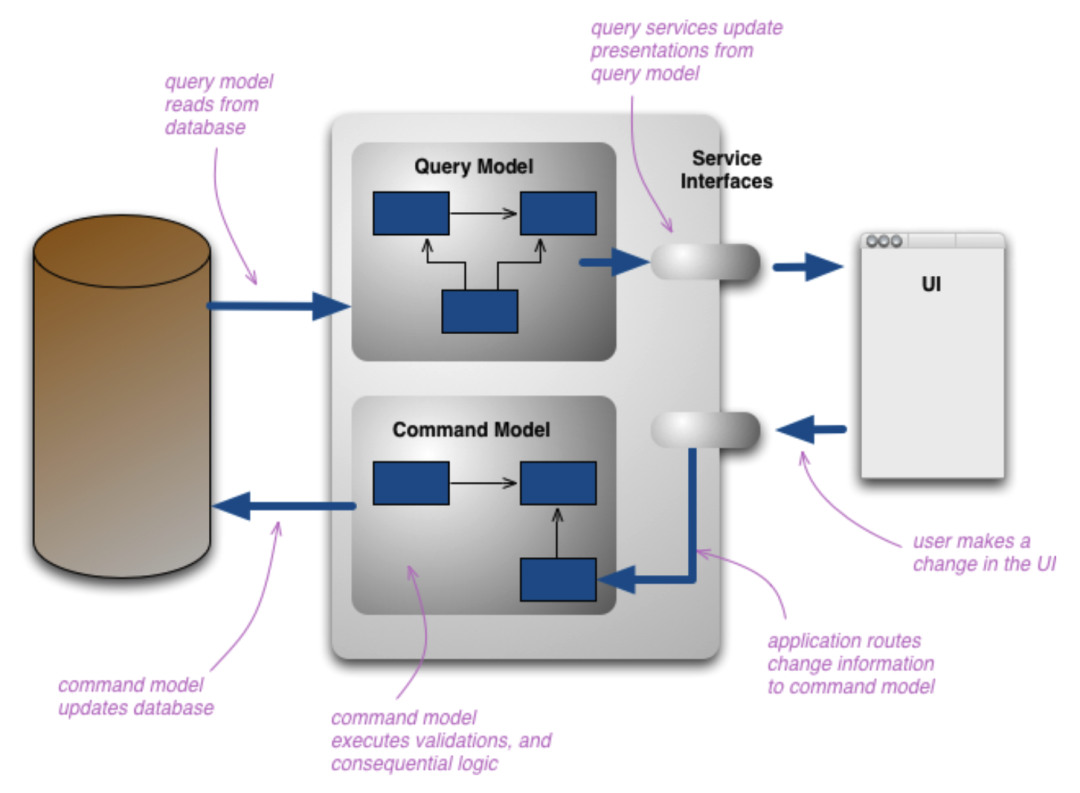
我恍然大悟。传统的读写分离,其根本局限在于读和写操作仍然共享同一套数据模型。这个模型为了同时照顾写入的效率(如范式化以减少冗余)和读取的便捷(如反范式化以关联查询),不得不做出妥协,结果往往是两头不讨好。
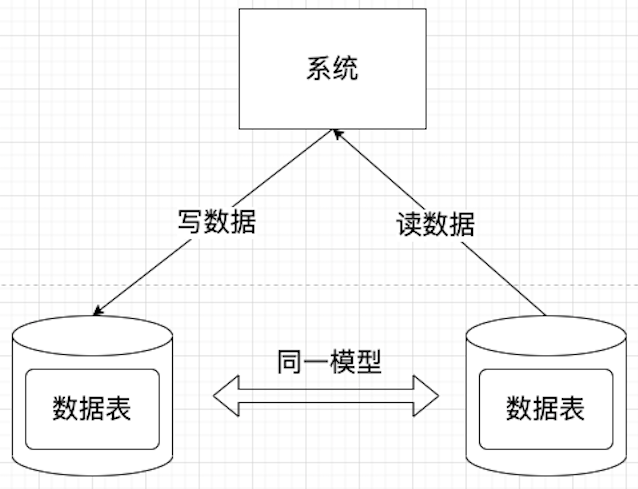
CQRS 的“职责分离”精髓正在于此:为“命令”(写)和“查询”(读)分别设计最适合其场景的专属模型。写入模型可以完全聚焦于业务规则的正确性和事务一致性,而不必关心查询效率;读取模型则可以极尽所能地优化,采用非规范化、甚至物化视图、搜索引擎索引等格式,只为最快的查询速度服务。
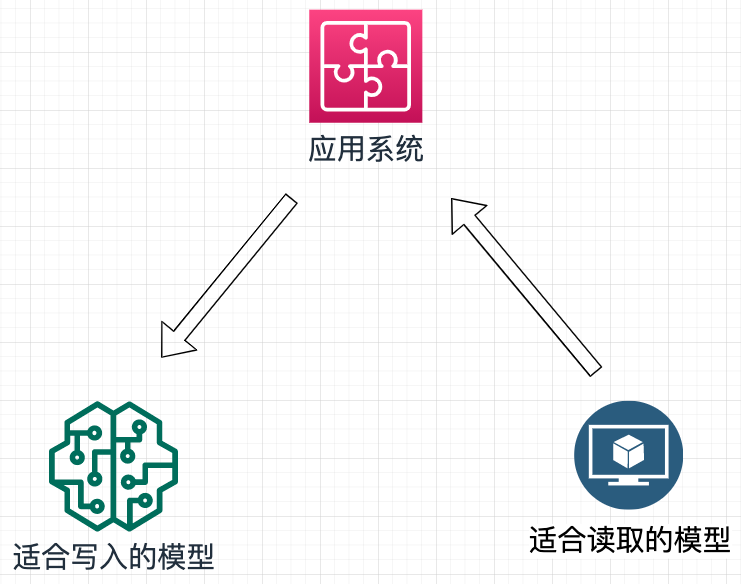
实战设计:用 CQRS 解决广告排行榜难题
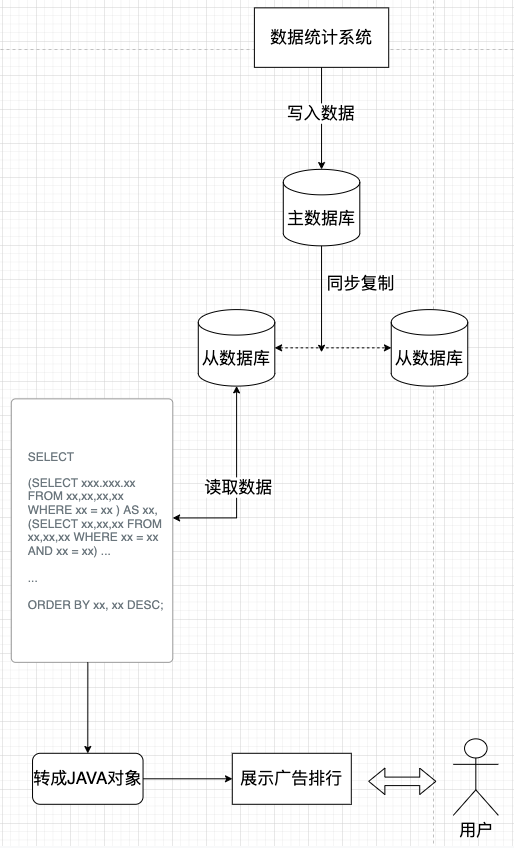
这个思想像一盏明灯,照亮了我的困境。针对广告排行榜这个具体问题,我设计了如下方案:
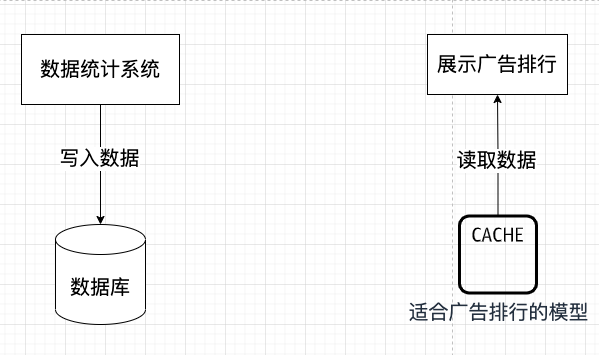
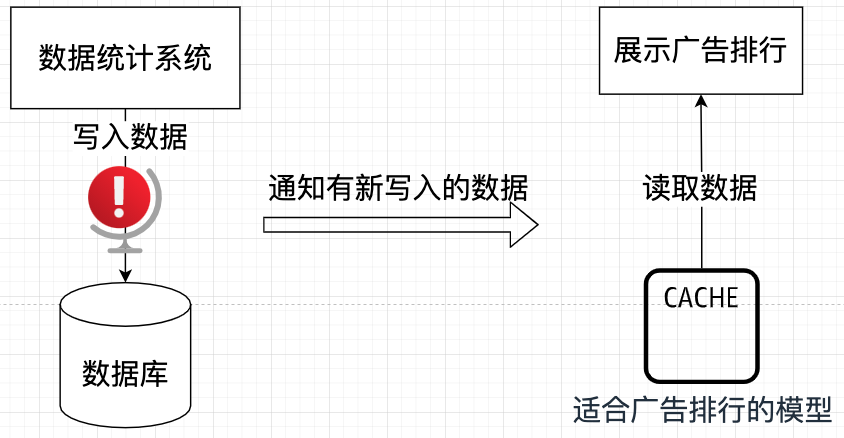
- 命令端(写):广告的点击、消费等统计数据的写入,直接进入一个专用于写入的数据库。这部分逻辑简单直接,只保证数据正确持久化。
- 查询端(读):展示排行榜的功能,不再执行复杂
SQL 查询,而是从一个专门的缓存(或读取数据库)中,直接获取已经计算好、结构最适合前端展示的排行榜模型。
- 数据同步:那么,写入的新数据如何让读取端感知并更新排行榜呢?这通过一个通知机制实现。当有新的统计数据写入时,系统会发布一个“数据已更新”的事件。查询端的处理器监听这个事件,然后根据新数据更新缓存中的排行榜模型。
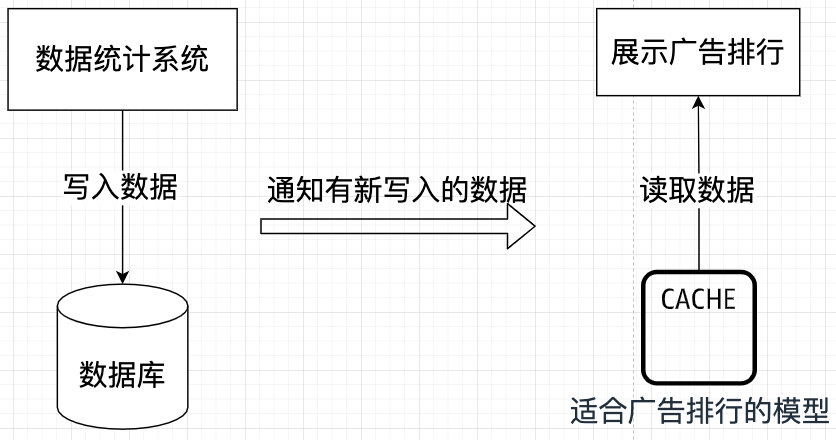
至此,一个完整的 CQRS 闭环形成了:写入高效且纯粹,读取迅速且直接,两者通过异步事件松耦合地协作。
冷静反思:CQRS 的代价与陷阱
在巨大的兴奋之余,我强迫自己冷静下来。任何技术选择都有其代价。在仅剩一周上线的时间里,我花了宝贵的两天做了一个“探针”式实验,快速实现两个功能来验证 CQRS。
实验结果证实了我的担忧:CQRS 会显著增加系统复杂度。读写模型分离意味着开发工作量几乎翻倍。更重要的是,为了最大化性能优势,不同的查询场景可能需要不同的读取模型(缓存、搜索引擎索引等),这会引入多种中间件,带来巨大的运维和认知负担。
最终,我做出了一个保守但稳妥的决定:仅在广告排行榜这个性能瓶颈最严重的核心功能上应用 CQRS。对于其他性能问题,我选择接受,因为它们很大程度上源于我们自身的“过度设计”。
结局与启示:过度复杂化的败局
戏剧性的是,内部竞争的结果恰恰印证了我的担忧。我的竞争对手,在架构上激进地全面采用了 CQRS,为大量功能引入了多种中间件来实现读写分离。这导致了灾难性的后果:系统复杂性失控。
最致命的问题是数据一致性的管理。在异步事件驱动的架构中,读取端更新缓存后,命令端可能因各种原因最终写入失败。这导致了用户看到的数据(来自读取缓存)与真实持久化的数据不一致,例如看到的点击量“回滚”减少。
这类问题定位困难、修复缓慢,最终导致客户流失,竞争失败。
这次经历是一次深刻的架构实战教育。CQRS 是一个强大的模式,能优雅地解决特定场景下的性能难题,但它绝非银弹。其引入的架构复杂度和最终一致性挑战,需要团队具备更高的设计和运维能力。它更像是一把锋利的手术刀,适用于对特定“读写性能不对称”痼疾的精准手术,而不是一套可以随意挥舞的“组合拳”。
技术的选型与应用,始终需要在收益与成本、先进性与复杂性之间做出审慎权衡。如果你也在探索分布式系统与高性能架构的平衡之道,欢迎来 云栈社区 与更多开发者交流心得。
 发表于 2026-4-5 06:22:12
|
查看: 93|
回复: 0
发表于 2026-4-5 06:22:12
|
查看: 93|
回复: 0
