排查Java应用中的内存问题,例如内存泄漏(Memory Leak)与内存溢出(OutOfMemoryError),即使对经验丰富的开发者而言也颇具挑战。本文将分享一系列实用的技巧、工具与方法论,帮助开发人员,尤其是初学者,能够快速定位并有效解决这类内存顽疾。
内存泄漏的常见迹象与预警信号
在应用最终抛出致命的内存溢出错误之前,通常会释放出一些预警信号。及早识别这些信号,是避免服务宕机、保障用户体验的关键。
1. 堆内存使用量持续攀升
你是否观察到,即使在垃圾回收(GC)之后,应用的堆内存使用率仍在缓慢但持续地增长?在一个健康的应用中,内存使用会呈现“锯齿状”波动。但如果内存曲线在每次GC后都无法回落到之前的低点,反而不断抬高基线,这通常是内存泄漏的典型迹象。最终,完全垃圾回收(Full GC)可能变得更加频繁,但每次回收释放的内存却微乎其微——这表明本该被回收的对象仍在被持续引用。
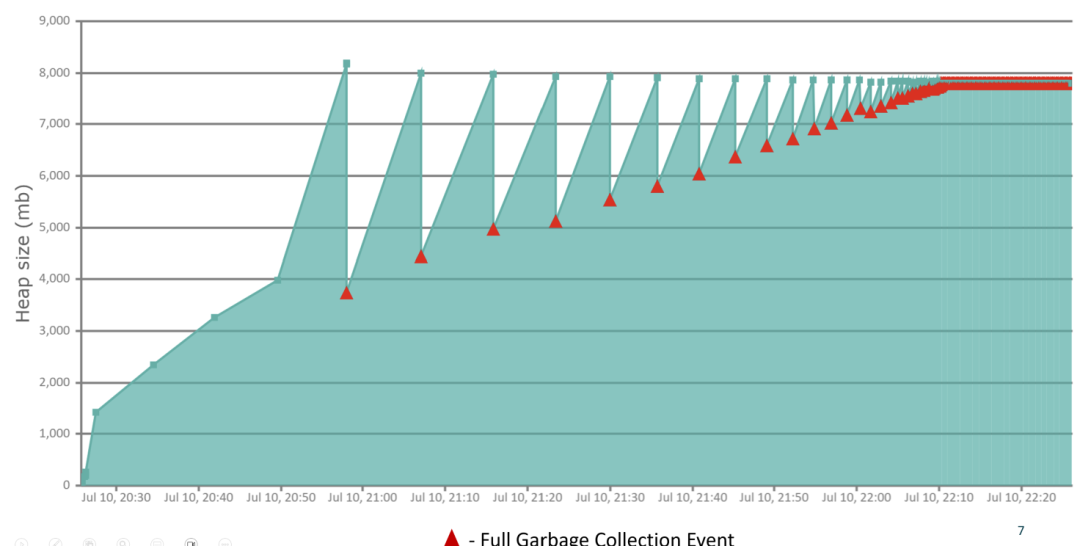 (图1:存在内存泄漏应用的GC行为,堆使用基线持续上升)
(图1:存在内存泄漏应用的GC行为,堆使用基线持续上升)
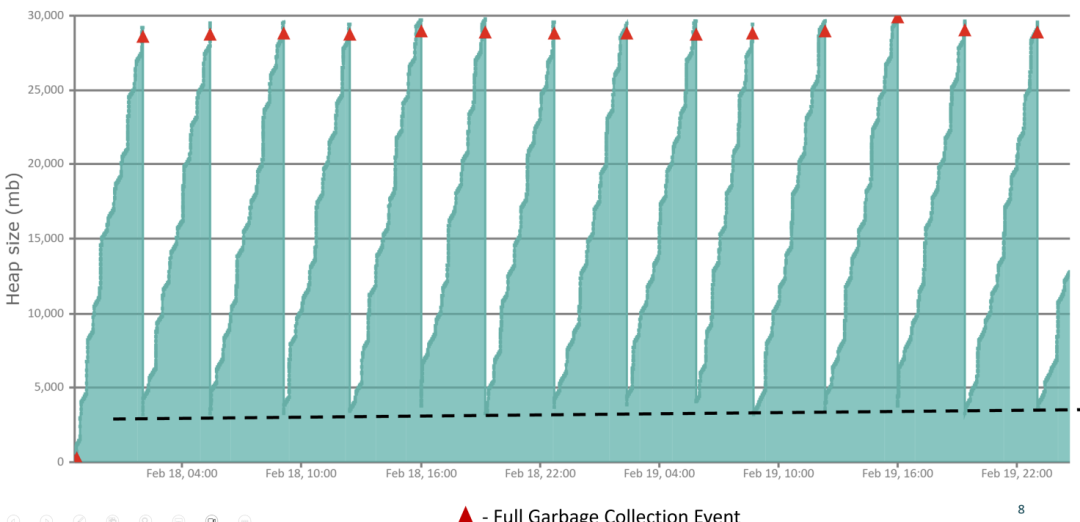 (图2:健康应用的GC行为,堆内存使用率呈稳定锯齿状波动)
(图2:健康应用的GC行为,堆内存使用率呈稳定锯齿状波动)
对于SRE(站点可靠性工程师)角色,核心目标是发现这类异常模式并告警。而对于Java研发人员,则需要深入代码层面进行根因分析。
2. CPU使用率异常飙升
应用的CPU占用率是否会在无明显业务压力时突然飙升?当内存泄漏发生时,Java虚拟机(JVM)会越来越频繁地触发垃圾回收以试图释放空间。GC是一个CPU密集型的过程,需要扫描内存、标记并清理对象。这种额外的开销会导致CPU使用率急剧上升,在某些情况下甚至可能达到100%。
3. 响应时间延迟与请求超时
如果应用突然变慢或开始出现超时,频繁且漫长的垃圾回收暂停(GC Pause)很可能是罪魁祸首。在GC执行期间,应用线程会被挂起(Stop-The-World),这将直接导致事务延迟、健康检查失败乃至用户请求超时。此时应用虽未完全崩溃,但已基本丧失可用性。
4. 内存溢出错误(OutOfMemoryError)
当堆内存被彻底耗尽,且JVM经过努力仍无法回收到足够空间时,便会抛出OutOfMemoryError。一旦出现此错误,通常已无法避免对应用造成严重影响。OOM错误会被记录在应用日志中,也可通过系统命令查找线索:
grep -i "out of memory" /var/log/syslog
grep -i "out of memory" /var/log/messages
# 或使用 dmesg
dmesg -T | grep -i "out of memory"
如果遇到上述任何一种情况,就需要启动深入的内存问题排查流程。
通过分析堆转储(Heap Dump)定位内存泄漏
隔离内存泄漏的根源常常被复杂化,但在大多数业务应用中,遵循以下三个核心步骤便能高效定位问题。
1. 利用工具自动检测泄漏
现代堆转储分析工具(如MAT, JProfiler, HeapHero)内置了智能检测算法,能够自动识别潜在的内存泄漏点,并在分析报告顶部醒目提示。
 (图:HeapHero工具的自动内存泄漏检测报告)
(图:HeapHero工具的自动内存泄漏检测报告)
报告中的每个问题通常都包含详细链接,点击后可进一步查看:是哪些对象发生了泄漏、它们占用了多少内存、以及是哪些引用链(Reference Chain)维持了这些对象的存活。这极大地简化了初步排查工作。
2. 分析支配树(Dominator Tree)
支配树视图列出了堆中占据最大内存块的对象。由于泄漏对象往往无法被回收且持续累积,它们通常会出现在列表的顶端。你可以通过查看这些“支配者”的“传入引用”(Incoming References)来追溯是谁持有着它们,也可以通过“传出引用”(Outgoing References)查看其内部结构,有时泄露对象内部包含的业务数据(如SQL语句、用户ID)能直接指向问题根源。
3. 对比不同时间点的类直方图
这是动态分析的有效方法。在应用运行期间(建议在相似负载条件下),间隔性地获取2-3个堆转储快照。然后对比这些快照的类直方图(Class Histogram),观察哪些类的对象实例数量在持续增长。在所有快照中数量只增不减的类,是内存泄漏的高嫌疑对象。
重要提示:务必确保对比的快照采集自相似的负载场景(例如,同一次压力测试的不同阶段,或生产环境流量平稳的相同时段)。否则,可能将正常的业务增长误判为内存泄漏。
识别问题后的修复与验证步骤
定位问题只是成功了一半,安全地修复并验证修复效果同样至关重要。
1. 根因分析与隔离
综合利用支配树、类直方图和GC根路径(GC Root Path)分析,精确锁定内存问题的根本原因。明确问题究竟源于何处:是未设置上限的缓存、未注销的事件监听器、ThreadLocal使用不当,还是不当的静态引用?只有准确理解对象为何被长期持有,才能制定正确的修复方案。
2. 在测试环境复现问题
如果条件允许,尝试在预发布环境或本地开发环境中,通过模拟相似流量或执行特定测试用例来复现内存泄漏。这为安全地验证修复方案提供了沙箱环境,避免将未经验证的代码直接部署上线。
3. 实施代码或配置修复
根据根因分析结果,对代码或配置进行针对性修改。常见的修复模式包括:
- 为缓存设置合理的容量上限与淘汰策略(如LRU)
- 清理无用的静态集合或字段引用
- 确保在对象生命周期结束时注销监听器、关闭连接
- 避免在长期存活的会话(Session)或全局集合中持有大对象
- 重构设计不佳的单例(Singleton)实现
4. 验证修复效果
应用修复后,在相同的负载模式下重新运行应用,并采集新的堆转储快照。将新快照与修复前的“问题”快照进行对比,检查是否出现积极变化:可疑类的对象实例数是否减少?其占用的总内存是否下降?之前自动检测报告中的泄漏问题是否消失?
5. 生产环境监控与观察
将修复方案部署到生产环境后,需要持续监控一段时间以确认其长期有效性。重点关注关键指标的变化趋势:堆内存使用是否恢复稳定锯齿状?Full GC频率是否显著降低?应用的平均响应时间是否改善?通过运维监控体系持续跟踪,是确保问题被彻底解决的最终环节。
结语
内存泄漏与内存溢出错误如同悄无声息的“资源黑洞”,会逐渐蚕食应用性能,最终导致服务停滞。掌握堆转储分析这一利器,你能够系统性地定位问题根源,理解内存的滞留点,并采取有效措施修复问题,从而保障Java应用的长期稳定与高效运行。
 发表于 2025-12-11 03:18:47
|
查看: 250|
回复: 0
发表于 2025-12-11 03:18:47
|
查看: 250|
回复: 0
