
AI芯片市场的格局正在发生深刻变化。Google近期正式发布并开始对外供应其第七代张量处理单元(TPU)Ironwood,而AI公司Anthropic为训练下一代Claude模型,已预订了高达100万颗。这不仅是一笔巨额订单,更预示着AI基础设施领域的竞争进入了一个新阶段。
Ironwood TPU 的核心性能突破
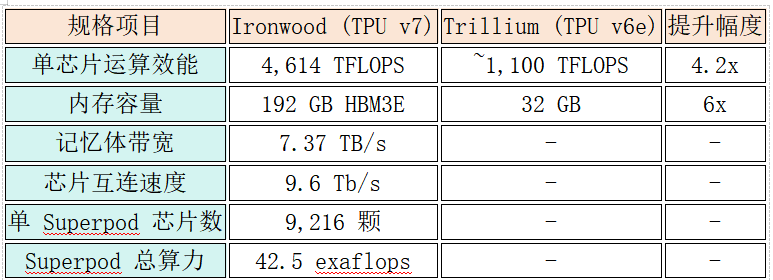
与上一代TPU v6e(代号Trillium)相比,Ironwood的单芯片性能提升了4倍以上。若与TPU v5p对比,其峰值性能更是实现了高达10倍的飞跃。具体来看,每颗Ironwood可提供4,614 TFLOPS的FP8计算能力,并配备了192GB的HBM3E内存,内存容量是Trillium的6倍。
这些硬件指标的跃升对实际 AI模型训练 意义重大。在训练大型语言模型时,内存容量决定了能同时处理的参数规模,而计算能力则直接影响每个训练周期的速度。Ironwood在这两个关键维度上都设立了新的标杆。
Ironwood 核心规格一览
此外,Ironwood采用的先进液冷技术值得关注。在处理超大规模AI工作负载时,该方案能提供比传统风冷高出近2倍的持续性能,这对于控制训练时间和运营成本至关重要。
从AlphaGo到Claude:Google的TPU演进之路
Google对TPU技术的投资始于2015年,这使其在AI算力上实现了重要的垂直整合。分析师估计,使用自研TPU为Google节省了约20%的运营成本,避免了对外部供应商的过度依赖。这种成本优势在动辄数亿美元的AI计算投资中,足以影响竞争格局。

Anthropic的算力豪赌与多云策略
Anthropic计划在2026年前部署这100万颗TPU,总算力将超过1吉瓦(GW),堪比一座中型发电厂的输出功率。这彰显了其服务企业级客户并保持在技术前沿的决心。
值得注意的是,Anthropic采用了灵活的多云策略。其Claude模型同时运行在Google Cloud TPU、Amazon Trainium芯片以及各类GPU上。这种根据工作负载特性选择最优硬件平台的思路,为企业在构建 稳健的云原生基础设施 时提供了重要参考。
TPU挑战GPU霸主的三大优势
当前AI产业虽高度依赖GPU,但TPU正从以下三个方面构成有力挑战:
- 专用化设计的效率优势:作为专门为机器学习设计的ASIC芯片,TPU无需兼顾图形渲染等通用任务,可将全部资源优化用于矩阵运算。报告显示,在部分深度学习应用中,TPU速度比GPU快15-30倍,能效比高出30-80倍。
- 差异化的成本结构:用户通过Google Cloud使用TPU,支付的是服务费用。Google自产自用的模式消除了中间环节,在大规模部署时成本优势明显。
- 成熟的规模化生态系统:Google的Pathways架构可将成千上万颗TPU串联成统一的计算系统。例如,一个由9,216颗Ironwood组成的SuperPod,通过高达9.6 Tb/s的光纤互联,能有效消除数据瓶颈。
Ironwood 与 Nvidia GPU 效能对比分析

关键技术亮点:SparseCore 与 Pathways
Ironwood包含两项关键技术革新:
- 增强版SparseCore:专为处理超大规模嵌入计算而设计的加速器,能高效执行推荐系统、排序算法中的稀疏矩阵运算,对电商、社交等需要实时推荐的应用场景至关重要。
- Pathways架构:由Google DeepMind开发的分布式机器学习执行系统,能像超级协调器一样,确保由数千芯片组成的集群高效协同工作,最大化资源利用率。

对企业的决策启示
Ironwood的出现促使企业在规划AI基础设施时需重新评估:
- 推动供应商多元化:避免过度依赖单一硬件供应商,可借鉴混合策略以分散风险并优化性能。
- 全面评估总体拥有成本(TCO):除了硬件采购价,更应计算运营、能耗、散热等全生命周期成本。
- 匹配工作负载特性:对于专注于大模型训练和推理的场景,TPU可能是更优解;若需支持多样化的AI应用,GPU的通用性仍有其价值。
结论:多元化竞争的产业未来
Ironwood的发布标志着AI算力竞赛进入新阶段。当专用加速器的性能足以比肩顶级GPU时,市场的焦点将从“有无替代”转向“何者更优”。这种竞争将推动技术创新与成本下降,最终让更多企业能够负担得起AI应用的开发与部署。
然而,GPU凭借其成熟的CUDA生态、开发者社区和工具链,建立的软实力优势短期内依然显著。未来的AI计算生态将是多元化的,TPU、Trainium以及其他AI专用芯片都将在其中找到自己的定位。
对于考虑采用TPU的企业,建议采取审慎策略:从小规模试验开始,在Google Cloud上实际测试自身工作负载的性能表现;综合评估团队学习成本、工具链支持等非硬件因素;最终根据不同的应用场景,构建一个灵活、高效且成本可控的混合算力平台。 |  发表于 2025-12-11 03:20:44
|
查看: 238|
回复: 0
发表于 2025-12-11 03:20:44
|
查看: 238|
回复: 0
