最近,OpenClaw(因其图标常被戏称为“龙虾”)在开发者社区中迅速走红。许多朋友跟风部署,却惊讶地发现,仅仅运行一晚的自动化任务,后台便显示消耗了数千万Token,有的甚至直接耗尽了API额度。要想理解这一现象,我们得先从一个更基础的问题入手:在大模型时代,Token到底是什么?
一、用大白话理解Token:AI语言的“乐高积木”
先抛开复杂术语,用最直白的语言解释:当我们与AI聊天或让它执行任务时,AI并不能直接“看懂”完整的句子。它需要先将我们输入的文字、要求处理的内容,切分成一个个“最小的有意义片段”,这些片段就是Token。
这个过程,就像用乐高积木搭建复杂造型,再宏伟的建筑也源于一块块基础积木的组合。Token就是AI处理人类语言的“乐高积木”。
这里需要简单了解大模型的基本工作原理,否则很难理解Token的价值。所谓大模型,就是一个能够理解、生成人类语言,并能执行复杂任务的“智能大脑”,例如ChatGPT、Kimi、通义千问,以及OpenClaw背后调用的各类模型。但这个“大脑”有一个特点:它不认识完整的字词,只能识别被拆分后的Token。
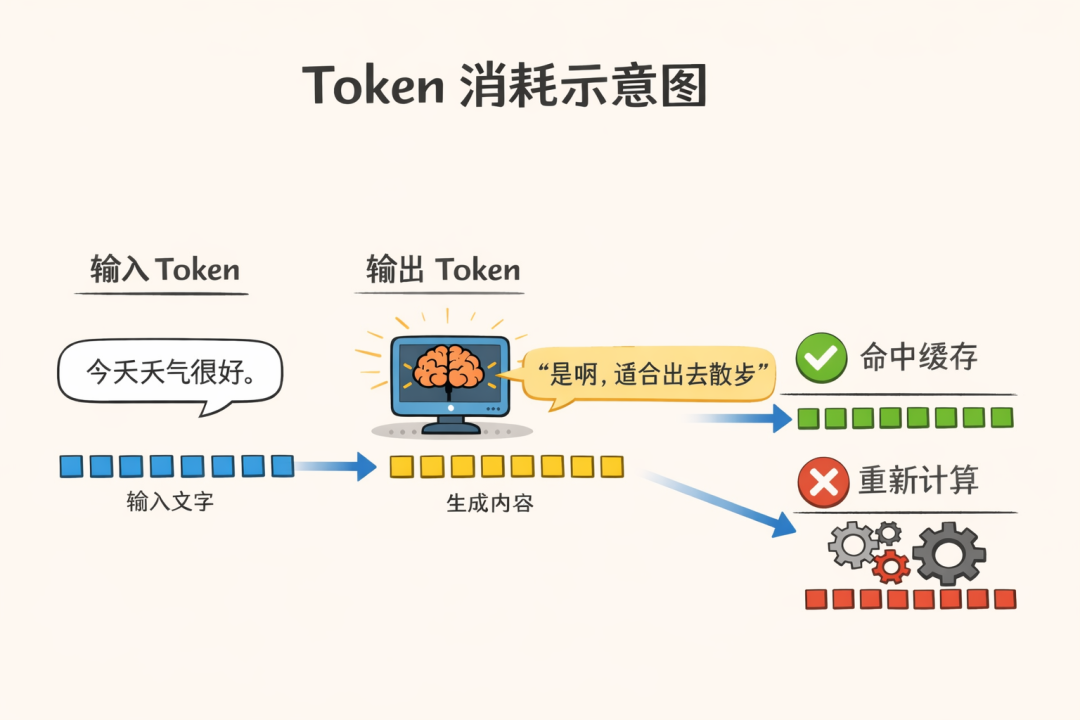
例如,中文句子“今天天气真好”,可能会被拆分成“今”、“天”、“天”、“气”、“真”、“好”六个Token。英文单词“unhappiness”,则可能被拆分为“un”、“happi”、“ness”三个Token。标点符号、空格甚至Emoji表情,都可能被视为一个独立的Token。
二、核心概念拆解:输入Token、输出Token与缓存命中
更形象地说,Token相当于驱动AI运转的“数据流量”。你让AI做的任何事情,都需要消耗这种“流量”。这就引出了几个关键概念:输入Token、输出Token和缓存命中。我们来逐一解释,力求一听就懂。
1. 输入Token与输出Token
这是Token消耗的两大基本来源,也是最容易理解的。
- 输入Token:指你发送给AI的所有内容。例如,你向OpenClaw发出的指令“爬取某平台100条商品数据并整理成表格”、粘贴给它的参考链接、交互过程中的每一句话,都属于输入Token。这相当于你给AI“发送消息”,消耗你的“流量”。
- 输出Token:指AI反馈给你的所有内容。例如,它完成任务后生成的表格、执行过程中的状态提示(如“正在爬取第35条数据”)、遇到问题时的报错信息,这些由AI生成的内容都属于输出Token。这相当于AI“回复消息”,同样要消耗“流量”。通常,生成输出Token的计算量比识别输入Token更大,因此输出Token的消耗往往更高,成本也更大。
2. 缓存命中
这是优化Token消耗、实现“省流量”的关键技巧,类似于手机缓存图片视频以减少重复下载。
简单来说,AI会将你之前执行过的任务、输入的内容、生成的结果临时存储起来,形成一个缓存。当你再次执行相同或高度相似的任务时,AI不必重新进行完整的计算和内容生成,而是直接从缓存中调用之前的结果,这个过程就是缓存命中。
缓存命中时,AI几乎不消耗或只消耗极少的新Token。反之,若未命中缓存,AI就需要从头开始处理,Token消耗便会大幅增加。
举个例子,在OpenClaw的应用场景中:你让它爬取某个固定网页的内容,第一次爬取会消耗大量Token;如果半小时后,你再次让它爬取同一个(且内容未更新的)网页,AI很可能触发缓存命中,消耗极少的Token。然而,OpenClaw的任务多数是动态的,例如爬取不同的商品、分析不同时段的日志,这使得缓存命中的概率较低,这也是它显得“费Token”的一个原因。
三、核心问题:为何OpenClaw如此消耗Token?
OpenClaw的高Token消耗,与其产品定位密切相关。它不同于我们日常使用的豆包、千问这类“一问一答”的对话式AI,而是一个能够自主工作的“数字员工”。你只需下达一个宏观指令,它便会自行拆解任务、一步步执行,而每一步操作都在持续消耗Token。
让我们通过一个更具体、有代入感的例子来说明,这比抽象地讲“整理文档”直观得多:
假设你是一名自媒体从业者,给OpenClaw下达指令:“爬取某平台100条同领域爆款笔记,提取标题、点赞数、核心文案,筛选出点赞1万+的内容,再按文案风格分类整理成表格,最后生成一份爆款规律分析报告。”
这个看似单一的指令,背后被拆解出的步骤远超想象:
- 理解与拆解:OpenClaw首先需要理解你的需求,并将其拆解为“爬取数据 → 筛选数据 → 分类整理 → 生成分析”等多个子任务。这一步就需要消耗输入和输出Token。
- 执行与交互:它需要模拟打开浏览器,逐一访问那100条笔记,每访问一条就提取信息。如果遇到网页加载失败,可能还需重试。每一次页面访问、每一次信息提取,都需要与背后的大模型进行交互,持续消耗Token。
- 处理与判断:接着,它要筛选出点赞数超过1万的内容,并对比每条笔记的文案风格进行分类。每一次筛选、每一次分类判断,都在消耗Token。
- 生成与输出:最后,生成包含所有结果的表格和分析报告。表格里的每一行数据、报告中的每一句话,都是实打实的输出Token。
关键在于,OpenClaw的工作模式是“自主循环”的。只要任务未完成,它就会一直运行,中间不会停顿。上述这个任务全程可能需要跑2-3小时,在这段时间里,每一秒它都可能在与大模型交互,每一次交互都在消耗Token。如果你再让它同时执行另一个平台的数据爬取,多任务并行之下,Token消耗直接翻倍。
对比我们常用的AI聊天工具就非常明显:你问“如何写一篇爆款笔记?”,AI给你一个回复,对话结束,Token消耗随即停止,一次可能只需几千Token。但OpenClaw是“全天候在岗”。例如,你让它通宵分析服务器日志,它会持续循环执行“读取日志 → 分析内容 → 标记异常 → 保存结果”的流程。一晚上下来,消耗数千万Token也就不足为奇了。
四、Token消耗的成本账:到底有多“费”?
Token是大模型处理信息的基本单位,是AI做事的“流量”成本。OpenClaw的高消耗,根源在于其作为智能体(AI Agent)需要持续、自主地执行复杂任务链。理解了原理,我们再来算算经济账,看看它到底有多“费”,尤其是对比不同模型时,差距惊人。
目前主流大模型的Token计费标准差异巨大。我们重点对比两款常用于此类任务的模型——国产的DeepSeek最新版和海外Anthropic的Claude Sonnet 4.6模型,并且主要关注输出Token的成本(因为OpenClaw主要消耗输出Token):
- DeepSeek:输出Token,每百万个约 2元人民币。
- Claude Sonnet 4.6:输出Token,每百万个约 15美元。按当前汇率(1美元≈6.9元人民币)折算,相当于每百万个约 103.5元人民币。
让我们以“一晚上消耗3000万输出Token”这个典型场景来计算:
- 使用DeepSeek,费用为:
3000万 ÷ 100万 × 2元 = 60元。
- 使用Claude Sonnet 4.6,费用为:
3000万 ÷ 100万 × 103.5元 = 3105元。
同样运行一晚上的任务,两者费用相差超过50倍! 这还仅仅是一晚的消耗。如果任务需要连续运行数日,使用Claude模型的成本轻松破万,而即使使用DeepSeek,累积下来也可能达到数百元。这直观地说明了为什么选择合适的模型对于控制AI应用成本至关重要。
写在最后
Token并非神秘概念,它只是大模型处理文本的计量尺。费用高低,完全取决于你“投喂”给模型的数据量、任务步骤的复杂度和持续运行的时间。
OpenClaw等智能体工具能力强大,能将我们从繁琐重复的工作中解放出来,但它绝非“免费的劳动力”。用好了,它是提升效率的神器;用不好,则可能成为吞噬预算的“碎钞机”。只有真正理解Token的运行机制和成本构成,才能在享受技术红利的同时,做到精打细算,实现效率与成本的最佳平衡。对于更多类似的开发实践与成本优化讨论,欢迎关注云栈社区的相关板块。
 发表于 2026-3-14 06:07:05
|
查看: 182|
回复: 0
发表于 2026-3-14 06:07:05
|
查看: 182|
回复: 0
