做后端的开发者几乎每天都在和 JSON 打交道,但你是否曾深入思考过,为何在高并发、低延迟的苛刻场景里,技术选型会纷纷转向 Protobuf?今天,我们就从 C++ 的底层视角,彻底讲清楚 Protobuf 更快的根本原因。

格式本质差异:文本 vs 二进制
JSON 是一种自描述的、人类可读的文本格式,其设计首要目标是可读性与跨语言兼容性。而 Protobuf 是一种基于静态 Schema 的紧凑二进制格式。这种根本性的差异,直接决定了它们在性能上的不同表现:体积与解析速度。
实际测试数据表明,在小、中、大三种规模的数据集上,Protobuf 序列化后的体积通常仅为 JSON 的 1/3 到 1/5,同时其序列化与反序列化的耗时也实现了大幅降低。
Protobuf 数据体积为何能大幅压缩?
1. 抛弃字符串字段名,改用 Tag 机制
JSON 在每次传输时都必须重复传送字段名称字符串,例如 “user_id”: 123。而 Protobuf 在定义消息结构(.proto文件)时就为每个字段分配了唯一的数字编号。传输时,它只传递这个编号与字段类型的组合体,即一个紧凑的 Tag,其计算公式为 (field_number << 3) | wire_type。接收方凭借事先约定好的静态 Schema,就能准确地将数据还原。这彻底消除了冗余的字符串字段名开销。
2. 变长整数编码 Base128 Varints
在 JSON 中,数字 123456 被存储为 ASCII 字符串 "123456",占用 6 个字节。Protobuf 采用 Varints 编码,核心思想是:每个字节的最高位(Most Significant Bit, MSB)作为标志位,1 表示后续字节仍属于当前数字,0 表示结束;剩余的 7 位用于存储有效数据位。因此,像 1、300 这样的小数字通常只需 1 到 2 个字节即可表示,显著节省了空间。
3. 负数的 ZigZag 编码
对于负数,如果直接用 Varints 编码其补码表示,由于补码高位全是 1,会导致固定占用较多字节(例如 int32 的 -1 会占满 5 字节)。Protobuf 采用 ZigZag 编码巧妙地解决了这个问题:它将有符号整数映射到一个无符号整数序列(映射公式为 (n << 1) ^ (n >> 31)),使得绝对值小的数字(无论正负)映射后值也小,再用 Varints 编码就会非常紧凑。例如,-5 经过 ZigZag 映射后,只需 2 个字节就能表示。
4. 紧凑的 TLV 结构
对于字符串、字节数组或嵌套消息这类长度不固定的数据(wire_type=2),Protobuf 采用 Tag-Length-Value 结构。先是一个 Tag 字节定位字段,接着是一个 Length(同样用 Varint 编码)标记后续 Value 的字节长度,最后是 Value 数据本身。这种结构无需依赖引号、逗号等分隔符,结构紧凑且解析时边界清晰。
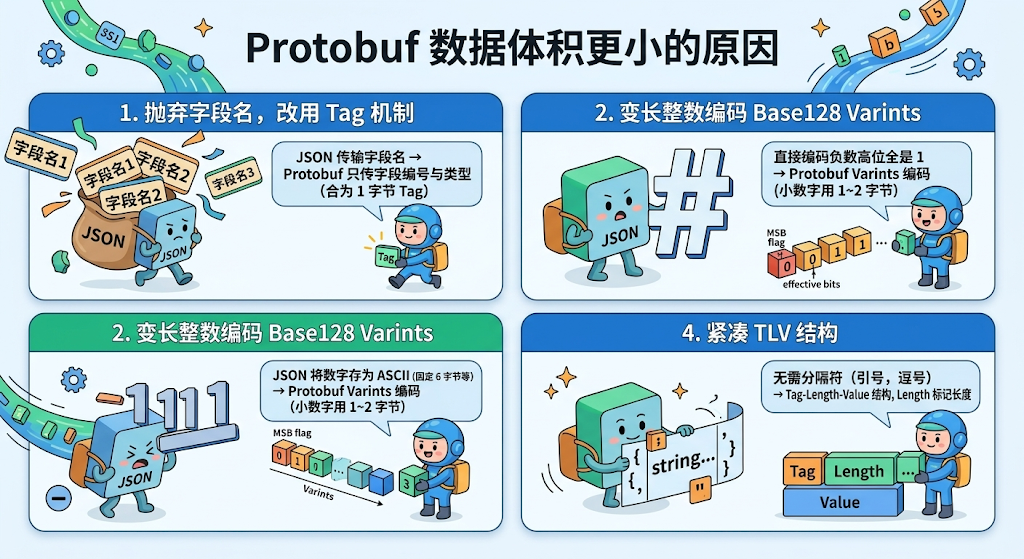
图示:Protobuf通过Tag机制、变长编码和紧凑TLV结构实现更小的数据体积。
解析速度为何快如闪电?
1. 避免了复杂的词法分析与语法分析
JSON 的解析是一个典型的文本解析过程:需要逐个字符扫描,识别 {、}、“ 等分隔符,构建抽象的语法树(AST),提取键名字符串,再将数字字符串动态转换为整数或浮点数。这个过程涉及大量分支判断和内存分配。反观 Protobuf 的解析,由于是二进制格式且有清晰的 TLV 结构,过程极其直接:读取 Tag,通过位运算解析出字段编号和类型;如果是变长类型,再读取 Length;最后根据长度,将后续的 Value 字节流直接复制(memcpy)或映射到预分配的内存地址中。整个过程没有字符串解析和动态类型推断的开销。
2. 静态类型与 C++ 代码强绑定
JSON 反序列化时,为了找到 “user_id” 对应的值,通常需要在解析后的键值对列表中,用 strcmp 等函数进行字符串比对。而 Protobuf 通过 protoc 编译器在编译期就生成了与 .proto 定义完全对应的、强类型的 C++ 类(.pb.cc/.pb.h 文件)。反序列化时,底层代码通过 switch-case 对字段编号进行快速跳转,直接将二进制数据填入对应的类成员变量(预分配的内存),执行路径极短,几乎没有动态查找和类型转换的成本。
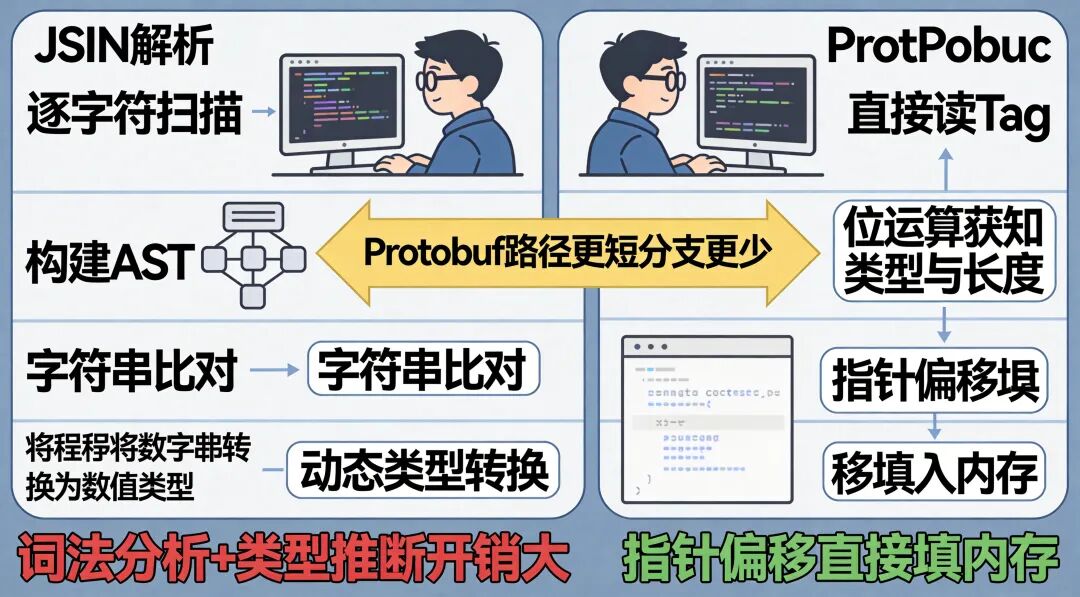
图示:JSON解析需要词法、语法分析和类型转换,而Protobuf解析是直接的指针偏移和内存填充。
实战选型与架构建议
1. 内部 RPC 与微服务:首选 Protobuf
在高并发、对延迟敏感的 RPC(如 gRPC)和微服务内部通信场景中,Protobuf 序列化时延低、体积小的优势能直接转化为更高的系统吞吐量和更低的网络 I/O 压力。你甚至可以在 .proto 文件中使用 option optimize_for = SPEED; 来指示编译器生成性能更高的 C++ 代码。
2. Web API 与前端交互:继续用 JSON
对于需要被浏览器 JavaScript 直接处理、或需要人工查看和调试的对外 API,JSON 的可读性和天然的 Web 兼容性是其不可替代的优势。
3. 架构折中:网关层做双向转换
一种常见的架构模式是使用如 gRPC-Gateway 这样的组件。服务内部微服务之间使用 Protobuf 进行高性能通信,而对外暴露的 RESTful API 则转换为 JSON 格式。这样既享受了内部的性能红利,又兼顾了对外的易用性和可调试性。
总结来说:
- 内部微服务、移动端 App(弱网环境)、海量数据存储:Protobuf 凭借其性能和体积优势,是更优的选择。
- Web API、调试脚本、需要快速迭代和人工干预的场景:JSON 的灵活性和可读性让它依然得心应手。
深入理解这些底层原理,能帮助开发者在不同的技术栈和业务场景下做出更合理的技术选型。如果你对 C++ 高性能编程或类似的技术原理有更多兴趣,欢迎在 云栈社区 与更多开发者交流探讨。
 发表于 2026-4-5 07:27:27
|
查看: 105|
回复: 0
发表于 2026-4-5 07:27:27
|
查看: 105|
回复: 0
