1. 项目功能
这是一个 Web 文件服务器项目,让你能够通过浏览器发送 HTTP 请求,来管理服务器上指定文件夹内的所有文件。它主要支持以下四大功能:
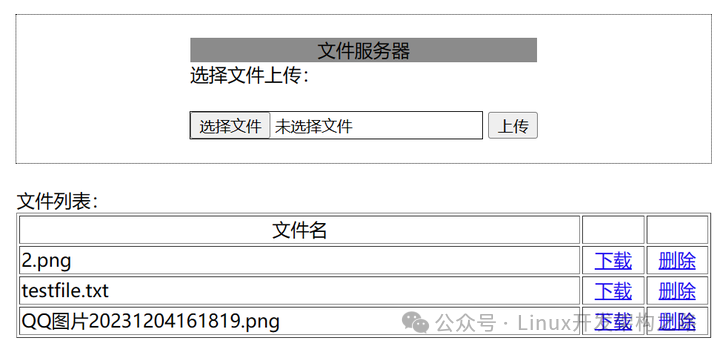
- 以 HTML 页面的形式,清晰地列出该文件夹下的所有文件。
- 你可以通过网页,选择本地文件上传到服务器。
- 对文件列表中的任意文件,点对点执行下载操作。
- 一键删除服务器上不再需要的指定文件。
1.1 功能路由与源码对照
上面四个功能,在 HTTP 请求中具体是如何路由,又对应了哪些处理函数呢?请看下表:
| 功能 |
HTTP 方法 |
URL 路径 |
核心处理函数 |
说明 |
| 文件列表 |
GET |
/ |
HandleSend::getFileListPage() |
读取 filedir/ 目录下所有文件,拼接到 html/filelist.html 模板后返回。 |
| 下载文件 |
GET |
/download/<文件名> |
HandleSend::process() → sendfile() |
打开filedir/<文件名>,使用零拷贝 sendfile() 函数发送。 |
| 删除文件 |
GET |
/delete/<文件名> |
HandleSend::process() → remove() |
调用 remove("filedir/<文件名>") 删除后,返回 302 重定向。 |
| 上传文件 |
POST |
/upload |
HandleRecv::process() |
手写解析 multipart/form-data 的 boundary 和 filename,将文件以二进制流写入 filedir/。 |
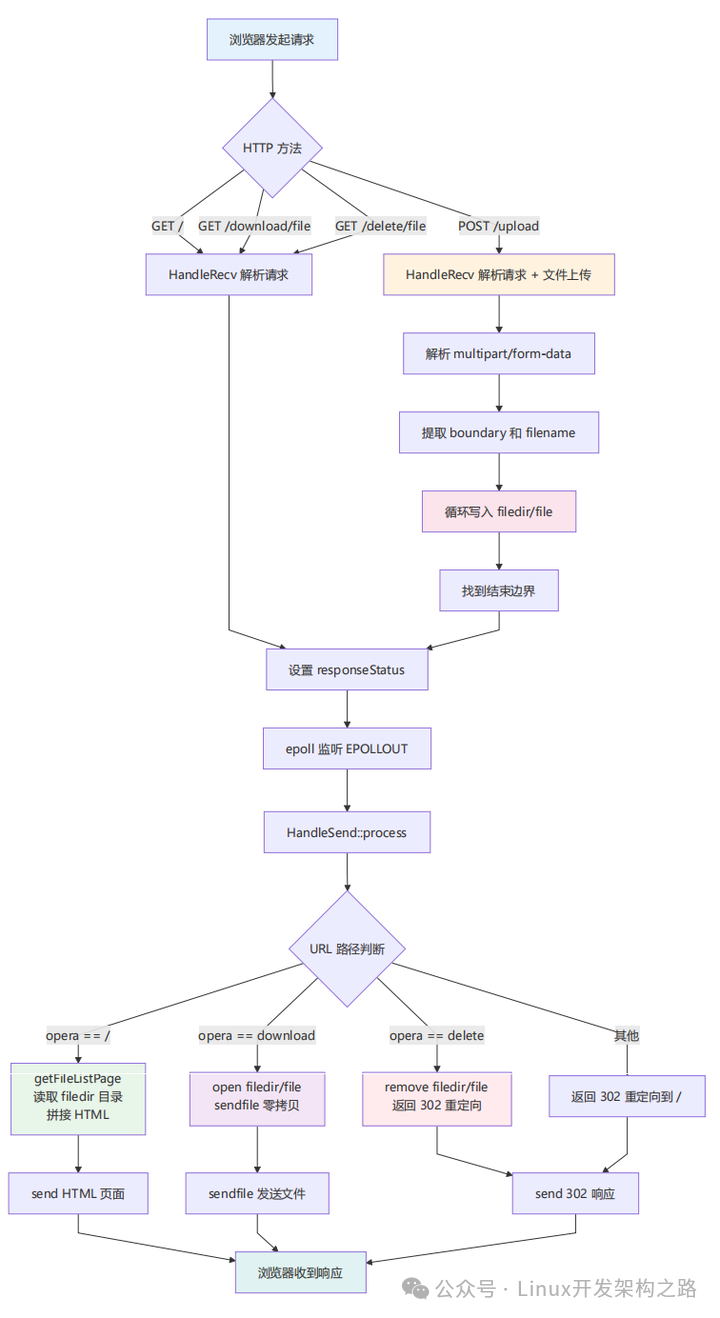
请求处理流程图
这张流程图清晰地展示了从浏览器发起请求到最终收到响应的全过程。你会发现,流程会根据是 GET 还是 POST 请求走向完全不同的分支,最终汇集处理后发回。
源码定位
如果你想深入研究代码,可以从以下两个核心入口开始:
- 请求解析入口:
event/myevent.cpp 的 HandleRecv::process()
- 这里维护了一个有限状态机,严格按照 请求行 → 首部 → 消息体 的步骤推进。如果是文件上传,还会进一步解析
boundary。
- 响应构建入口:
event/myevent.cpp 的 HandleSend::process()
- 根据 URL 路径分支,执行不同操作:
opera == "/" 、 "download" 、 "delete" 、 "redirect"。
两个值得关注的关键位置:
- 零拷贝发送:
event/myevent.cpp:498 行的 sendfile(m_clientFd, responseStatus[m_clientFd].fileMsgFd, ...)。
- 文件上传落盘:
event/myevent.cpp:194 行的 std::ofstream ofs("filedir/" + requestStatus[m_clientFd].recvFileName, ...)。
源码领取: https://www.bilibili.com/video/BV1nJkJB8EP7/
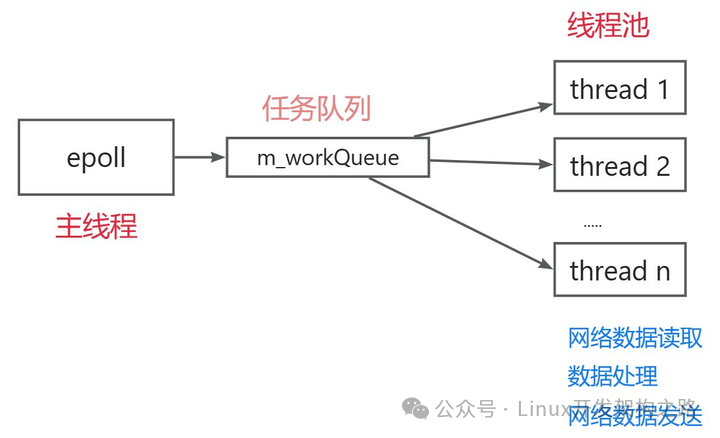
2. 整体框架
这个项目的骨架是经典的 Reactor 事件处理模型,其设计思路如下:
- 统一事件源:主线程利用
epoll 统一监听所有文件描述符(fd)上的事件,然后将具体的逻辑处理任务分发给工作线程。
- 线程池机制:服务启动时预先创建好线程池。当有事件发生时,就将其封装为任务,投递到线程池的任务队列中。工作线程通过信号量+互斥锁的机制,有条不紊地从队列中取出并处理事件。
- HTTP 方法映射:使用 HTTP
GET 方法来获取文件列表、发起下载和删除请求;使用 POST 方法向服务器上传文件。
- 请求解析:服务端采用有限状态机对 HTTP 请求报文进行解析,根据解析结果执行相应操作,最后向客户端发送页面、文件或重定向报文。
- 性能优化:服务端使用
sendfile 系统调用,实现零拷贝数据发送,极大地提升了文件传输性能。
2.1 源码级架构拆解
2.1.1 项目目录结构
项目目录结构干净清晰,各模块职责分明:
WebFileServer/
├── main.cpp # 入口:创建 WebServer、线程池、epoll、启动监听
├── fileserver/ # WebServer 核心类(封装 Reactor 主循环)
│ ├── fileserver.h
│ └── fileserver.cpp # createThreadPool / createEpoll / waitEpoll
├── event/ # 事件对象(AcceptConn / HandleRecv / HandleSend)
│ ├── myevent.h
│ └── myevent.cpp # HTTP 状态机解析、文件上传/下载/删除逻辑
├── threadpool/ # 线程池(pthread + 信号量 + 互斥锁)
│ ├── threadpool.h
│ └── threadpool.cpp # appendEvent / worker / run
├── message/ # 请求/响应消息结构体(Request / Response)
│ └── message.h # 状态机状态枚举、消息首部存储
├── utils/ # 工具函数(epoll 操作、非阻塞设置)
│ ├── utils.h
│ └── utils.cpp # addWaitFd / modifyWaitFd / setNonBlocking
├── html/ # HTML 模板与 CSS
│ ├── filelist.html # 文件列表页面模板
│ ├── fileitem.html # 单个文件项模板(未直接使用)
│ └── styles.css
└── filedir/ # 文件存储目录(上传/下载/删除的文件都在这里)
2.1.2 Reactor 主线程与线程池的调用链
下图完整地描绘了主从 Reactor 模型的架构,左侧是主线程的监听分发逻辑,右侧是工作线程池的事件处理流程。
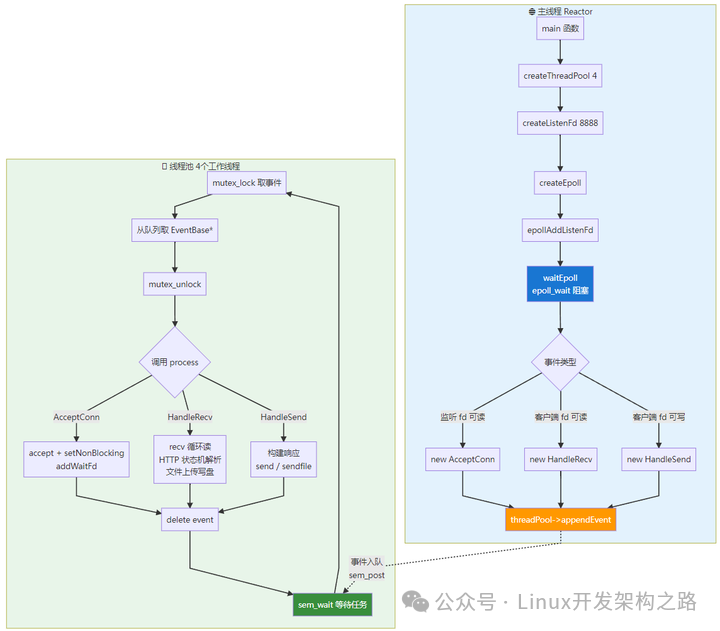
主线程(Reactor):只负责监听与分发
主线程的逻辑很纯粹,就是初始化所有组件,然后进入无限循环,在 epoll_wait 上阻塞,等待事件的发生。
main()
└─> WebServer::createThreadPool(4) // 创建 4 个工作线程
└─> ThreadPool 构造函数
└─> pthread_create(..., worker, this) // 4 个线程调用 worker
└─> ThreadPool::run()
└─> sem_wait(&queueEventNum) ← 工作线程阻塞在此,等待事件
└─> WebServer::createListenFd(8888) // 创建监听套接字,绑定 0.0.0.0:8888
└─> WebServer::createEpoll() // 创建 epoll 实例
└─> WebServer::epollAddListenFd() // 监听 fd 设为 ET + 非阻塞
└─> WebServer::waitEpoll() // ← 主线程阻塞在此
└─> epoll_wait(m_epollfd, resEvents, ...)
├─ 监听 fd 可读 → new AcceptConn(...) → threadPool->appendEvent(event)
├─ 客户端 fd 可读 → new HandleRecv(...) → threadPool->appendEvent(event)
└─ 客户端 fd 可写 → new HandleSend(...) → threadPool->appendEvent(event)
工作线程:执行业务逻辑
工作线程的核心工作,就是在一个循环中,通过信号量等待任务到来,然后调用具体的事件处理对象来干活。
ThreadPool::run() // 工作线程一直循环
└─> sem_wait(&queueEventNum) // 等待事件队列中有新事件
└─> pthread_mutex_lock(&queueLocker) // 加锁取事件
└─> EventBase* curEvent = m_workQueue.front(); m_workQueue.pop();
└─> pthread_mutex_unlock(&queueLocker)
└─> curEvent->process() // ← 调用事件的 process 方法
├─ AcceptConn::process() → accept() + setNonBlocking() + addWaitFd()
├─ HandleRecv::process() → recv() + HTTP 状态机解析 + 文件上传写盘
└─ HandleSend::process() → 构建响应 + send() / sendfile()
└─> delete curEvent; // 事件处理完后销毁
2.1.3 核心类与关键成员
下表梳理了项目中几个核心类及其职责,熟悉它们就能快速把握项目脉络。
| 类名 |
文件 |
核心成员/方法 |
说明 |
WebServer |
fileserver/fileserver.cpp |
waitEpoll() |
Reactor 主循环,调用 epoll_wait 分发事件。 |
ThreadPool |
threadpool/threadpool.cpp |
appendEvent() / run() |
管理者角色,维护事件队列、信号量和一群工作线程。 |
EventBase |
event/myevent.h |
静态成员 requestStatus / responseStatus |
保存每个 fd 的请求/响应状态。这是对 ET+ONESHOT 机制的补充,支持一个请求分多次处理。 |
AcceptConn |
event/myevent.cpp |
process() |
接待员,接受新连接,设置 ET+ONESHOT,并将其纳入 epoll 监听。 |
HandleRecv |
event/myevent.cpp:27 |
process() |
接收员,循环 recv 数据,并驱动状态机解析请求。 |
HandleSend |
event/myevent.cpp:294 |
process() |
发送员,构建并发送响应报文,包括用 sendfile 实现零拷贝。 |
Request |
message/message.h |
recvMsg / status / fileMsgStatus |
一个结构体,用于保存请求解析的全过程状态。 |
Response |
message/message.h |
bodyFileName / bodyType / fileMsgFd |
一个结构体,用于保存响应构建时的各项状态。 |
2.1.4 EPOLLET + EPOLLONESHOT 的使用
项目中 epoll 的标志位设置非常考究,直接关系到模型的正确性和性能:
- 监听 fd:使用
EPOLLET (边沿触发)。这能让它在高并发下避免主线程被重复触发,给工作线程留出时间来处理新连接。
- 客户端 fd:使用
EPOLLET | EPOLLONESHOT。ONESHOT 标志保证了同一个 fd 的事件,在任何时刻都只会被一个线程处理。试想一下,如果没有它,线程 A 正忙着给这个 fd 发数据,线程 B 可能就同时开始处理读事件了,那不乱套了吗?
- 每次事件处理干净后,都需要调用
modifyWaitFd(..., EPOLLONESHOT) 来重置ONESHOT,这样该 fd 之后的事件才能再次触发。
3. 编译和运行
3.1 编译项目
编译过程很简单,执行项目中的构建脚本即可:
./build.sh
注意:虽然默认 Makefile 里带 -g 选项(支持调试),但如果你想获得最精确的调试信息,建议在 -g 后加上 -O0 来彻底关闭编译器优化。
想看一眼 Makefile 内容?它在这儿:
CXX ?= g++
fileserver: main.cpp ./fileserver/fileserver.cpp ./threadpool/threadpool.cpp ./event/myevent.cpp ./utils/utils.cpp
$(CXX) -std=c++11 -g $^ -lpthread -o main
clean:
rm -r main
3.2 启动文件服务器
编译成功后,直接运行生成的可执行文件:
./main
启动后,服务器就开始监听 0.0.0.0 的 8888 端口了(端口号在 main.cpp 中是硬编码的)。控制台会打印类似下面的日志,告诉你一切就绪:
[info] 线程 0 正在执行
[info] 线程 1 正在执行
[info] 线程 2 正在执行
[info] 线程 3 正在执行
[info] epoll 中添加监听套接字成功
3.3 浏览器访问
现在,打开你的浏览器,在地址栏输入 服务端ip:端口号(默认端口 8888):
http://192.168.1.100:8888
如果你在本机上跑,直接用这个:
http://localhost:8888
一个清爽的文件管理页面就会出现在你眼前,上传、下载、删除,尽管去试试吧。
4. 如何快速分析代码
面对一个陌生的 C++ 项目,你会不会感觉无从下手?这里分享一个实用的技巧:按 "入口 → 线程模型 → 数据流" 的顺序,用 GDB 配合最精简的断点集来快速摸清其核心脉络。照着下面的步骤走,大约 30 分钟 你就能拿下它。
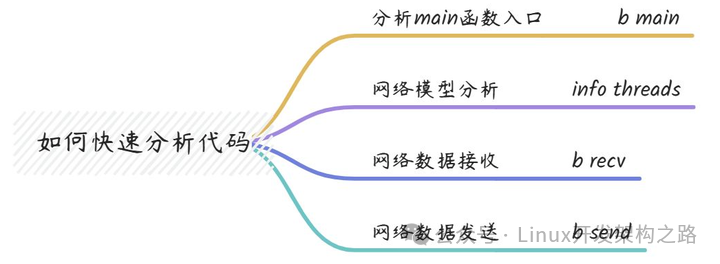
4.1 定位入口:main 函数
万事开头难,程序的开头就是 main 函数。在 GDB 里这么设:
gdb ./main
(gdb) b main
Breakpoint 1 at 0x5555555590ad: file main.cpp, line 3.
(gdb) r
在 main 函数里,整个项目的初始化顺序一目了然:
WebServer webserver;
webserver.createThreadPool(4); // 创建 4 个工作线程
webserver.createListenFd(8888); // 监听 8888 端口
webserver.createEpoll(); // 创建 epoll 实例
webserver.epollAddListenFd(); // 将监听 fd 加入 epoll
webserver.waitEpoll(); // 主线程进入 Reactor 循环
4.2 分析线程模型:验证 Reactor + 线程池
4.2.1 查看线程数量与状态
程序跑起来后,在 GDB 里按 Ctrl+C 暂停它,然后查看所有线程:
(gdb) info threads
输出大概长这样:
* 1 Thread 0x7ffff79a9740 (LWP 339328) "main" 0x00007ffff7c1c68e in epoll_wait (epfd=4, events=0x7fffffffaf14, maxevents=1024, timeout=-1) at ../sysdeps/unix/sysv/linux/epoll_wait.c:30
2 Thread 0x7ffff79a8700 (LWP 339343) "main" futex_abstimed_wait_cancelable ( ) at ../sysdeps/nptl/futex-internal.h:320
3 Thread 0x7ffff71a7700 (LWP 339344) "main" futex_abstimed_wait_cancelable ( ) at ../sysdeps/nptl/futex-internal.h:320
4 Thread 0x7ffff69a6700 (LWP 339345) "main" futex_abstimed_wait_cancelable ( ) at ../sysdeps/nptl/futex-internal.h:320
5 Thread 0x7ffff61a5700 (LWP 339346) "main" futex_abstimed_wait_cancelable ( ) at ../sysdeps/nptl/futex-internal.h:320
从上面我们能得出两个结论:
- 数量对了:总共 5 个线程,正好是 1 个主线程加上我们创建的 4 个工作线程。
- 位置对了:
- 主线程(Thread 1)正阻塞在
epoll_wait,负责事件的监听。
- 工作线程(Thread 2-5)则全部阻塞在
futex_abstimed_wait_cancelable。这其实是 sem_wait(&queueEventNum) 的底层实现,说明它们正在等待任务队列的信号。
这种 "epoll + 线程池" 的经典搭配,正是支撑 后端高并发 服务的基石之一。
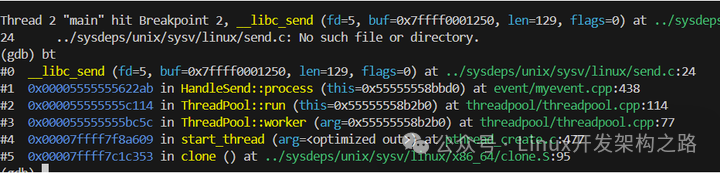
4.2.2 验证工作线程的调用栈
切换到某个工作线程,用 bt 命令看看它到底卡在哪儿:
(gdb) thread 2
(gdb) bt
调用栈清晰地展示了它的“身世”:
#0 futex_abstimed_wait_cancelable (...) at ../sysdeps/nptl/futex-internal.h:320
#1 __sem_wait_common (...) at sem_wait.c:...
#2 0x000055555555c0xx in ThreadPool::run (this=0x55555558b2b0) at threadpool/threadpool.cpp:87
#3 0x000055555555bcxx in ThreadPool::worker (arg=0x55555558b2b0) at threadpool/threadpool.cpp:77
#4 0x00007ffff7f8a609 in start_thread (...) at pthread_create.c:477
#5 0x00007ffff7c1c353 in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:95
你看,和我们的设计完全吻合,工作线程就是在 ThreadPool::run() 里的 sem_wait 上耐心等着呢。
4.3 跟踪数据流:断点 recv 和 send
数据就像血液,在网络应用中流动。我们在关键的 recv和 send 上打断点,观察它的流向。
4.3.1 数据接收:断点 recv
在浏览器里访问 http://localhost:8888,你会立刻触发 GDB 里的断点:
(gdb) b recv
Breakpoint 2 at 0x...
(gdb) c
命中断点后立即查看调用栈:
(gdb) bt
可以看到,recv 确实是在工作线程的上下文中被调用的:
#0 __libc_recv (fd=5, buf=0x7ffff69a5600, len=2048, flags=0) at ../sysdeps/unix/sysv/linux/recv.c:24
#1 0x000055555555df4a in HandleRecv::process (this=0x55555558bb90) at event/myevent.cpp:38
#2 0x000055555555c114 in ThreadPool::run (this=0x55555558b2b0) at threadpool/threadpool.cpp:114
#3 0x000055555555bc5c in ThreadPool::worker (arg=0x55555558b2b0) at threadpool/threadpool.cpp:77
#4 0x00007ffff7f8a609 in start_thread (arg=<optimized out>) at pthread_create.c:477
#5 0x00007ffff7c1c353 in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:95
这证实了:请求的接收和解析,都是在 工作线程 中完成的,主线程完全不参与。
4.3.2 数据发送:断点 send 和 sendfile
分别对 send 和 sendfile 下断点,看看数据是怎么发出去的:
(gdb) b send
Breakpoint 3 at 0x...
(gdb) b sendfile
Breakpoint 4 at 0x...
(gdb) c
当我们访问页面时,会触发 send 断点,调用栈如下:
#0 __libc_send (...)
#1 0x000055555555e2xx in HandleSend::process (this=0x...) at event/myevent.cpp:438
#2 0x000055555555c114 in ThreadPool::run (this=0x...) at threadpool/threadpool.cpp:114
...
当我们点击下载一个文件时,sendfile 断点被触发,调用栈如下:
#0 sendfile64 (out_fd=5, in_fd=6, offset=0x..., count=...)
#1 0x000055555555e3xx in HandleSend::process (this=0x...) at event/myevent.cpp:498
#2 0x000055555555c114 in ThreadPool::run (this=0x...) at threadpool/threadpool.cpp:114
...
这说明两件事:
第一,响应的发送也在 工作线程 中执行。
第二,下载文件时,使用的是 sendfile(),这正是我们的零拷贝优化点。
4.4 验证 HTTP 解析:状态机断点
一个典型的 HTTP 请求报文长这样:
GET /index.html HTTP/1.1 // 请求行
Host: www.example.com // 请求头(键值对)
User-Agent: Mozilla/5.0...
Accept: text/html,application/xhtml+xml
// 空行(分隔头部和主体)
[请求主体] // 可选的请求体(例如 POST 提交的表单数据)
如果你想深入了解 HTTP 请求的解析流程,可以在 HandleRecv::process() 里的状态机关键位置下断点:
(gdb) b event/myevent.cpp:69 # 解析请求行
(gdb) b event/myevent.cpp:85 # 解析首部
(gdb) b event/myevent.cpp:116 # 解析消息体
(gdb) b event/myevent.cpp:133 # 文件上传:解析 multipart/form-data
当程序停下时,用 print requestStatus[m_clientFd] 可以随时窥探当前的解析状态。
4.5 验证文件上传:boundary 解析
想看看文件是怎么被一点点解析并写入磁盘的吗?在上传文件时,把断点设在这里:
(gdb) b event/myevent.cpp:194 # 打开文件准备写入
(gdb) b event/myevent.cpp:245 # 写入文件内容
(gdb) c
在浏览器里上传一个文件,GDB 会立刻让你停下。这时,可以查看一些关键信息:
(gdb) print requestStatus[m_clientFd].recvFileName # 上传的文件名
(gdb) print requestStatus[m_clientFd].fileMsgStatus # 文件解析状态
4.6 快速分析总结
就像侦探破案一样,我们通过五个步骤快速锁定了项目的核心:
main 函数:看初始化的顺序(线程池 → 监听 → epoll → 主循环),把握启动流程。info threads:确认了 Reactor(主线程epoll_wait)+ 线程池(工作线程sem_wait)的模型。- 断点
recv/send/sendfile:证实了数据收发都在工作线程,下载功能使用了零拷贝。
- 状态机断点:理解了 HTTP 解析是按“请求行 → 首部 → 消息体”一步步推进的。
- 文件上传断点:追踪了
multipart/form-data 格式下,boundary 的手工解析和二进制写盘过程。
5. 项目亮点与面试考点
熟悉了基本流程后,让我们来挖一挖这个项目真正的技术含金量。下面这些,都是面试中可能被深挖的高频考点。
5.1 EPOLLET + EPOLLONESHOT 的使用场景
为什么不能“一刀切”,而要对不同 fd 区别对待呢?
- 监听 fd(EPOLLET):用边沿触发,是为了防止在新连接到来时,主线程被重复触发。主线程只需将
AcceptConn 事件入队一次,就可以安心地把后续工作交给线程池,避免了不必要的惊群或重复通知。
- 客户端 fd(EPOLLET + EPOLLONESHOT):这套组合拳打得很妙。
ET 保证了每次数据到来只触发一次,需要我们循环读取直到 EAGAIN,效率很高。ONESHOT 则像一把锁,确保了同一个 fd 的事件在任何时刻只被一个线程处理,从根本上杜绝了并发读写冲突。比如,线程 A 正在给客户端发送一个大文件,此时这个 fd 又变得可读了,幸好有 ONESHOT,主线程不会把这个读事件再分发给另一个线程 B。- 线程处理完手头的事后,必须调用
epoll_ctl(EPOLL_CTL_MOD) 来重置 ONESHOT,相当于把这把锁打开,让该 fd 之后的事件可以再次被触发。
5.2 手写 HTTP 解析:有限状态机
项目没有使用现成的 http-parser 等库,而是徒手撸了一个状态机来解析 HTTP 请求。这让你对 HTTP 协议的理解会更上一层楼。
状态转移(定义在 message/message.h 中):
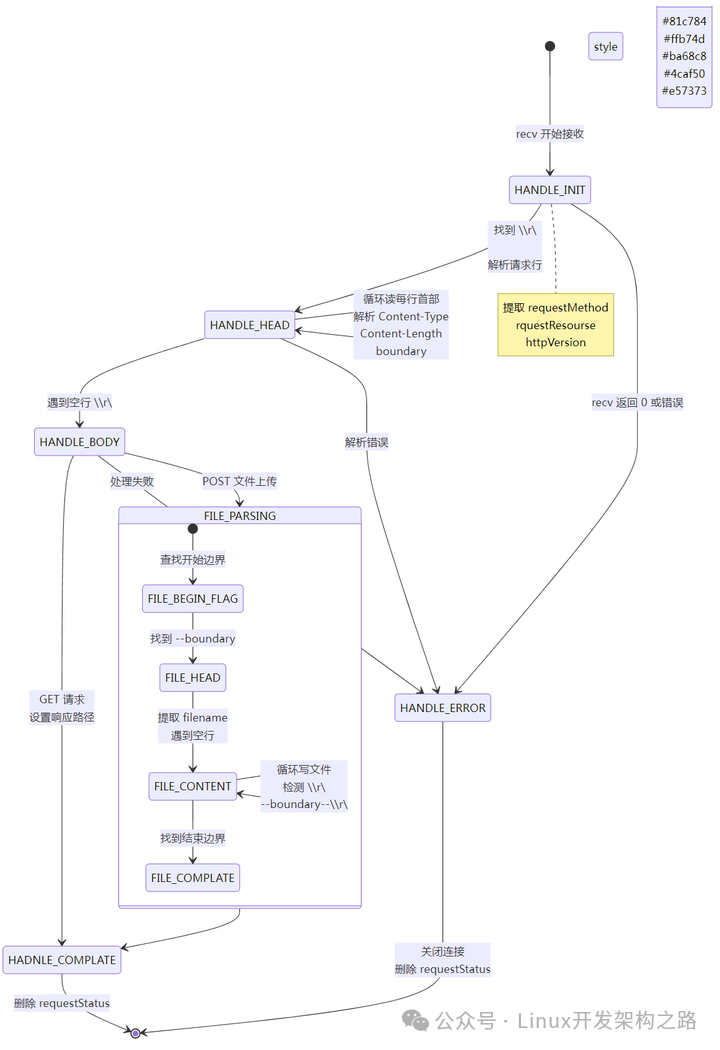
关键点解析:
- 请求行解析(
event/myevent.cpp:69):在一段数据中,高效地查找 \r\n,然后从中提取出 requestMethod、rquestResourse 和 httpVersion。
- 首部解析(
event/myevent.cpp:85):循环读取每一行,解析出我们关心的 Content-Type、Content-Length 和 boundary。
- 消息体解析(
event/myevent.cpp:116):这是状态机最精彩的分支。对于 GET 请求,直接设置好响应路径就完事了;但对于 POST(文件上传),事情就复杂了。它内部会再细分出一个子状态:FILE_BEGIN_FLAG → FILE_HEAD → FILE_CONTENT → FILE_COMPLATE。
“如何解析带文件的表单?”这是后端开发面试里的一个经典问题。一个典型的 multipart/form-data 格式长得像这样:
POST /upload HTTP/1.1
Content-Type: multipart/form-data; boundary=---------------------------24436669372671
Content-Length: 12345
-----------------------------24436669372671
Content-Disposition: form-data; name="upload"; filename="test.txt"
Content-Type: text/plain
文件内容在这里...
-----------------------------24436669372671--
我们的解析流程(event/myevent.cpp:133)是这么做的:
- 查找开始边界:找到
--<boundary> 字符串。
- 解析文件头:从中提取出
Content-Disposition 里的 filename="test.txt"。
- 写入文件内容:这是一个细活儿。程序会循环读取数据,并实时判断即将到来的数据是否属于结束边界
\r\n--<boundary>--\r\n。在遇到边界之前,所有的数据都原封不动地写入 filedir/<filename> 文件里。
- 精确匹配:这里对边界的匹配必须做到零误差,绝不能把文件尾部的边界信息也当成文件内容写进去。
下图清晰地描绘了这个解析流程:
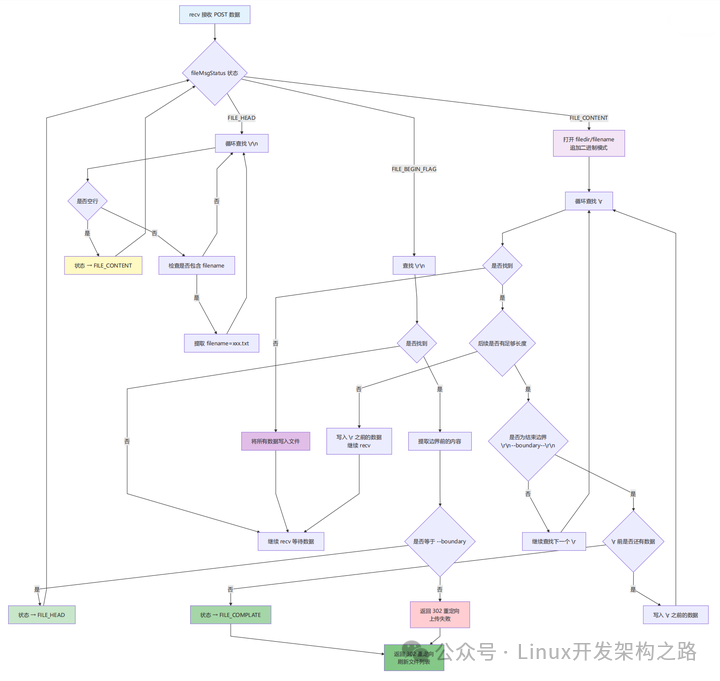
代码实现也非常直白(event/myevent.cpp:194):
std::ofstream ofs("filedir/" + requestStatus[m_clientFd].recvFileName,
std::ios::out | std::ios::app | std::ios::binary);
// 循环写入,直到遇到结束边界
ofs.write(requestStatus[m_clientFd].recvMsg.c_str(), saveLen);
5.4 sendfile 零拷贝:下载文件优化
下载文件时,项目使用的是 sendfile() 这个系统调用(event/myevent.cpp:498):
sentLen = sendfile(m_clientFd, responseStatus[m_clientFd].fileMsgFd,
(off_t *)&sentLen,
responseStatus[m_clientFd].msgBodyLen - sentLen);
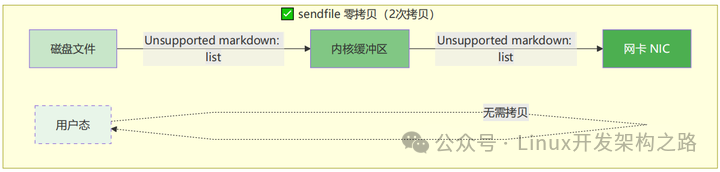
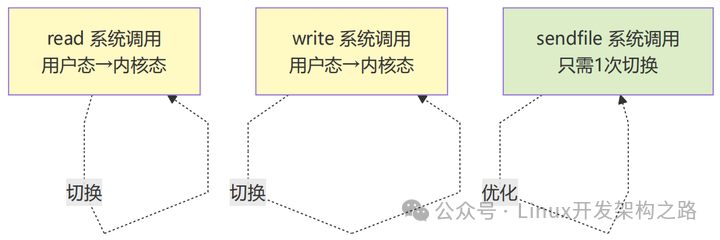
这背后其实是一场I/O性能革命。我们来看看 read + write 和 sendfile 的数据传输路径对比图,就一目了然了:
传统 read + write(4次拷贝)

sendfile 零拷贝(2次拷贝)
上下文切换对比
优势对比:
| 方案 |
拷贝次数 |
用户态拷贝 |
系统调用次数 |
上下文切换 |
read + write |
4 次 |
2 次(内核→用户→内核) |
2 次 |
4 次(每次调用来回切换) |
sendfile |
2 次 |
0 次(数据不经过用户态) |
1 次 |
2 次(进入内核+返回用户态) |
这就是 sendfile 被称为"零拷贝"(Zero-Copy)的原因,它避免了数据在用户态和内核态之间来回搬运,并把两次系统调用和四次上下文切换,优化为一次调用和两次切换,性能提升非常显著。如果面试官顺着这个话题往下问,你可以谈谈 mmap、splice 甚至更底层的 DMA,这会是很好的加分项。
5.5 302 重定向:上传/删除后刷新列表
你有没有留意到,当你上传或删除一个文件后,页面是如何自动刷新文件列表的?这背后是一个 HTTP 重定向的经典应用。
在我们的代码中(event/myevent.cpp:414),处理完操作后,并没有直接返回文件列表的 HTML,而是构建了一个 302 Found 响应:
responseStatus[m_clientFd].beforeBodyMsg = getStatusLine("HTTP/1.1", "302", "Moved Temporarily");
responseStatus[m_clientFd].beforeBodyMsg += getMessageHeader("0", "html", "/", "");
浏览器收到 302 状态码和 Location: / 这个响应头后,会自动向 / 发起一次全新的 GET 请求,效果就是页面自动刷新了,用户操作体验非常流畅。
5.6 静态成员保存状态:支持分多次处理
一个请求或响应,可能因为网络原因或数据量太大,需要多次读写才能完成。为了支持这一点,EventBase 类巧妙地使用了静态(static)成员来保存每个连接的状态:
static std::unordered_map<int, Request> requestStatus; // key 是 fd
static std::unordered_map<int, Response> responseStatus;
这样,每当一个 fd 上的事件再次被触发,工作线程就能通过 fd 作为 key 找到它上次处理到哪里了,然后根据 status 字段继续未完成的工作,直到 HADNLE_COMPLATE 状态才结束。这个设计配合 EPOLLONESHOT,完美地解决了长连接下的大数据量传输问题。
6. 拓展建议
这个项目是一个非常扎实的起点,但如果你想让它成为你简历上的“明星项目”,可以考虑从以下方向进行拓展。
6.1 性能测试与对比
- 迁移到 muduo 库:将本项目的核心功能移植到 muduo 的 Reactor 模型上。muduo 采用的是
one loop per thread,而我们这里是 one loop + threadpool。亲手跑一遍,对比两者的性能差异,这将是一次极具价值的实践。
- 与 nginx 对比:使用
wrk 或 ab 等 HTTP 压力测试工具,在相同环境下对比你的服务器和 nginx 的文件下载 QPS 和延迟。剖析瓶颈在哪里?是 epoll 事件处理的效率、线程池的调度开销,还是 sendfile 的优化空间?有了数据和分析,面试时讲出来会非常有说服力。
- 加入日志系统:当前日志只是简单使用
std::cout,可以把它改为一个异步日志系统(可以参考 muduo 的 LogFile 实现),或者更进一步,将日志发送到一个远程日志服务器上。
6.2 功能扩展
- 用户系统:加入注册和登录功能,用 MySQL 来持久化存储用户信息,为每个用户创建隔离的
filedir/<username>/ 目录。
- 分享链接:提供生成文件分享链接的功能,并支持设置过期时间和访问密码。这背后可以用 Redis 来缓存分享状态。
- 断点续传:实现 HTTP
Range 请求头的解析和支持,让你的文件服务器可以处理大文件的断点下载和上传。
- Socket通信 的增强:引入 WebSocket 协议,实现文件上传进度的实时推送,让用户体验更好。
6.3 简历优化建议
在将项目写入简历时,请务必突出以下技术关键词,它们都是面试官眼中的“闪光点”:
- Reactor 网络模型 (epoll ET + ONESHOT)
- 手写 HTTP 协议解析 (有限状态机)
- 零拷贝优化 (sendfile 系统调用)
- 线程池 (POSIX 信号量 + 互斥锁)
- 性能测试 (与 nginx / muduo 对比,QPS 提升 X%)
如果需要进一步掌握项目细节或 GDB 调试技巧,可以参考:https://www.bilibili.com/video/BV1yBqwYLEwj/
 发表于 2026-5-10 00:32:44
|
查看: 112|
回复: 0
发表于 2026-5-10 00:32:44
|
查看: 112|
回复: 0
