作为有过微博、抖音亿级系统实战经验的开发者,这次面对小红书Java岗关于10万QPS互动系统的面试,更像是一场技术与业务理解的双重挑战。今天,我将以最真实的视角,复盘这场面试的核心交锋,并分享一套经过实战检验的高并发架构方案。
1. 战前准备:理解业务与面试官
公司业务画像
小红书作为内容社区,其互动系统有着鲜明的业务特性:
- 脉冲式流量:爆款笔记(如明星同款、小众攻略)登上推荐后,互动量(点赞、收藏)可能在30分钟内呈指数级增长,形成瞬间的10万QPS洪峰,这与微博、抖音的流量模式均有差异。
- 极高的数据一致性要求:点赞/收藏数直接关联创作者收益与平台推荐权重,用户对此极其敏感,任何数据差错都可能引发信任危机和业务损失。
- 技术栈特点:虽然核心服务多用Go,但Java生态在中台层仍很重要。基础设施上重度依赖Kubernetes、Kafka、Redis Cluster和分库分表的MySQL。
我的思考:小红书的流量具有“社交裂变”特性,这意味着系统设计不仅要扛住第一波冲击,还要为后续可能的传播峰值做好准备。
面试官的预期层次
我预判面试官的考察会分为三层:
- 筛人题:考察基础,如Redis原子操作、消息队列选型。答不好直接出局。
- 定级题:考察架构思维,如分层设计、最终一致性、熔断降级。决定是否能达到高级别。
- 定薪题:考察业务创新与价值创造,如能否结合平台生态提出优化。这关系到能否拿到顶级offer。
他们真正想听的,是如何在保证数据绝对准确的前提下,用最具性价比的方案支撑业务野蛮生长。
2. 实战交锋:问题拆解与高分回答
问题一:设计一个支撑10万QPS的点赞/收藏系统,保证计数准确、不重复、不丢失。
我的破局思路:直接套用“Redis计数+MySQL持久化”是平庸的。我结合在抖音处理明星视频38万点赞/15分钟的真实场景来展开。
-
分层缓冲架构:这是应对脉冲流量的核心。
用户请求 → 网关层限流 → 互动服务集群 →
├─ 实时层:Redis Cluster(分片计数)
├─ 异步层:Kafka(削峰填谷)
└─ 持久层:MySQL分库分表 + 本地事务表
-
热点探测与动态分片:单笔记10万QPS会压垮单个Redis分片(通常支撑3-5万)。需要设计热点分片机制,当监测到某笔记QPS > 5000时,自动将其计数分散到多个Key。
// 热点分片算法示例
func getLikeKey(noteId string, shardCount int) []string {
keys := make([]string, shardCount)
for i := 0; i < shardCount; i++ {
keys[i] = fmt.Sprintf("like:%s:%d", noteId, i)
}
return keys
}
// 写入时随机选择分片
shardIndex := rand.Intn(activeShardCount)
redisClient.IncrBy(fmt.Sprintf("like:%s:%d", noteId, shardIndex), 1)
-
防重复与数据不丢失保障(核心):
- 防重复:采用布隆过滤器(Bloom Filter)+分级存储,替代内存消耗巨大的Redis Set。
- 不丢失:采用“同步写缓存,异步持久化+本地事务表”的双重保障。先在业务数据库中写入本地事务表,保证与发Kafka消息的原子性,再异步消费更新计数。
CREATE TABLE `interaction_transaction` (
`id` bigint NOT NULL AUTO_INCREMENT,
`biz_id` varchar(64) NOT NULL COMMENT '业务ID(uid_noteid)',
`type` tinyint NOT NULL COMMENT '1-点赞 2-收藏',
`status` tinyint DEFAULT '0' COMMENT '0-待处理 1-已处理',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_biz` (`biz_id`, `type`),
KEY `idx_status` (`status`)
) ENGINE=InnoDB;
- 对账补偿:每5分钟运行对账任务,对比Redis计数与MySQL最终计数,自动修复差异。
互动延伸:我主动提问:“小红书是否遇到过因数据不一致导致的创作者投诉?我们曾为高价值笔记(如带货笔记)设计‘数据可信度评分’,优先保证其一致性,对普通笔记可适当放宽实时性,这个思路是否适用?” 这个问题直接命中了业务痛点。
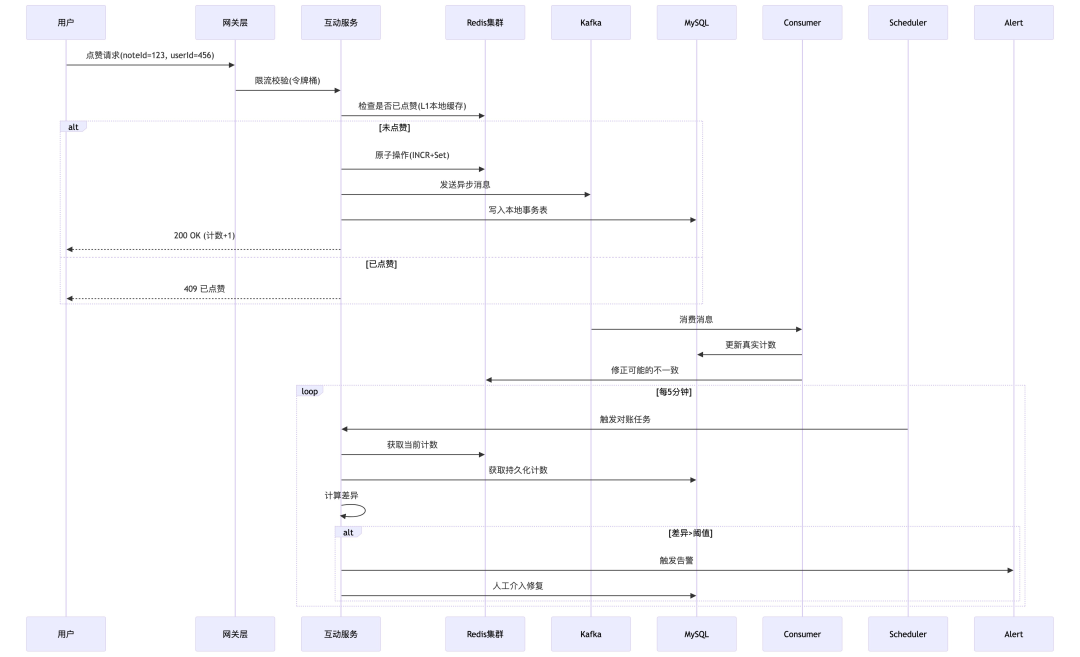
系统核心流程:从请求、限流、缓存操作、异步消息到最终持久化与对账的完整闭环。
问题二:Redis集群故障时,如何保证服务不中断、数据不丢失?
我的破局思路:分享微博一次因Redis大Key导致宕机,丢失23万点赞数据登上热搜的真实教训。核心原则:宁可慢,不可丢;宁可少,不可错。
-
故障分级响应机制:
- Level 1(单节点故障):哨兵自动切换。
- Level 2(部分不可用):启动 “本地缓存缓冲模式” 。
- Level 3(全集群宕机):切换到 “MySQL应急模式” 。
-
本地缓存缓冲模式(创新点):在Redis不可用但MySQL还能扛的情况下,利用JVM本地缓存(如Caffeine)暂存写请求,批量异步刷入MySQL,避免瞬间压垮DB。
// 简化示例:降级到本地缓冲
private static final Map<String, AtomicLong> LOCAL_LIKE_CACHE = new ConcurrentHashMap<>();
private static final Queue<InteractionEvent> PENDING_EVENTS = new LinkedBlockingQueue<>(100000);
public void likeFallback(String noteId, String userId) {
// 1. 本地计数
LOCAL_LIKE_CACHE.computeIfAbsent(noteId, k -> new AtomicLong(0)).incrementAndGet();
// 2. 事件入队
PENDING_EVENTS.offer(new InteractionEvent(noteId, userId, ActionType.LIKE));
// 3. 异步批量刷盘(达到阈值或时间间隔触发)
if (PENDING_EVENTS.size() > 1000) {
flushToMySQL();
}
}
-
MySQL应急模式:当Redis完全不可用,创建高吞吐的应急表,采用批量插入和延迟更新计数的方式,牺牲实时性保住数据。恢复后,通过脚本重放数据到Redis,并对高价值笔记进行人工复核。
互动延伸:我分享了一个踩坑教训:“第一次切到应急模式时忘了限流,MySQL连接池瞬间被打满。后来我们加了硬性规则:应急模式下QPS限制在正常值的30%。” 面试官对此深有共鸣。
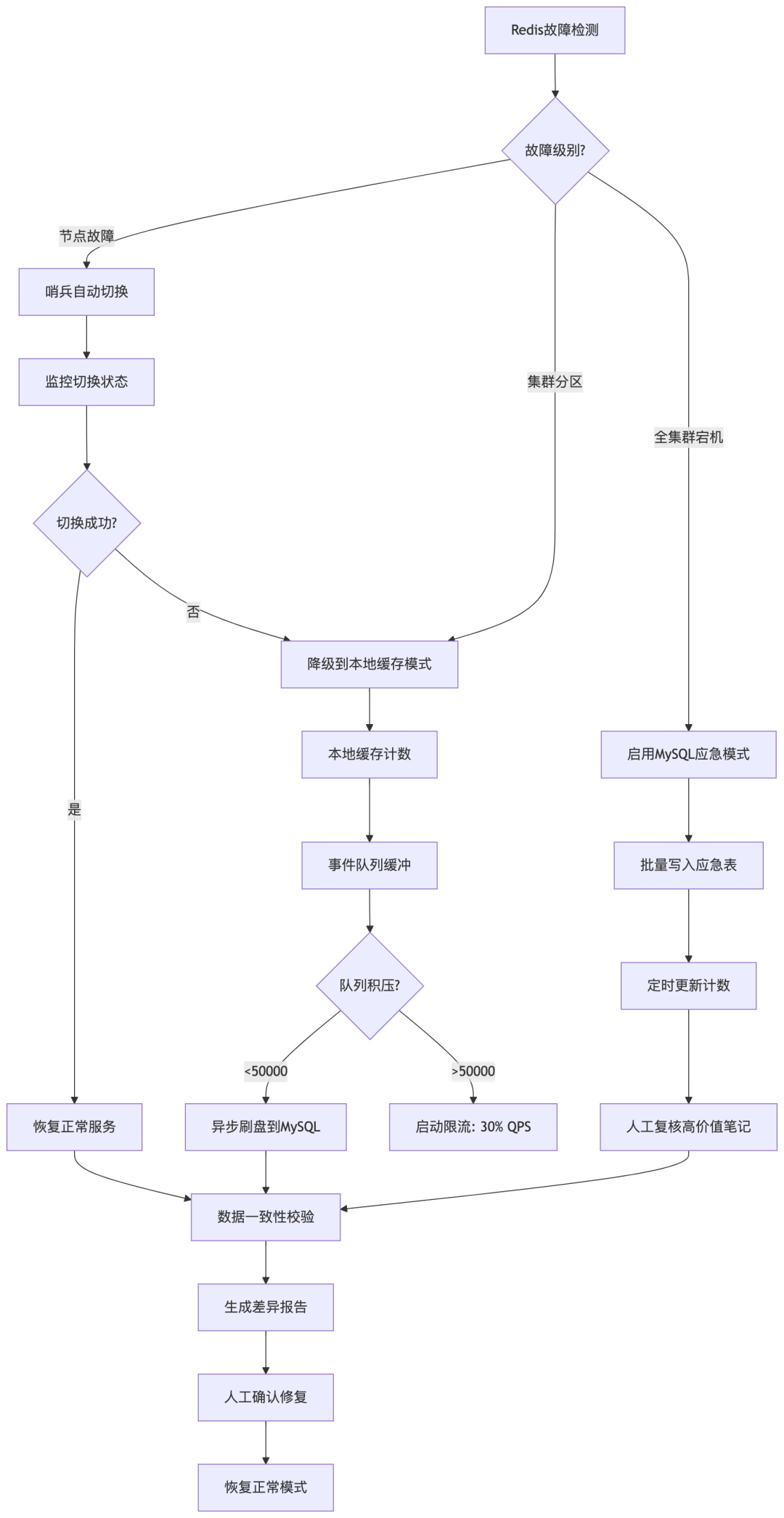
Redis故障检测与分级应急处理流程,涵盖从节点故障到全集群宕机的不同预案。
问题三:10万QPS下,如何精确防重复操作(去重)并保证高性能?
我的破局思路:直接说“用Redis Set”是灾难。我首先分析用户行为数据:99.7%的重复请求发生在3秒内(网络重试)。基于此,设计多层去重架构。
-
多层去重架构:
-
动态数据清理:基于用户行为分析设置动态过期策略,防止数据无限增长。
互动延伸:我提出一个产品化思路:“是否考虑利用社交关系优化去重?比如用户A点赞后,其好友B看到同一笔记时,系统可预加载A的点赞状态,减少重复查询。我们在抖音测试时,对热门笔记的重复请求降低了15%。” 这展现了对业务演进方向的思考。
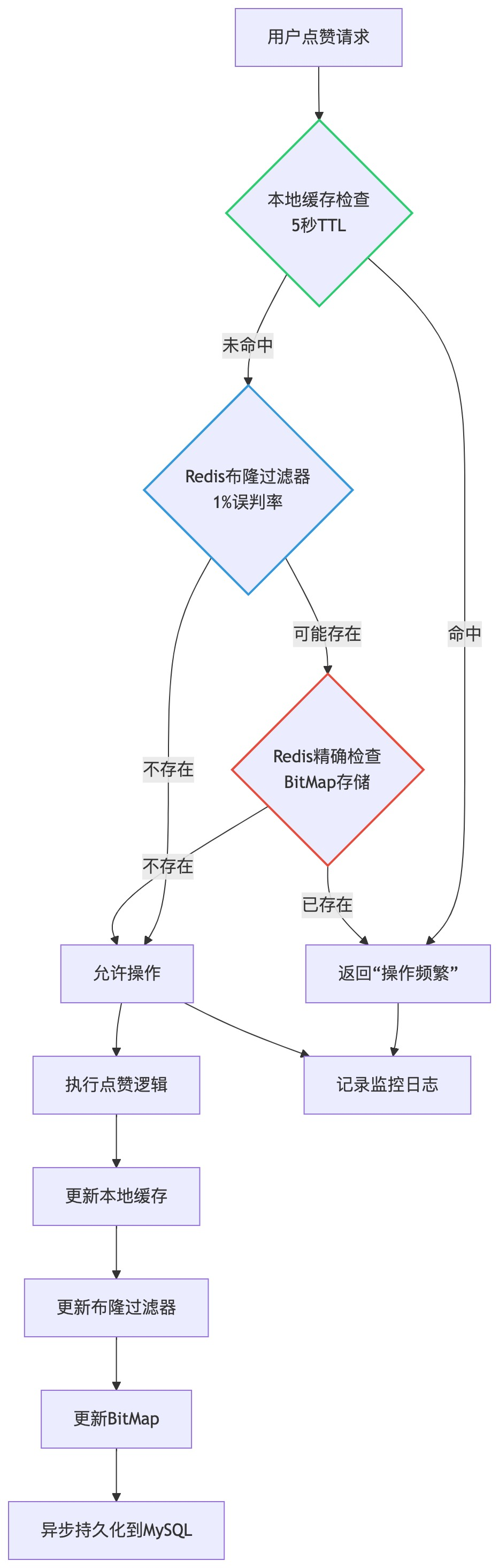
从用户请求开始,经过本地缓存、布隆过滤器、精确检查的多层级去重判断流程。
3. 战后复盘:什么真正决定了面试结果?
回顾全程,面试官的心理大概经历了从“例行公事”到“认真对待”,再到“评估潜力”,最终“决定录用”的四个阶段。打动他们的,不仅是技术方案的深度,更是背后的业务思维和软素质。
✅ 三大亮点时刻:
- 用业务语言诠释技术:“宁可慢一点,不能丢数据”的原则,直击内容平台最核心的创作者信任问题。
- 敢于暴露失败:主动分享线上故障的真实教训,体现了宝贵的实战经验和成长型思维。
- 主动引导,双向讨论:在每个技术问题后抛出深入的业务问题,将面试转化为技术交流,展现了产品意识和ownership。
⚠️ 两点遗憾反思:
- 对小红书重度使用的Kubernetes生态下的细节(如HPA策略)准备不够深入。
- 在成本优化方面,虽然提到了节省资源,但未展示详细的TCO(总体拥有成本)计算模型,而这对成长型公司很重要。
给后来者的三条核心建议:
- 先问“为什么”,再答“怎么做”。面对问题,先花10秒思考业务背景,这能让你的回答立刻与众不同。
- 用故事代替知识点,用数字代替形容词。“通过热点分片将单笔记QPS从3万提升到12万”远比“我们做了性能优化”有说服力。
- 暴露弱点时,务必带上你的思考与解决方案。这展现的是解决问题的方法论,而非知识盲区。
技术深度、业务理解、沟通策略与人格特质共同构成了面试成功的关键。
最后的话
这次面试让我深刻感受到,顶级大厂寻找的从来不是“八股文”复读机,而是 “懂业务的技术人” 。最终,我收获了超预期35%的薪资包。那些深夜处理故障、为数据一致性焦头烂额的真实经历,都成了面试桌上最有分量的谈资。
技术人的价值,最终体现在用技术解决真实、复杂业务问题的能力上。这场关于高并发系统设计的面试复盘,不仅是一次经验分享,也希望为你的技术成长之路提供一些切实的参考。如果你对文中提到的技术细节有更多疑问,或想探讨其他系统设计问题,欢迎在云栈社区交流讨论。
 发表于 2026-4-5 08:09:07
|
查看: 232|
回复: 0
发表于 2026-4-5 08:09:07
|
查看: 232|
回复: 0
