这两天,Claude Code的源码在网上传得沸沸扬扬。谁都没想到,一次不经意的疏漏,就让一个核心商业产品的“底裤”暴露在了全球开发者眼前。
出于纯粹的技术好奇,我也去翻阅了这份源码。你还别说,里面发现的几个小细节,还真有点出人意料。
01 用户情绪失控?赶紧用正则判断一下!
你以为一个顶级AI产品,是靠什么来理解用户情绪的?
是多模态情感分析?还是复杂的大模型推理?
都不是。
答案是一行简单的正则表达式!
在源码文件 userPromptKeywords.ts 中,我找到了下面这段代码:
export function matchesNegativeKeyword(input: string): boolean {
const lowerInput = input.toLowerCase()
const negativePattern =
/\b(wtf|wth|ffs|omfg|shit(ty|tiest)?|dumbass|horrible|awful|piss(ed|ing)? off|piece of (shit|crap|junk)|what the (fuck|hell)|fucking? (broken|useless|terrible|awful|horrible)|fuck you|screw (this|you)|so frustrating|this sucks|damn it)\b/
return negativePattern.test(lowerInput)
}
看到那个长长的正则了吗?这意味着,如果你的抱怨里夹杂着这些英文俚语或脏话,比如:
“This shit is broken again.”
“Wtf”
Claude Code 是能“听懂”你在发脾气的。但如果你用中文骂一句:
“这破玩意怎么又坏了?”
不好意思,它可能就一脸茫然了。看来,想被 AI 准确识别情绪,还得学好英语啊。
更有意思的是,它检测到你“情绪崩溃”后,并不会切换成“温柔客服模式”来哄你,也不会连连道歉。它只是默默地记下一笔:“嗯,这个用户刚才爆粗口了。” 这些数据很可能会被用于内部统计,比如分析哪些功能最容易让用户抓狂,或者整体的用户满意度趋势。
既然目的只是统计,那精度要求自然不用太高,一行正则表达式搞定,又快又省事。我甚至能脑补出这段代码诞生的场景:
产品经理:老板想看看用户用咱们产品时,有多少比例会感到沮丧,能做个统计吗?
实习生:没问题。
产品经理:今天下班前能上线不?
实习生:可以,我用一行正则搞定。
02 一个文件长达5594行!
早年我在IBM工作时,曾遇到过这么一个“神级”项目:前端页面光鲜亮丽,结果一打开后端代码,赫然是一个历经风霜、长达5000行的JSP文件。那一刻,我以为自己已经见识到了“屎山艺术”的巅峰。
万万没想到,这次在Claude Code的源码里,我又找到了那种熟悉的感觉:一个长达 5594行 的 TypeScript 文件。
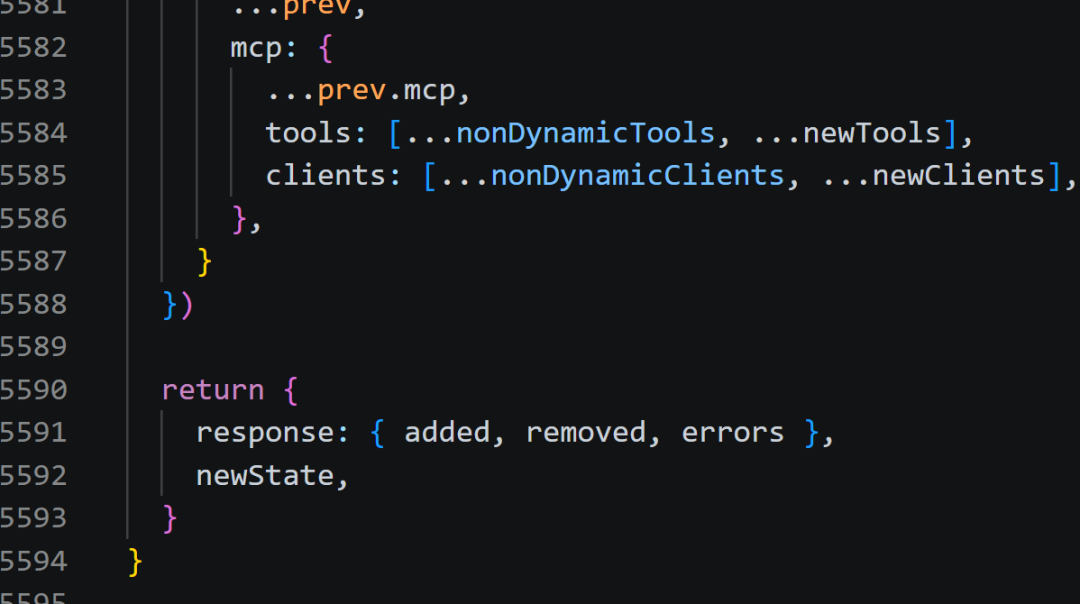
用 Claude Code 自身来分析这个庞大的文件,结果如下:
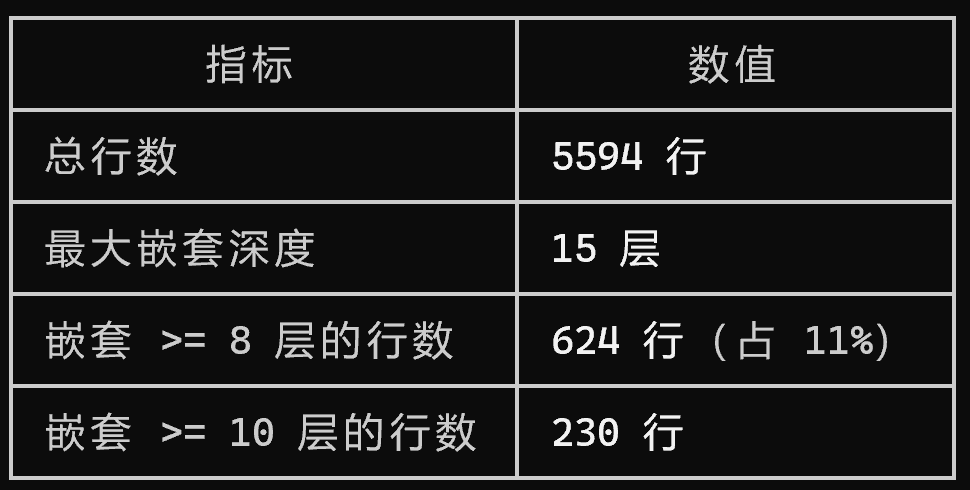
更夸张的是,其中单单一个函数的长度就达到了约 3170行,占整个文件行数的 57%。
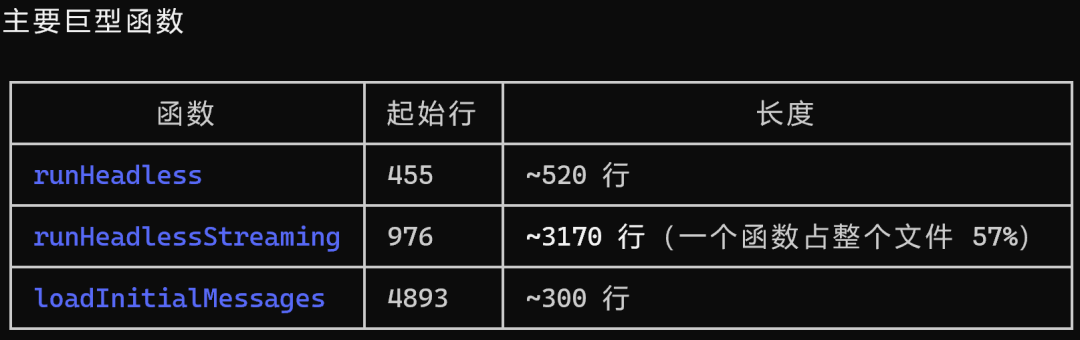
平心而论,这份源码分析的代码质量本身并不差,注释清晰,类型规范。问题不在于“写得烂”,而在于“结构已经失控了”。
这很可能是快速迭代下的典型产物。我们几乎可以还原它的生长路径:
- 项目初期:架构清晰,模块分明。
- 第一次需求变更:给某个函数加个新分支(subtype)吧。
- 第二次需求变更:时间紧,再往同一个函数里塞点逻辑。
- 第三次、第四次……“往现有函数里加代码”永远是阻力最小的路径,几乎没有程序员能长期抵抗这种诱惑。
03 有人想“蒸馏”我?给丫投毒!
在 claude.ts 文件的第 301–313 行,我发现了一个名为 ANTI_DISTILLATION_CC 的开关。
一旦这个开关在特定条件下被触发,Claude Code 在调用 API 时会带上一个特殊的字段:anti_distillation: ['fake_tools']。
// Anti-distillation: send fake_tools opt-in for 1P CLI only
if (
feature('ANTI_DISTILLATION_CC')
? process.env.CLAUDE_CODE_ENTRYPOINT === 'cli' &&
shouldIncludeFirstPartyOnlyBetas() &&
getFeatureValue_CACHED_MAY_BE_STALE(
'tengu_anti_distill_fake_tool_injection',
false,
)
: false
) {
result.anti_distillation = ['fake_tools']
}
这个字段的作用是告诉后端服务器:请在给模型的系统提示词(system prompt)里,偷偷混入一些“假工具(fake tools)”的定义。
如果有人在抓取 API 流量,企图用这些对话数据去做模型蒸馏训练,那么这些根本不存在的“假工具”定义就会污染训练数据集。最终,训练出来的模型会学到一堆虚无缥缈的“能力”,效果自然越跑越偏。这招“数据投毒”,可谓相当之狠。
此外,在 betas.ts 文件中,还有另一套组合拳:服务端文本压缩 + 签名验证。Claude 会将对话内容压缩成摘要并签名,然后传给客户端;下一轮对话时,客户端需要把这个签名回传给服务端,服务端再据此恢复出完整的对话原文。
这样一来,即使你截获了 API 响应,得到的也只是一串无法解读的摘要签名,关键的对话内容根本拿不到。这招既节省了传输的 Token 数量,也再次加固了反蒸馏的防线。
04 嘿嘿,我是卧底!
这个“卧底”功能,是专门给 Anthropic 自家员工准备的。
在内部的白名单项目里,Claude Code 显得非常“坦诚”。它生成的提交信息(commit message)里会明确写着:
Co-Authored-By: Claude Opus 4.6 noreply@anthropic.com
它创建的拉取请求(PR)描述里也会带上标记:
🤖 Generated with Claude Code (93% 3-shotted by claude-opus-4-5)
同事们一看就明白:哦,这是咱们的AI助手干的活。
然而,一旦员工切换到外部的开源项目,画风立刻突变,直接进入“卧底模式”。所有 commit、PR 的标题和描述,都必须严格遵守一套“隐身”规则:
- 不能提及任何内部模型代号。
- 不能出现未发布的版本号。
- 不能暴露内部仓库的任何信息。
- 甚至连 “Claude Code” 这个名字都不能出现。
- 更不用说
Co-Authored-By 这种明显的 AI 署名了。
简单说,就是不允许留下任何能表明“这段代码是 AI 生成”的痕迹。
于是便出现了这样一个微妙的场景:一位 Anthropic 的员工,使用着全世界最先进的 AI 编程助手,却在 GitHub 上像普通人类开发者一样提交代码、撰写 PR、修复 Bug、通过 Code Review。一切看起来都天衣无缝。
如果只是担心模型内部细节泄露,这很好理解。但现在连“AI 参与过”这件事本身也要彻底抹去,这就不单是“保护商业机密”了,更像是有意地让 AI 悄然无声地融入人类开发者的洪流之中。
05 一点儿感想
翻完这堆代码,我最大的感触是:不管产品外表多么光鲜亮丽,其内部的代码世界,依然遵循着最朴素的软件工程规律。
再强大的底层模型,到了具体的应用层,该用正则表达式做脏活累活的时候,一点也不会含糊;在业务快速迭代的压力下,该出现的“代码巨兽”和复杂结构,也一点不会少。
AI 产品,骨子里依然首先是软件产品。这次Claude Code的源码泄露事件,就像一次突然的“代码 CT 扫描”,让我们得以抛开营销与光环,窥见其真实的技术肌理与工程挑战。这也提醒我们,在关注模型能力跃迁的同时,承载它的软件工程体系同样至关重要。对这类技术实践感兴趣的开发者,不妨多来我们 云栈社区 逛逛,这里常有关于前沿技术落地与工程实战的深度讨论。
 发表于 2026-4-5 09:23:00
|
查看: 153|
回复: 0
发表于 2026-4-5 09:23:00
|
查看: 153|
回复: 0
