“找到那次看完烟花秀几天后,我在海边拍的照片。”
当你脑海中闪过这个念头时,现有的图像检索系统几乎全部失灵。不是因为 AI 看不懂海滩或烟花,而是因为在它眼里,你的相册只是成千上万张孤立图片的堆砌,而非一段连贯的情景记忆。

为了打破“逐张语义匹配”的传统范式,人大高瓴人工智能学院窦志成教授团队联合 OPPO 研究院正式开源了DeepImageSearch。该工作将图像检索从“看图识物”推向了“语料库级上下文推理”,并发布了首个硬核评测基准DISBench,还通过ImageSeeker框架对当前所有主流前沿多模态智能体进行了系统评测。
1. 范式转移:从“图书馆搜书”到“福尔摩斯破案”
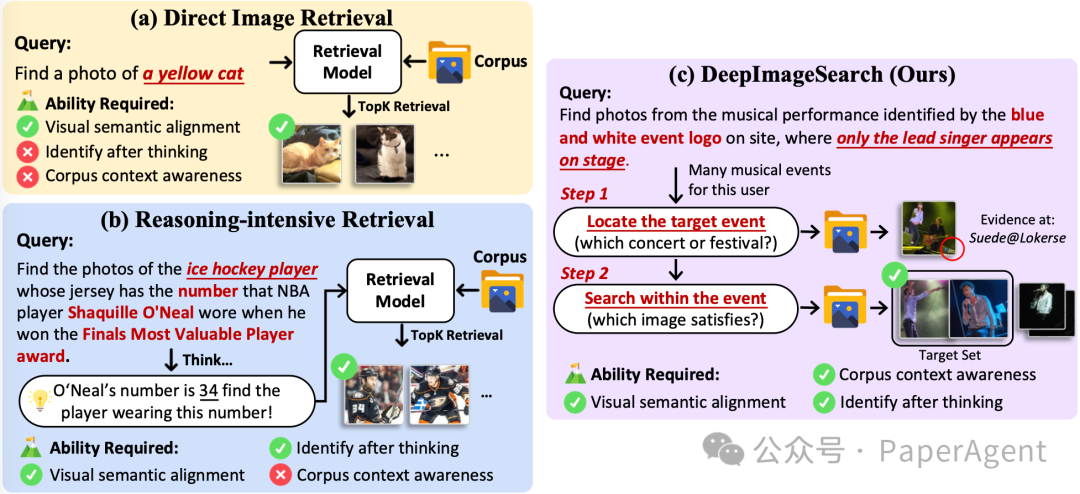
传统的图像检索(Image Retrieval)本质上是在做语义对齐。即便模型能通过Chain-of-Thought搜到“奥尼尔球衣号码的照片”,它依然遵循一个假设:目标仅凭自身视觉内容就能被识别。 DeepImageSearch 彻底打破了这个假设。 核心洞察:真正的相册搜索往往涉及“线索”与“目标”的分离。检索系统需要像侦探一样,在你的视觉历史中规划搜索路径、串联散落线索、构建证据链,才能找到结果。
- 案例: 你想找“我开的咖啡店的员工照片”。
- 痛点: 你去过很多咖啡馆,模型需要确认哪个员工是你家的。
- 推理链: 找到我在咖啡馆开业仪式上剪彩的照片 -> 锁定图中咖啡馆的logo -> 找到所有咖啡店员工的照片 -> 根据工服上的logo进行筛选 -> 返回logo匹配的员工照片
这种“先定位线索,再锁定目标”的路径,让检索从被动的匹配进化为主动的上下文推理探索。
2. DISBench:给 Agent 准备的一张地狱级考卷
为了评估这种能力,团队构建了DISBench。不同于传统数据集,它要求标注者在大量混乱的照片中,自主发现线索、构建逻辑。这样做的人工成本极高。为此,他们设计了一套人机协作流水线(Pipeline):先由 VLM 自动解析视觉线索并构建结构化记忆图谱,再由 LLM 沿着图谱路径自动生成候选查询,最后由人类专家核验。
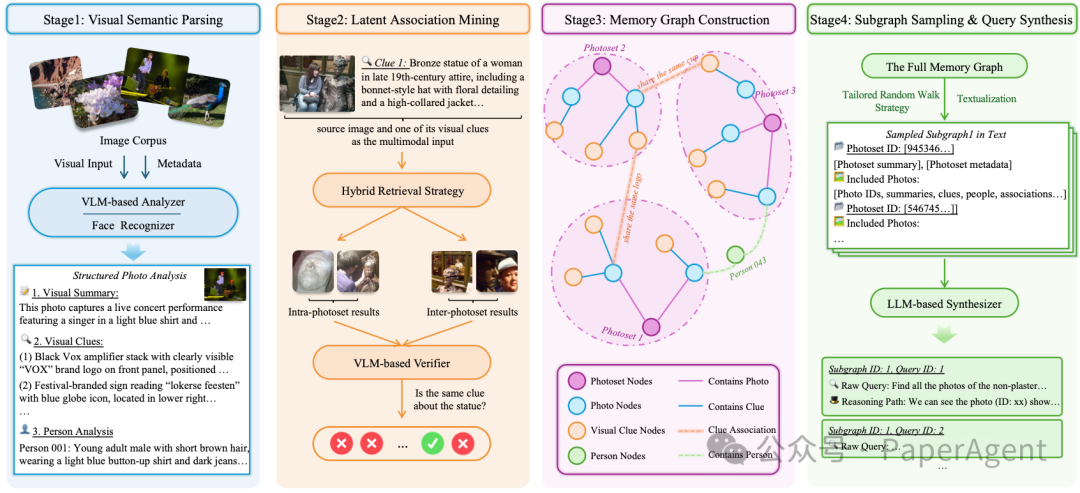
最终产出的DISBench涵盖了两大类极具挑战性的查询:
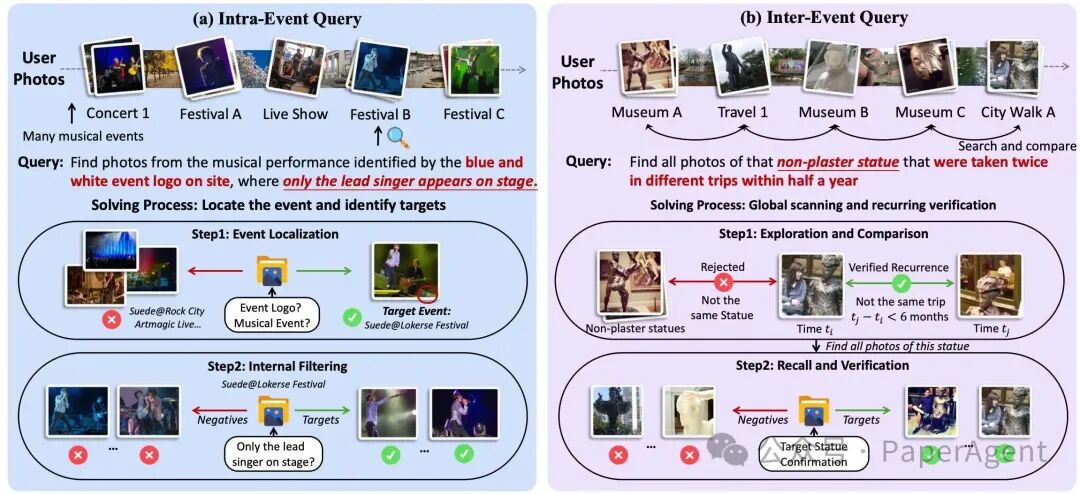
- Intra-Event(事件内推理,46.7%): 线索指向单一事件。比如:先通过一张“路牌”照片确定旅行地点,再定位该地点下的特定活动。
- Inter-Event(跨事件推理,53.3%): 跨越数年的视觉历史,寻找隐藏的长程关联。例如:“找到我两年都穿了一样的衣服的照片”。
数据集规格:
- 覆盖57位用户,11万张真实个人照片。
- 时间跨度平均3.4年,每条查询平均指向3.84张目标图片。
- 关键点:模型在测试时对相册的内在结构(如事件划分)完全不可见,必须像真人一样从混沌中自主发现脉络。
3. ImageSeeker 框架:视觉 Agent 的大脑与双眼
针对这一新任务,研究团队设计了 ImageSeeker 框架。这不仅是一个 Baseline,更是对“视觉历史探索”所需能力的工程化定义:
A. 复合工具调用(Multi-Tool Interaction)
模型需要灵活组合四种工具才能应对这个任务:
- Image Search:用自然语言在相册中搜图。
- Filter Metadata:精确处理时间戳和经纬度约束。
- View Photo:细粒度判别图片。
- Web Search:解决查询中涉及的百科常识(如:这个 Logo 属于哪个乐队?)。
B. 双层记忆管理(Memory Management)
一次深度探索可能涉及数十步交互,处理海量图片极易撑爆上下文窗口(Context Window)。ImageSeeker 引入:
- 显式状态记忆: 通过“可命名子集”保存中间步骤的工具结果,确保多步推理中可以复用之前的结果。
- 压缩上下文记忆: 在 Context 接近上限时,自动提炼“全局目标”与“当前行动计划”摘要,保留核心推理状态。
他们的ImageSeeker智能体不仅能跑DISBench,其开源的Demo还支持加载用户的个人相册,解决用户自定义的复杂相册检索需求。如图所示,用户可以直接用自然语言提出复杂的跨事件问题,ImageSeeker能够在海量照片中自主调用工具、逐步筛选并精准锁定目标图片。
4. 实验复盘:顶级模型全线受挫,AI 到底“笨”在哪?
团队横评了GPT-4o、Gemini-3-Pro、Claude-4.5-Opus以及Qwen/GLM 等主流模型。即使是表现最好的模型(Claude-Opus-4.5),准确率也仅约为28.7%,开源模型中的最高准确率不超过12%。传统图像检索的 Embedding 模型在此任务中表现更加糟糕。
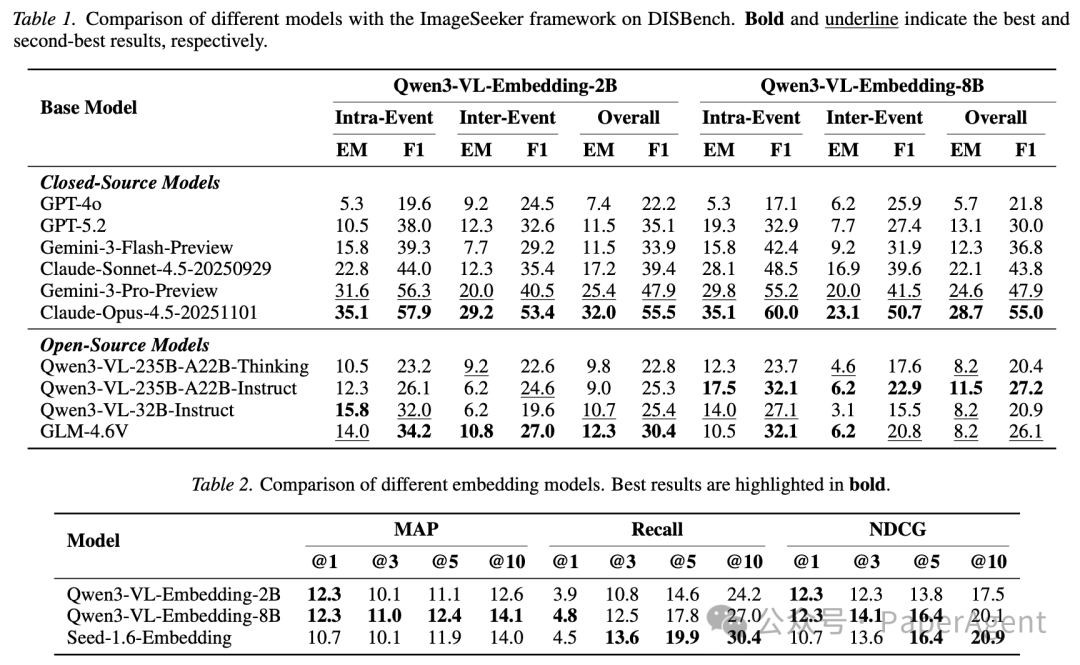
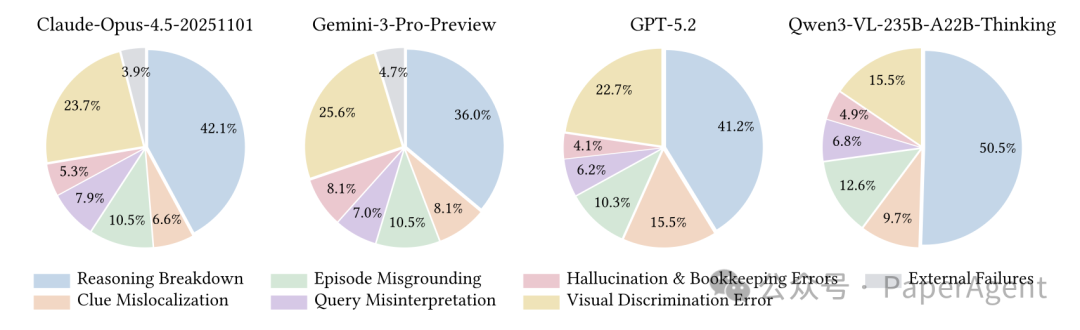
但更值得关注的,是这些模型到底“笨”在哪里。研究团队对失败案例进行了系统性的人工分析,发现了一个清晰的结论:感知能力(能不能看清图)已非主瓶颈,规划与记忆管理才是重灾区。
- 推理迷失: 模型找到了正确线索,但在执行长程计划时,由于上下文干扰或逻辑链断裂,导致过早停止搜索或丢失了最初的约束条件。
- 视觉判别失败: 例如模型无法区分不同光影、不同角度下的同一座建筑。
- 搜得准不等于答得好: 实验发现,即便更换更强的 Embedding 模型,整体表现提升也有限。核心挑战在于如何对搜到的结果进行利用。
5. 结语
“相册搜索”曾被认为是一个工程优化的检索问题,但 DeepImageSearch 告诉我们,这是一个认知推理问题。当 AI 真正学会在我们的视觉历史中“读懂”事件脉络、串联碎片化记忆时,它才会从“工具”进化为真正理解你人生故事的记忆伙伴。
论文链接:
https://arxiv.org/abs/2602.10809
Github项目主页: https://github.com/RUC-NLPIR/DeepImageSearch
Huggingface数据集: https://huggingface.co/datasets/RUC-NLPIR/DISBench
Leaderboard: https://huggingface.co/spaces/RUC-NLPIR/DISBench-Leaderboard
这个优秀的开源项目为我们重新思考AI图像检索的边界提供了宝贵的工具和基准。
 发表于 2026-4-5 10:37:00
|
查看: 153|
回复: 0
发表于 2026-4-5 10:37:00
|
查看: 153|
回复: 0
