目录
- 原始模块:带有内部 Buffer 的模型
- 图变换:将状态显式化
- 导出为 ONNX
- ONNXRuntime 状态管理包装类
- 总结
在部署 循环神经网络(RNN)、Transformer 增量推理中的 KV Cache 或任何带有内部计数器的模型时,一个核心痛点在于:模型内部维护了可变状态(如 self.h、self.kv_cache),而传统推理引擎(ONNX Runtime、TensorRT)要求模型是无状态的(下一次执行不会记住本次执行的任何内容)。本文介绍一种自动化方法,将 PyTorch 模块中的所有 buffer 转换为显式的图输入/输出,从而导出干净的 ONNX 模型,并提供一个轻量级的运行状态包装类。
适用场景
- RNN/LSTM 隐藏状态:每次前向需要传入/传出
h_t。
- Transformer 增量推理:管理
key_cache 和 value_cache。
- 计数器/滑动窗口:如本文示例中的自增计数器。
- 任何需要跨多次调用保持内部状态的模型。
1. 原始模块:带有内部 Buffer 的模型
下面定义一个简单的有状态模块:它包含两个 buffer h 和 counter,每次前向输出 x + h,然后将 h 增加 1,counter 增加 1。
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self, init_h=3.0):
super().__init__()
self.register_buffer('h', torch.tensor(init_h)) # 状态1
self.register_buffer('counter', torch.tensor(0)) # 状态2
def forward(self, x):
out = x + self.h
self.h = self.h + 1.0 # 非原地加法后赋值
self.counter = self.counter + 1
return out
- 原理:
register_buffer 将张量注册为模块的一部分,但不参与梯度更新,适合存储持久化状态。与普通属性不同,buffer 会出现在 state_dict 中,并随模型一起保存和加载。- 前向中读取
self.h、self.counter,并更新它们。这里特意使用 self.h = self.h + 1.0 而非 self.h += 1.0,后者会触发原地加法(add_),导致图变换时难以捕获新值。
- 所有操作均为普通非原地加减,便于 TorchScript 图分析。
原始 TorchScript 代码
通过 torch.jit.script 编译后,可以看到内部使用了 prim::GetAttr 和 prim::SetAttr:
scripted = torch.jit.script(MyModule())
print(scripted.code)
输出:
def forward(self, x: Tensor) -> Tensor:
h = self.h
out = torch.add(x, h)
h0 = self.h
new_h = torch.add(h0, 1.)
self.h = new_h
counter = self.counter
self.counter = torch.add(counter, 1)
return out
- 原理:
torch.jit.script 将动态 Python 代码转为静态中间表示(IR),该 IR 是一种基于数据流的图结构。prim::GetAttr 节点从 self 对象中读取属性(即 buffer),prim::SetAttr 节点将值写回属性。- 这种 IR 无法直接导出 ONNX,因为 ONNX 的计算图是无副作用的——没有“赋值”操作,所有数据流动必须通过输入输出显式传递。
原始计算图(样式区分普通/状态节点)
下图展示了原始计算图:
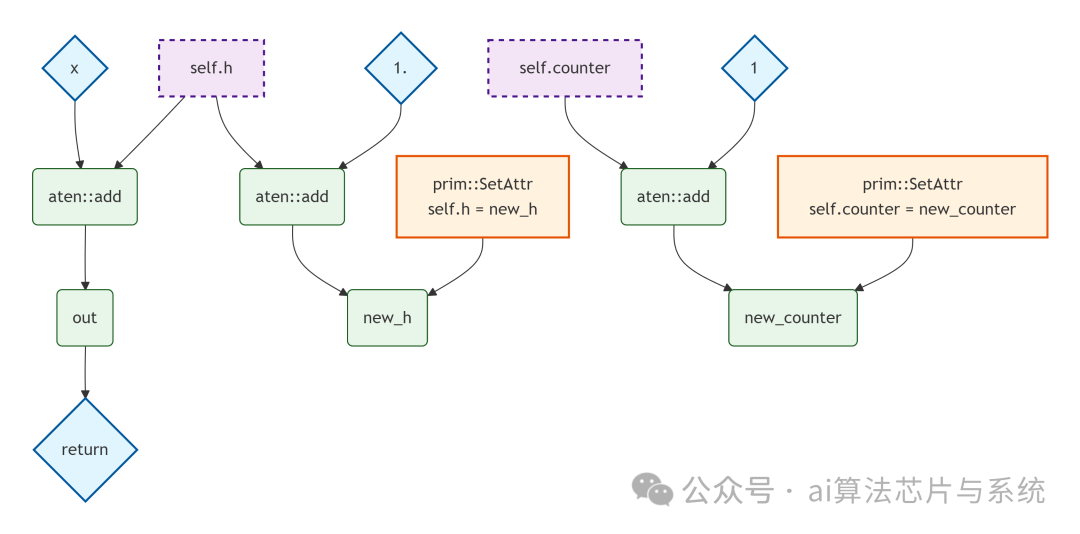
2. 图变换:将状态显式化
我们直接操作 TorchScript 的 torch._C.Graph,自动完成以下步骤:
- 收集模块中所有 buffer 的名称和初始值。
- 为每个 buffer 添加一个 graph 输入(命名为
{name}_in)。
- 将所有
prim::GetAttr 节点替换为对应的输入。
- 收集每个 buffer 最后一个
prim::SetAttr 的值作为状态输出({name}_out)。
- 修改返回节点,将原返回值与所有状态输出打包成元组。
def transform_to_stateless(script_module):
graph = script_module.forward.graph.copy()
state_names = [n for n, _ in script_module.named_buffers()]
# 遍历节点,识别 GetAttr/SetAttr,进行替换
# ...(完整实现见文末仓库)
return graph, state_names, state_inits
- 原理:
graph.copy() 深拷贝原始图,避免修改原模块。named_buffers() 自动获取所有 buffer,无需手动指定名称,使得转换函数通用。- 替换
GetAttr 后,节点输出直接来自图输入,状态不再依赖模块内部存储。
- 提取
SetAttr 的第二个输入(被赋的值)作为状态输出,并删除原 SetAttr 节点。注意:这里取最后一个SetAttr 节点,因为后续的赋值会覆盖前面的。
- 最后将原返回值与所有状态输出打包成元组,使图返回多个值。这样,调用者可以同时获得推理结果和新的状态。
变换后的 TorchScript 代码
将新图重新编译为 ScriptFunction 后,代码变得完全无状态:
def forward(x, h_in, counter_in):
out = x + h_in
h_out = h_in + 1.0
counter_out = counter_in + 1
return (out, h_out, counter_out)
- 原理:
- 状态
h 和 counter 不再作为模块属性,而是作为显式输入h_in、counter_in。
- 更新后的状态作为显式输出
h_out、counter_out 返回。
- 模型现在是纯函数:相同输入(包括状态输入)必定产生相同输出。这符合 ONNX 和大多数推理引擎的要求。
- 注意返回值是一个元组,这在 TorchScript 中允许,但导出 ONNX 时会被展开为多个输出。
变换后的计算图(样式区分普通/状态输入输出)
现在所有状态都通过显式的输入输出传递,GetAttr/SetAttr 消失。图中:
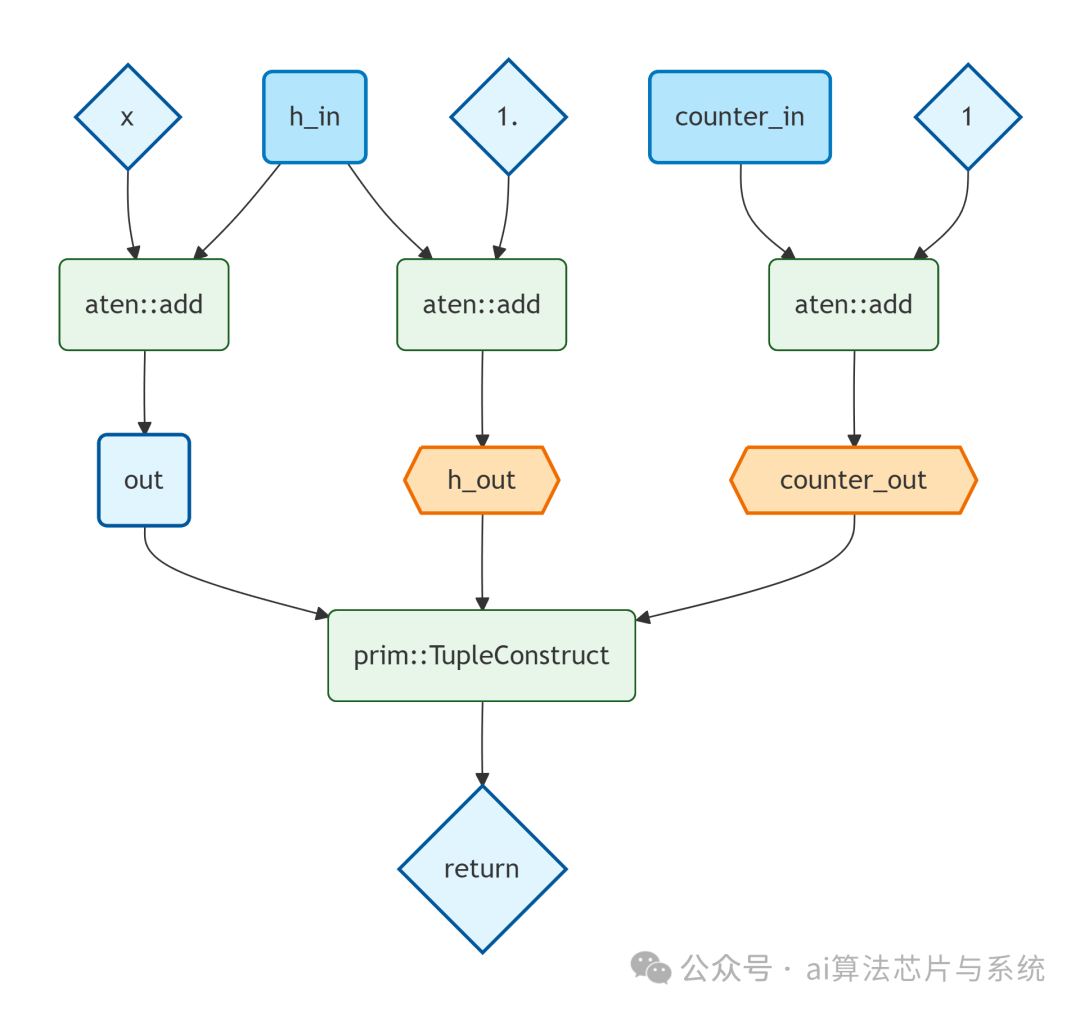
-
绿色菱形:普通输入输出(x、常量、最终返回的 out)。
-
浅蓝色圆角矩形:状态输入(h_in、counter_in)。
-
橙色六边形:状态输出(h_out、counter_out)。
-
绿色圆角矩形:运算节点。
-
原理:
- 绿色菱形:普通数据流(
x、常量、最终返回的 out),这些是业务输入输出。
- 浅蓝色圆角矩形:状态输入(
h_in、counter_in),表示来自外部提供的初始或上次更新的状态。
- 橙色六边形:状态输出(
h_out、counter_out),表示需要传递给下一次调用的新状态。
- 这种设计使得状态的生命周期完全由调用者管理,推理引擎无需关心内部可变性。同时,图结构清晰,便于后续优化(如常量折叠、算子融合)。
3. 导出为 ONNX
利用变换后的图创建 ScriptFunction,然后直接导出 ONNX。注意输入/输出命名遵循约定:状态输入以 _in 结尾,状态输出以 _out 结尾。
from torch._C import _create_function_from_graph
def export_onnx(scripted_model, onnx_path, sample_x):
graph, state_names, state_inits = transform_to_stateless(scripted_model)
const_table = scripted_model.forward.graph.constants()
stateless_func = _create_function_from_graph("forward", graph, const_table)
dummy_inputs = (sample_x,) + tuple(state_inits.values())
input_names = ['x'] + [f'{n}_in' for n in state_names]
output_names = ['output'] + [f'{n}_out' for n in state_names]
torch.onnx.export(stateless_func, dummy_inputs, onnx_path,
input_names=input_names, output_names=output_names,
dynamic_axes={'x': {0: 'batch_size'}, 'output': {0: 'batch_size'}},
opset_version=11)
return state_names, state_inits
- 原理:
_create_function_from_graph 将修改后的 IR 图包装为可调用的函数。torch.onnx.export 遍历该函数,将每个操作转换为 ONNX 算子,同时根据 dummy_inputs 推断张量形状和类型。- 我们显式指定了
input_names 和 output_names,并标记了动态维度(batch 大小可变)。
- 最终生成一个
.onnx 文件,其中不再包含任何状态赋值操作,所有状态都作为显式输入输出。
ONNX 计算图(样式保持状态区分)
导出的 ONNX 模型可使用 Netron 等工具可视化,其逻辑结构如下。
绿色菱形为普通输入输出,浅蓝色圆角矩形为状态输入,橙色六边形为状态输出,绿色圆角矩形为运算节点。
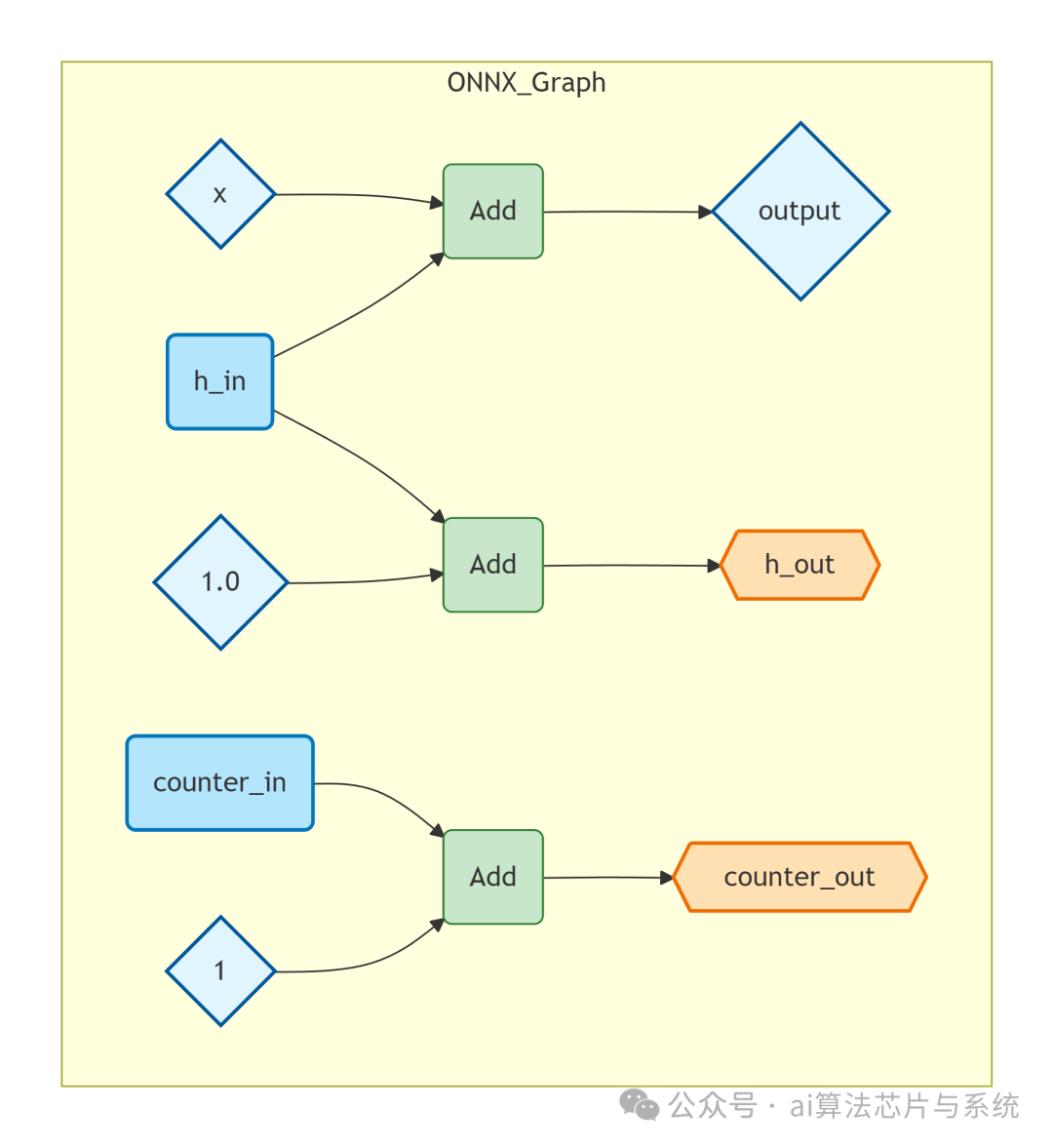
- 原理:
- ONNX 将每个输出张量独立列出,不再有
prim::TupleConstruct 节点。
- 状态输入和输出在图中明确分离,任何 ONNX Runtime 的消费者都能正确理解该模型。
4. ONNXRuntime 状态管理包装类
虽然导出的 ONNX 模型是无状态的,但在实际推理中我们需要跨调用维护状态。为此,我们实现一个包装类 StatefulRunner,它自动完成状态拼接、推理和更新。该类的 run 方法接受一个字典(键为输入名,值为 numpy 数组),返回一个字典(键为输出名,值为 numpy 数组),这与原始 PyTorch 模块的 forward 调用方式完全一致——用户只需提供业务输入(如 {'x': x_array}),无需关心状态参数。
import onnxruntime as ort
import numpy as np
class StatefulRunner:
def __init__(self, onnx_path: str, init_state_dict: dict):
self.session = ort.InferenceSession(onnx_path)
self.input_names = [inp.name for inp in self.session.get_inputs()]
self.output_names = [out.name for out in self.session.get_outputs()]
self.state_in_names = [n for n in self.input_names if n.endswith('_in')]
self.state_out_names = [n for n in self.output_names if n.endswith('_out')]
self.original_input_names = [n for n in self.input_names if not n.endswith('_in')]
# 当前状态值
self._state = {}
for name in self.state_in_names:
base = name[:-3]
self._state[base] = init_state_dict[f"{base}.init"]
def run(self, inputs: dict) -> dict:
"""
与原始 PyTorch 模块的 forward 签名一致:传入业务输入字典,返回业务输出字典。
原始模块调用方式:output = model(x)
本方法调用方式:output_dict = runner.run({'x': x_array})
"""
# 构建完整输入字典:业务输入 + 当前状态
feed = {}
for name in self.original_input_names:
if name not in inputs:
raise KeyError(f"缺少业务输入 '{name}'")
feed[name] = inputs[name]
for in_name in self.state_in_names:
base = in_name[:-3]
feed[in_name] = self._state[base]
# 推理
outputs = self.session.run(self.output_names, feed)
# 解析输出:第一个输出是原始业务输出,后续是状态输出
result = {self.output_names[0]: outputs[0]}
for i, out_name in enumerate(self.state_out_names):
base = out_name[:-4]
self._state[base] = outputs[i+1]
return result
def reset(self, init_state_dict):
"""重置状态到初始值"""
for base in self._state.keys():
self._state[base] = init_state_dict[f"{base}.init"]
- 原理:
- 构造函数解析 ONNX 模型的输入/输出名称,通过
_in/_out 后缀自动识别状态变量。
_state 字典保存当前每个状态的值。run 方法:
- 接收一个字典,包含所有业务输入(如
{'x': x_array})。
- 自动将当前状态值拼接到输入字典中。
- 调用 ONNX Runtime 执行推理。
- 从输出中分离业务输出(第一个输出)和状态输出,更新
_state。
- 返回业务输出字典(如
{'output': out_array})。
- 这种设计与原始 PyTorch 模块的
forward(x) 调用方式语义一致:用户只需提供业务输入,状态管理完全透明。
使用示例:
model = MyModule(init_h=3.0)
scripted = torch.jit.script(model)
sample_x = torch.randn(1, 3)
onnx_file = "model.onnx"
state_names, state_inits = export_onnx(scripted, onnx_file, sample_x)
init_np = {f"{name}.init": state_inits[name].cpu().numpy() for name in state_names}
runner = StatefulRunner(onnx_file, init_np)
x_test = np.array([[1.0, 2.0, 3.0]], dtype=np.float32)
out1 = runner.run({'x': x_test})
print(out1['output']) # [[4. 5. 6.]]
out2 = runner.run({'x': x_test})
print(out2['output']) # [[5. 6. 7.]]
runner.reset(init_np)
out3 = runner.run({'x': x_test})
print(out3['output']) # 再次 [[4. 5. 6.]]
- 原理:
- 第一次调用时,状态为
h=3, counter=0,输出 [4,5,6],状态变为 h=4, counter=1。
- 第二次调用使用更新后的状态,输出
[5,6,7],状态继续变化。
- 重置后,状态恢复初始值,输出与第一次相同。
- 用户始终只传递
{'x': x_test},与原始 PyTorch 模块的 model(x) 调用体验完全一致。
5. 总结
- 自动化:无需手动修改模型代码,脚本自动识别所有 buffer 并转换。对于包含数十个状态的复杂模型(如 Transformer 中的 KV Cache),这种自动化能极大减少人工错误。
- 通用性:适用于任意包含
register_buffer 的模块,包括 RNN 隐藏状态、KV Cache、滑动窗口、贝叶斯统计中的累积量等。
- 部署友好:导出的 ONNX 模型可被 TensorRT、OpenVINO 等后端加速,且包装类使得状态管理对调用者透明。
- 性能:由于状态变为显式传递,推理引擎可以更好地进行内存规划和算子融合。例如,ONNX Runtime 可以将状态输入和输出映射到持久内存区域,避免重复分配。
注意事项:直接操作 torch._C.Graph 依赖 PyTorch 内部 API,建议锁定 PyTorch 版本(如 2.0+)并在测试环境中充分验证。不同 PyTorch 版本的 IR 节点名称可能略有差异(如 prim::GetAttr vs GetAttr),代码中应使用 in 判断。完整代码示例可在 GitHub Gist 获取。
本文介绍的方法,是解决 深度学习 模型在 ONNX 等生产环境中管理状态的一个实用技巧。如果你在 PyTorch 模型部署或 TorchScript 图操作中遇到其他难题,欢迎来 云栈社区 的 人工智能 或 智能 & 数据 & 云 板块交流探讨。
 发表于 2026-4-6 07:32:10
|
查看: 179|
回复: 0
发表于 2026-4-6 07:32:10
|
查看: 179|
回复: 0
