一张充满科幻感的对战海报拉开了序幕:斑驳的石质王座上,“Transformer”的字样与“王座不保”的铭文格外刺眼,一顶金色皇冠滚落在地。中央是蓝黄闪电贯穿的“VS”标志,右侧则是散发着光芒的“SubQ”。一种全新的架构,正向旧日的王者发起挑战。
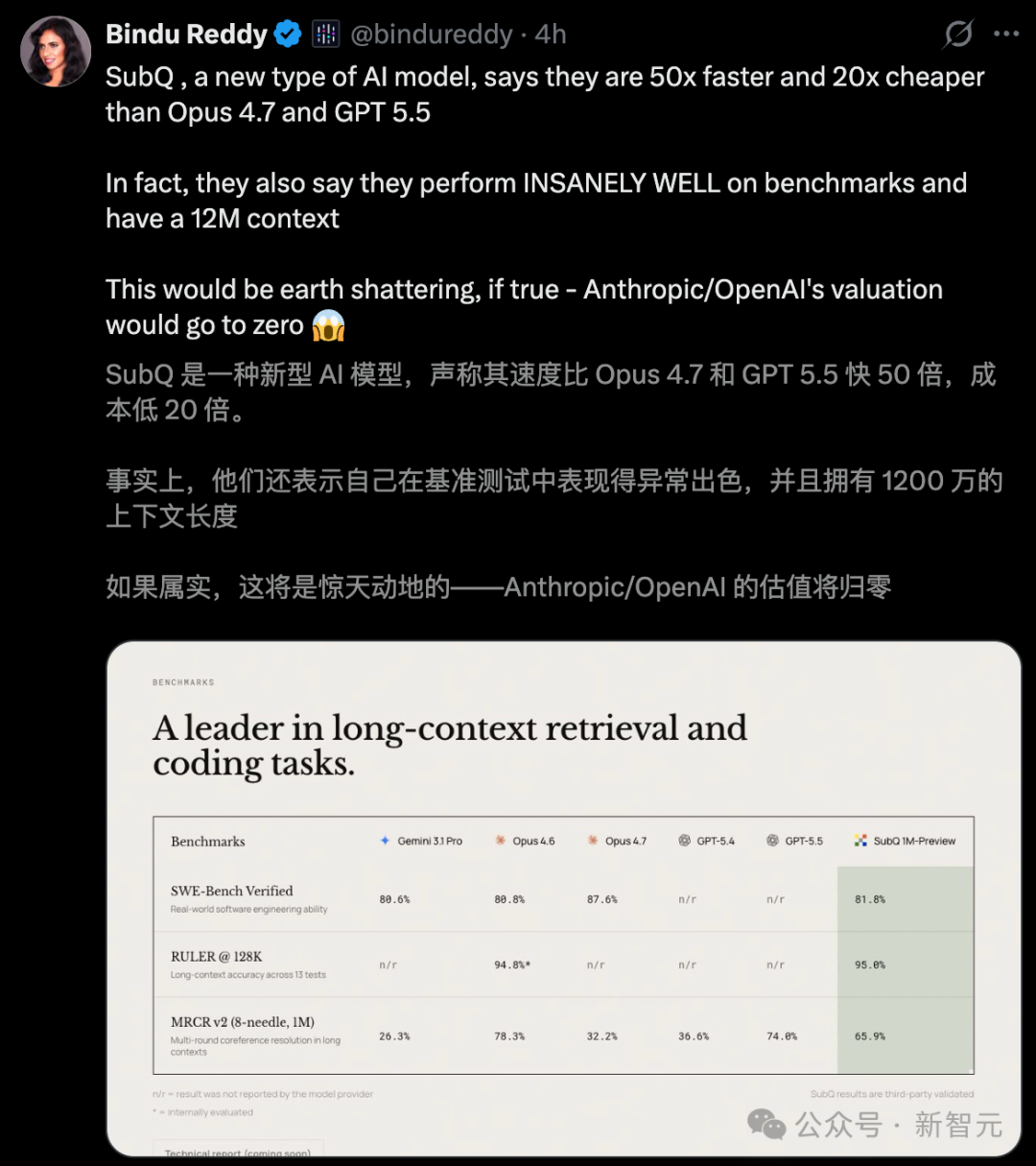
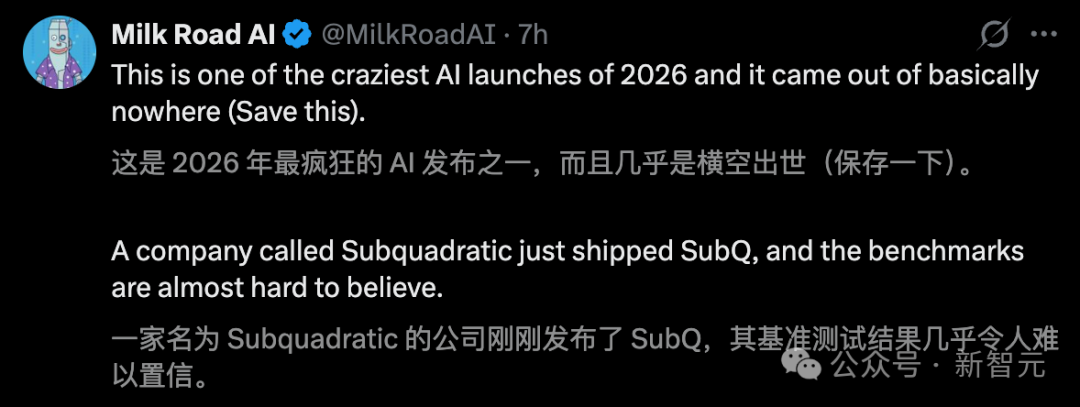
AI 社区因为一款名为 SubQ 的模型炸开了锅。这是全球首个基于完全亚二次方稀疏注意力架构(SSA)打造的前沿模型,其上下文窗口高达 1200 万 Token。

它的核心突破,在于其 SSA 架构会依据内容“动态选择”关注点,而非像传统模型那样盲目计算所有 Token 间的关系。

相较 Transformer,SubQ 的计算量直接暴减 1000 倍。实验数据显示,在处理 100 万 token 上下文时,SubQ 比 FlashAttention 快 52 倍,而成本不到 Claude Opus 的 5%。

打造出这一架构的,是一家名为 Subquadratic 的公司,全员仅 13 人,坐标迈阿密。AI 大佬 Bindu Reddy 对此辣评:“若这一切都是真的,Anthropic 和 OpenAI 的估值将直接归零!”
还有观点认为,这或许才是 LLM 接下来真正的 Scaling Law。
2017 年,谷歌一篇《Attention is All You Need》奠定了 Transformer 架构的统治地位。

此后九年,从 GPT 到 Claude 再到 Gemini,几乎所有前沿大模型都建立在同一个基础之上——密集注意力机制。这种机制的工作方式非常“暴力”:每个 token 都要和序列中所有其他 token 做一次比较。这让它深陷“二次方复杂度”的泥潭,上下文每增加一倍,计算成本便飙升四倍。输入越长,模型就越贵、越慢、越容易崩。这也解释了为何几乎所有 LLM 的上下文都卡在 100 万 token 左右——不是技术做不到更长,而是做到了也用不起。
SubQ 的诞生,则从根本上改写了这个等式。

SSA 架构出世:不是“更快”,而是“更少”
SubQ 的核心突破叫做 SSA——亚二次方稀疏注意力(Subquadratic Sparse Attention)。它的思路出奇地简单:不再让每个 token 和所有 token 做比较。既然在训练好的模型中,绝大多数注意力权重都接近零,那为什么还要算它们?
SSA 的做法是,对每一个 query,基于“内容”选择序列中真正值得关注的位置,然后只在这些位置上精确计算注意力。它只计算那些真正有意义的交互,跳过其余 99% 以上的无用计算。

以下是 SSA 的三大关键特性:
- 线性扩展:计算量随选中的位置数量增长,而不是随整个序列长度增长。上下文翻倍,成本只翻倍,不再是翻四倍。
- 内容依赖路由:模型根据语义决定“看哪里”,而不是根据位置。关键信息在序列第 3 个 token 还是第 1100 万个 token,都能被精准找到。
- 精确检索:不像循环模型那样把信息压缩成固定状态,SSA 保留了从任意位置精确取回信息的能力。
简单来说,SSA 不是“把密集注意力算得更快”,而是“让模型做更少的注意力计算”。减少的计算量,直接转化为速度。
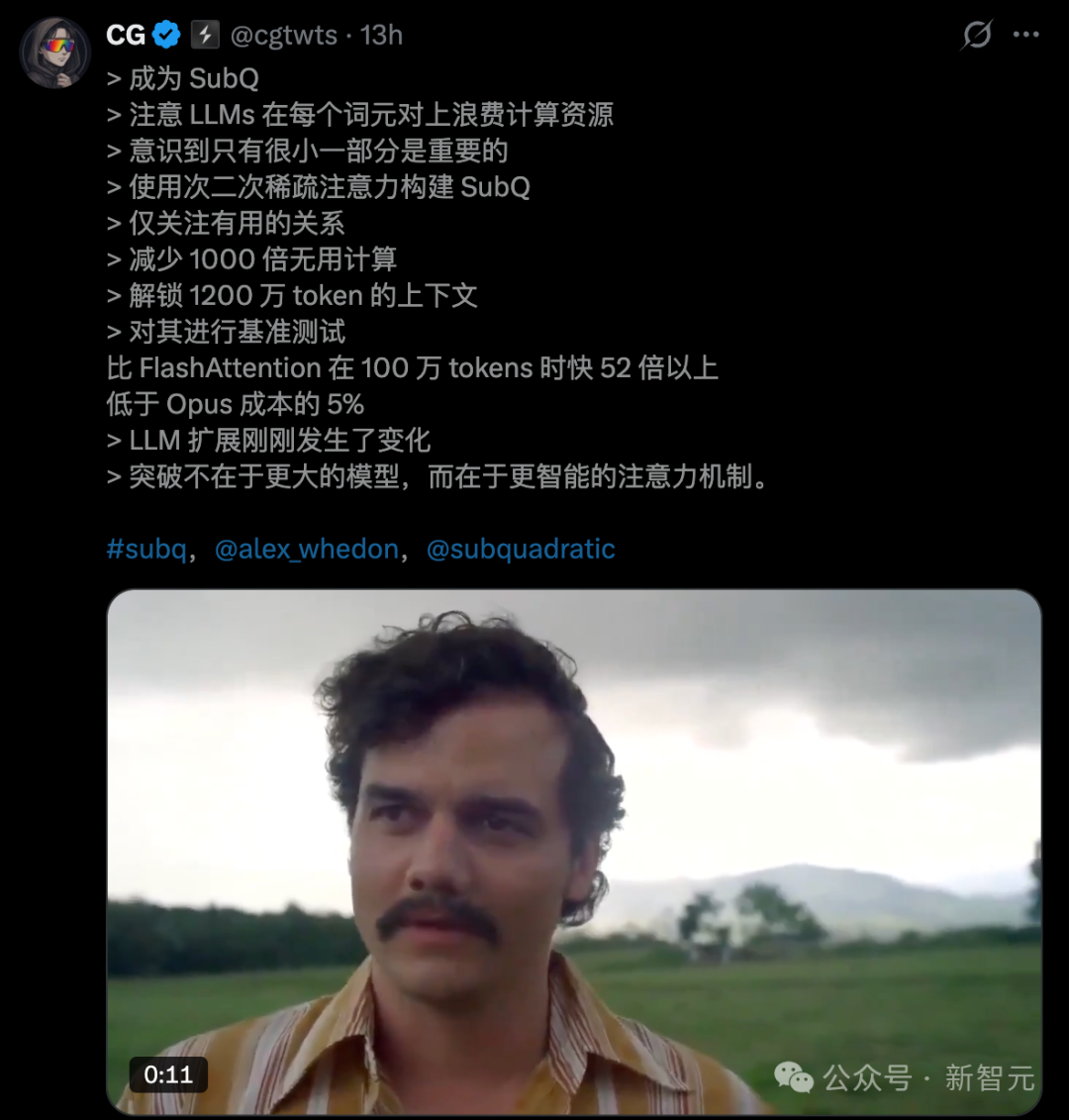
速度狂飙 52.5 倍,成本不到 Opus 的 5%
SubQ 放出的数据,每一条都在冲击旧有的认知:
在 100 万 token 长度上,SSA 比标准密集注意力 + FlashAttention-2 快 52.2 倍。

而在 12.8 万 token 上快 7.2 倍,25.6 万 token 快 13.2 倍,51.2 万 token 快 23 倍。显而易见,上下文越长,优势越碾压。这正是 SSA 线性扩展的直接体现——密集注意力是越长越慢,SSA 则是越长越划算。

再看算力消耗。在 100 万 token 下,注意力 FLOP 减少了 62.5 倍。而在 1200 万 token 下,这个数字飙升到接近 1000 倍。

至于成本,Subquadratic 给出了一个非常直观的对比:在 RULER 128K 基准测试上,SubQ 花费 8 美元,而 Opus 则为 2600 美元,成本差距高达 300 倍。
最关键的在于,这些速度和成本优势,并没有以牺牲准确率为代价。
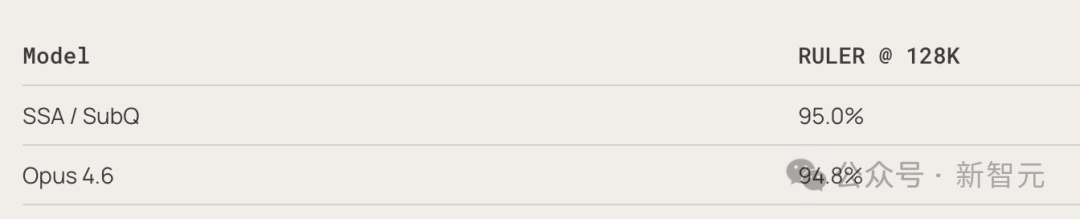
- RULER 128K 基准测试:SubQ 拿下 95%,Opus 4.6 是 94.8%。
- SWE-Bench Verified(代码工程):SubQ 得分 81.8,超过 Opus 4.6 的 80.8。
- MRCR v2(长上下文检索):SubQ 拿到 65.9%,虽低于 Opus 4.6 的 78%,但远超 GPT 5.4 的 39% 和 Gemini 3.1 Pro 的 23%。

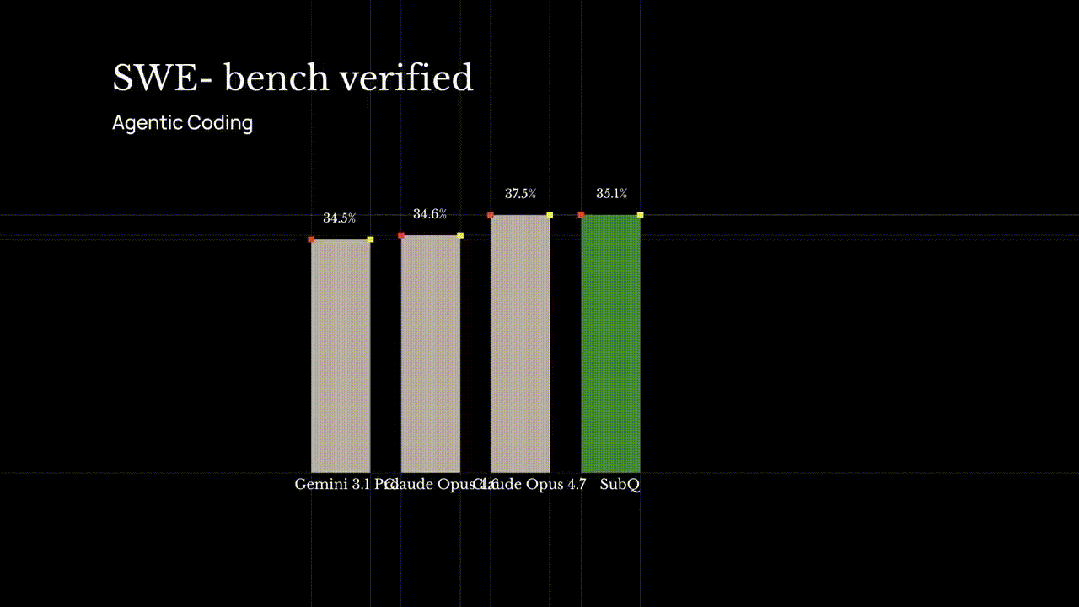
一家种子轮公司,用不到 Opus 5% 的成本,在多项核心基准测试上打平甚至超越了顶尖公司的旗舰模型。这组数字放在一起看,细思极恐。
一个提示词,SubQ 即可轻松处理 1200 万 Token 的超长信息。无论是整个代码库、数月的 PR 记录,还是长期运行的 AI 智能体状态,全都不在话下,而且成本仅需原来的五分之一。
若这一切成真,这将是 Transformer 问世九年来最重要的架构级突破。
Subquadratic 成立于 2024 年,拿下 2900 万美元种子轮,估值 5 亿美元。两位联合创始人分别是 CEO Justin Dangel 和 CTO Alexander Whedon。

研究团队共 11 人,全员博士,背景来自 Meta、谷歌、牛津大学、剑桥大学、Adobe 等顶尖机构。值得一提的是,这家公司之前名为 Aldea,主攻语音模型,后转型至注意力架构研究。
此次,其三条产品线同时上线:
- SubQ API:1200 万 token 全量上下文接口。
- SubQ Code:命令行编码 Agent,可一次性塞入整个代码库。
- SubQ Search:深度研究工具,初期免费。
全网炸锅:是终结者,还是 AI 版 Theranos?
SubQ 发布后数小时内,AI 社区便分裂成两大阵营。Dan McAteer 的一句话精准概括了所有人的心态:
SubQ 要么是自 Transformer 以来最大的突破……要么就是 AI 界的 Theranos。

支持者阵容不小。有人盛赞这是“2026 年最疯狂的 AI 发布之一,几乎横空出世”。更有观点认为,Subquadratic 可能已经找到了 Sam Altman 所说的、那个意义堪比当年 Transformer 相对于 LSTM 的下一个架构级重大突破。

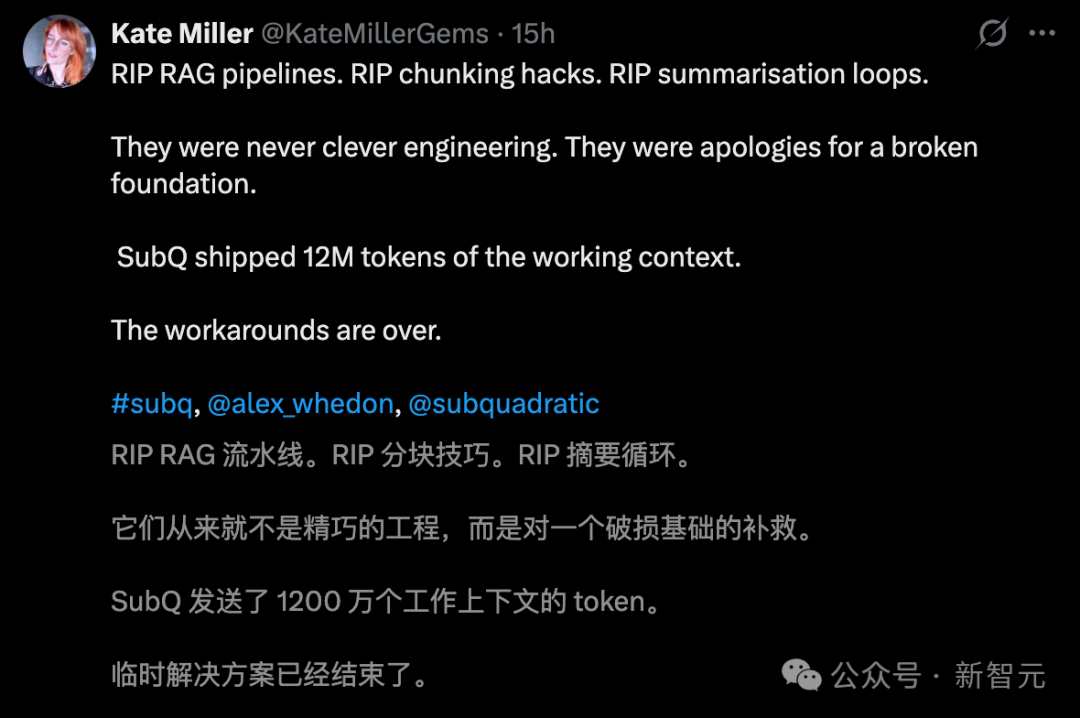
也有人宣告,随着 SubQ 能处理 1200 万 token 的工作上下文,曾经那些“RAG 流水线”、“分块技巧”、“摘要循环”等临时解决方案,都可以寿终正寝了。
然而,怀疑派也毫不留情。有人直言这就是一个“骗子公司”,尤其是在查看了创始人的领英资料后,认为其缺乏真正的 AI 经验,更像是擅长融资的连续创业者。

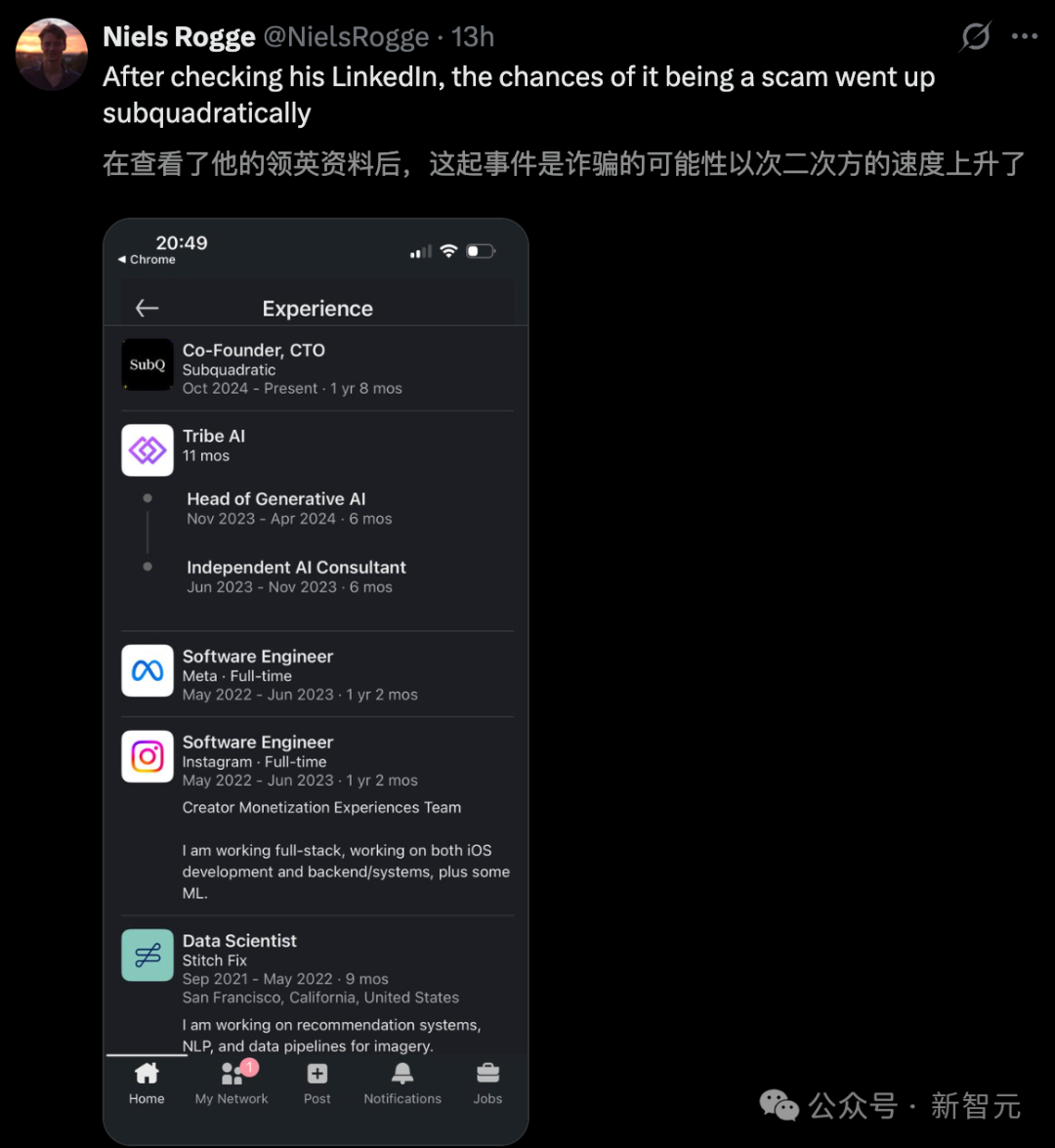
OpenAI 前研究员 Will Depue 更是连发数条推文,指出“这几乎可以肯定是对 Kimi 或 DeepSeek 进行的稀疏注意力微调”。他还质疑道:“如果你真的是亚二次方复杂度,为啥上下文长度只做到 1200 万?如果是 n log n 或者 n^1.25 的复杂度,那至少在演示里整出个一亿上下文来看看啊,兄弟。”
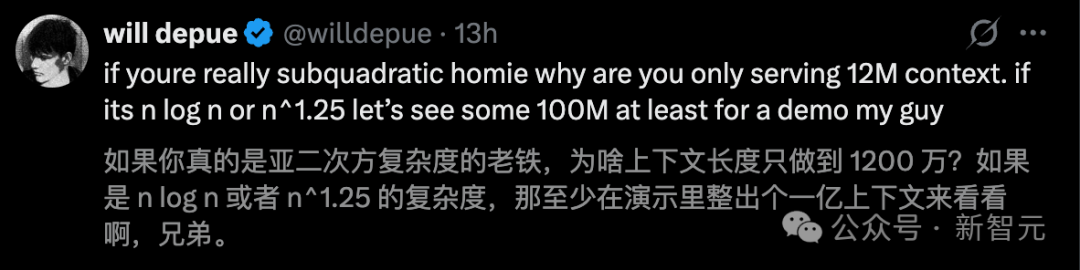

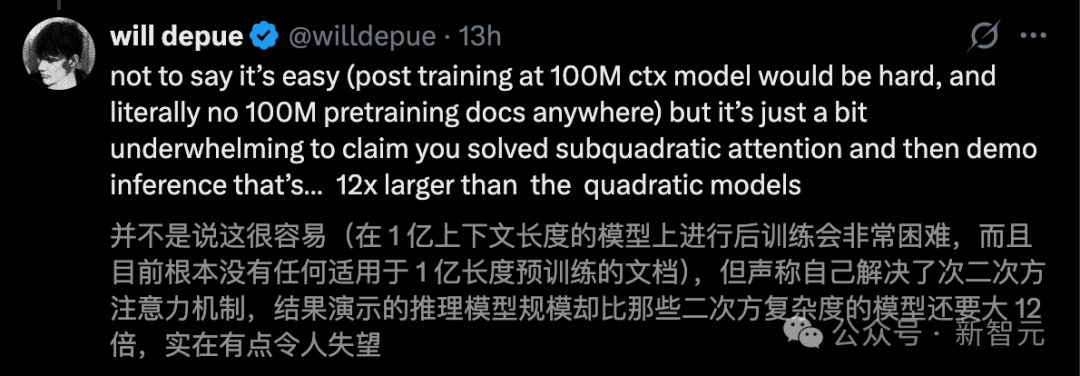
AI 圈见证了太多“发布即巅峰”的故事,发布会上的 PPT 与真实世界的部署之间,往往隔着一整条死亡谷。但也正因这个赌注如此巨大,整个行业才不敢不认真对待。
答案,也许只有等技术报告公开,并经独立的基准测试复现之后,才会真正揭晓。
参考资料:
https://x.com/alex_whedon/status/2051663268704636937?s=20
https://subq.ai/how-ssa-makes-long-context-practical
https://x.com/daniel_mac8/status/2051710659822305661?s=20
在技术浪潮瞬息万变的今天,SubQ 究竟是颠覆性的突破,还是一场精心的炒作,仍有待时间检验。但可以肯定的是,关于下一代基础模型架构的竞赛,已经进入了白热化阶段。对于追求前沿技术的 云栈社区 的开发者们而言,这无疑是一个值得持续关注和深入探讨的焦点。
 发表于 1 小时前
|
查看: 4|
回复: 0
发表于 1 小时前
|
查看: 4|
回复: 0
