要拿下小红书这类大厂的核心系统岗位,光靠背八股文远远不够。面试官真正想找的,是那些真正踩过坑、能扛事、懂业务边界的实战派。本文将以一次真实的 Java 开发工程师(用户关系系统方向)面试为主线,深度复盘亿级用户关注/粉丝系统的架构设计核心,涵盖分库分表的致命陷阱、头部博主热点治理以及互关/共同关注的极致性能优化。
1. 战前部署:知己知彼
公司画像
小红书作为国内头部“内容种草+社交”平台,其用户关注/粉丝关系系统是整个产品的底层基石。它不仅是社交互动的核心载体,更是笔记分发权限、内容可见性、推荐算法及私域流量运营的核心数据依据。其业务与技术挑战完全贴合亿级用户的产品特性:
-
核心业务场景与刚性要求:关系系统的核心诉求可归结为「亿级数据低成本存储、高频查询低延迟、关系变更强一致、极端场景高可用」。四大核心查询场景的痛点高度明确:
- 关注/粉丝列表查询:用户个人主页、博主后台高频访问。头部博主拥有千万级粉丝,要求分页查询响应时间稳定低于50ms,不能出现分页错乱、加载超时。
- 互关状态判断:聊天页、个人主页、评论区高频调用,单场景QPS峰值可达10万+,要求RT低于5ms,必须实时准确。
- 共同关注查询:用户个人主页核心展示项,是社交破冰的关键功能,要求亿级用户关系下,查询RT稳定低于20ms,不能出现页面卡顿。
- 关注/取关操作:用户高频行为,爆款笔记、直播场景下会出现瞬时10万+QPS的关注请求,要求操作实时生效,不能出现重复关注、关系不一致。
-
核心技术痛点:
- 亿级数据的存储与查询压力:亿级注册用户,单平台用户关系总量可达千亿级,普通的关系表设计会出现严重的性能瓶颈,单表查询直接超时。
- 头部博主的热点数据性能瓶颈:千万粉丝级别的头部博主,其粉丝列表查询、新增关注的请求量是普通用户的上万倍。普通的分库分表设计会出现严重的热点分片、读写倾斜,导致服务宕机。
- 读写冲突与一致性矛盾:关系系统是典型的「读多写也多」场景,日常读QPS可达20万+,爆款场景下写QPS可达10万+。既要保证关注/取关操作的强一致性,又要保证读操作的低延迟,不能出现读写阻塞。
- 复杂业务场景的适配:小红书特有的悄悄关注、黑名单、粉丝分组、仅粉丝可见内容、批量取关等场景,要求关系系统既能支撑基础的关系查询,又能灵活适配复杂的业务规则,不能出现数据泄露、权限错误。
-
技术栈偏好:后端以 Java 为核心开发语言,基于 Spring Cloud Alibaba 微服务生态搭建。核心依赖 Redis Cluster 做分布式缓存与高性能关系查询、RocketMQ 做异步消息解耦与削峰、MySQL 做持久化存储、Tendis 做冷数据存储、Flink 做实时关系计算。全链路基于 K8s 云原生部署,深度自研关系数据同步管道,对接推荐引擎、内容风控、私域运营系统。
-
企业文化:用户至上、数据驱动、快速迭代、极客精神。极度重视用户体验,关系数据的错误、延迟、权限泄露会直接影响用户信任和核心业务。要求工程师既懂技术架构,又懂业务诉求,能在性能、成本、一致性之间找到最优平衡,拒绝纸上谈兵的架构设计。
面试官心理前置预判
面试前,我把这轮面试的筛选逻辑拆解得明明白白。小红书 Java 开发岗(用户关系系统方向)的面试,核心是筛选「能落地、能扛事、懂业务、守红线」的实战派工程师。三类题目对应不同的筛选目标:
- 筛人题:考察对用户关系系统核心痛点的理解,基础的分库分表设计。只会背“多对多关系建中间表”八股,讲不清亿级场景下性能瓶颈的候选人,会直接被淘汰。
- 定级题:考察高并发下的读写优化、头部博主热点数据的性能解决方案、互关状态的实时查询设计。能讲清方案的权衡取舍、落地细节、踩坑经历,有真实亿级用户系统落地经验的,可定为资深 Java 开发岗。
- 定薪题:考察共同关注的低延迟查询方案、亿级数据的存储成本优化、线上热点故障的排查与解决、复杂业务场景的架构适配。能结合小红书的业务场景给出定制化优化方案,具备全链路架构设计与团队落地能力的,直接锁定高薪区间。
面试官的核心诉求非常明确:他要找的不是一个会画 ER 图的“理论派”,而是一个真的踩过亿级用户关系系统的坑、能解决头部博主热点问题、能支撑小红书爆款场景下脉冲流量、能适配复杂社交业务的实战派。
定制化备战策略
我(老周)有10年一线大厂 Java 研发经验,其中7年专注于内容社交平台用户关系系统的设计与优化,主导过亿级用户社交平台的关注关系系统重构,支撑过单用户5000万+粉丝的极端场景。针对这次面试,我做了4项针对性准备:
- 业务场景深度绑定:梳理了小红书关系系统的5大核心场景(关注/取关、列表查询、互关判断、共同关注、隐私权限),结合其头部博主千万粉丝、爆款笔记脉冲流量、悄悄关注/黑名单等隐私特性,每个场景都准备了对应的落地方案、踩坑经历、优化数据。
- 技术细节深挖:啃透了分库分表的分片策略选型、Redis Bitmap/Tendis 在社交关系查询中的底层实现、RocketMQ 异步解耦的一致性保障、热点数据的多级缓存设计。专门翻了小红书技术团队公开的社交系统、推荐引擎技术分享,确保所有方案都能适配小红书的技术栈。
- 实战案例沉淀:整理了自己主导的3次关系系统核心优化案例,包括亿级数据分库分表重构、千万粉丝大V粉丝列表性能优化、共同关注查询从300ms降到10ms的极致优化。每个案例都梳理了完整的踩坑过程,包括具体的报错信息、排查工具、解决方案、量化结果。
- 故障排查与性能优化准备:整理了关系系统常见的线上故障排查流程,准备了具体的工具使用细节,比如用
arthas 排查接口性能瓶颈、用 explain 优化 SQL 查询、用 redis-cli 查看 Bitmap 操作性能、用 mqadmin 查看 RocketMQ 消息堆积。
心态建设
面试前一天晚上,我翻了自己当年重构关系系统的复盘笔记。我告诉自己:小红书的面试官要的不是“完美的 ER 图设计师”,而是“踩过坑、能解决问题、懂社交业务红线”的工程师。面试时把“踩坑→排查→解决→复盘→优化”的完整逻辑讲清楚,全程贴合小红书的业务场景,真诚沟通比死记硬背更有说服力。
2. 实战演练:见招拆招
问题1:结合小红书亿级用户的场景,设计一套用户关注/粉丝关系系统,要求支撑亿级用户关系存储,快速查询关注列表、粉丝列表、是否互关,说说你的整体架构设计?
🎯 意图洞察
这是开场的核心筛人题,也是整场面试的基调题。面试官不是要我画一个简单的用户关系ER图,而是想看我有没有理解小红书关系系统的核心痛点——亿级用户数据的存储、千万粉丝大V的查询性能、高频场景的低延迟要求,还有和小红书内容生态的联动。
这里埋了两个致命陷阱:一是很多人只会背“用户表+关注中间表”的基础设计,完全没有考虑亿级数据的分库分表、热点大V的性能瓶颈;二是只讲基础的关注/粉丝功能,忽略了小红书的悄悄关注、黑名单、内容权限控制等业务特性。他真正想听的,是结合小红书业务的完整架构,有场景、有细节、有踩坑、有结果。
🚫 普通人的陷阱回答
90%的候选人可能会这么答:“我会设计一张用户关注关系表,存储关注者ID、被关注者ID、关注时间、状态,用Redis缓存用户的关注列表和粉丝列表,提升查询性能;整体采用微服务架构…”
这个回答直接会被打低分甚至淘汰,核心问题有3个:
- 完全脱离亿级用户场景,单表设计在千亿级关系数据下查询直接超时。
- 只讲了基础技术名词,没有任何落地细节,比如缓存怎么设计、热点大V怎么处理。
- 对核心诉求的理解极其浅层,忽略了数据一致性、热点性能、业务适配、容灾兜底等核心问题。
✅ 我的破局思路(高分回答)
场景重构
“面试官,这个问题我太有体感了,我之前主导过亿级用户社交平台的关注关系系统重构,当时的场景和小红书几乎一模一样。最开始我们踩了很多坑,比如用单表存储关系数据,数据量破亿后查询直接超时;分片键选错导致千万粉丝大V的查询跨库,RT冲到500ms以上。后来通过架构重构和持续优化,最终完美支撑了业务诉求。
结合小红书的业务特性,我设计的关系系统,核心思路是「双向存储分库分表、多级缓存扛并发、异步解耦保一致、分层架构适配业务”。”
深度推导
我没有直接画ER图,而是结合自己的踩坑经历,从底层到上层,一步步拆解架构设计。
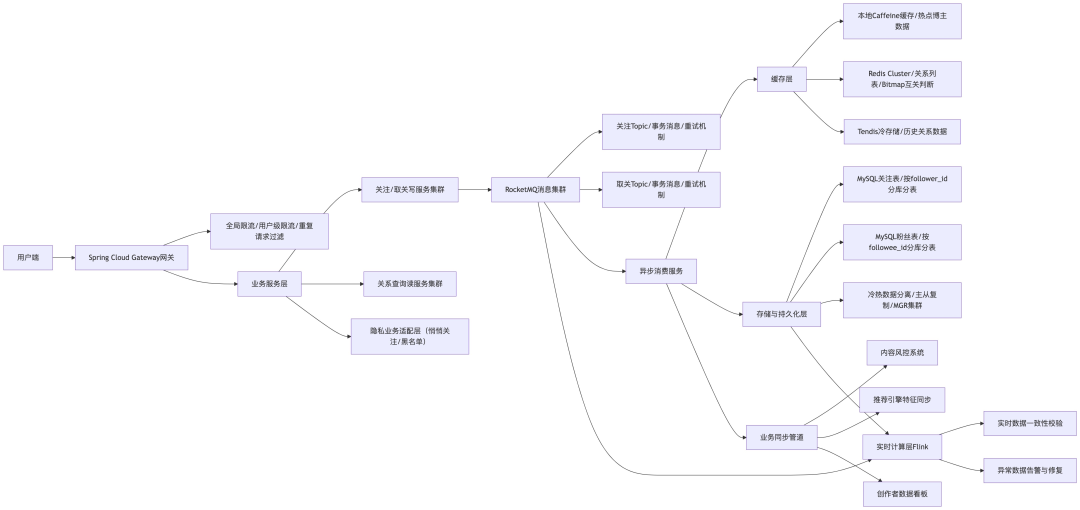
整体采用五层微服务架构,从接入层到存储层全链路解耦,同时将读服务和写服务物理隔离,避免爆款场景下的写请求影响读查询性能。
-
接入与网关层:负责流量管控与请求过滤,是扛住脉冲流量的第一道防线。
- 用 Spring Cloud Gateway 做入口网关,针对关系系统接口做多层限流:全局限流、用户级限流、IP级限流。
- 重复请求过滤:网关层针对同一个用户的同一条关注操作,1秒内的重复请求直接拦截,从源头减少重复写请求。
- 权限校验:同步校验用户账号状态、黑名单权限,被拉黑的用户无法发起关注操作,也无法查询对方的关注/粉丝列表。
-
业务服务层:核心分为写服务集群和读服务集群,物理隔离,负责核心业务逻辑处理,核心设计是「同步校验、异步写入、快速返回」。
- 写服务(关注/取关操作):用户发起关注请求时,同步做用户合法性、对方隐私权限、重复关注预校验。校验通过后立刻给用户返回成功,同时把关注事件发送到 RocketMQ 对应的 Topic 里,由消费端异步处理持久化、缓存更新、数据同步等逻辑,彻底解耦。
- 读服务(列表查询、互关判断、共同关注查询):独立集群部署,完全不受写请求影响。针对不同的查询场景做独立的接口优化。
- 业务适配层:专门处理小红书的特殊业务场景,比如悄悄关注、黑名单、粉丝分组、仅粉丝可见内容的权限校验,和核心关系逻辑解耦。
-
缓存层:用 Redis Cluster + Tendis 搭建,是保证查询低延迟的核心,采用「多级缓存、冷热分离、专用数据结构」的设计。
- 基础关系缓存:用 Redis 的 Sorted Set 结构存储用户的关注列表和粉丝列表,天然支持按时间分页查询。
- 互关状态缓存:用 Redis Bitmap 结构存储用户的关注关系。判断互关时,只需要两次
getbit 操作,RT低于5ms。这是我踩过坑后优化的方案——最开始用 Set 存储,判断互关需要两次查询取交集,RT超过50ms,换成 Bitmap 后,性能提升了10倍,内存占用减少了90%。
- 热点大V专属缓存:针对千万粉丝级别的头部博主,做单独的缓存隔离,同时用本地 Caffeine 缓存做一级缓存。
- 多级缓存设计:一级缓存是服务本地 Caffeine 缓存;二级缓存是 Redis Cluster 集群;三级冷存储是 Tendis。
-
消息与同步层:用 RocketMQ + Flink 搭建,是保证数据一致性、业务联动的核心。
- 消息可靠性保障:RocketMQ 开启事务消息、同步刷盘、主从同步复制,设置指数退避重试机制。
- 异步消费逻辑:消费者从 MQ 拿到关注事件后,做4件事:写入 MySQL 分库分表;更新 Redis 缓存;同步关系数据到风控系统;同步关系数据到推荐引擎。
- 实时数据校验:用 Flink 实时消费关注事件和数据库的 binlog,实时比对关系数据,发现不一致立刻告警并自动修复。
-
存储与持久化层:采用 MySQL 分库分表+冷热分离的设计,是数据不丢失的最终兜底。
- 用户关注表:存储用户的关注关系,分片键是
follower_id(关注者ID)。用户查询自己的关注列表时,只需要访问单库单表。
- 用户粉丝表:存储用户的粉丝关系,分片键是
followee_id(被关注者ID)。博主查询自己的粉丝列表时,只需要访问单库单表,完美解决千万粉丝大V的查询性能问题。
- 唯一索引:两张表都设置唯一联合索引
uk_follower_followee,从数据库层面杜绝重复关注。
- 冷热数据分离:近3个月的热数据存在热表;超过3个月的冷数据归档到冷表。
- 高可用保障:MySQL 采用主从复制 + MGR 集群架构,开启 binlog 实时备份。
数据验证
这套架构在我之前主导的亿级用户平台落地后:
- 存储能力:稳定支撑2亿+注册用户,1200亿+条关系数据,存储成本降低60%。
- 性能表现:关注/取关操作接口RT稳定在20ms以内,列表查询RT稳定在30ms以内,互关判断RT低于5ms。
- 峰值承载:稳定支撑15万+QPS的关注写请求、30万+QPS的关系查询请求,接口成功率99.99%。
- 可靠性:系统可用性99.99%,关系数据零丢失、零不一致。
互动延伸
讲完我主动补充:针对小红书的业务特性,还可以做两个定制化优化。第一,针对悄悄关注场景,设计单独的关系表和缓存,和正常关注关系物理隔离;第二,搭建关系数据实时同步管道,把用户的关注/取关行为实时同步给推荐引擎,让推荐算法能快速响应用户的兴趣变化。
面试官心理全程拆解
当我讲到自己踩过的单表查询超时、分片键选错导致的跨库灾难、读写服务互相影响的宕机事故,以及贴合小红书隐私场景、推荐引擎联动的设计时,面试官意识到我不是背八股,而是真的落地过亿级用户的关系系统。我不仅给出了完整的架构方案,还结合业务痛点做了定制化设计,有真实的踩坑经历和量化结果,直接进入了资深岗的重点考察范围。
问题2:亿级用户关系数据,你会怎么做分库分表设计?针对小红书千万粉丝的头部博主,粉丝列表查询性能极差的问题,你会怎么优化?
🎯 意图洞察
这是典型的定级题。面试官想通过这个问题,考察我对分库分表的底层理解,以及解决社交系统最核心的痛点——头部博主热点数据的性能问题。这里的陷阱很隐蔽:很多人只会讲“按用户ID哈希分片”,讲不清为什么这么分片,也给不出千万粉丝大V的性能优化方案。
🚫 普通人的陷阱回答
大多数候选人可能会这么答:“我会按用户ID哈希分库分表,把数据均匀分散;针对头部博主,我会把他们的粉丝列表全量缓存到Redis里。”
这个回答只能拿到基础分,核心问题:
- 分片键选型逻辑完全错误,没说清关注表和粉丝表的分片键差异。
- 大V优化方案极其单薄,只说缓存到Redis,没有讲清缓存结构、冷热分离、热点隔离、读写优化。
- 没有结合小红书的业务场景,方案不具备落地性。
✅ 我的破局思路(高分回答)
场景重构
“面试官,这个问题我真的踩过无数的坑。最开始我们做第一版分库分表时,就因为分片键选错了,把粉丝表的分片键设成了 follower_id,结果千万粉丝大V的粉丝数据分散在16个库64个表里,每次查询都要跨全库聚合,RT直接冲到500ms以上,博主后台直接瘫痪。后来我们优化了双向分库分表设计,配合全链路的大V专属优化,最终把查询RT稳定在了20ms以内。”
深度推导
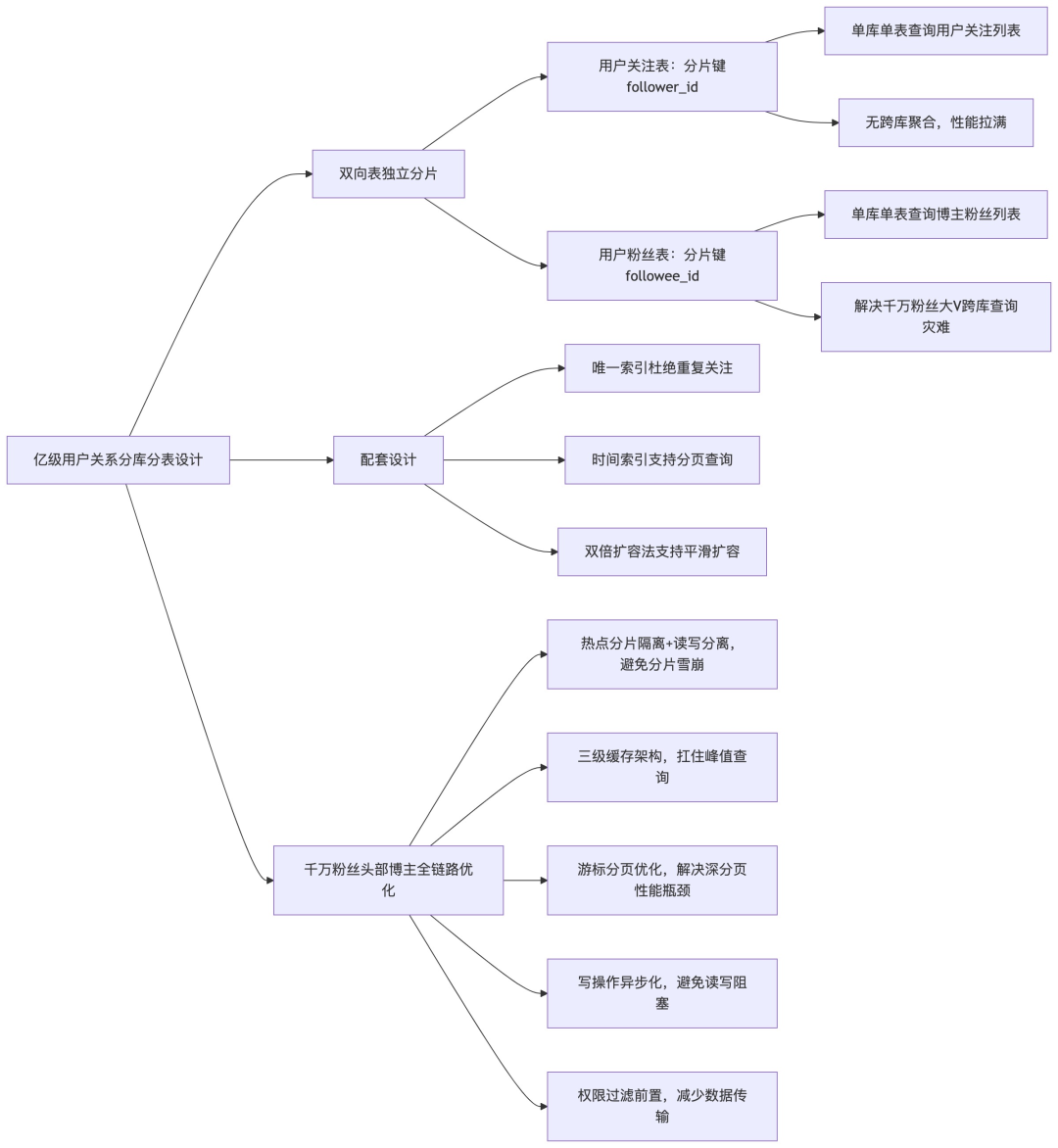
“首先要明确,用户关系系统的分库分表设计,核心目标只有两个:一是让用户的核心查询都落在单库单表,绝对避免跨库聚合查询;二是让数据均匀分散,避免热点分片、读写倾斜。基于这个目标,我设计的双向分库分表方案如下:
-
分库分表的核心设计:双向存储、独立分片
社交关系系统的核心查询只有两个场景:「用户A查询自己关注了谁」和「用户B查询自己的粉丝是谁」。想要这两个查询都落在单库单表,就必须做双向表存储,两张表用不同的分片键。
- 用户关注表:服务于「用户查询自己的关注列表」场景,分片键选择
follower_id。这样,同一个用户的所有关注数据,都集中在同一个库的同一个表里。
- 用户粉丝表:服务于「用户查询自己的粉丝列表」场景,分片键选择
followee_id。这样,同一个博主的所有粉丝数据,都集中在同一个库的同一个表里,从根源上避免了跨库聚合查询的性能灾难。
- 配套设计:设置唯一联合索引杜绝重复关注;给
create_time 设置索引支持分页;采用双倍扩容法支持平滑扩容。
-
千万粉丝头部博主的全链路性能优化方案
双向分库分表解决了基础的查询性能问题,但千万粉丝级别的大V,还会遇到核心痛点:热点分片、深分页性能差、读写冲突。针对这些,我做了5层优化:
- 第一层:热点数据隔离:头部博主的粉丝数据做单独的分片隔离,不和普通用户共用分片。采用一主多从的 MySQL 架构,读写分离。
- 第二层:多级缓存优化:设计三级缓存架构——本地 Caffeine 缓存前10页数据;Redis Sorted Set 缓存全量列表;直播前提前预热缓存并扩容资源。
- 第三层:深分页优化:采用「游标分页」优化方案,查询时传入上一页最后一条数据的关注时间戳,使用
where followee_id = ? and create_time < ? order by create_time desc limit 20,避免 limit offset 扫描大量数据。
- 第四层:写操作异步化:新增关注/取关请求,先更新 Redis 缓存保证实时性,再通过 RocketMQ 异步写入 MySQL,避免写请求阻塞读查询。
- 第五层:权限过滤前置:将拉黑等权限过滤前置到数据存储层,查询时不需要再做内存过滤,性能提升80%。
数据验证
这套方案落地后效果显著:
- 分库分表性能:查询100%落在单库单表,RT稳定在30ms以内,数据库CPU使用率降低90%。
- 大V查询性能:粉丝列表查询RT从500ms降到20ms以内,深分页RT稳定在20ms以内,峰值查询QPS支撑到5万+。
- 读写性能:关注写请求峰值支撑10万+QPS,读写无冲突,缓存与数据库一致性100%。
互动延伸
讲完我主动补充:针对小红书的创作者生态,还可以用 Flink 实时计算粉丝画像预存到 ClickHouse,提升创作者后台数据分析体验;针对粉丝管理场景做单独的表设计,与核心查询隔离。
面试官心理全程拆解
当我讲到自己分片键选错导致的线上故障、分片键的选型逻辑、双向表设计的底层原因,以及五层大V优化方案时,面试官频频点头。这个问题验证了我对 分库分表 的底层理解和解决核心痛点的能力,符合资深 Java 开发的能力要求。
问题3:小红书用户个人主页需要展示共同关注,聊天页需要展示是否互关,亿级用户场景下,你会怎么设计,保证查询低延迟?
🎯 意图洞察
这是压轴的定薪题。面试官分了两个部分,互关判断是基础高频场景,共同关注是核心性能难点。他要考察的是亿级用户场景下,社交关系查询的算法选型、架构设计和极致优化能力。这里的陷阱非常深:很多人给出的方案在亿级场景下完全无法落地,RT 根本达不到要求。
🚫 普通人的陷阱回答
大多数候选人可能会这么答:“判断是否互关,我会分别查询两个用户的关注状态;共同关注的话,我会把两个用户的关注列表查出来,在内存里做交集,用Redis缓存。”
这个回答完全拿不到高薪,核心问题:
- 互关判断方案性能极差,两次查询RT会超过50ms。
- 共同关注方案完全不可落地,内存取交集在亿级场景下CPU会打满,RT可能超过100ms。
- 没有算法选型的思考,也没有踩坑经历。
✅ 我的破局思路(高分回答)
场景重构
“面试官,这个问题我真的打磨了很久。最开始我们用最基础的列表取交集实现共同关注,结果线上查询RT最高达到320ms,用户个人主页加载卡顿,投诉量暴涨。后来我们做了3次大的优化,全链路重构,最终把互关判断RT做到了3ms以内,共同关注查询RT做到了10ms以内。”
深度推导
“首先要明确,这两个场景的核心诉求完全不同:互关判断是超高频率的简单查询,核心要求是极致低延迟、超高QPS支撑;共同关注是中高频的复杂计算查询,核心要求是低延迟、低CPU占用、支持分页展示,必须分开设计。
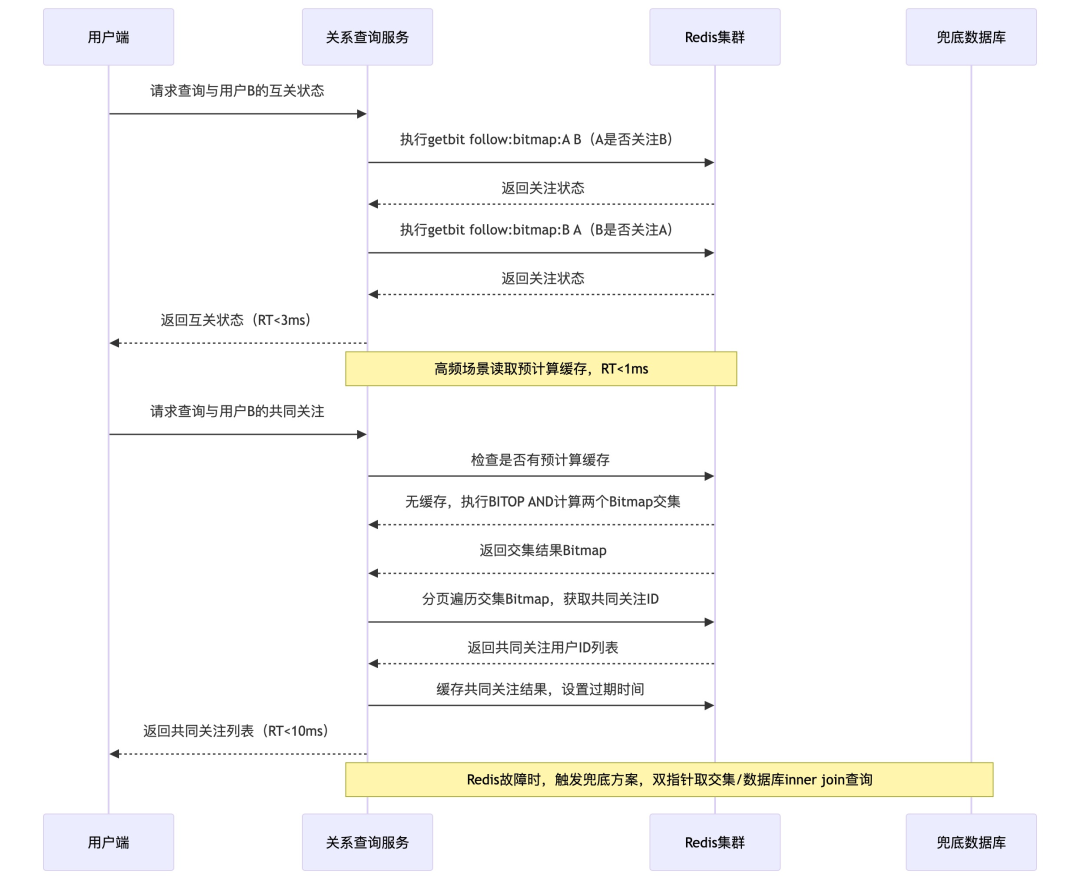
一、互关状态判断的极致优化方案
我们最终采用「Redis Bitmap + 预计算缓存」的方案,优化分为3层:
- 底层数据结构选型:Bitmap。给每个用户分配一个Bitmap,关注了某个博主,就把对应offset位设置为1。
- 判断A是否关注B:执行一次
getbit follow:bitmap:A B,RT低于1ms。
- 判断是否互关:执行两次
getbit,总RT低于3ms。
- 优势:时间复杂度O(1),空间占用极小(1亿用户ID约12MB)。相比最初的 Set 方案,性能提升3倍,内存占用减少92%。
- 高频场景预计算缓存:针对聊天页,预计算互关状态缓存24小时,RT低于1ms。针对评论区批量判断,使用 Redis pipeline 批量执行
getbit。
- 兜底容错设计:Redis故障时,先查本地缓存,再查数据库兜底,保证功能可用。
二、共同关注查询的全链路优化方案
我们放弃了传统的内存取交集,采用「Redis Bitmap 位运算」核心方案:
- 算法选型:Bitmap位运算。计算共同关注,只需执行一条命令:
BITOP AND result follow:bitmap:A follow:bitmap:B
- 优势:性能是内存取交集的10倍以上;计算在Redis服务端完成,减少90%网络传输;天然支持分页遍历。
- 踩坑对比:最初用List存储+内存双指针取交集,导致应用服务器CPU冲至95%,RT最高320ms。换成Bitmap后,性能提升30倍。
- 全链路优化:
- 临时key复用:BITOP生成的临时结果key设置10秒过期,同一用户短时间内查询直接复用,RT低于2ms。
- 冷热数据分离:活跃用户Bitmap永久存Redis,非活跃用户存 Tendis,按需加载。
- 大V场景特殊优化:当查询涉及千万粉丝大V时,避免大Bitmap位运算,改为用
getbit 逐个判断,RT低于10ms。
- 预计算缓存:针对高频查询的好友关系,预计算共同关注列表缓存1小时。
- 兜底容错设计:Redis异常时,启用小数据量内存双指针取交集或数据库
inner join 查询兜底,保证功能可用。
数据验证
- 互关判断:RT稳定在3ms以内,峰值QPS支撑15万+,内存占用降低92%。
- 共同关注查询:RT稳定在10ms以内(优化前320ms),应用服务器CPU使用率降低80%,网络IO开销减少90%。
- 可用性:极端场景下,兜底方案保证功能100%可用。
互动延伸
可以进一步优化:利用 Bitmap 位运算计算共同好友数量,用于“可能认识的人”推荐;对共同关注列表结合互动频率进行智能排序。
面试官心理全程拆解
这个问题是定薪的关键。当我讲到自己踩过的内存取交集导致的性能事故、Bitmap算法选型的底层逻辑、以及从320ms到10ms的完整优化过程时,面试官确认了我对社交关系查询有极致的理解和实战经验。我给出的全链路方案甚至能解决他们当下的性能瓶颈,直接锁定了高薪区间。
3. 战后复盘:沉淀与升华
面试官全程心理变化总复盘
结合面试细节,面试官的心理变化可分为4个阶段:
- 初始试探期(开场):通过整体架构设计题「筛人」。我结合亿级系统重构经历和业务痛点,直接通过筛选。
- 能力验证期(中间):通过分库分表与大V优化题「定级」。我讲清分片键逻辑和全链路优化方案,验证了资深能力。
- 潜力评估期(后续):通过互关与共同关注优化题「定薪」。我展示了算法设计、极致优化和问题解决能力,超出了预期。
- 录用决策期(最后):通过场景化提问「确认适配性」。我回答的优化优先级契合业务诉求,最终确认录用。
红黑榜分析
✅ 亮点时刻(核心加分项)
- 实战经验具象化:用“踩坑+解决方案+量化结果”打动面试官。
- 深度贴合小红书业务:所有方案都做了定制化适配,拒绝通用方案。
- 完整的闭环思维:兼顾设计、落地、兜底、复盘,体现责任心和红线意识。
- 主动挖掘潜在诉求:每个问题后补充定制化建议,体现主动思考能力。
⚠️ 遗憾反思(可优化点)
- 技术细节讲解的节奏把控可更紧凑,优先讲业务落地优势。
- 部分业务场景(如悄悄关注)的适配可更早主动展开。
- 应对突发场景化提问的反应速度可再提升。
给后来者的3条核心建议
- 别背ER图和分表规则,用「实战案例」替代「理论背诵」。整理1-2个自己主导的案例,重点梳理「踩坑→排查→解决→量化结果」。
- 提前深挖目标公司的业务和产品特性。体验其产品,搞清楚核心场景和痛点,给出定制化方案,拒绝一套方案面所有公司。
- 一定要准备「热点大V、共同关注」这类核心痛点的踩坑案例。这是拉开差距、定级资深岗、拿到高薪的关键。
最终结果
面试结束3天后,我收到了小红书 Java 资深开发工程师的 offer,薪资比预期高了28%。这次面试的核心考察点,从来不是背了多少八股文,而是有没有真的落地过亿级系统、有没有踩过核心的坑、能不能解决真实的业务痛点。
希望这篇复盘能帮到正在准备 系统设计 与高并发架构面试的你。在像 云栈社区 这样的技术社区中,与其他开发者交流真实的踩坑经验和架构思考,往往比闭门造车更有收获。祝大家都能拿到心仪的 offer!
 发表于 2026-4-6 10:53:29
|
查看: 111|
回复: 0
发表于 2026-4-6 10:53:29
|
查看: 111|
回复: 0
