
“同事.Skill”这个GitHub项目火出圈了。随后,什么“老板.Skill”、“前任.Skill”也跟着冒了出来,仿佛你身边的每个人都能被“Skill”化成一个数字分身,实现7*24小时在线陪伴。
媒体那边也热闹,有的说它能“完美复刻同事的语气、甩锅姿势”,还有的说它“彻底替代你的同事”。讲真的,上次我看到这么有赛博朋克味道的事,还是在《战锤40K》里太空死灵种族的背景故事里。
这让我一度怀疑自己是不是穿越了。看了一眼手机,一切正常。于是我重新梳理了整个事件,最后发现,这本质上是一次开发者社区的玩梗狂欢,却在传播链中被过度解读,甚至变得煞有介事。这也不难理解,在人人担心被AI替代的今天,焦虑往往比真相跑得更快。
所谓的“炼化同事”,其实就是个爬虫加提示词模板
“同事.Skill”这个项目,结构其实很简单。
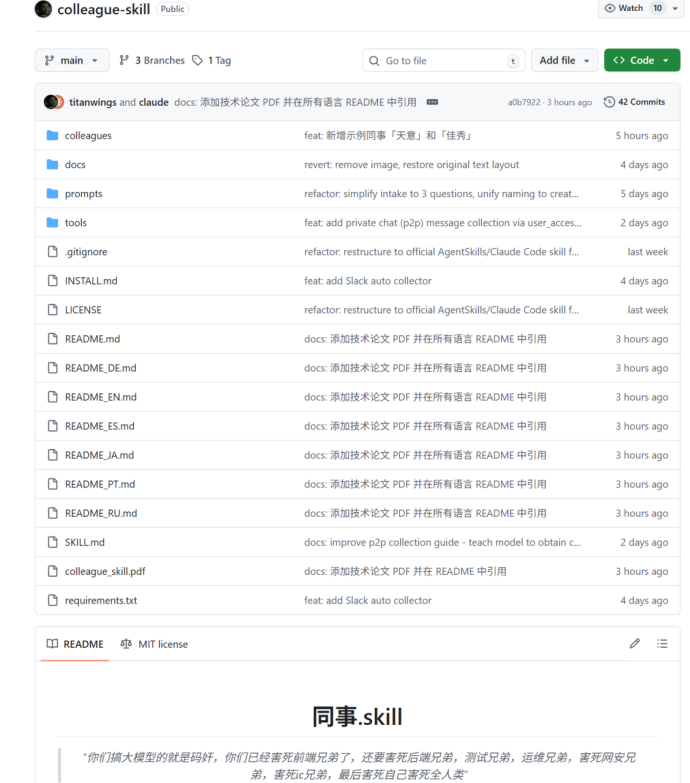
在colleagues文件夹下,每个“数字同事”就是一个独立的子目录。里面通常包含几个Markdown文件:Skill.md是主入口,work.md描述工作内容,persona.md描述性格特征,再加一个meta.json存放元数据。仅此而已。
所有信息都被总结成了几个静态文本文件。它没有使用向量数据库进行语义检索,也不涉及任何真正的模型训练。
它的工作流程也非常直白。项目提供了几个Python脚本,比如feishu_auto_collector.py用来抓取飞书消息和文档,dingtalk_auto_collector.py抓取钉钉数据,wechat_parser.py解析微信聊天记录,email_parser.py处理邮件。
这些脚本干的就是数据爬取和格式转换的活儿,把原始文本整理成统一格式。然后,把这堆文本喂给大模型(比如Claude),让它总结出这个人的“工作能力”和“性格特征”,从而生成上述那几个Markdown文件。
运行时就更加简单了。当你调用这个Skill,Claude就会读取那几个静态的Markdown文件作为上下文,然后按照里面描述的风格跟你对话。这就像你给一个演员一份详细的角色剧本,告诉他“你现在要扮演一个说话爱用感叹号、经常把问题甩锅给测试部门的产品经理”,演员照着演就行。
所以说,“同事.Skill”本质上是一个遵循AgentSkills标准的提示词工程加上数据爬虫的项目。它根本不是什么AI训练项目,更谈不上是赛博永生。
项目中提到的“五层人格结构”确实存在,但这仅仅是提示词的一种组织方式,并非对这个人的思维和知识进行深度剖析,里面并没有什么高深莫测的黑科技。
在persona.md文件里,人格描述被分成了五层(Layer):
- Layer 0 是硬性规则,优先级最高。
- Layer 1 是身份认知,比如“我是前端工程师”。
- Layer 2 是表达风格,比如“说话简洁,不爱用emoji”。
- Layer 3 是决策模式,比如“遇到技术选型时倾向保守方案”。
- Layer 4 是人际行为,比如“不主动参与办公室争论”。

项目运行规则也写得很清楚:先由persona部分判断用什么样的态度来接收任务,再由work部分运用技术能力去完成任务,输出时则始终保持persona所定义的表达风格。
说到底,它只是在给Claude写一份极其详细的角色扮演指南。
这种设计带来了几个明显的局限性。首先,是记忆问题。这些Skill没有持久化的记忆系统。每次对话都是重新读取那几个静态Markdown文件,不会根据新的交互进行学习和更新。你跟它聊的内容,下次再调用时它就全忘了。
其次,是原材料决定上限。项目README里那句话说得很实在:“原材料质量决定Skill质量”。计算机领域有个著名的原则叫GIGO(Garbage In, Garbage Out),翻译过来就是“垃圾进,垃圾出”,完美概括了这里的情况。
如果你的前同事本来就不爱在聊天软件里多说话,记录里全是“收到”、“好的”、“1”,那生成的Skill基本就是个复读机。如果聊天记录里技术讨论很少,大多是闲聊和吐槽,那这个Skill也只会陪你闲聊和吐槽。
第三,人格漂移不可避免。由于这是你强加给模型的扮演设定,在长时间、多轮次的对话中,随着上下文窗口被新的对话内容填满,最初定义人格的那段提示词的权重会被稀释,模型就会逐渐“忘记”自己应该扮演的角色,出现人格漂移。
最后,也是最重要的一点:这个所谓的“炼化”,无法蒸馏出真正的专业知识和判断逻辑。这里会出现一种“专家悖论”现象:你越让AI扮演一个懂技术、有知识的专家角色,它反而越有可能输出错误或似是而非的答案。
因为一旦要求AI扮演专家,它会优先模仿专家的表达方式、语气甚至某些职业腔调,但这些额外的约束反而会干扰模型对问题本身进行冷静、客观的判断。
“同事.Skill”能提取的,其实只是最表层的东西:
- 口头禅和表达习惯(比如“习惯用‘嗯嗯’开头”、“喜欢用省略号”)。
- 常用的技术栈和工具(比如“熟悉React和TypeScript”)。
- 显性的工作流程(比如“代码提交前必须先跑一遍单元测试”)。
但它提取不了复杂情境下的判断力。当一个从未遇见过的新技术问题出现,需要权衡性能、成本、开发周期等多个因素时,这个Skill给不出真正有洞察力的建议。它也提取不了创新性的问题解决能力——真正的工程师能在遇到瓶颈时想出巧妙的解决方案,而Skill只能重复它从数据中见过的模式。它更提取不了基于多年经验积累的、那种“感觉这里可能有坑”的工程直觉。
说这个Skill能“用他的技术规范写代码”,这话只对了一半。它确实能输出符合某种代码风格(如命名规范、缩进格式)的片段。但遇到真正需要架构决策的时候,比如要不要引入新技术栈、如何设计系统扩展性、怎么平衡技术债务与业务需求,它就只能给出模棱两可的套话,或者干脆重复训练数据里见过的标准答案。
说到底,这是一个很有想法的项目,展示了如何用结构化的方式去封装和定义“数字人格”。它更像是一个带预设人设的聊天机器人,或者说是一个智能化的、可交互的工作日志。把它定位为一种知识传承或工作交接的辅助工具,是合理的。但如果真以为它能替代一个活生生的人,那恐怕是被误导了。
这事背后,其实藏着不小的法律风险
“同事.Skill”在项目说明里写得很清楚,需要把同事的飞书消息、钉钉文档、邮件“喂”进去。这句话背后,其实藏着巨大的法律风险。
问题的核心在于离职后的数据使用权。
《中华人民共和国个人信息保护法》第十三条明确规定,处理个人信息需要满足下列条件之一:
- 取得个人的同意;
- 为订立、履行合同所必需;
- 为履行法定职责或者法定义务所必需;
- 为应对突发公共卫生事件;
- 在合理的范围内处理已公开的个人信息。
现在的情况是:员工已经离职,劳动合同关系已经解除。公司继续使用他工作期间产生的数据来“炼化”成数字人格,这属于哪一条?
答案是哪一条都不属于。 没有取得离职员工的新授权(通常根本没人会去问);劳动合同已解除,不再是“履行合同所必需”;将数据用于AI训练,也超出了员工当初提供信息时(用于工作沟通)的“合理范围”预期。
违反《个人信息保护法》,可能面临责令改正、警告、没收违法所得、罚款等行政处罚。情节严重的,罚款额度可能高达五千万元以下或上一年度营业额的百分之五。
更麻烦的是,工作聊天记录里包含的往往不只有工作内容。可能还有个人健康状况(如“今天身体不舒服,请假”)、家庭情况(如“孩子生病了,要早走”)、财务信息(如“这个月房贷压力大”)、对他人的人际评价等。这些都属于敏感个人信息。
《个人信息保护法》第二十八条规定,处理敏感个人信息需要取得个人的单独同意。注意,这里是“单独同意”,不是入职时签的那份笼统的数据使用协议可以覆盖的。
但在这些Skill项目的操作流程里,完全没有这个“单独同意”的环节。它们只是用爬虫一股脑地把所有聊天记录转换成Markdown格式,再喂给AI,根本不管里面夹杂着什么内容。这意味着每一个被“炼化”的同事Skill,都可能持续违反敏感信息保护的规定。
事情还没完。项目要求用户提供微信聊天数据,甚至还“贴心”地推荐了三款导出工具。
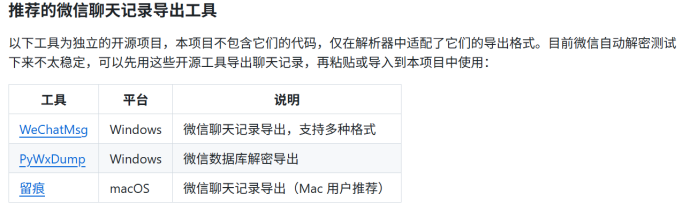
根据《腾讯微信软件许可及服务协议》,未经腾讯书面许可,对微信运行过程中的数据进行复制、读取、衍生开发,均属于违规行为。而《中华人民共和国数据安全法》第四十五条规定,违反数据安全保护义务,造成数据泄露等严重后果,构成犯罪的,依法追究刑事责任。企业数据泄露,是有可能担刑责的。
很多人可能觉得这只是技术圈的“整活”,不会有人真的追究。但“整活”从来不是免死金牌。如果真的有公司开始用这种方式来“留住”离职员工,那恐怕离吃官司就不远了。离职员工发现自己被“数字炼化”,完全有权投诉并要求删除数据、赔偿损失。若因此导致商业秘密或其他员工信息泄露,还可能引发更多法律纠纷。
从技术玩梗到大众神化,传播链上的失真
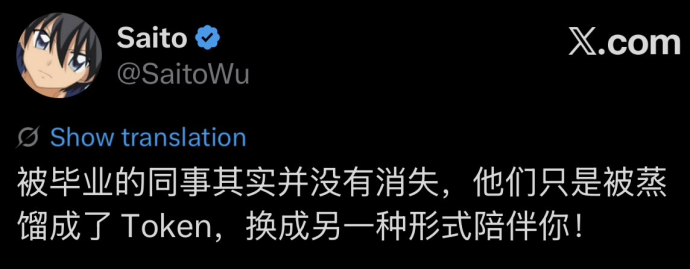
这件事的起源其实很简单。X平台上一名用户发了一条推文调侃:“被毕业的同事其实并没有消失,他们只是被蒸馏成了Token,换成另一种形式陪伴你!”这句话精准地戳中了当下人们对Agent时代的一种普遍焦虑。
这条推文在技术小圈子里引发了共鸣。于是,就有了“同事.Skill”这个具体化的项目。项目在GitHub上发布之初,圈内人都知道这只是一个有趣的玩具。
但事情很快变味了。当“老板.Skill”、“前任.Skill”等衍生项目出现后,话题开始从纯粹的技术实验,转向了带有情感投射和职场隐喻的领域。不了解技术细节的公众看到这些梗,很容易望文生义,以为真的可以把一个人“复活”成一个AI。
当这件事脱离技术社区,进入大众舆论场时,叙事就开始严重偏离事实。 其中的技术难度被放大了,而社会影响则被渲染得更加夸张。一个简单的文本处理工具,被包装成了“数字永生”;一个GitHub上的开源玩具,被解读为“职场生存危机”;一段普通的提示词,被视作“AI替代人类的开端”。
还是那句话,焦虑比真相更具传播力。大众媒体需要的往往不是准确、枯燥的技术细节,而是能引发强烈情绪共鸣的故事标签。这场从技术玩梗到大众神化的传播过程,完美地展示了“技术如何在传播中失真”。
一个项目从开发者社区流传到公共舆论,每经过一个传播环节,技术细节就被简化一层,叙事就被夸张一分。到最后,原本那个用Python写的爬虫脚本,在很多人心中就变成了能实现“赛博永生”的黑科技。
当大多数人不具备基础的AI知识时,就很容易被这种夸张叙事误导。他们分不清提示词工程和模型训练的区别,不明白上下文注入和真实记忆的差异,也搞不懂角色扮演和人格复制的鸿沟。这种认知上的空白,恰恰是夸大其词的故事最好的生存土壤。
我认为,真正值得担心的并非“同事.Skill”这类项目本身,而是公众对AI技术能力的系统性误读。为了流量而不断夸大技术的边界,只会进一步误导公众认知,加深不必要的恐慌。
当我们把注意力都放在“同事被炼化”这个充满噱头的话题上时,一些真正重要的问题却被忽视了。比如:在AI时代,我们究竟该如何界定和保护个人数据的权利?当企业可以如此“便捷”地利用员工的数字痕迹时,法律的边界在哪里?这些问题虽然没有简单的答案,但它们远比讨论一个“赛博永生”的玩具要重要得多。
 发表于 2026-4-6 10:57:55
|
查看: 185|
回复: 0
发表于 2026-4-6 10:57:55
|
查看: 185|
回复: 0
