在量化因子挖掘中,“成交量分桶熵”是一个多次出现在《因子日历》中的经典因子。它源自兴业证券郑兆磊老师于2022年8月29日发布的研报《高频研究系列四——成交量分布中的Alpha》。
笔者此前已复现并介绍过该研报中的部分因子,如“成交量极大值分布”、“同价成交量分布中alpha因子”等。这意味着,在深入探讨完“成交量分桶熵”之后,郑老师这篇研报中关于成交量分布的Alpha因子系列就基本介绍完毕了。
这个因子在2024至2026年的《因子日历》中至少出现了两次,其逻辑在《因子日历》中被描述为:
成交量分桶熵(标准差)衡量了成交量不稳定性的分散程度,该因子值越大,说明该股在近一段时间内成交量不稳定的分散程度较大,股价曾经或正在受到知情交易者的带动,此时个股不稳定性极高,整体下行风险较大;日度成交量分桶熵取值越大,日内成交量分布越均匀。
计算步骤与代码实现
笔者最初没有介绍这个因子,主要是因为未能理解其核心计算逻辑,即“如何分桶”。但最近终于想通了关键所在。
1. 计算步骤
- 分桶与概率计算:将单日的分钟成交量数据,从其最小值到最大值的范围进行等距分桶,并计算成交量落在每一个桶中的概率。研报中分为10个桶。经笔者测试,分成5个或20个桶的结果与10个桶相差不大。
- 计算熵值:基于每个桶的概率计算信息熵。
- 低频化处理:计算近20个交易日熵值的标准差(研报推荐方法)。在测试中,使用标准差进行低频化的因子表现优于使用均值。
2. Python代码
该因子的核心计算逻辑并不复杂,代码如下:
def process_single_day(self, idx):
# 加载当日分钟数据
file_name = self.files[idx]
full_path = os.path.join(self.file_pth, file_name)
vol = BaseDataLoader.load_data(full_path,
fields=['volume']).to_dataframe('volume')
start = vol.min()
step = (vol.max() - start) / 10
res = []
for i in range(1, 11):
end = start + step
if i != 10:
flag = (vol >= start) & (vol < end)
else:
flag = (vol >= start) & (vol <= end)
res.append(flag.sum())
start = end
res = pd.concat(res, axis=1).T
res = res / vol.count()
res = res * np.log(res)
res = -res.sum()
res.name = pd.to_datetime(file_name.split('.')[0]) + timedelta(hours=15)
return res
代码解读:
- 第1-6行:读取指定日期的分钟成交量数据。
- 第7行:获取当日成交量的最小值,作为第一个分桶的起始点。
- 第8行:计算分桶的步长 (
(最大值-最小值)/10)。
- 第9-17行:循环10次,统计成交量落在每个桶内的数量。
- 第19行:计算成交量落在每个桶内的概率(次数/总样本数)。
- 第20-21行:根据信息熵公式
H = -Σ(p * log(p)) 计算熵值。
因子表现评价
我们对因子进行了IC分析、回归分析、换手率分析和分层收益分析。
01 IC分析
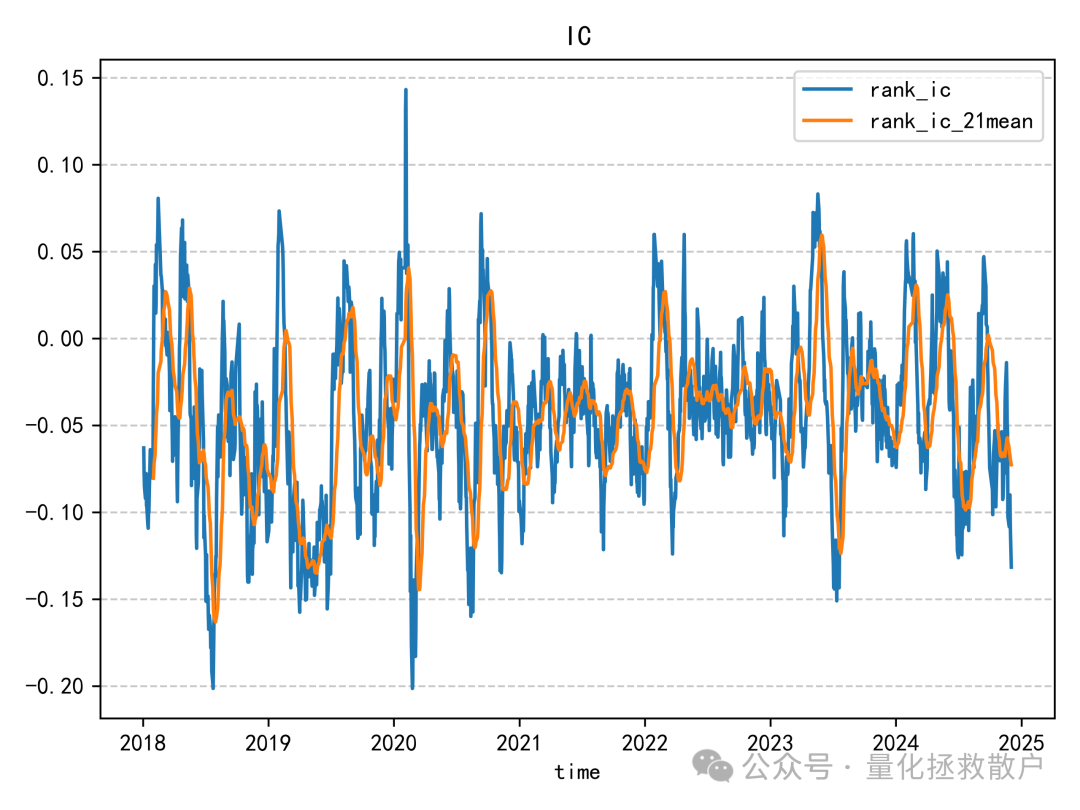
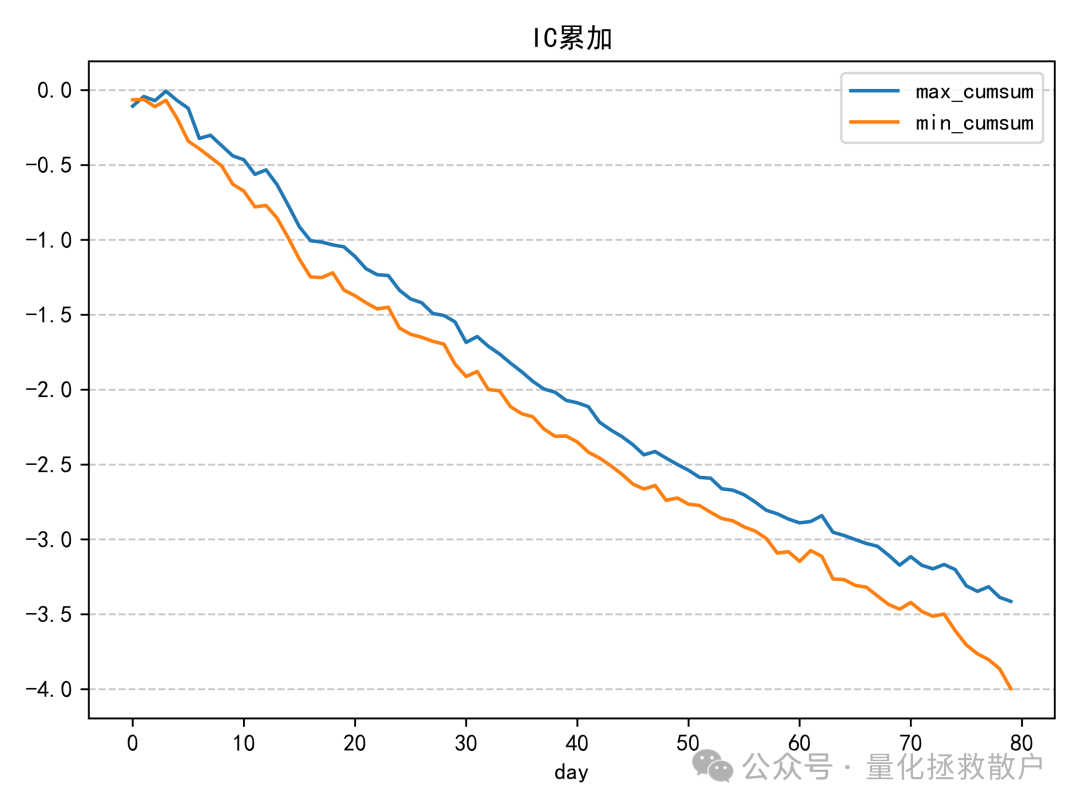
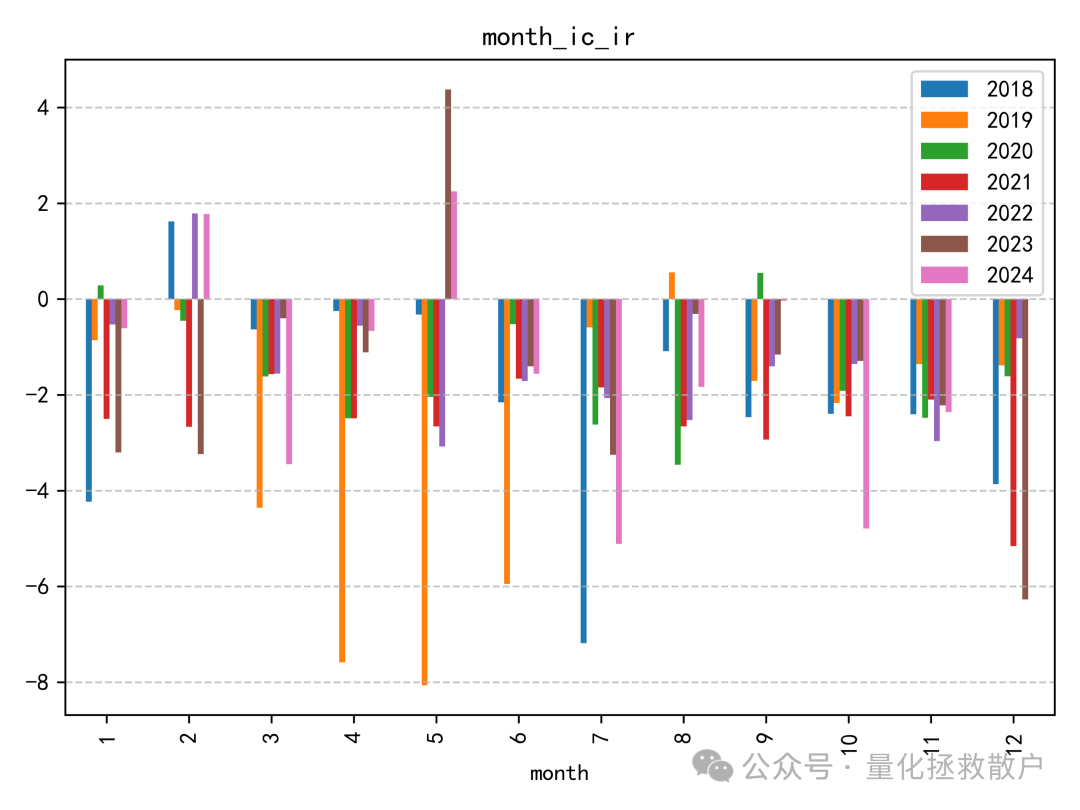
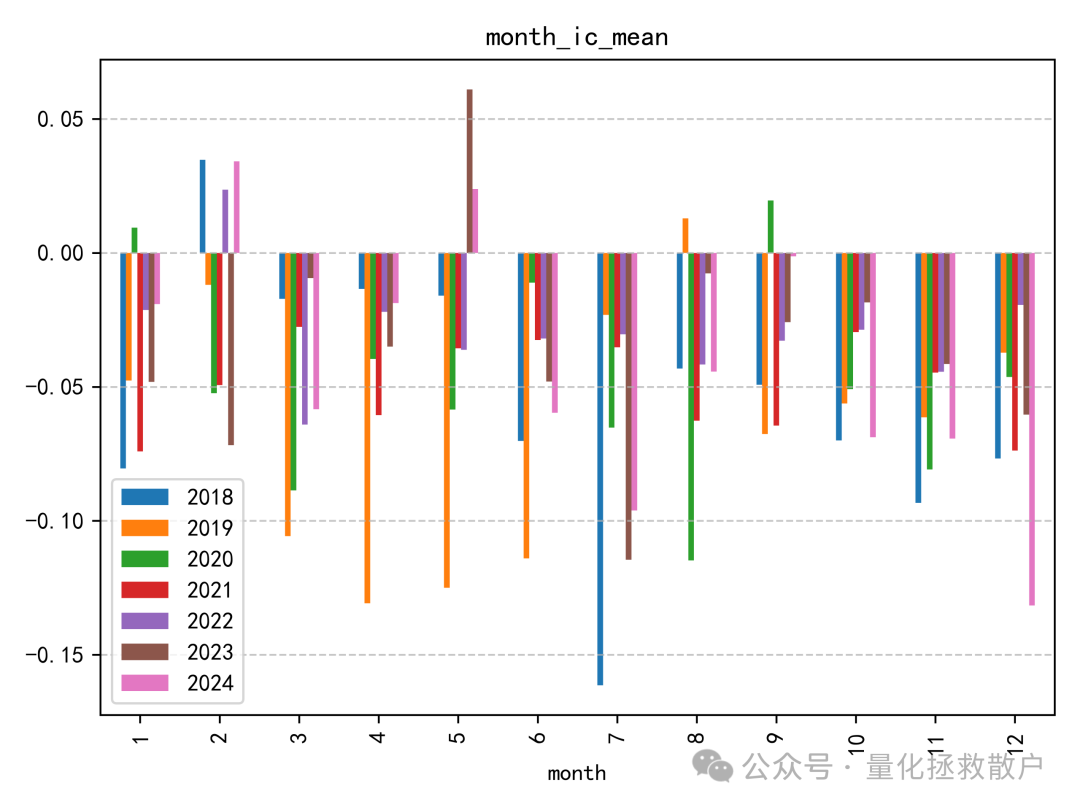
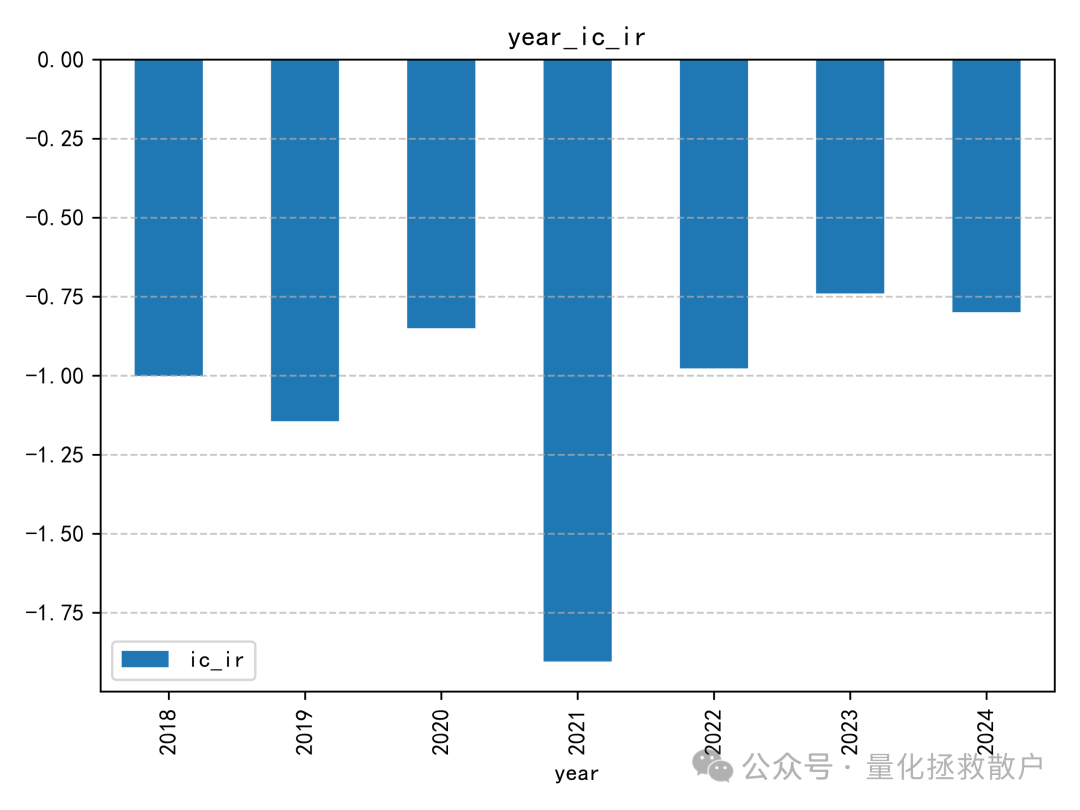
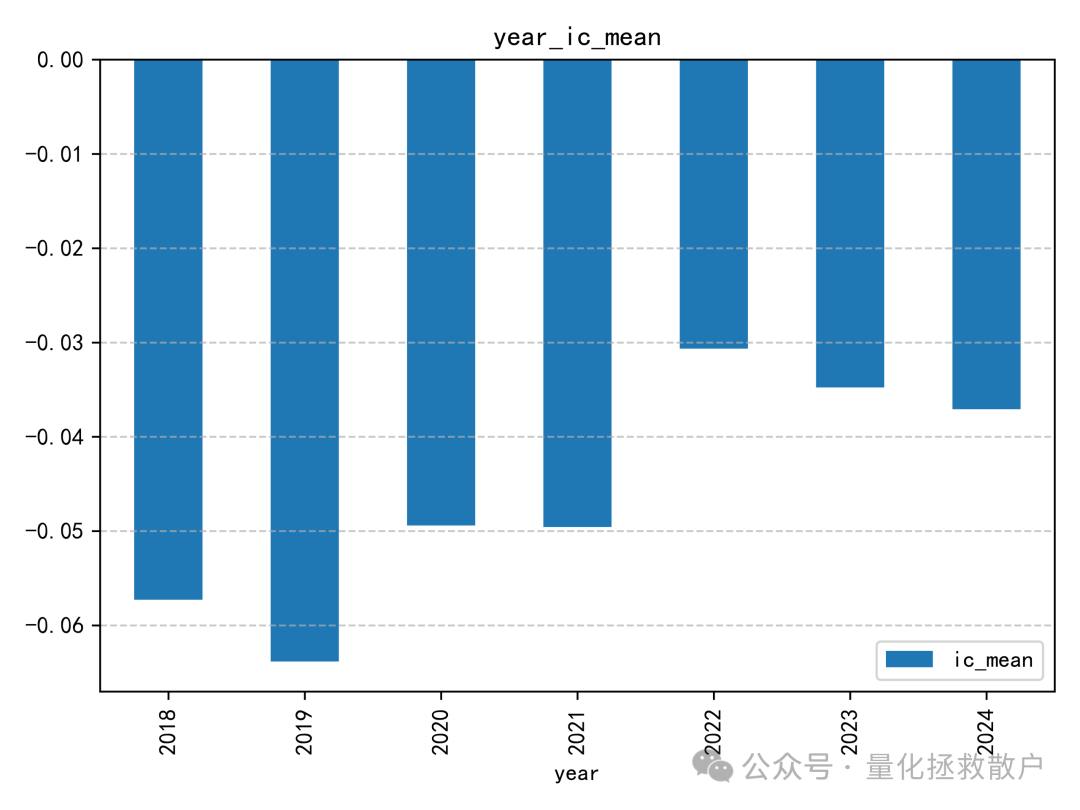
从IC分析结果看,该因子的表现比较一般。即使在同篇研报的诸多因子中,其预测能力也称不上突出。IC绝对值超过0.06的年份仅有2019年。
02 回归分析
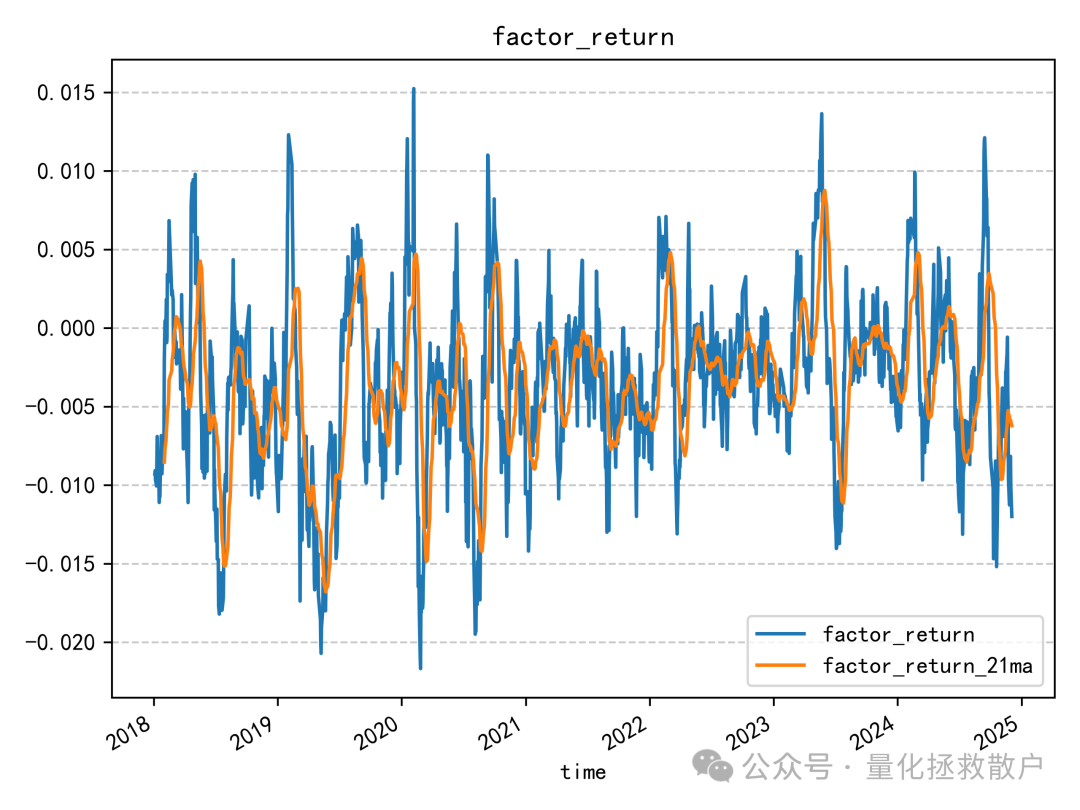
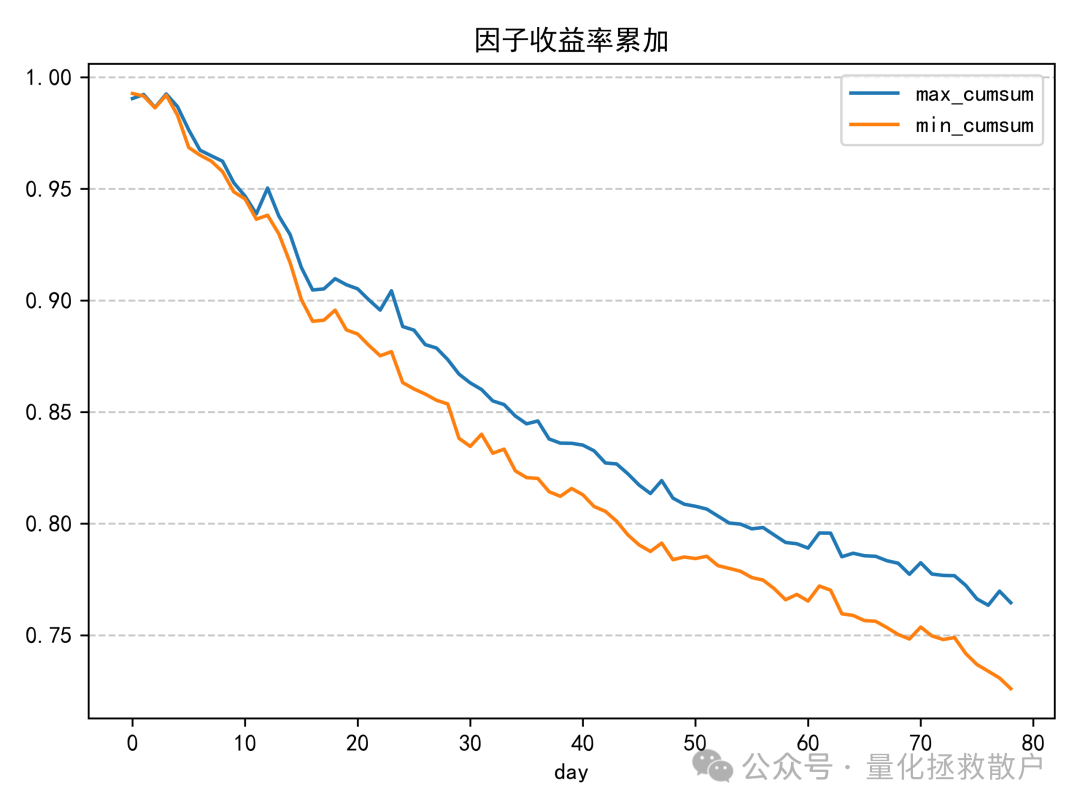
03 换手率分析
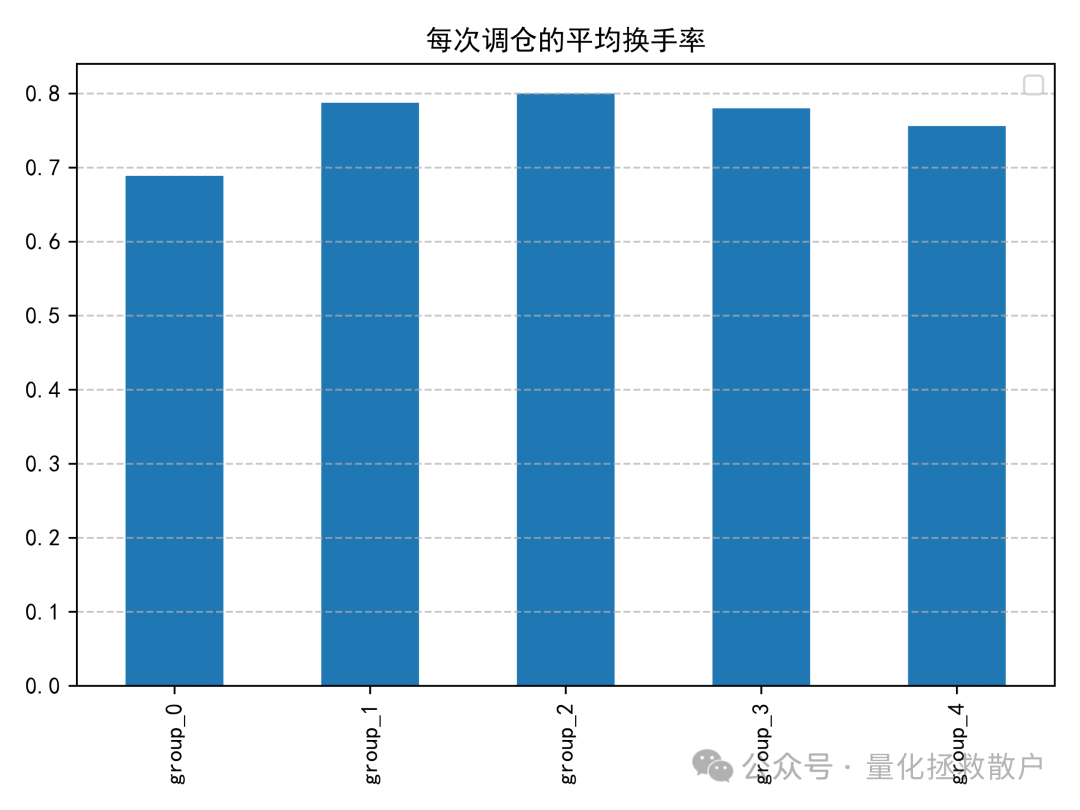
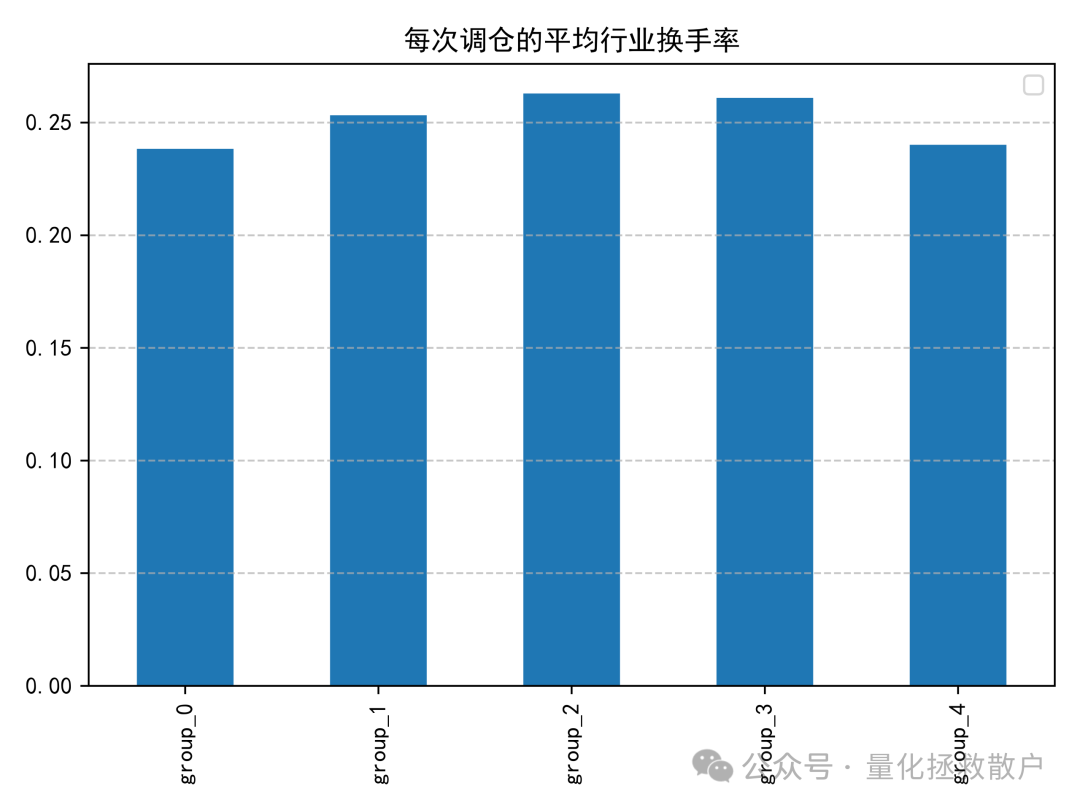
04 分层回测收益分析
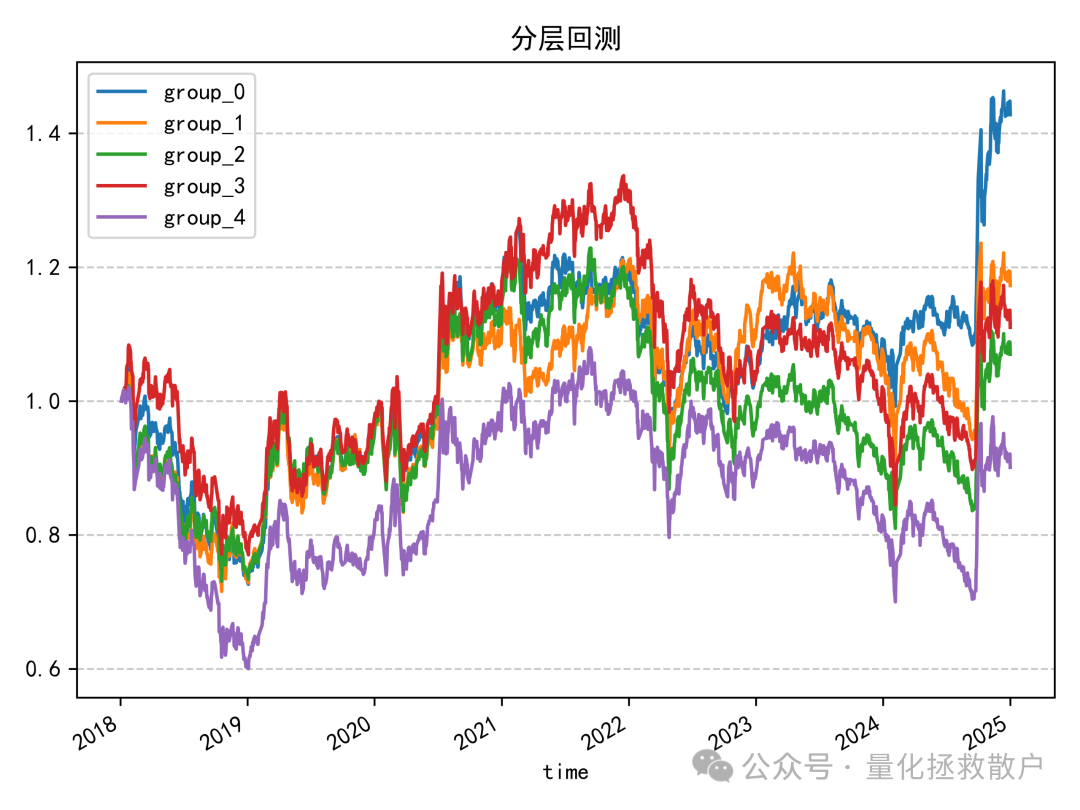
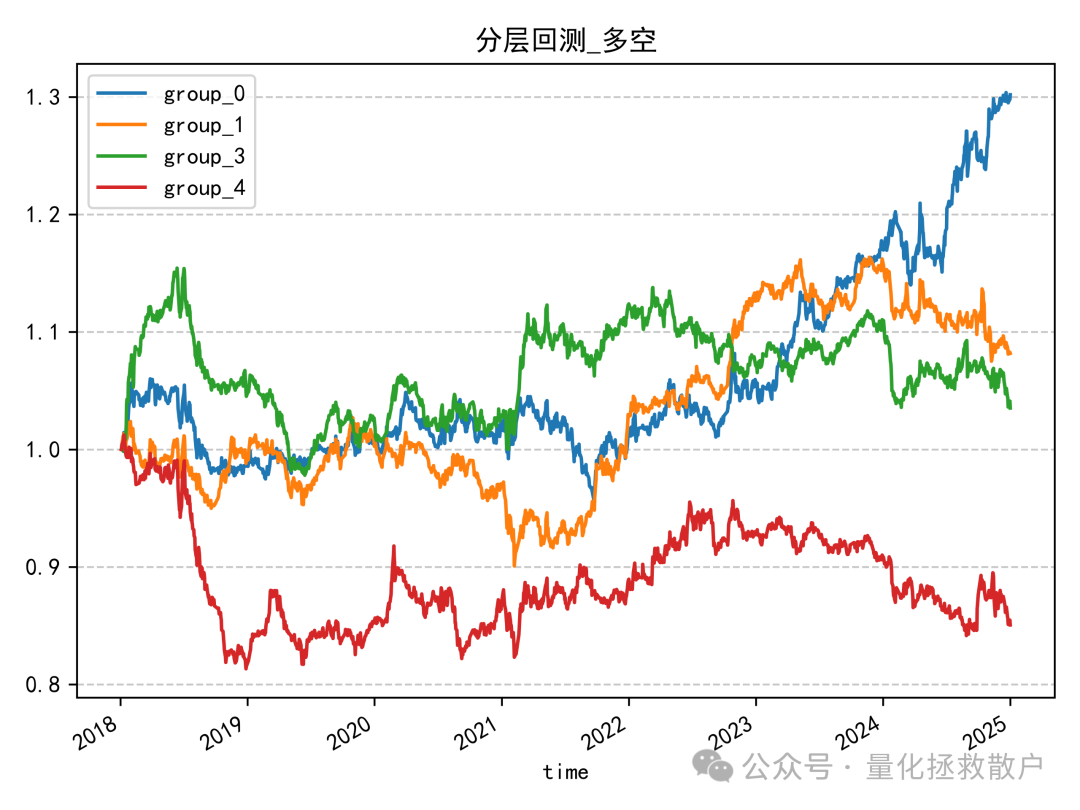
分层回测的结果也较为平淡。最终的单调性并不理想,除了因子值最大的一组(group_4)表现明显落后外,其余四组之间的区分度并不高。
总结
至此,兴业证券《高频研究系列四——成交量分布中的Alpha》研报中的核心因子已全部介绍完毕。该研报共提出了约20个因子,其中表现最好的可能是之前介绍的“同价成交量分布中alpha因子”。
成交量分桶熵因子虽然逻辑清晰,也具备一定的大数据分析特征,但从回测结果看,其选股效果相对有限。在量化实践中,我们可以借鉴其算法思想,但可能需要进行更多的改进或与其他因子结合使用。
对量化因子开发和算法交易感兴趣的朋友,欢迎在云栈社区交流讨论更多实战经验。 |  发表于 2026-4-7 03:38:19
|
查看: 173|
回复: 0
发表于 2026-4-7 03:38:19
|
查看: 173|
回复: 0
